






自己学习自用:
关于编译器识别的一些研究历史和方法:



本来是想直接通过.s文件识别编译器版本,不是很懂这方面的东西
这个论文主要是通过的二进制文件.o和反编译的结果,里面提到汇编文件不能很好的区分不同的编译器

里面提到的一些方法
法一:
将二进制文件反汇编为反汇编文件,从反汇编文件中提取所有反汇编函数并相交,得出编译器相关函数,之后提取编译器相关函数的特征。
该系统提取编译器的标志信息、编译器相关函数的属性控制流图(Attributed Control FlowGraph
,
ACFG
)等语法和语义特征作为编译器的特征。
法二:
对混合后的数据集进行了四分类。其提取每个函数对应的二进制字节并删除字节中的 X64
字节特征,之后选择前
2048
个字节作为长短期记忆网络(
Long Short-Term Memory,
LSTM
)和卷积神经网络(
Convolutional Neural Networks
,
CNN
)的输入,使用这两种网络分别学习字节的内在特征并对其进行分类。
法三:
提取每个反汇编函数中的反汇编指令(由操作码和操作数组成),为了减少无关特征的干扰,其将反汇编指令中的内存操作数统一使用 MEM
替换,将小于
5000
的立即数操作数使用
IMM
替换,再使用
Word2Vec
将处理后的反汇编指令表示为向量,输入 CNN
进行分类,以实现对编译器家族、版本和优化级别的识别。此外,IDA Pro
、
PEiD
等反汇编工具也能识别不同配置的编译器,但是这些工具大多数使用精确匹配算法,当签名之间存在细微的差异时,识别结果可能会出错。
二进制文件特征表示
目前关于二进制代码的特征提取方法可以分为两类: 静态特征提取和动态特征提取



非逆向: 随机森林更优
一种是直接使用字节码作为特征,其不对二进制代码进行处理,直接将其输入神经网络进行学习。另一种是从基于可视化、n-grams、n-perms、hash 等技术从二进制原始字节中提取特征。
逆向:
主要使用
IDA Pro 提取三个方面的特征①常用特征(包括导出函数、字符串)②常量特征(包括整数常量、字符串数组、全局常量数组、全局枚举数组)③控制流特征(包括控制流图、调用图、属性控制流图、switch/case
、
if/else
)等。
Li L
等人
[35]
将二进制文件以
16
进制表示,再将该文件转为灰度图像,使用 CNN
提取图像特征。再将二进制文件反汇编为反汇编文件,基于反汇编文件提取整个数据集的操作码,将出现频率最高的 184
个操作码作为反汇编文件的特征。
所读论文的方法:
(2)针对目前主要基于深度学习提取粗粒度的编译器特征,对差异较小的编译器优化级别识别准确率不高的问题,提出了一种 基于反汇编的编译器特征提取及识别方法 。该方法首先将可执行文件反汇编为反汇编文件,再从反汇编文件中提取统计特征(常用寄存器特征和常用操作码特征)和关联特征,之后使用卡方检验特征选择方法对提取的两种特征进行筛选,将筛选后的融合特征作为编译器的识别依据。
(
3
)可执行文件存在加壳情况,一般很难对加壳代码进行反汇编操作,基于反汇编的编译器特征提取及识别方法具有一定的局限性。针对该问题,本文提出了
一种基于二进制字节码的多特征融合的编译器特征提取及识别方法
。该方法从二进制代码中提取GLCM 图像纹理特征、
LBP
图像纹理特征、字节直方图特征和字节熵直方图特征,
使用PCA 特征选择方法对四种特征分别进行选
择,选择总贡献率大于
90%
的特征集,将筛选后的特征集融合作为编译器的识别依据。
(
4
)使用
SVM
(
Support Vector Machine
,
SVM
)、
LightGBM
(
Light Gradient Boosting Machine,LightGBM
)、
XGBoost
(
Extreme Gradient Boosting
,
XGBoost
)和
RF
(
Random
Forest
,
RF
)四种机器学习模型
分别对提取的单一特征和融合特征进行分类
,从编译器家族、版本和优化级别三个角度验证本文提出的两种编译器特征提取方法的有效性。
编译器优化

基于机器学习的编译器识别步骤
目前关于编译器识别的研究主要是基于深度学习,其主要是将二进制文件以各种方式表示为可以送入网络进行学习的形式,然后依靠网络自动提取二进制代码的内在特征并分类。
这种方式提取的特征基本是整个二进制文件,其存在大量的冗余特征,不能很好的识别差异较小的编译器优化级别。
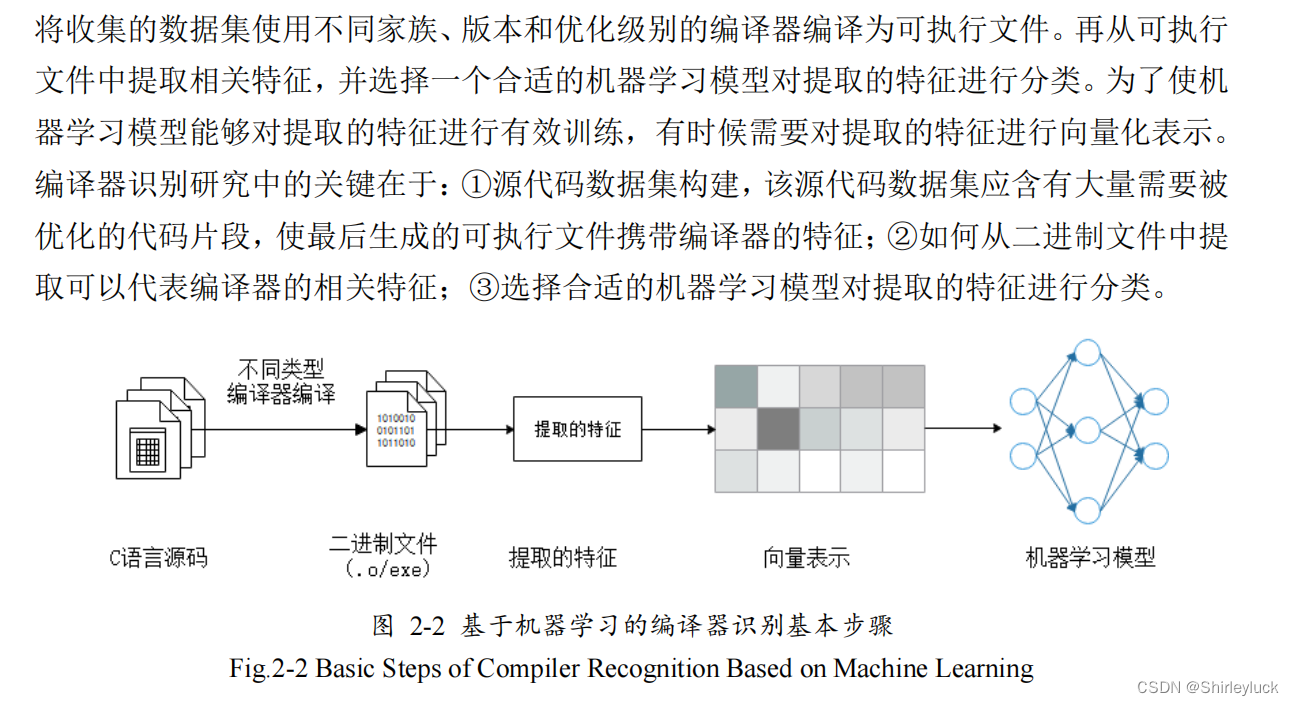
二进制文件特征表示
基于灰度共生矩阵的纹理特征提取
选择了最具 代表性的 5
个特征:能量、对比度、熵、逆差距和相关性
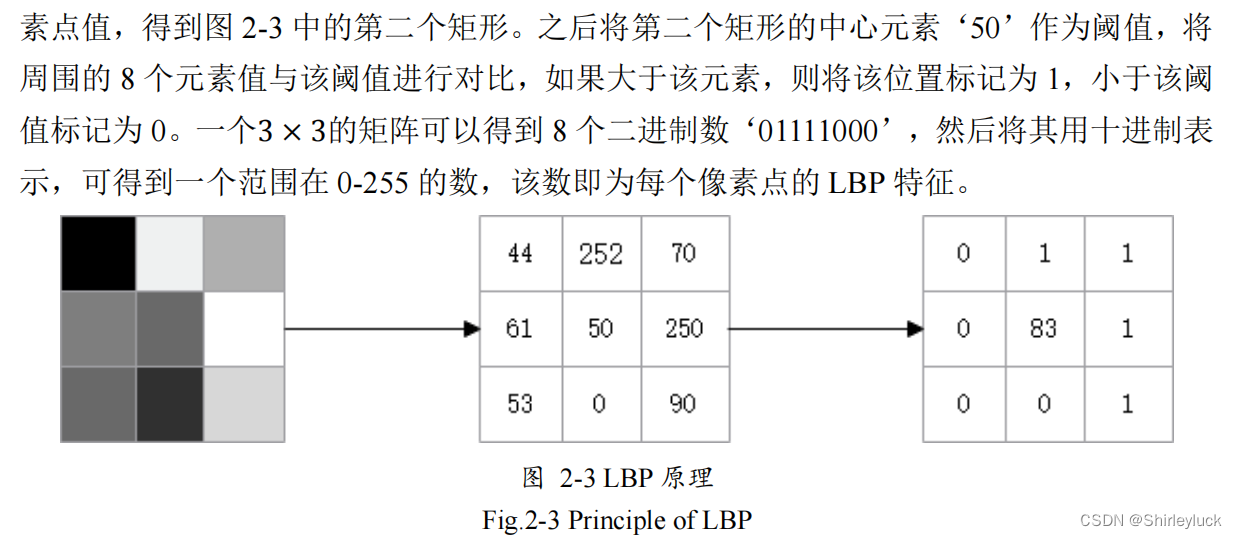
使用 LBP 算法的局部纹理特征提取
分类算法
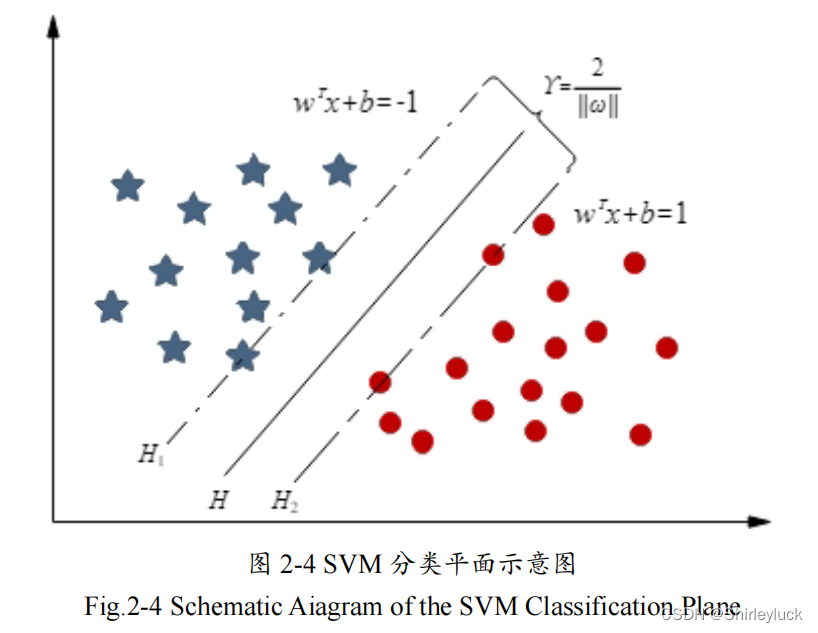
支持向量机SVM
SVM
的训练过程就是寻找一个最优的分类超平面 H
,
H
选择的条件就是使类别间隙
γ
最大,并且使
H
1
和
H
2
到
H
的距离相等。
SVM
核函数的选择至关重要,一般在训练时需要基于多种核函数进行实验对比,以选择出最优的核函数进行分类,常见的核函数有以下三种


SVM
进行多分类有两种方式,一对剩余(
One VS Rest
,
OVR
)和 一对一(One VS One
,
OVO
)。

集成学习
常见的集成模型有三种:
Bagging
、Boosting 和
Stacking。
Bagging
的核心思想是并行地训练一系列各自独立的同类模型, 然后将各个模型的分类结果按照某种策略进行聚合。
其在数据集较小时训练结果较好,当
数据集较大时训练结果不好。
Boosting
的核心思想是串行地训练一系列
前后依赖
的同类模型,后一个模型会对前一个模型的输出结果进行纠正。
Stacking 的核心思想是并行地训练一系列各自独立的不同类模型,然后再训练一个元模型来将各个模型的输出结果进行结合。
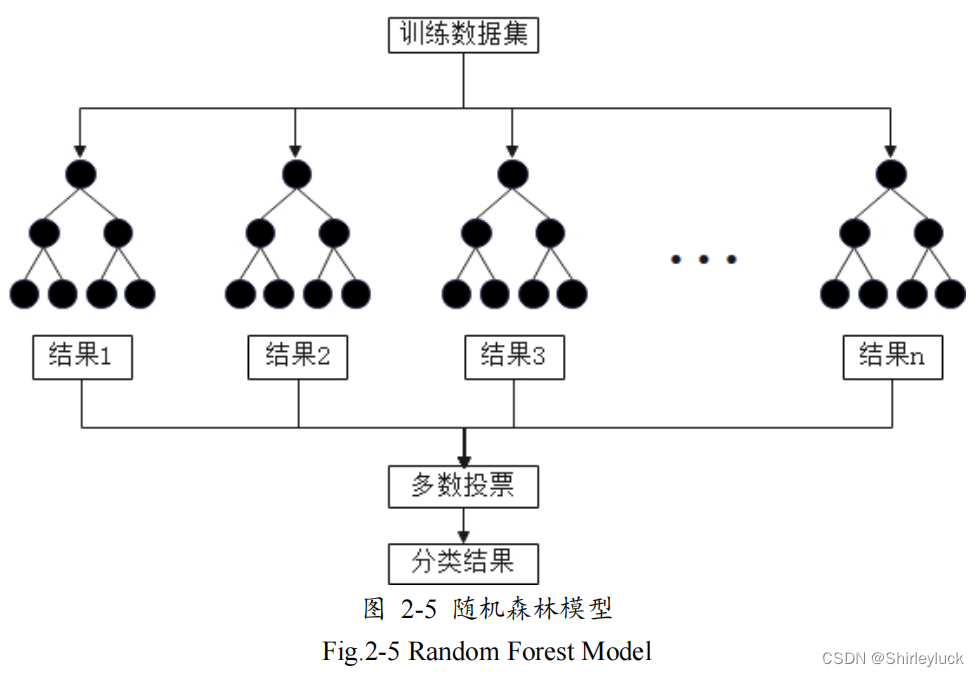
随机森林
基于
Bagging
思想,由多颗决策树组成。
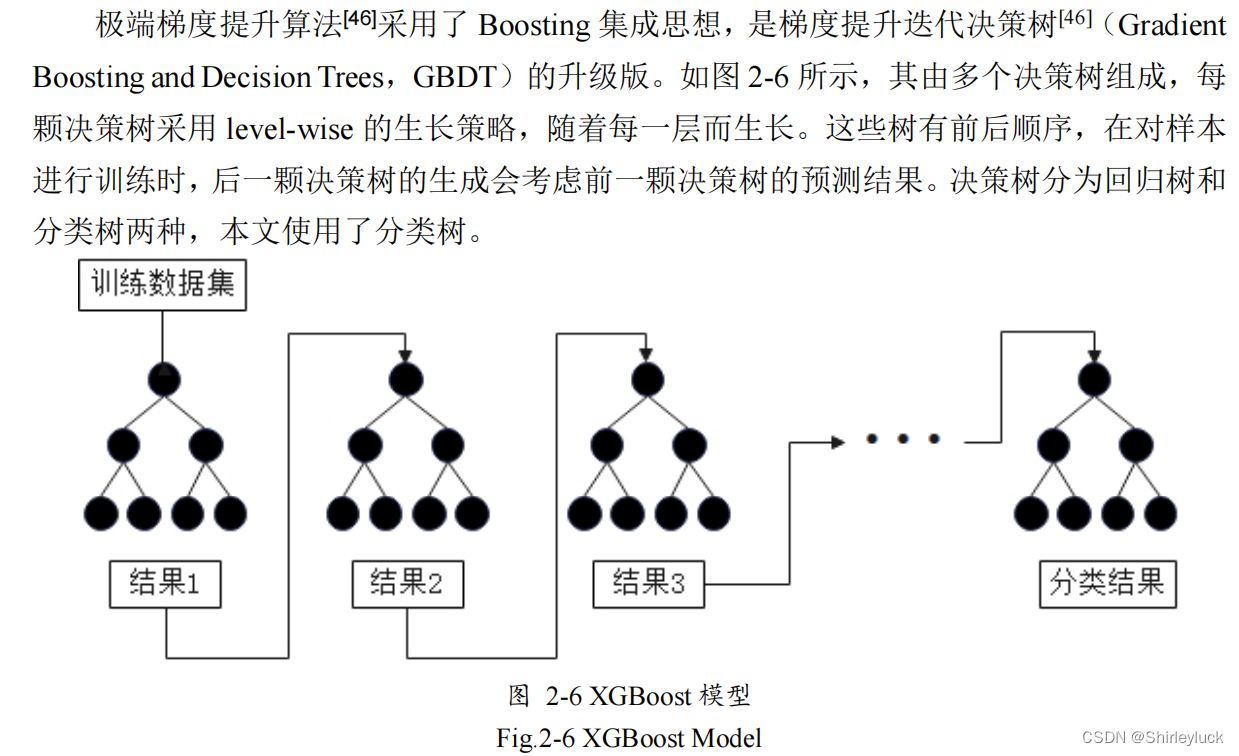
XGBoost
LightGBM
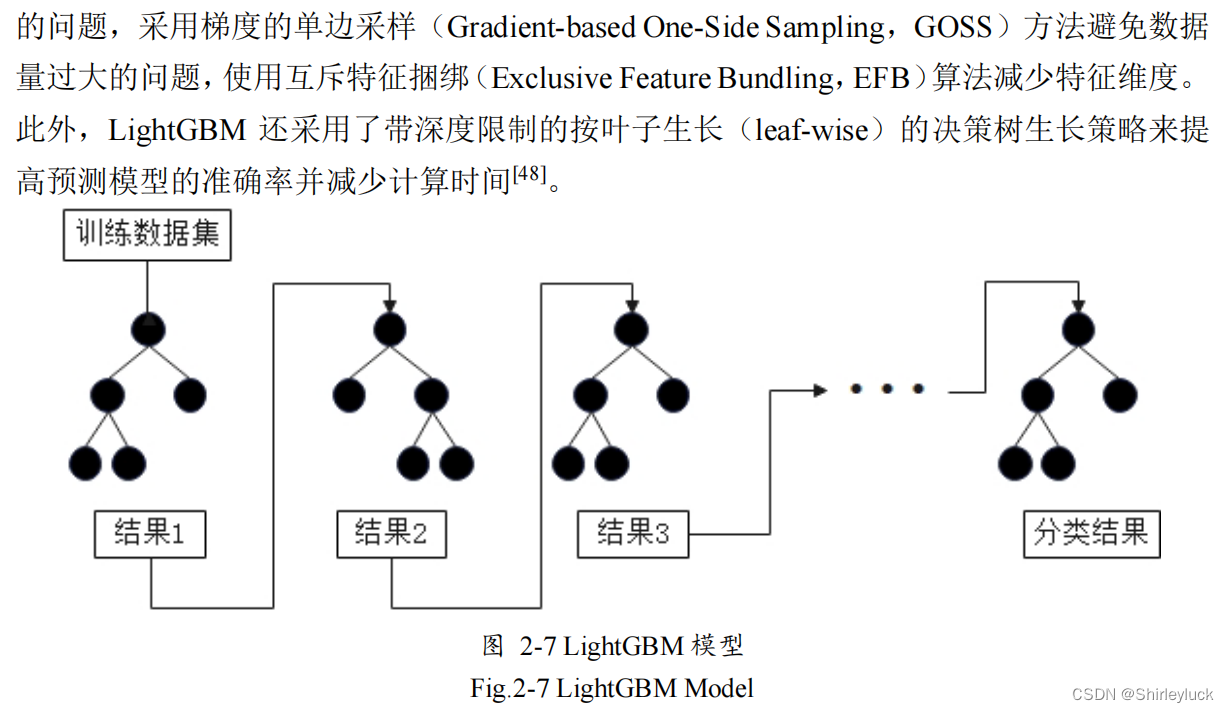
LightGBM
是基于
GBDT
和
XGBoost
的算法框架,它结合了
RF
和梯度学习算法的优点。
特征选择算法
特征降维是采用某种映射方法将高维特征向量映射为低维特征向量,降低高维特征中冗余信息造成的误差,从而提高模型识别准确率,特征降维主要分为特征选择和特征提取两种方式。
主成分分析
卡方检验

不同编译器的设计决策只针对某些特定规则的源代码,只有这些代码经过不同编译器编译后生成的可执行文件才会携带编译器的相关信息,所以 C
语言源码数据集的选取对之后的工作至关重要。
CSmith 编译器测试工具
该工具会针对编译器的特性生成符合
C
语言标准的
C
语言源代码。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









