







写在前面
本文隶属于专栏《100个问题搞定大数据理论体系》,该专栏为笔者原创,引用请注明来源,不足和错误之处请在评论区帮忙指出,谢谢!
本专栏目录结构和文献引用请见100个问题搞定大数据理论体系
解答
Lambda架构作为一种模式,提供了在大型数据集上执行高度可伸缩和高性能分布式计算的方法,并且最终为批处理和近实时处理提供了一致的数据。
Lambda架构定义了能应对企业中各种数据负载的可水平扩展架构的实现方法与手段,并且具有较低的延迟预期。
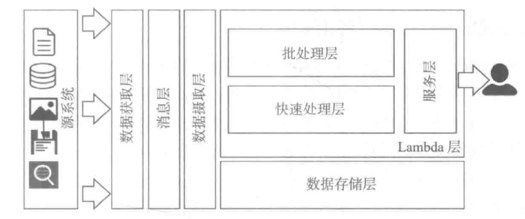
Lambda架构模式的实现方式是将整个架构划分为多个功能模块/层(layer)。
分别是数据摄取层,批处理层,快速处理层,数据存储层,服务层,数据获取层和消息层。
数据湖中的功能模块如图所示。
补充
数据摄取层一一摄取数据用于处理和存储
快速的数据摄取层(data ingestion layer)是Lambda架构模式中的关键层之一。这一层需要控制将数据快速传递到Lambda架构的工作模型中。
关键功能
- 该层必须具有高度可扩展性,满足各种需求,能够根据不同的负载情况进行伸缩。
- 该层必须具有容错(fault tolerant)能力,提供系统可靠性和故障转移(fail-over)能力。
- 该层必须支持多线程及多事件处理
- 该层必须能够快速地将所摄取数据的结构转换为目标数据格式,这是 Lambda架构处理层所要求的。
- 该层必须确保所交付的所有数据都以最纯粹的形式供下一步处理。
批处理层一一批量处理已提取数据
批处理层(batch layer)是Lambda架构中对已提取数据进行批量处理的层,以确保系统资源的最佳利用,同时也可将长时间运行的操作应用于数据,以确保输出数据的高质量。 输出数据也称为模型数据(modeled data)。
将原始数据转换为模型数据是批处理层的主要职责,其中,模型数据中蕴含了Lambda架构中服务层(serving layer)向外提供数据的数据模型。
关键功能
- 该层必须能在已摄取的原始数据之上执行数据清理、数据处理、数据建模算法。
- 该层必须提供重新执行(replay/rerun)某些操作的机制,以实现故障恢复。
- 该层必须支持在已摄取的原始数据之上执行机器学习算法或数据科学处理,以产生高质量的模型数据。
- 该层可能需要执行一些其他操作,以期通过移除重复数据、检測错误数据和提供数据世系视图来提高模型数据的整体质量。
快速处理层一一近实时数据处理
快速处理层(speed layer)将对从数据摄取层接收的数据执行近实时处理。由于处理预期接近实时,因此这些数据的处理需要快速、高效,为高并发场景提供支持和相应的精心设计,并且最终产生满足一致性要求的输出结果。
关键功能
- 必须支持在特定数据流之上的快速操作。
- 必须能生成满足近实时处理需求的数据模型。所有需要长时间运行的处理必须被委托给批处理模式。
- 必须有快速访问能力和存储层的支持,这样就不会因为处理能力而导致事件的堆积。
- 必须与数据摄取层的批处理过程分离。
- 必须产生一个输出模型,该模型(从某种程度上来说)可以与批处理产生的数据集合并,进一步提供增强型的企业数据。
数据存储层一一存储所有数据
在 Lambda架构模式中,数据存储层(data storage layer)非常引人注目,因为该层定义了整个解决方案对传入事件/数据流的反应。
由架构常识可知,一个系统的速度最多与处理链中最慢的子系统一样快,因此,如果存储层不够快,由近实时处理层执行的操作将会变得很慢,从而阻碍了该架构达到近实时的效果。
在Lambda的总体架构中,针对已摄取的数据有两种主动操作:批处理和近实时处理。批处理和近实时处理的数据需求差别很大。
例如,在大多数情况下,批处理模式需要执行串行读和串行写操作,此时使用 Hadoop存储层就足够了,但是如果我们考虑近实时处理, 需要快速查找和快速写入,那么 Hadoop存储层可能是不合适的(见下表)。
为了支持近实时处理,需要数据层支持某些类型的索引数据存储。
| 批处理 | 近实时处理 |
|---|---|
| 串行写及串行读操作 | 快速查找,快速写入 |
| Hadoop存储层能胜任 | Hadoop存储层不能胜任 |
关键功能
- 同时支持串行读写及随机读写。
- 针对用户的使用情况,提供合适的层次性的解决方案。
- 支持以批量模式或近实时模式处理海量数据。
- 以灵活、可扩展的方式支持多种数据结构的存储。
服务层一一数据交付与导出
Lambda架构也强调了为消费者程序提供数据传输服务的重要性。
众所周知,数据可以以多种方式在系统间传递。其中最重要的一种方式是通过服务(service)传递。在数据湖背景中,这些服务被称为数据服务(data service),因为它们的主要功能是传输数据。
另外一种传输数据的方式是数据导出(export)。数据最终可导出为多种格式,如消息、文件、数据备份等,导出的数据供其他系统消费。
数据传输/服务主要关注的是如何将数据转换为预期的格式。这种格式可以强制约定为数据契约(data contract),数据服务在对外提供服务时遵循该约定。
然而,在执行数据传输操作时,合并批量处理及近实时处理产生的数据非常重要,因为这两类数据中都可能包含与组织机构相关的关键信息。
数据服务层必须保证数据与数据契约(与消费者程序约定)的一致性。
关键功能
- 支持多种机制为消费者程序提供数据服务。
- 每种支持数据服务的机制,必须与消费者程序的数据契约兼容。
- 支持批量处理及近实时处理数据视图的合并。
- 为消费者程序提供可扩展、快速响应的数据服务。
因为数据服务层的核心职责是向数据湖以外的消费者提供数据服务,出于增强数据表现的考虑,该层可能会选择性地进行数据合并。
数据获取层一一从源系统获取数据
企业中数据格式多种多样,可大致分为结构化数据、半结构化数据和非结构化数据。
结构化数据的常见例子包括关系数据库、XML/JSON、系统间传递的消息等。
企业也非常青睐半结构化数据,尤其是E-Mail、聊天记录、文档等。
非结构化数据的典型例子包括图片、视频、原始文本、音频文件等。
对于这些类型的数据,部分数据可能无法对其定义模式( schema)。需要将数据转换为有意义的信息时,模式是非常重要的。
为结构化数据定义模式的方法非常直接,但是无法为半结构化数据或非结构化数据定义模式。
数据获取层的一个关键作用是将数据转换为在数据湖中可进行后续处理的消息。
因此数据获取层必须非常灵活,能适应多种数据模式。同时,它也必须支持快速的连接机制,无缝地推送所有转换过的数据消息到数据湖中去。
数据获取层在数据获取端由多路连接(multi- connector)组件构成,然后将数据推送到特定的目的地。
在数据湖的例子中,目的地指的是消息层。
很多技术框架可以用于构建能支持多种源系统的低延迟的数据获取层。
对于每种源系统类型,数据获取层的连接都需要根据所依赖的底层框架进行特殊配置。
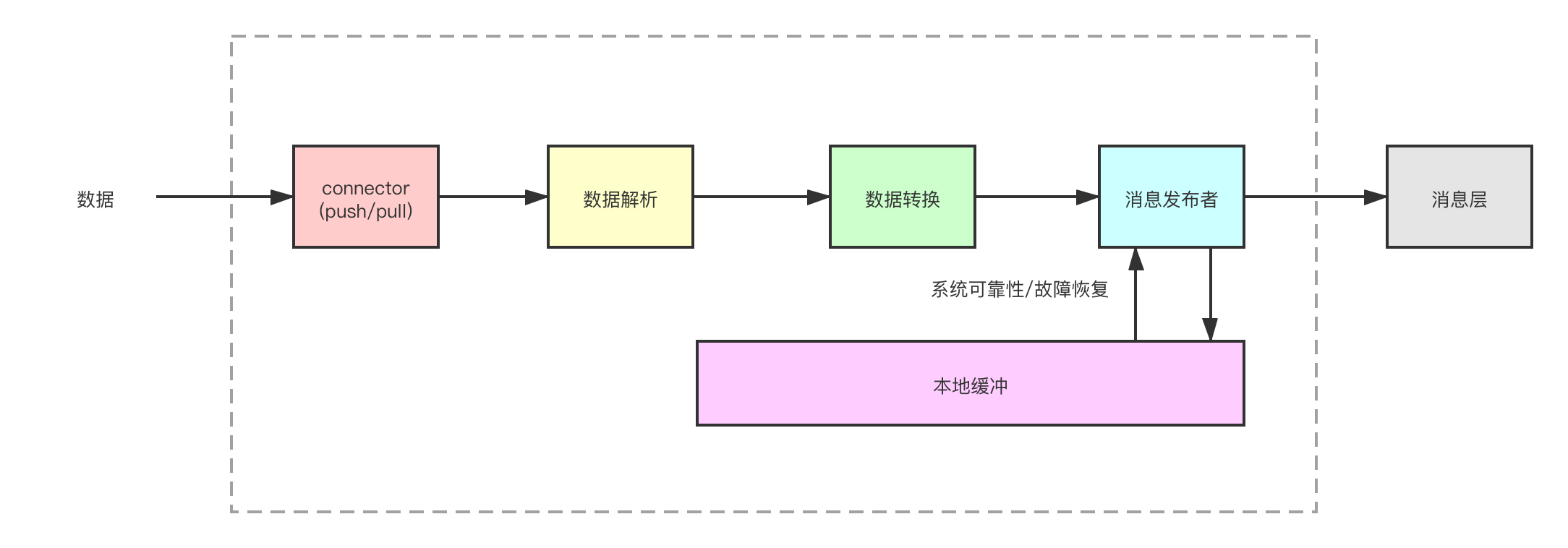
数据获取层会对已获取的数据做少量转换,其目的是最小化传输延迟。
这里的数据转换指的是将已获取的数据转换为消息或事件,它们可以发送给消息层。
如果消息层无法到达(由于网络中断或消息层处于停机期间),则数据获取层还必须提供所需的安全性保障和故障恢复机制。
为了确保该层的安全性,它应该能够支持本地持久化的消息缓冲,这样,如果需要, 并且当消息层再次可用时,消息可以从本地缓冲区中恢复。
该模块还应该支持故障转移如果其中一个数据获取进程失败,另一个进程将无缝接管,如图所示。
消息层一一数据传输的保障
消息层其实就是数据湖架构里的消息中间件(Message Oriented Middleware,MOM), 该层的主要作用是让数据湖各层组件之间解耦,同时保证消息传递的安全性。
为了确保消息能被正确传输到目的地,消息将会被持久化到某种存储设备中去。被选用的存储设备需要与消息处理需求匹配(结合消息大小及数量等因素)。
更进一步来看,不论是读操作还是写操作,消息中间件都是按队列(queue)方式来处理的,队列天然适合处理串行存取,机械硬盘足以应付此类I/O操作。
对于那些需要每秒处理百万级的消息的大型应用程序来说,SSD能提供更好的I/O性能。
消息层组件必须能对消息队列进行入队列和出队列操作。对于大多数消息处理框架来说,入队列和出队列操作对应的是消息发布与消息消费。
每个消息处理框架都提供了一系列库函数,用于与消息队列的资源连接(如 topic/queue)。
任意消息中间件都支持两类与队列通信的方式以及topic消息结构:
- 点对点模型:队列通常用于点对点(point-to-point)通信,每个消息应该只被某个消费者消费一次。
- 发布订阅模型:topic概念经常出现于发布/订阅机制中,在这里,一个消息被发布一次,但是被多个订阅者(消费者)消费。一条消息会被多次消费,但是每个消费者消费一次。在消息系统内部, topic基于队列来构建;消息引擎(message engine)对这些队列进行差异化管理,以实现一个发布/订阅机制。
队列与topic都可以根据需要配置为持久化或非持久化。出于保障数据发布安全的目的,强烈建议将队列配置为持久化,这样消息将不会丢失。
从较高的层次来看,消息中间件可以抽象为由消息代理(message broker)、消息存储、topic/queue等组件组成的框架。















 366
366











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









