







前言
本文隶属于专栏《1000个问题搞定大数据技术体系》,该专栏为笔者原创,引用请注明来源,不足和错误之处请在评论区帮忙指出,谢谢!
本专栏目录结构和参考文献请见1000个问题搞定大数据技术体系
目录
Spark SQL functions.scala 源码解析(一)Sort functions (基于 Spark 3.3.0)
Spark SQL functions.scala 源码解析(二)Aggregate functions(基于 Spark 3.3.0)
Spark SQL functions.scala 源码解析(三)Window functions (基于 Spark 3.3.0)
Spark SQL functions.scala 源码解析(四)Non-aggregate functions (基于 Spark 3.3.0)
Spark SQL functions.scala 源码解析(五)Math Functions (基于 Spark 3.3.0)
Spark SQL functions.scala 源码解析(六)Misc functions (基于 Spark 3.3.0)
Spark SQL functions.scala 源码解析(七)String functions (基于 Spark 3.3.0)
Spark SQL functions.scala 源码解析(八)DateTime functions (基于 Spark 3.3.0)
Spark SQL functions.scala 源码解析(九)Collection functions (基于 Spark 3.3.0)
Spark SQL functions.scala 源码解析(十)Partition transform functions(基于 Spark 3.3.0)
Spark SQL functions.scala 源码解析(十一)Scala UDF functions(基于 Spark 3.3.0)
Spark SQL functions.scala 源码解析(十二)Java UDF functions(基于 Spark 3.3.0)
正文
ascii
/**
* 计算字符串列的第一个字符的数值,并将结果作为 int 列返回
*
* @group string_funcs
* @since 1.5.0
*/
def ascii(e: Column): Column = withExpr { Ascii(e.expr) }
用法
========== df.select(ascii($"a"), ascii($"b"), ascii($"c")).show() ==========
+--------+--------+--------+
|ascii(a)|ascii(b)|ascii(c)|
+--------+--------+--------+
| 97| 97| 0|
+--------+--------+--------+
base64
/**
* 计算二进制列的 BASE64 编码并将其作为字符串列返回。
* 这与 unbase64 正好相反。
*
* @group string_funcs
* @since 1.5.0
*/
def base64(e: Column): Column = withExpr { Base64(e.expr) }
用法
========== df.select(base64($"a"), base64($"b"), base64($"c")).show() ==========
+---------+---------+---------+
|base64(a)|base64(b)|base64(c)|
+---------+---------+---------+
| YWJj| YWFhQmI=| |
+---------+---------+---------+
bit_length
/**
* 计算指定字符串列的位长。
*
* @group string_funcs
* @since 3.3.0
*/
def bit_length(e: Column): Column = withExpr { BitLength(e.expr) }
concat_ws
/**
* 使用给定的分隔符将多个输入字符串列连接到一个字符串列中。
*
* @group string_funcs
* @since 1.5.0
*/
@scala.annotation.varargs
def concat_ws(sep: String, exprs: Column*): Column = withExpr {
ConcatWs(Literal.create(sep, StringType) +: exprs.map(_.expr))
}
用法
========== df.select(concat_ws(";", $"a", $"b", $"c")).show() ==========
+---------------------+
|concat_ws(;, a, b, c)|
+---------------------+
| abc;aaaBb;|
+---------------------+
decode/encode
/**
* 使用提供的字符集(“US-ASCII”、“ISO-8859-1”、“UTF-8”、“UTF-16BE”、“UTF-16LE”、“UTF-16” 之一)
* 将第一个参数从二进制计算为字符串。
*
* 如果任一参数为空,则结果也将为空。
*
* @group string_funcs
* @since 1.5.0
*/
def decode(value: Column, charset: String): Column = withExpr {
StringDecode(value.expr, lit(charset).expr)
}
/**
* 使用提供的字符集(“US-ASCII”、“ISO-8859-1”、“UTF-8”、“UTF-16BE”、“UTF-16LE”、“UTF-16” 之一)
* 将第一个参数从字符串计算为二进制。
*
* 如果任一参数为空,则结果也将为空。
*
* @group string_funcs
* @since 1.5.0
*/
def encode(value: Column, charset: String): Column = withExpr {
Encode(value.expr, lit(charset).expr)
}
用法
========== df.select(decode($"a", "utf-8")).show() ==========
+----------------------+
|stringdecode(a, utf-8)|
+----------------------+
| abc|
+----------------------+
========== df.select(encode($"a", "utf-8")).show() ==========
+----------------+
|encode(a, utf-8)|
+----------------+
| [61 62 63]|
+----------------+
format_number/format_string
/**
* 将数字列 x 格式化为类似 '#,###,###.##' 的格式,使用 HALF_EVEN 舍入模式舍入到 d 个小数位,并将结果作为字符串列返回。
*
* 如果 d 为 0,则结果没有小数点或小数部分。 如果 d 小于 0,则结果将为空。
*
* @group string_funcs
* @since 1.5.0
*/
def format_number(x: Column, d: Int): Column = withExpr {
FormatNumber(x.expr, lit(d).expr)
}
/**
* 以 printf 样式格式化参数并将结果作为字符串列返回。
*
* @group string_funcs
* @since 1.5.0
*/
@scala.annotation.varargs
def format_string(format: String, arguments: Column*): Column = withExpr {
FormatString((lit(format) +: arguments).map(_.expr): _*)
}
HALF_EVEN 舍入模式:向最接近数字方向舍入,如果与两个相邻数字的距离相等,则向相邻的偶数舍入。
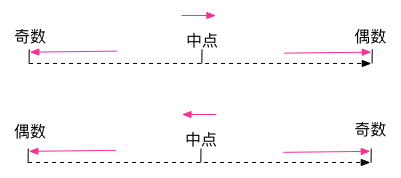
用法
========== df.select(format_number(lit(5L), 4)).show() ==========
+-------------------+
|format_number(5, 4)|
+-------------------+
| 5.0000|
+-------------------+
========== df.select(format_number(lit(1.toByte), 4)).show() ==========
+-------------------+
|format_number(1, 4)|
+-------------------+
| 1.0000|
+-------------------+
========== df.select(format_number(lit(2.toShort), 4)).show() ==========
+-------------------+
|format_number(2, 4)|
+-------------------+
| 2.0000|
+-------------------+
========== df.select(format_number(lit(3.1322.toFloat), 4)).show() ==========
+------------------------+
|format_number(3.1322, 4)|
+------------------------+
| 3.1322|
+------------------------+
========== df.select(format_number(lit(4), 4)).show() ==========
+-------------------+
|format_number(4, 4)|
+-------------------+
| 4.0000|
+-------------------+
========== df.select(format_number(lit(5L), 4)).show() ==========
+-------------------+
|format_number(5, 4)|
+-------------------+
| 5.0000|
+-------------------+
========== df.select(format_number(lit(6.48173), 4)).show() ==========
+-------------------------+
|format_number(6.48173, 4)|
+-------------------------+
| 6.4817|
+-------------------------+
========== df.select(format_number(lit(BigDecimal("7.128381")), 4)).show() ==========
+--------------------------+
|format_number(7.128381, 4)|
+--------------------------+
| 7.1284|
+--------------------------+
========== df.select(format_string("aa%d%s", lit(123), lit("cc"))).show() ==========
+------------------------------+
|format_string(aa%d%s, 123, cc)|
+------------------------------+
| aa123cc|
+------------------------------+
initcap
/**
* 通过将每个单词的第一个字母转换为大写,返回一个新的字符串列。
* 单词由空格分隔。
* 例如,“hello world”将变成“Hello World”。
*
* @group string_funcs
* @since 1.5.0
*/
def initcap(e: Column): Column = withExpr { InitCap(e.expr) }
用法
========== df.select(initcap($"a"), initcap($"b"), initcap($"c")).show() ==========
+----------+----------+----------+
|initcap(a)|initcap(b)|initcap(c)|
+----------+----------+----------+
| Abc| Aaabb| |
+----------+----------+----------+
instr
/**
* 定位给定字符串中第一次出现 substr 列的位置。
* 如果任一参数为 null,则返回 null。
* 注意:
* 该位置不是基于零的,而是基于 1 的索引。
* 如果在 str 中找不到 substr,则返回 0。
*
* @group string_funcs
* @since 1.5.0
*/
def instr(str: Column, substring: String): Column = withExpr {
StringInstr(str.expr, lit(substring).expr)
}
用法
========== df.select(instr($"b", "aa")).show() ==========
+------------+
|instr(b, aa)|
+------------+
| 1|
+------------+
length
/**
* 计算给定字符串的字符长度或二进制字符串的字节数。
* 字符串的长度包括尾随空格。
* 二进制字符串的长度包括二进制零。
*
* @group string_funcs
* @since 1.5.0
*/
def length(e: Column): Column = withExpr { Length(e.expr) }
用法
========== df.select(length($"a"), length($"b"), length($"c")).show() ==========
+---------+---------+---------+
|length(a)|length(b)|length(c)|
+---------+---------+---------+
| 3| 5| 0|
+---------+---------+---------+
lower
/**
* 将字符串列转换为小写。
*
* @group string_funcs
* @since 1.3.0
*/
def lower(e: Column): Column = withExpr { Lower(e.expr) }
用法
========== df.select(lower($"b")).show() ==========
+--------+
|lower(b)|
+--------+
| aaabb|
+--------+
levenshtein
/**
* 计算两个给定字符串列的 Levenshtein 距离。
* @group string_funcs
* @since 1.5.0
*/
def levenshtein(l: Column, r: Column): Column = withExpr { Levenshtein(l.expr, r.expr) }
莱文斯坦距离,又称 Levenshtein 距离,是编辑距离的一种。指两个字串之间,由一个转成另一个所需的最少编辑操作次数。允许的编辑操作包括将一个字符替换成另一个字符,插入一个字符,删除一个字符。
例如将 kitten 一字转成 sitting:
sitten (k→s)
sittin (e→i)
sitting (→g)
俄罗斯科学家弗拉基米尔·莱文斯坦在1965年提出这个概念。
用法
========== df.select(levenshtein($"a", $"b")).show() ==========
+-----------------+
|levenshtein(a, b)|
+-----------------+
| 4|
+-----------------+
locate
/**
* 定位第一次出现 substr 的位置。
* 注意:
* 该位置不是基于零的,而是基于 1 的索引。
* 如果在 str 中找不到 substr,则返回 0
*
* @group string_funcs
* @since 1.5.0
*/
def locate(substr: String, str: Column): Column = withExpr {
new StringLocate(lit(substr).expr, str.expr)
}
/**
* 定位字符串列中第一次出现 substr 的位置,在位置 pos 之后。
*
* 注意:
* 该位置不是基于零的,而是基于 1 的索引。
* 如果在 str 中找不到 substr,则返回 0
*
* @group string_funcs
* @since 1.5.0
*/
def locate(substr: String, str: Column, pos: Int): Column = withExpr {
StringLocate(lit(substr).expr, str.expr, lit(pos).expr)
}
用法
========== df.select(locate("aa", $"b")).show() ==========
+----------------+
|locate(aa, b, 1)|
+----------------+
| 1|
+----------------+
========== df.select(locate("aa", $"b", 2)).show() ==========
+----------------+
|locate(aa, b, 2)|
+----------------+
| 2|
+----------------+
lpad
/**
* 用 pad 左填充字符串列到 len 的长度。
* 如果字符串列长于 len,则返回值将缩短为 len 个字符。
*
* @group string_funcs
* @since 1.5.0
*/
def lpad(str: Column, len: Int, pad: String): Column = withExpr {
StringLPad(str.expr, lit(len).expr, lit(pad).expr)
}
/**
* 用 pad 左填充二进制列到 len 的字节长度。
* 如果二进制列长于 len,则返回值将缩短为 len 字节。
*
* @group string_funcs
* @since 3.3.0
*/
def lpad(str: Column, len: Int, pad: Array[Byte]): Column = withExpr {
new BinaryLPad(str.expr, lit(len).expr, lit(pad).expr)
}
用法
========== df.select(lpad($"a", 10, " ")).show() ==========
+--------------+
|lpad(a, 10, )|
+--------------+
| abc|
+--------------+
ltrim
/**
* 修剪指定字符串值左端的空格。
*
* @group string_funcs
* @since 1.5.0
*/
def ltrim(e: Column): Column = withExpr {StringTrimLeft(e.expr) }
/**
* 为指定的字符串列从左端修剪指定的字符串。
* @group string_funcs
* @since 2.3.0
*/
def ltrim(e: Column, trimString: String): Column = withExpr {
StringTrimLeft(e.expr, Literal(trimString))
}
用法
========== df.select(ltrim(lit(" 123"))).show() ==========
+-------------+
|ltrim( 123)|
+-------------+
| 123|
+-------------+
========== df.select(ltrim(lit("aaa123"), "a")).show() ==========
+---------------------------+
|TRIM(LEADING a FROM aaa123)|
+---------------------------+
| 123|
+---------------------------+
octet_length
/**
* 计算指定字符串列的字节长度。
*
* @group string_funcs
* @since 3.3.0
*/
def octet_length(e: Column): Column = withExpr { OctetLength(e.expr) }
regexp_extract/regexp_replace
/**
* 从指定的字符串列中提取与 Java 正则表达式匹配的特定组。
* 如果正则表达式不匹配,或指定的组不匹配,则返回空字符串。
* 如果指定的组索引超过正则表达式的组数,则会抛出 IllegalArgumentException。
*
* @group string_funcs
* @since 1.5.0
*/
def regexp_extract(e: Column, exp: String, groupIdx: Int): Column = withExpr {
RegExpExtract(e.expr, lit(exp).expr, lit(groupIdx).expr)
}
/**
* 将指定字符串值中与 regexp 匹配的所有子字符串替换为 rep
*
* @group string_funcs
* @since 1.5.0
*/
def regexp_replace(e: Column, pattern: String, replacement: String): Column = withExpr {
RegExpReplace(e.expr, lit(pattern).expr, lit(replacement).expr)
}
/**
* 将指定字符串值中与 regexp 匹配的所有子字符串替换为 rep
*
* @group string_funcs
* @since 2.1.0
*/
def regexp_replace(e: Column, pattern: Column, replacement: Column): Column = withExpr {
RegExpReplace(e.expr, pattern.expr, replacement.expr)
}
用法
========== df.select(regexp_extract(lit("abc123"), "(\\d+)", 1)).show() ==========
+--------------------------------+
|regexp_extract(abc123, (\d+), 1)|
+--------------------------------+
| 123|
+--------------------------------+
========== df.select(regexp_replace(lit("abc123"), "(\\d+)", "num")).show() ==========
+-------------------------------------+
|regexp_replace(abc123, (\d+), num, 1)|
+-------------------------------------+
| abcnum|
+-------------------------------------+
========== df.select(regexp_replace(lit("abc123"), lit("(\\d+)"), lit("num"))).show() ==========
+-------------------------------------+
|regexp_replace(abc123, (\d+), num, 1)|
+-------------------------------------+
| abcnum|
+-------------------------------------+
unbase64
/**
* 解码 BASE64 编码的字符串列并将其作为二进制列返回。
* 这与base64相反。
*
* @group string_funcs
* @since 1.5.0
*/
def unbase64(e: Column): Column = withExpr { UnBase64(e.expr) }
用法
========== df.select(unbase64(typedlit(Array[Byte](1, 2, 3, 4)))).show() ==========
+---------------------+
|unbase64(X'01020304')|
+---------------------+
| []|
+---------------------+
rpad
/**
* 用 pad 右填充字符串列到 len 的长度。
* 如果字符串列长于 len,则返回值将缩短为 len 个字符。
*
* @group string_funcs
* @since 1.5.0
*/
def rpad(str: Column, len: Int, pad: String): Column = withExpr {
StringRPad(str.expr, lit(len).expr, lit(pad).expr)
}
/**
* 用 pad 右填充二进制列到 len 的字节长度。
* 如果二进制列长于 len,则返回值将缩短为 len 字节。
*
* @group string_funcs
* @since 3.3.0
*/
def rpad(str: Column, len: Int, pad: Array[Byte]): Column = withExpr {
new BinaryRPad(str.expr, lit(len).expr, lit(pad).expr)
}
用法
========== df.select(rpad($"a", 10, " ")).show() ==========
+--------------+
|rpad(a, 10, )|
+--------------+
| abc |
+--------------+
repeat
/**
* 重复字符串列 n 次,并将其作为新的字符串列返回。
*
* @group string_funcs
* @since 1.5.0
*/
def repeat(str: Column, n: Int): Column = withExpr {
StringRepeat(str.expr, lit(n).expr)
}
用法
========== df.select(repeat($"a", 3)).show() ==========
+------------+
|repeat(a, 3)|
+------------+
| abcabcabc|
+------------+
rtrim
/**
* 修剪指定字符串值右端的空格
*
* @group string_funcs
* @since 1.5.0
*/
def rtrim(e: Column): Column = withExpr { StringTrimRight(e.expr) }
/**
* 为指定的字符串列从右端修剪指定的字符串。
*
* @group string_funcs
* @since 2.3.0
*/
def rtrim(e: Column, trimString: String): Column = withExpr {
StringTrimRight(e.expr, Literal(trimString))
}
用法
========== df.select(rtrim(lit("123 "))).show() ==========
+-------------+
|rtrim(123 )|
+-------------+
| 123|
+-------------+
========== df.select(rtrim(lit("123aaa"), "a")).show() ==========
+----------------------------+
|TRIM(TRAILING a FROM 123aaa)|
+----------------------------+
| 123|
+----------------------------+
soundex
/**
* 返回指定表达式的 soundex 代码。
*
* @group string_funcs
* @since 1.5.0
*/
def soundex(e: Column): Column = withExpr { SoundEx(e.expr) }
soundex 是一个将任何文本串转换为描述其语音表示的字母数字模式的算法。soundex 考虑了类似的发音字符和音节,使得对字符串进行发音比较而不是字母比较。
用法
========== df.select(soundex($"a"), soundex($"b")).show() ==========
+----------+----------+
|soundex(a)|soundex(b)|
+----------+----------+
| A120| A100|
+----------+----------+
split
/**
* 围绕给定模式的匹配拆分 str 。
*
* @param str 要拆分的字符串表达式
* @param pattern 表示正则表达式的字符串。正则表达式字符串应该是 Java 正则表达式。
*
* @group string_funcs
* @since 1.5.0
*/
def split(str: Column, pattern: String): Column = withExpr {
StringSplit(str.expr, Literal(pattern), Literal(-1))
}
/**
* 围绕给定模式的匹配拆分 str
*
* @param str 要拆分的字符串表达式
* @param pattern 表示正则表达式的字符串。正则表达式字符串应该是 Java 正则表达式。
* @param limit 一个整数表达式,用于控制应用正则表达式的次数。
* limit 大于 0:结果数组的长度不会超过 limit,并且结果数组的最后一个条目将包含最后一个匹配的正则表达式之外的所有输入。
* limit 小于或等于 0:正则表达式将被应用尽可能多的次数,结果数组可以是任意大小。
*
* @group string_funcs
* @since 3.0.0
*/
def split(str: Column, pattern: String, limit: Int): Column = withExpr {
StringSplit(str.expr, Literal(pattern), Literal(limit))
}
用法
========== df.select(split(lit("a;b;c"), ";")).show() ==========
+-------------------+
|split(a;b;c, ;, -1)|
+-------------------+
| [a, b, c]|
+-------------------+
========== df.select(split(lit("a;b;c"), ";", 2)).show() ==========
+------------------+
|split(a;b;c, ;, 2)|
+------------------+
| [a, b;c]|
+------------------+
========== df.select(split(lit("a;b;c"), ";", 0)).show() ==========
+------------------+
|split(a;b;c, ;, 0)|
+------------------+
| [a, b, c]|
+------------------+
========== df.select(split(lit("a;b;c"), ";", -1)).show() ==========
+-------------------+
|split(a;b;c, ;, -1)|
+-------------------+
| [a, b, c]|
+-------------------+
substring/substring_index
/**
* 子字符串从pos开始,当 str 是 String 类型时长度为len或返回字节数组中从pos开始的字节数组切片,当 str 是 Binary 类型时长度为
* len
*
* @注意 该位置不是基于零的,而是基于 1 的索引。
*
* @group string_funcs
* @since 1.5.0
*/
def substring(str: Column, pos: Int, len: Int): Column = withExpr {
Substring(str.expr, lit(pos).expr, lit(len).expr)
}
/**
* 在分隔符 delim 出现次数之前返回字符串 str 中的子字符串。
* 如果计数为正,则返回最终定界符左侧的所有内容(从左侧开始计数)。
* 如果 count 为负数,则返回最终分隔符右侧的每个字符(从右侧开始计数)。
* substring_index 在搜索 delim 时执行区分大小写的匹配。
*
* @group string_funcs
*/
def substring_index(str: Column, delim: String, count: Int): Column = withExpr {
SubstringIndex(str.expr, lit(delim).expr, lit(count).expr)
}
用法
========== df.select(substring(lit("abcdef"), 2, 5)).show() ==========
+-----------------------+
|substring(abcdef, 2, 5)|
+-----------------------+
| bcdef|
+-----------------------+
========== df.select(substring_index(lit("www.shockang.com"), ".", 2)).show() ==========
+---------------------------------------+
|substring_index(www.shockang.com, ., 2)|
+---------------------------------------+
| www.shockang|
+---------------------------------------+
overlay
/**
* 用replace覆盖src的指定部分,从src 的字节位置pos开始并继续len字节。
*
* @group string_funcs
* @since 3.0.0
*/
def overlay(src: Column, replace: Column, pos: Column, len: Column): Column = withExpr {
Overlay(src.expr, replace.expr, pos.expr, len.expr)
}
/**
* 从src 的字节位置pos开始,用replace覆盖src的指定部分。
*
* @group string_funcs
* @since 3.0.0
*/
def overlay(src: Column, replace: Column, pos: Column): Column = withExpr {
new Overlay(src.expr, replace.expr, pos.expr)
}
用法
========== df.select(overlay(lit("abcdef"), lit("abc"), lit(4), lit(1))).show() ==========
+--------------------------+
|overlay(abcdef, abc, 4, 1)|
+--------------------------+
| abcabcef|
+--------------------------+
========== df.select(overlay(lit("abcdef"), lit("abc"), lit(4))).show() ==========
+---------------------------+
|overlay(abcdef, abc, 4, -1)|
+---------------------------+
| abcabc|
+---------------------------+
sentences
/**
* 将字符串拆分为句子数组,其中每个句子是一个单词数组。
*
* @group string_funcs
* @since 3.2.0
*/
def sentences(string: Column, language: Column, country: Column): Column = withExpr {
Sentences(string.expr, language.expr, country.expr)
}
/**
* 将字符串拆分为句子数组,其中每个句子是一个单词数组。
* 使用默认语言环境。
*
* @group string_funcs
* @since 3.2.0
*/
def sentences(string: Column): Column = withExpr {
Sentences(string.expr)
}
用法
========== df.select(sentences(lit("我们都有一个家,名字叫中国"), lit("zh"), lit("CN"))).show() ==========
+---------------------------------------------+
|sentences(我们都有一个家,名字叫中国, zh, CN)|
+---------------------------------------------+
| [[我们都有一个家, 名字叫中国]]|
+---------------------------------------------+
========== df.select(sentences(lit("我们都有一个家,名字叫中国"))).show() ==========
+-----------------------------------------+
|sentences(我们都有一个家,名字叫中国, , )|
+-----------------------------------------+
| [[我们都有一个家, 名字叫中国]]|
+-----------------------------------------+
translate
/**
* 将 src 中的任何字符转换为 replaceString 中的一个字符。
* replaceString 中的字符对应 matchingString 中的字符。
* 当字符串中的任何字符在 matchingString 匹配字符会发生转换。
*
* @group string_funcs
* @since 1.5.0
*/
def translate(src: Column, matchingString: String, replaceString: String): Column = withExpr {
StringTranslate(src.expr, lit(matchingString).expr, lit(replaceString).expr)
}
用法
========== df.select(translate(lit("abcdef"), "def", "123")).show() ==========
+---------------------------+
|translate(abcdef, def, 123)|
+---------------------------+
| abc123|
+---------------------------+
trim
/**
* 修剪指定字符串列两端的空格。
*
* @group string_funcs
* @since 1.5.0
*/
def trim(e: Column): Column = withExpr { StringTrim(e.expr) }
/**
* 修剪指定字符串列 e 两端的指定字符串 trimString。
*
* @group string_funcs
* @since 2.3.0
*/
def trim(e: Column, trimString: String): Column = withExpr {
StringTrim(e.expr, Literal(trimString))
}
用法
========== df.select(trim(lit(" abc "))).show() ==========
+---------------+
|trim( abc )|
+---------------+
| abc|
+---------------+
========== df.select(trim(lit("aaabcaaaa"), "a")).show() ==========
+---------------------------+
|TRIM(BOTH a FROM aaabcaaaa)|
+---------------------------+
| bc|
+---------------------------+
upper
/**
* 将字符串列转换为大写。
*
* @group string_funcs
* @since 1.3.0
*/
def upper(e: Column): Column = withExpr { Upper(e.expr) }
用法
========== df.select(upper($"b")).show() ==========
+--------+
|upper(b)|
+--------+
| AAABB|
+--------+
实践
代码
package com.shockang.study.spark.sql.functions
import com.shockang.study.spark.util.Utils.formatPrint
import org.apache.log4j.{Level, Logger}
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions._
/**
*
* @author Shockang
*/
object StringFunctionsExample {
def main(args: Array[String]): Unit = {
Logger.getLogger("org").setLevel(Level.OFF)
val spark = SparkSession.builder().appName("StringFunctionsExample").master("local[*]").getOrCreate()
import spark.implicits._
val df = Seq(("abc", "aaaBb", "")).toDF("a", "b", "c")
// ascii
formatPrint("""df.select(ascii($"a"), ascii($"b"), ascii($"c")).show()""")
df.select(ascii($"a"), ascii($"b"), ascii($"c")).show()
// base64
formatPrint("""df.select(base64($"a"), base64($"b"), base64($"c")).show()""")
df.select(base64($"a"), base64($"b"), base64($"c")).show()
// concat_ws
formatPrint("""df.select(concat_ws(";", $"a", $"b", $"c")).show()""")
df.select(concat_ws(";", $"a", $"b", $"c")).show()
// decode/encode
formatPrint("""df.select(decode($"a", "utf-8")).show()""")
df.select(decode($"a", "utf-8")).show()
formatPrint("""df.select(encode($"a", "utf-8")).show()""")
df.select(encode($"a", "utf-8")).show()
// format_number/format_string
formatPrint("""df.select(format_number(lit(5L), 4)).show()""")
df.select(format_number(lit(5L), 4)).show()
formatPrint("""df.select(format_number(lit(1.toByte), 4)).show()""")
df.select(format_number(lit(1.toByte), 4)).show()
formatPrint("""df.select(format_number(lit(2.toShort), 4)).show()""")
df.select(format_number(lit(2.toShort), 4)).show()
formatPrint("""df.select(format_number(lit(3.1322.toFloat), 4)).show()""")
df.select(format_number(lit(3.1322.toFloat), 4)).show()
formatPrint("""df.select(format_number(lit(4), 4)).show()""")
df.select(format_number(lit(4), 4)).show()
formatPrint("""df.select(format_number(lit(5L), 4)).show()""")
df.select(format_number(lit(5L), 4)).show()
formatPrint("""df.select(format_number(lit(6.48173), 4)).show()""")
df.select(format_number(lit(6.48173), 4)).show()
formatPrint("""df.select(format_number(lit(BigDecimal("7.128381")), 4)).show()""")
df.select(format_number(lit(BigDecimal("7.128381")), 4)).show()
formatPrint("""df.select(format_string("aa%d%s", lit(123), lit("cc"))).show()""")
df.select(format_string("aa%d%s", lit(123), lit("cc"))).show()
// initcap
formatPrint("""df.select(initcap($"a"), initcap($"b"), initcap($"c")).show()""")
df.select(initcap($"a"), initcap($"b"), initcap($"c")).show()
// instr
formatPrint("""df.select(instr($"b", "aa")).show()""")
df.select(instr($"b", "aa")).show()
// length
formatPrint("""df.select(length($"a"), length($"b"), length($"c")).show()""")
df.select(length($"a"), length($"b"), length($"c")).show()
// lower
formatPrint("""df.select(lower($"b")).show()""")
df.select(lower($"b")).show()
// levenshtein
formatPrint("""df.select(levenshtein($"a", $"b")).show()""")
df.select(levenshtein($"a", $"b")).show()
// locate
formatPrint("""df.select(locate("aa", $"b")).show()""")
df.select(locate("aa", $"b")).show()
formatPrint("""df.select(locate("aa", $"b", 2)).show()""")
df.select(locate("aa", $"b", 2)).show()
// lpad
formatPrint("""df.select(lpad($"a", 10, " ")).show()""")
df.select(lpad($"a", 10, " ")).show()
// ltrim
formatPrint("""df.select(ltrim(lit(" 123"))).show()""")
df.select(ltrim(lit(" 123"))).show()
formatPrint("""df.select(ltrim(lit("aaa123"), "a")).show()""")
df.select(ltrim(lit("aaa123"), "a")).show()
// regexp_extract/regexp_replace
formatPrint("""df.select(regexp_extract(lit("abc123"), "(\\d+)", 1)).show()""")
df.select(regexp_extract(lit("abc123"), "(\\d+)", 1)).show()
formatPrint("""df.select(regexp_replace(lit("abc123"), "(\\d+)", "num")).show()""")
df.select(regexp_replace(lit("abc123"), "(\\d+)", "num")).show()
formatPrint("""df.select(regexp_replace(lit("abc123"), lit("(\\d+)"), lit("num"))).show()""")
df.select(regexp_replace(lit("abc123"), lit("(\\d+)"), lit("num"))).show()
// unbase64
formatPrint("""df.select(unbase64(typedlit(Array[Byte](1, 2, 3, 4)))).show()""")
df.select(unbase64(typedlit(Array[Byte](1, 2, 3, 4)))).show()
// rpad
formatPrint("""df.select(rpad($"a", 10, " ")).show()""")
df.select(rpad($"a", 10, " ")).show()
// repeat
formatPrint("""df.select(repeat($"a", 3)).show()""")
df.select(repeat($"a", 3)).show()
// rtrim
formatPrint("""df.select(rtrim(lit("123 "))).show()""")
df.select(rtrim(lit("123 "))).show()
formatPrint("""df.select(rtrim(lit("123aaa"), "a")).show()""")
df.select(rtrim(lit("123aaa"), "a")).show()
// soundex
formatPrint("""df.select(soundex($"a"), soundex($"b")).show()""")
df.select(soundex($"a"), soundex($"b")).show()
// split
formatPrint("""df.select(split(lit("a;b;c"), ";")).show()""")
df.select(split(lit("a;b;c"), ";")).show()
formatPrint("""df.select(split(lit("a;b;c"), ";", 2)).show()""")
df.select(split(lit("a;b;c"), ";", 2)).show()
formatPrint("""df.select(split(lit("a;b;c"), ";", 0)).show()""")
df.select(split(lit("a;b;c"), ";", 0)).show()
formatPrint("""df.select(split(lit("a;b;c"), ";", -1)).show()""")
df.select(split(lit("a;b;c"), ";", -1)).show()
// substring/substring_index
formatPrint("""df.select(substring(lit("abcdef"), 2, 5)).show()""")
df.select(substring(lit("abcdef"), 2, 5)).show()
formatPrint("""df.select(substring_index(lit("www.shockang.com"), ".", 2)).show()""")
df.select(substring_index(lit("www.shockang.com"), ".", 2)).show()
// overlay
formatPrint("""df.select(overlay(lit("abcdef"), lit("abc"), lit(4), lit(1))).show()""")
df.select(overlay(lit("abcdef"), lit("abc"), lit(4), lit(1))).show()
formatPrint("""df.select(overlay(lit("abcdef"), lit("abc"), lit(4))).show()""")
df.select(overlay(lit("abcdef"), lit("abc"), lit(4))).show()
// sentences
formatPrint("""df.select(sentences(lit("我们都有一个家,名字叫中国"), lit("zh"), lit("CN"))).show()""")
df.select(sentences(lit("我们都有一个家,名字叫中国"), lit("zh"), lit("CN"))).show()
formatPrint("""df.select(sentences(lit("我们都有一个家,名字叫中国"))).show()""")
df.select(sentences(lit("我们都有一个家,名字叫中国"))).show()
// translate
formatPrint("""df.select(translate(lit("abcdef"), "def", "123")).show()""")
df.select(translate(lit("abcdef"), "def", "123")).show()
// trim
formatPrint("""df.select(trim(lit(" abc "))).show()""")
df.select(trim(lit(" abc "))).show()
formatPrint("""df.select(trim(lit("aaabcaaaa"), "a")).show()""")
df.select(trim(lit("aaabcaaaa"), "a")).show()
// upper
formatPrint("""df.select(upper($"b")).show()""")
df.select(upper($"b")).show()
}
}
输出
========== df.select(ascii($"a"), ascii($"b"), ascii($"c")).show() ==========
+--------+--------+--------+
|ascii(a)|ascii(b)|ascii(c)|
+--------+--------+--------+
| 97| 97| 0|
+--------+--------+--------+
========== df.select(base64($"a"), base64($"b"), base64($"c")).show() ==========
+---------+---------+---------+
|base64(a)|base64(b)|base64(c)|
+---------+---------+---------+
| YWJj| YWFhQmI=| |
+---------+---------+---------+
========== df.select(concat_ws(";", $"a", $"b", $"c")).show() ==========
+---------------------+
|concat_ws(;, a, b, c)|
+---------------------+
| abc;aaaBb;|
+---------------------+
========== df.select(decode($"a", "utf-8")).show() ==========
+----------------------+
|stringdecode(a, utf-8)|
+----------------------+
| abc|
+----------------------+
========== df.select(encode($"a", "utf-8")).show() ==========
+----------------+
|encode(a, utf-8)|
+----------------+
| [61 62 63]|
+----------------+
========== df.select(format_number(lit(5L), 4)).show() ==========
+-------------------+
|format_number(5, 4)|
+-------------------+
| 5.0000|
+-------------------+
========== df.select(format_number(lit(1.toByte), 4)).show() ==========
+-------------------+
|format_number(1, 4)|
+-------------------+
| 1.0000|
+-------------------+
========== df.select(format_number(lit(2.toShort), 4)).show() ==========
+-------------------+
|format_number(2, 4)|
+-------------------+
| 2.0000|
+-------------------+
========== df.select(format_number(lit(3.1322.toFloat), 4)).show() ==========
+------------------------+
|format_number(3.1322, 4)|
+------------------------+
| 3.1322|
+------------------------+
========== df.select(format_number(lit(4), 4)).show() ==========
+-------------------+
|format_number(4, 4)|
+-------------------+
| 4.0000|
+-------------------+
========== df.select(format_number(lit(5L), 4)).show() ==========
+-------------------+
|format_number(5, 4)|
+-------------------+
| 5.0000|
+-------------------+
========== df.select(format_number(lit(6.48173), 4)).show() ==========
+-------------------------+
|format_number(6.48173, 4)|
+-------------------------+
| 6.4817|
+-------------------------+
========== df.select(format_number(lit(BigDecimal("7.128381")), 4)).show() ==========
+--------------------------+
|format_number(7.128381, 4)|
+--------------------------+
| 7.1284|
+--------------------------+
========== df.select(format_string("aa%d%s", lit(123), lit("cc"))).show() ==========
+------------------------------+
|format_string(aa%d%s, 123, cc)|
+------------------------------+
| aa123cc|
+------------------------------+
========== df.select(initcap($"a"), initcap($"b"), initcap($"c")).show() ==========
+----------+----------+----------+
|initcap(a)|initcap(b)|initcap(c)|
+----------+----------+----------+
| Abc| Aaabb| |
+----------+----------+----------+
========== df.select(instr($"b", "aa")).show() ==========
+------------+
|instr(b, aa)|
+------------+
| 1|
+------------+
========== df.select(length($"a"), length($"b"), length($"c")).show() ==========
+---------+---------+---------+
|length(a)|length(b)|length(c)|
+---------+---------+---------+
| 3| 5| 0|
+---------+---------+---------+
========== df.select(lower($"b")).show() ==========
+--------+
|lower(b)|
+--------+
| aaabb|
+--------+
========== df.select(levenshtein($"a", $"b")).show() ==========
+-----------------+
|levenshtein(a, b)|
+-----------------+
| 4|
+-----------------+
========== df.select(locate("aa", $"b")).show() ==========
+----------------+
|locate(aa, b, 1)|
+----------------+
| 1|
+----------------+
========== df.select(locate("aa", $"b", 2)).show() ==========
+----------------+
|locate(aa, b, 2)|
+----------------+
| 2|
+----------------+
========== df.select(lpad($"a", 10, " ")).show() ==========
+--------------+
|lpad(a, 10, )|
+--------------+
| abc|
+--------------+
========== df.select(ltrim(lit(" 123"))).show() ==========
+-------------+
|ltrim( 123)|
+-------------+
| 123|
+-------------+
========== df.select(ltrim(lit("aaa123"), "a")).show() ==========
+---------------------------+
|TRIM(LEADING a FROM aaa123)|
+---------------------------+
| 123|
+---------------------------+
========== df.select(regexp_extract(lit("abc123"), "(\\d+)", 1)).show() ==========
+--------------------------------+
|regexp_extract(abc123, (\d+), 1)|
+--------------------------------+
| 123|
+--------------------------------+
========== df.select(regexp_replace(lit("abc123"), "(\\d+)", "num")).show() ==========
+-------------------------------------+
|regexp_replace(abc123, (\d+), num, 1)|
+-------------------------------------+
| abcnum|
+-------------------------------------+
========== df.select(regexp_replace(lit("abc123"), lit("(\\d+)"), lit("num"))).show() ==========
+-------------------------------------+
|regexp_replace(abc123, (\d+), num, 1)|
+-------------------------------------+
| abcnum|
+-------------------------------------+
========== df.select(unbase64(typedlit(Array[Byte](1, 2, 3, 4)))).show() ==========
+---------------------+
|unbase64(X'01020304')|
+---------------------+
| []|
+---------------------+
========== df.select(rpad($"a", 10, " ")).show() ==========
+--------------+
|rpad(a, 10, )|
+--------------+
| abc |
+--------------+
========== df.select(repeat($"a", 3)).show() ==========
+------------+
|repeat(a, 3)|
+------------+
| abcabcabc|
+------------+
========== df.select(rtrim(lit("123 "))).show() ==========
+-------------+
|rtrim(123 )|
+-------------+
| 123|
+-------------+
========== df.select(rtrim(lit("123aaa"), "a")).show() ==========
+----------------------------+
|TRIM(TRAILING a FROM 123aaa)|
+----------------------------+
| 123|
+----------------------------+
========== df.select(soundex($"a"), soundex($"b")).show() ==========
+----------+----------+
|soundex(a)|soundex(b)|
+----------+----------+
| A120| A100|
+----------+----------+
========== df.select(split(lit("a;b;c"), ";")).show() ==========
+-------------------+
|split(a;b;c, ;, -1)|
+-------------------+
| [a, b, c]|
+-------------------+
========== df.select(split(lit("a;b;c"), ";", 2)).show() ==========
+------------------+
|split(a;b;c, ;, 2)|
+------------------+
| [a, b;c]|
+------------------+
========== df.select(split(lit("a;b;c"), ";", 0)).show() ==========
+------------------+
|split(a;b;c, ;, 0)|
+------------------+
| [a, b, c]|
+------------------+
========== df.select(split(lit("a;b;c"), ";", -1)).show() ==========
+-------------------+
|split(a;b;c, ;, -1)|
+-------------------+
| [a, b, c]|
+-------------------+
========== df.select(substring(lit("abcdef"), 2, 5)).show() ==========
+-----------------------+
|substring(abcdef, 2, 5)|
+-----------------------+
| bcdef|
+-----------------------+
========== df.select(substring_index(lit("www.shockang.com"), ".", 2)).show() ==========
+---------------------------------------+
|substring_index(www.shockang.com, ., 2)|
+---------------------------------------+
| www.shockang|
+---------------------------------------+
========== df.select(overlay(lit("abcdef"), lit("abc"), lit(4), lit(1))).show() ==========
+--------------------------+
|overlay(abcdef, abc, 4, 1)|
+--------------------------+
| abcabcef|
+--------------------------+
========== df.select(overlay(lit("abcdef"), lit("abc"), lit(4))).show() ==========
+---------------------------+
|overlay(abcdef, abc, 4, -1)|
+---------------------------+
| abcabc|
+---------------------------+
========== df.select(sentences(lit("我们都有一个家,名字叫中国"), lit("zh"), lit("CN"))).show() ==========
+---------------------------------------------+
|sentences(我们都有一个家,名字叫中国, zh, CN)|
+---------------------------------------------+
| [[我们都有一个家, 名字叫中国]]|
+---------------------------------------------+
========== df.select(sentences(lit("我们都有一个家,名字叫中国"))).show() ==========
+-----------------------------------------+
|sentences(我们都有一个家,名字叫中国, , )|
+-----------------------------------------+
| [[我们都有一个家, 名字叫中国]]|
+-----------------------------------------+
========== df.select(translate(lit("abcdef"), "def", "123")).show() ==========
+---------------------------+
|translate(abcdef, def, 123)|
+---------------------------+
| abc123|
+---------------------------+
========== df.select(trim(lit(" abc "))).show() ==========
+---------------+
|trim( abc )|
+---------------+
| abc|
+---------------+
========== df.select(trim(lit("aaabcaaaa"), "a")).show() ==========
+---------------------------+
|TRIM(BOTH a FROM aaabcaaaa)|
+---------------------------+
| bc|
+---------------------------+
========== df.select(upper($"b")).show() ==========
+--------+
|upper(b)|
+--------+
| AAABB|
+--------+















 2553
2553











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









