






1.文件系统操作
2.文件内容操作
1字节流
以字节为单位读写数据
InputStream
不能实例化,这个东西对应的不仅仅是文件、还有控制台、网卡等。
2字符流
以字符为单位读写数据
1)通过构造方法,打开文件
2)通过read方法读文件内容
3)通过write方法写文件内容
4)通过close方法关闭文件
Reader
Writer
构造方法填写参数:
1.填写字符串表示的文件路径(绝对/相对路径均可)
2.填写File对象
抛出异常IOExcepton的异常
import java.io.*;
public class Test {
public static void main(String[] args) throws IOException {
File file=new File("D:/1");
InputStream inputStream=new FileInputStream(file);
inputStream.read();
}
}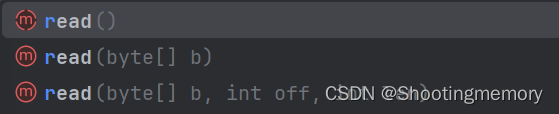
第一个是一个字节一个字节读,读取到的内容通过返回值表示,这里的返回值是int类型。
为什么是int类型呢?
从原则上来说,“字节”这样的概念,本身应该是“无符号”但是byte类型,本身有符号此处通过int类行就可以确保读出来的字节,都是正数,按照"无符号"的方式来处理了!
那为什么用short,而是用int?
但凡使用short的场景,都建议大家使用int.类似的,但凡使用float的场景,都建议大家使用double.
由于cpu一次性处理的字节数越来越多,这时候使用short,就还是要short转换为int来处理
第二个是一个字节组一个字节组的读byte[]
第二个版本,读到的数据往整个数组填充
byte[]buffer=new byte[1024];
inputStream.read(buffer);输出型参数,先准备空数组,然后在方法执行完毕后,把读到的数据填写到byte数组中。
一次取多少取决于数组的长度(这里☞1024),read尽量把数组填满
返回值int,这次表示读取到多少个字节了
光标会回到首行,字符流,
字节就是utf8编码
字符流,基于字节流实现,
上述两个api中
read() 频次高,一次读东西少,下面的操作频次低,一个读的东西多。
read(bytes)低效操作次数越少,整体速度就越快
第三个也是字节组的读,但是第二个填入开始的位置,字节长度。
第三个版本,只能填充数组的一部分,从offset下标开始,最多填充len这么长.
关闭文件close
定时炸弹
打开文件.
打开文件的时候,会在操作系统内核,PCB结构体中,给文件描述符表”添加一个元素,这个元素就是表示当前打开的文件相关信息。当打开过多的时候
进程打开的文件会记录这个地方
文件描述符表,里面的长度存在上限,这个东西不能自动扩容。占满后,尝试打开,就会打开文件失败。就会类似于内存泄露成为文件资源泄露。
当执行close的时候,就会释放这个文件描述符表上对应的元素
文件描述表的长度有上限
可以用finally防止前面异常或者returrn,此时close就执行不到了
try {
byte[] buffer = new byte[1024];
int n= inputStream.read(buffer);
for(int i=0;i<n;i++){
System.out.println();
}
}finally {
inputStream.close();
}更加优雅,低耦合
try ( InputStream inputStream=new FileInputStream(file);){
byte[] buffer = new byte[1024];
int n= inputStream.read(buffer);
for(int i=0;i<n;i++){
System.out.println();
}
}OutputStream
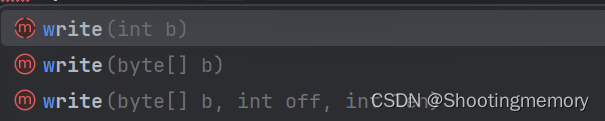 版本一:一次write一个字节.参数是int类型
版本一:一次write一个字节.参数是int类型
版本二:一次write若干字节.会把参数数组里所有的字节都写入文件中
版本三:一次write若干字节.把数组从offset下标开始,连续写len个字节.
按照写方式打开文件的时候,会把文件原有内容清空掉
(不是write清空的,而是打开操作清空的)
OutputStream outputStream=new FileOutputStream("D:/2/test.txt",true);
outputStream.write(buffer);
outputStream.close();这样就可以实现追加写的方式了。
char用的时候unicode
String 里面则默认utf8.
比如当你写String s =“你好”s.charAt(1)=>char(好)
String内部是使用长度为6这样的byte数组来存储.
示例1
扫描指定目录,并找到名称中包含指定字符的所有普通文件(不包含目录),并且后续询问用户是否要删除该文件
前提:给定一个目录,给定一个查询词
写程序,搜索说,看哪个文件的名字里带有这个查询词把匹配的结果。
import java.io.File;
import java.util.Scanner;
public class Test1 {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
System.out.println("输入搜索的目录");
String rootPath = sc.next();
System.out.println("输入查询的单词");
String searchPath = sc.next();
File root = new File(rootPath);
if (!root.isDirectory()) {
System.out.println("输入路径非法");
return;
}
searchFile(root,searchPath);
}
private static void searchFile(File root, String searchPath) {{
File[] files = root.listFiles();
if (files == null) {
return;
}
for (File file : files) {
if (file.isFile()) {
String fileName = file.getName();
if (fileName.contains(searchPath)) {
System.out.println(""+file.getAbsolutePath());
} else if (file.isDirectory()) {
searchFile(file,searchPath);
}
}
}
}
}
}
示例2
复制一个文件
输入一个路径,表示要被复制的文件
输入另一个路径,表示要复制到的目标目录
import java.io.*;
import java.sql.SQLOutput;
import java.util.Scanner;
public class Test2 {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
System.out.println("请输入想要输入的文件路径");
String srcpath = sc.next();
System.out.println("请输入你想要复制的文件路径");
String destpath = sc.next();
File srcfile = new File(srcpath);
if(!srcfile.isFile()){
System.out.println("你输入的文件不合法");
return;
}
File destfile = new File(destpath);
if(!destfile.getParentFile().isDirectory()){//判断复制的文件的母类是否是目录,如果不是的话就说明他不合法,否则就是合法的
//用getParentFile()返回的对象是File对象而getParentFile()返回的是字符串路径(String)
System.out.println("输入的复制文件路径不合法");
return;
}
try(InputStream inputStream = new FileInputStream(srcfile);
OutputStream outputStream=new FileOutputStream(destfile)) //try结束的时候,自动close
{
while(true){
byte []type= new byte[1024];
int n=inputStream.read(type);
if(n==-1){
return;
}
outputStream.write(type,0,n);
}
} catch (FileNotFoundException e) {
throw new RuntimeException(e);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
在此处考虑过文件不存在的情况,用的是
OutputStream outputStream=new FileOutputStream(destfile)由于OutputStream会在文件打开的时候自动创建文件所以就会解决这个问题,当然用createNewFile也是可以的,但是在此处只是画蛇添足的操作。
只有OutputStream可以在文件的不存在的时候创建文件而InputStream不可以
示例3
输入一个路径
在输入一个查询词
就会在这个路径中,文件内容,包含这个查询词这里的文件
import java.io.*;
import java.util.Scanner;
public class Test3 {
public static void main(String[] args) {
Scanner scanner=new Scanner(System.in);
System.out.println("输入搜索的路径");
String path=scanner.next();
System.out.println("输入的查询单词");
String searchWord=scanner.next();
File file=new File(path);
if(!file.isDirectory()){
System.out.println("输入的路径非法");
return;
}
search(file,searchWord);
}
public static void search(File file,String searchWord){
File[] files=file.listFiles();
if(files==null){
return;
}
for(File f:files){
if(f.isFile()){
matchword(f,searchWord);
} else if (f.isDirectory()) {
search(f, searchWord);
}
}
}
private static void matchword(File f, String searchWord) {
try (Reader reader = new FileReader(f)){
StringBuffer stringBuffer=new StringBuffer();
while (true){
int c=reader.read();
if(c==-1){
break;
}
stringBuffer.append((char)c);
}
if(stringBuffer.indexOf(searchWord)>=0){
System.out.println("找到了匹配结果路径是"+f.getAbsolutePath());
}
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
文件操作
文件系统操作
文件内容操作















 10万+
10万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









