








ShowMeAI日报系列全新升级!覆盖AI人工智能 工具&框架 | 项目&代码 | 博文&分享 | 数据&资源 | 研究&论文 等方向。点击查看 历史文章列表,在公众号内订阅话题 #ShowMeAI资讯日报,可接收每日最新推送。点击 专题合辑&电子月刊 快速浏览各专题全集。点击 这里 回复关键字 日报 免费获取AI电子月刊与资料包。
💰 Autowise.ai 仙途智能完成两亿元 B2 轮融资,全球业务逆势猛
仙途智能 Autowise.ai 以『人工智能』和『自动驾驶』技术为核心,2017年在上海组建了中国最早的一批 robotaxi 车队,2019年获得自动驾驶卡车测试牌照,并率先将自动驾驶技术应用到城市环卫领域,发布了全球首支涵盖1-18吨不同车型、并能应用于复杂作业场景的自动驾驶清扫车队,累计真实运营里程超百万公里。本轮2亿元融资由杉杉创投、欧普资本、老股东天奇资本与创始人黄超参与投资,融资将主要用于自动驾驶技术研发与商业化运营投入,以及海内外市场规模的扩张。

工具&框架
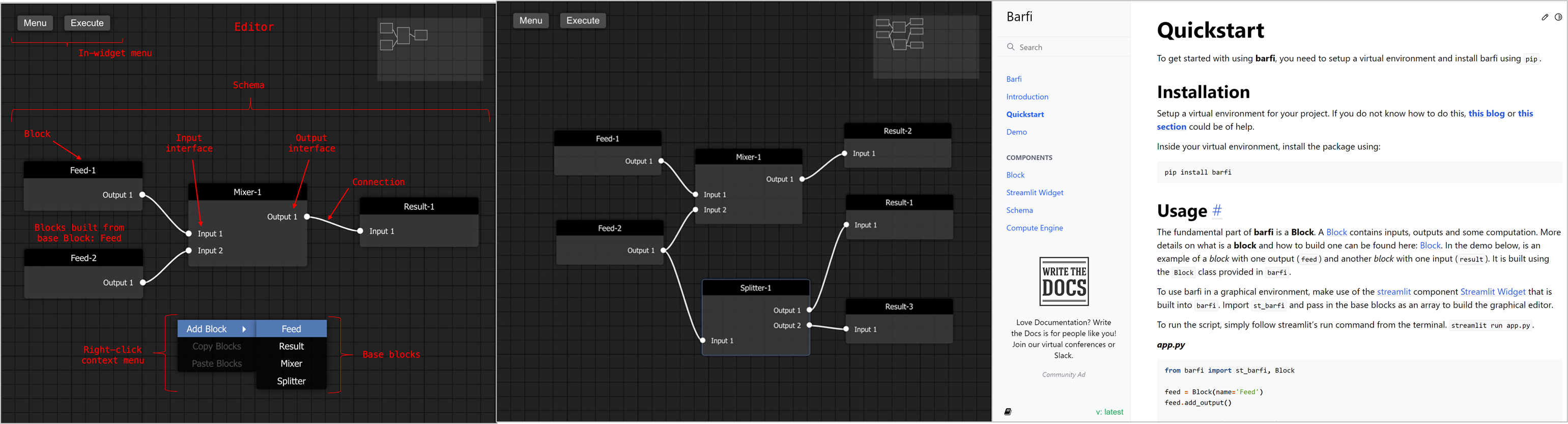
🚧 『Barfi』基于 Python 流程的编程环境,提供了一个图形化的编程环境
https://github.com/krish-adi/barfi
使用 barfi.Blocks 创建一个 Schema,生成并连接各 Block,编辑器右上方的小地图显示了当前布局。点击编辑器 Execute 按钮,在 compute_engine=True 时,创建的 schema 将与 Block 一起被返回。一个程序就这样完成啦!界面简洁、操作简单,还可以快速集成到 Python 工作流!你真的不心动嘛~
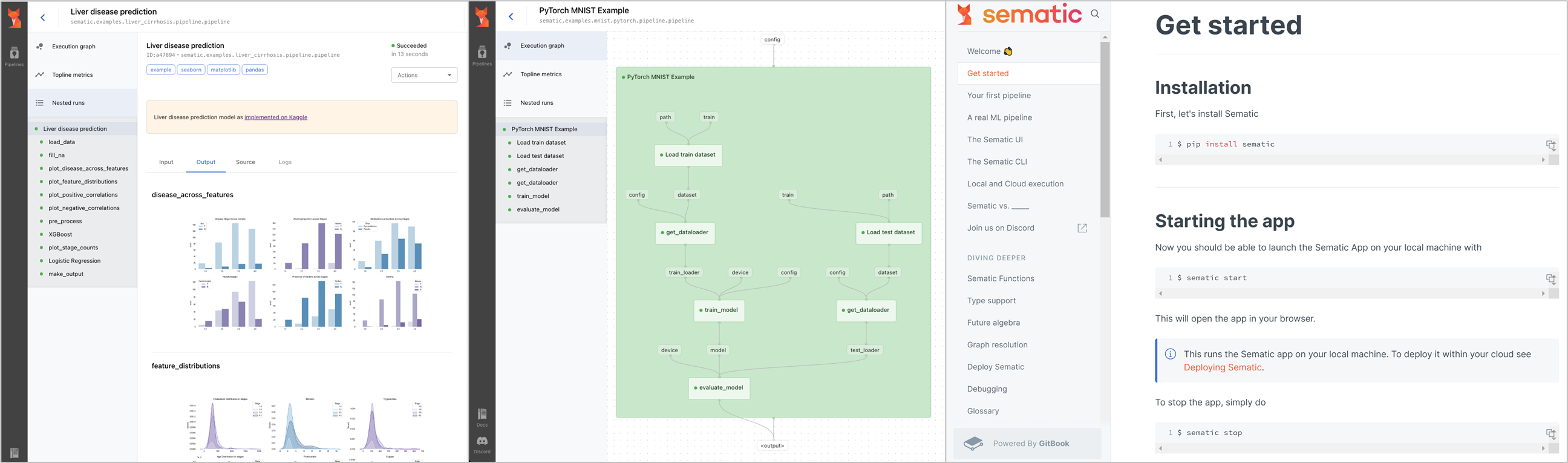
🚧 『sematic』一个开源的 ML 流程开发工具箱
https://github.com/sematic-ai/sematic
sematic 可以将搭建 ML Pipline 原型、部署生产的时间,从几周压缩到几天之内(可以当作 Kubeflow Pipelines 的『替身』)。作为一款开源的开发工具包,sematic 在开发/运行 ML Pipeline时使用本地 Python 函数,并且能够监控 / 可视化 / 跟踪所有 Pipeline 步骤的输入输出。
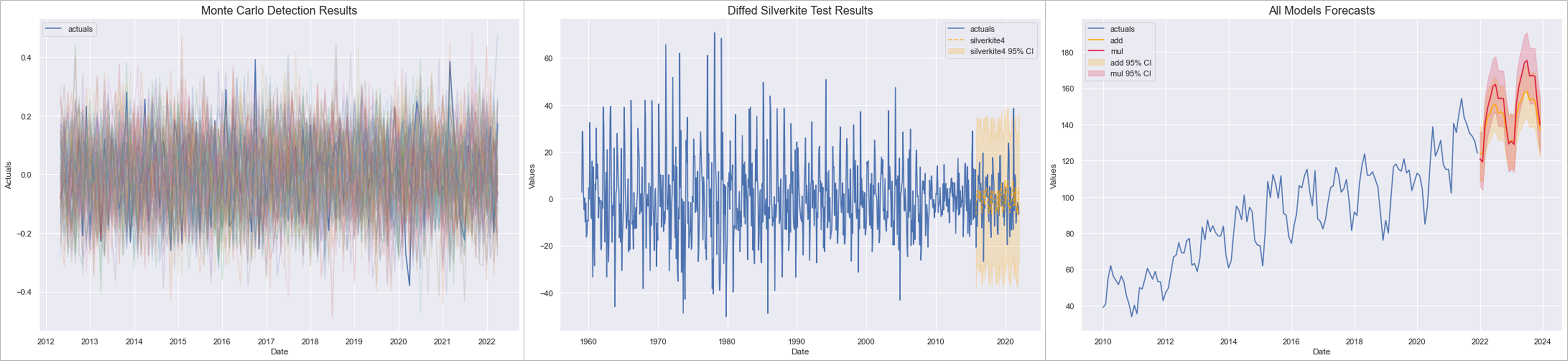
🚧 『Scalecast』时序数据预测库
https://github.com/mikekeith52/scalecast
Scalecast 是一个轻量级的建模应用,可以快速地应用、调优和验证预测问题的各类模型。如果你需要为几条业务线(成百上千的数据片)提供预测结果,那试试 scalecast 吧!相比于简单的线性回归或者一些快速程序,scalecast 可以产生动态的预测结果,而不是一步预测的平均值,避免了『测试集上准确率很好,但不能推广到真实数据』的尴尬局面。
🚧 『stopes』为机器翻译研究准备数据(单语预处理,双文本挖掘等)的库
https://github.com/facebookresearch/stopes
NLLB(No Language Left Behind,无语言障碍)是 Meta 首创的人工智能突破项目,旨在为 200 多种语言提供一对一的高质量翻译。stopes 作为 NLLB 项目的一部分,可用于创建干净的单语数据(monolingual data)、挖掘双文本、通过模块化的 API 快速构建和复制数据挖掘管道等。

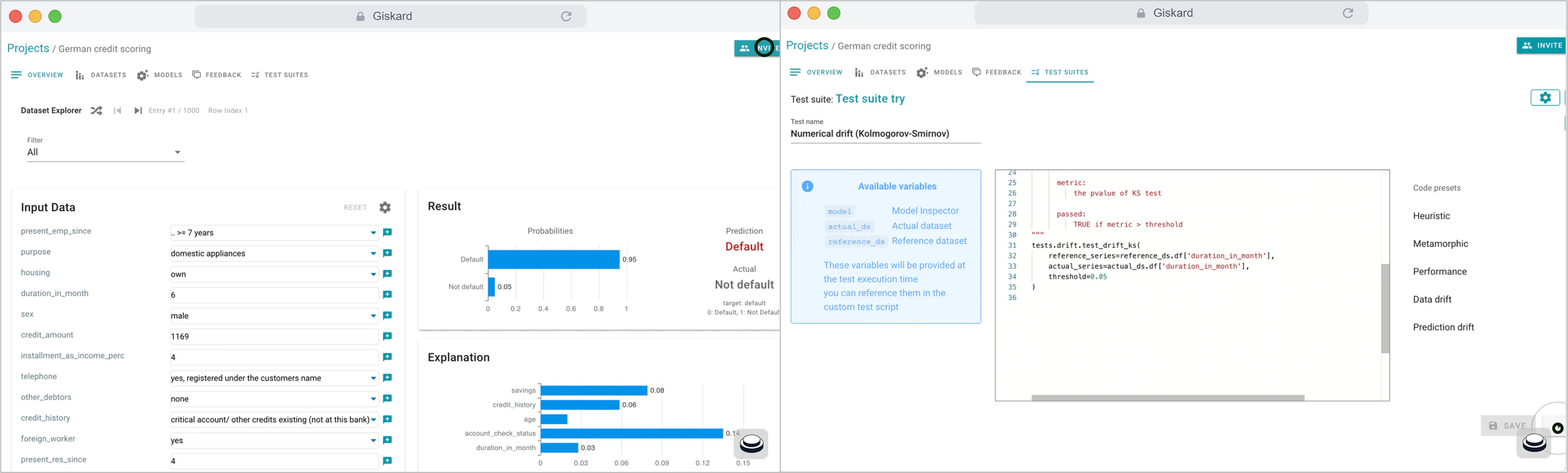
🚧 『Giskard』面向 ML 团队的开源 CI/CD 平台
https://github.com/Giskard-AI/giskard
项目&代码
🏆『2022 搜狐校园算法大赛』NLP 赛道第1名开源方案(实验代码)
https://github.com/jzm-chairman/sohu2022-nlp-rank1
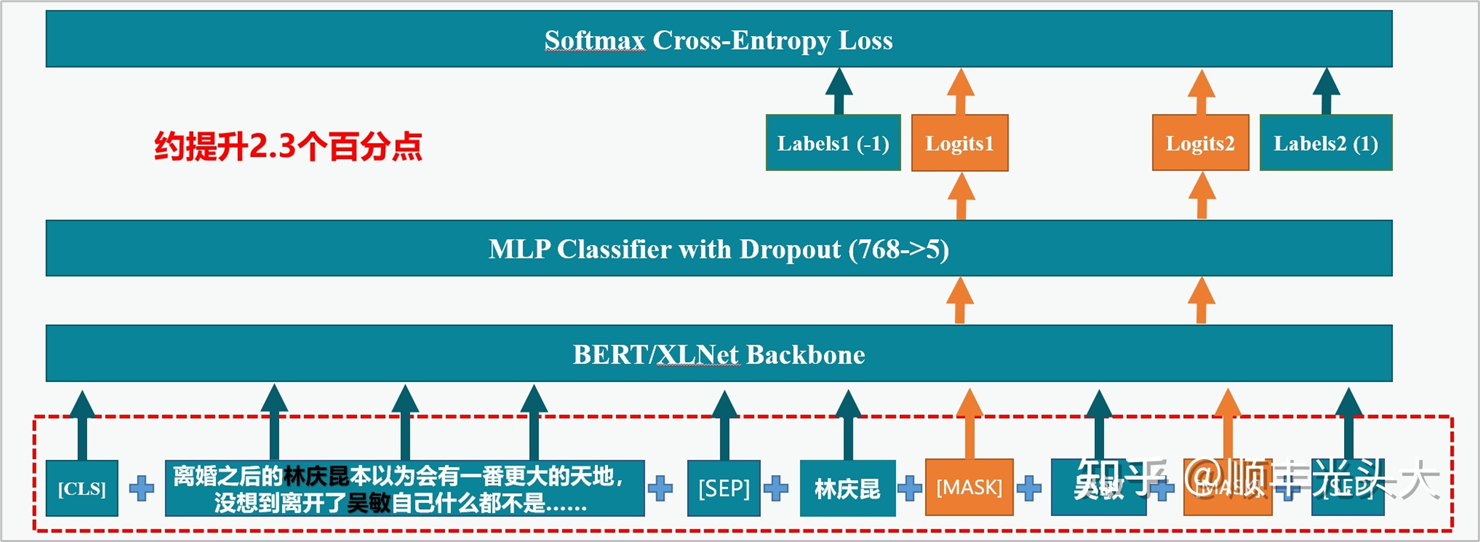
模型的整体架构就是一个普通的分类模型,在预训练的 BERT 或 XLNet 模型基础上增加了简单的MLP分类器。这个思路的要点在于改变数据输入的方式,利用 BERT 和 XLNet 作为 Masked Language Model 的性质,以 [SEP] 符号为界,第一段为文本输入,第二段按顺序输入所有实体,实体之间以 [MASK] 进行分隔,这 个[MASK] 标签通过 BERT Encoder 得到的语义向量就代表对应实体的情感极性。将所有 [MASK] 位置的语义向量通过分类器即可并行对所有的实体进行分类。更多作者解读可以看 《这篇文章 https://zhuanlan.zhihu.com/p/533808475》 。
博文&分享
📚 『Probabilistic Numerics』概率数值方法 免费书籍
https://www.probabilistic-numerics.org/textbooks/
数值算法从『可计算的量』中近似地计算出『难以处理的量』,或者说,从数据中推断出一个潜在的量。因此计算程序可被视作 learning machine,使用贝叶斯推理来建立更灵活有效的计算算法。概率数值计算正式确立了『机器学习』和『应用数学』之间的联系。本书提供了大量的背景材料(还有数据、工作实例、练习及解答),更适用于AI、CS、统计学、应用数学的研究生。(公众号『ShowMeAI研究中心』回复『日报』获取该书电子版)

📚 『Object Detection State of the Art 2022』2022目标检测 前沿博文
https://medium.com/@pedroazevedo6/object-detection-state-of-the-art-2022-ad750e0f6003
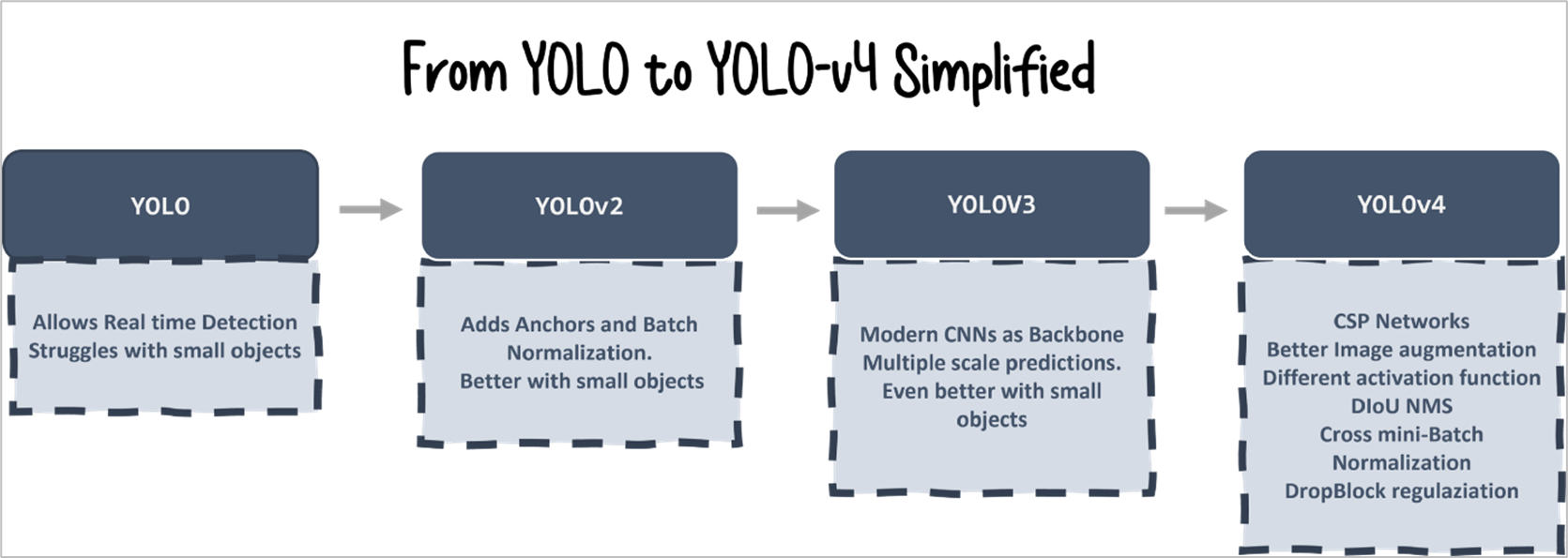
深度学习技术蓬勃发展,物体检测也随之成为热门话题。本文介绍了最新的物体检测技术现状。本文是作者 Pedro Azevedo『Object Detection and YOLO』系列的 Part 1,另外两篇『Part 2: From YOLO to YOLOv4』、『Part 3: What is the Best YOLO?』 也很不错,推荐阅读!


数据&资源
🔥『2023届互联网校招信息』提前批、秋招、春招 信息资源汇总
https://github.com/CARLOSGP2021/2023-campus-recruitment-for-IT-industry
研究&论文

可以点击 这里 回复关键字 日报,免费获取整理好的论文合辑。
科研进展
- 2022.07.06『计算机视觉』YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors
- 2022.07.06『计算机视觉』Bridging the Gap between Object and Image-level Representations for Open-Vocabulary Detection
- 2022.07.06『计算机视觉』DCT-Net: Domain-Calibrated Translation for Portrait Stylization
- 2022.07.06『语音』Speech Denoising in the Waveform Domain with Self-Attention
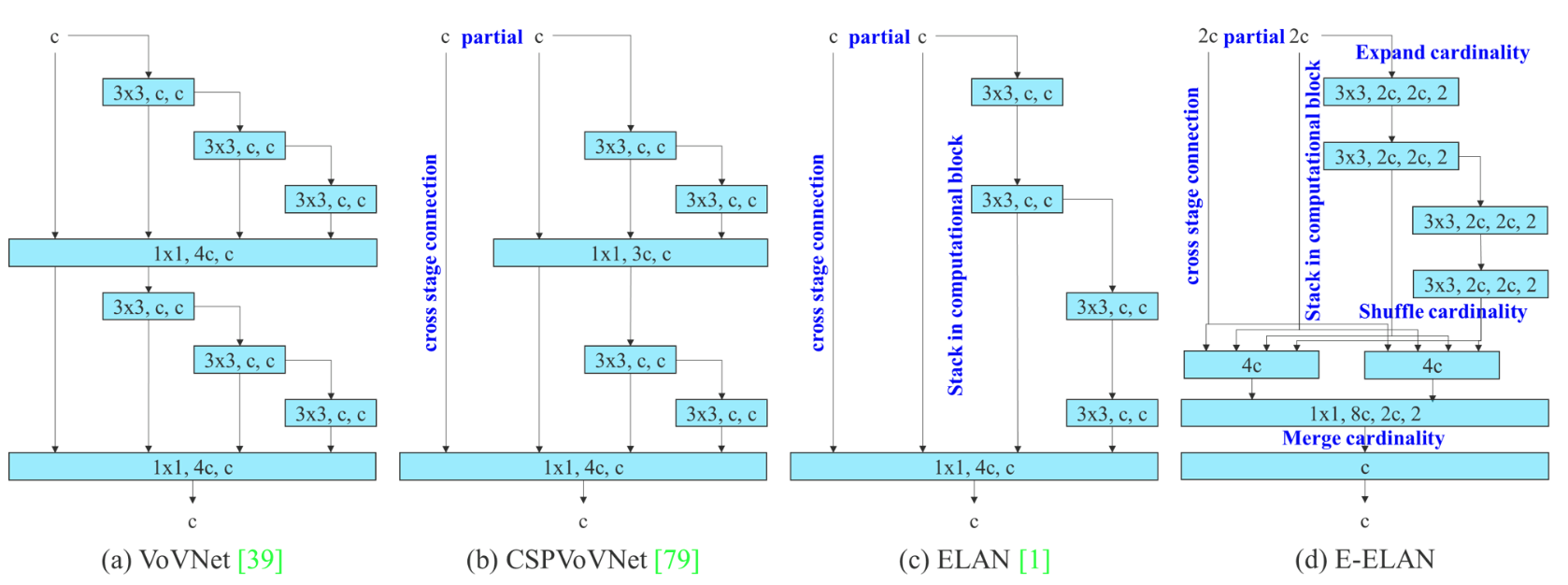
⚡ 论文:YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors
论文标题:YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors
论文时间:6 Jul 2022
所属领域:计算机视觉
对应任务:Object Detection,Real-Time Object Detection,目标检测,实时目标检测
论文地址:https://arxiv.org/abs/2207.02696
代码实现:https://github.com/wongkinyiu/yolov7 , https://github.com/pjreddie/darknet , https://github.com/AlexeyAB/darknet
论文作者:Chien-Yao Wang, Alexey Bochkovskiy, Hong-Yuan Mark Liao
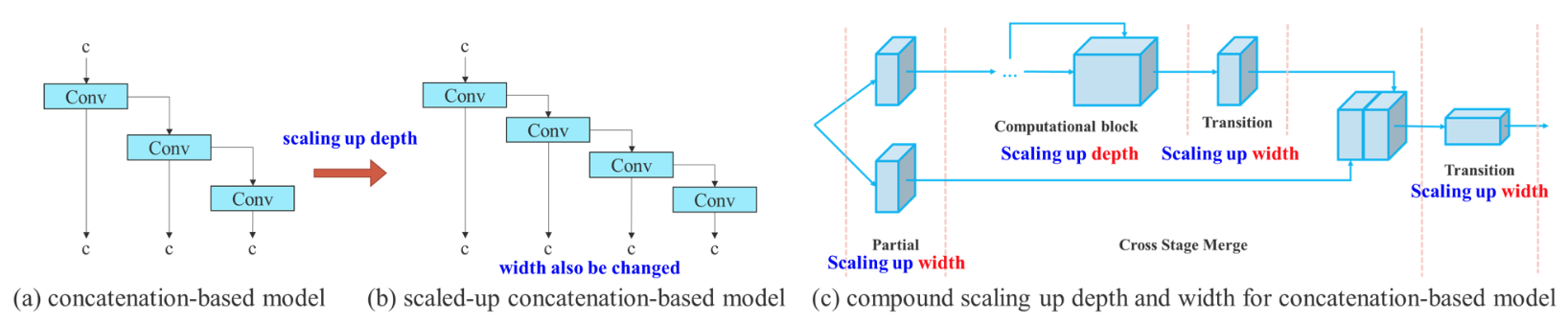
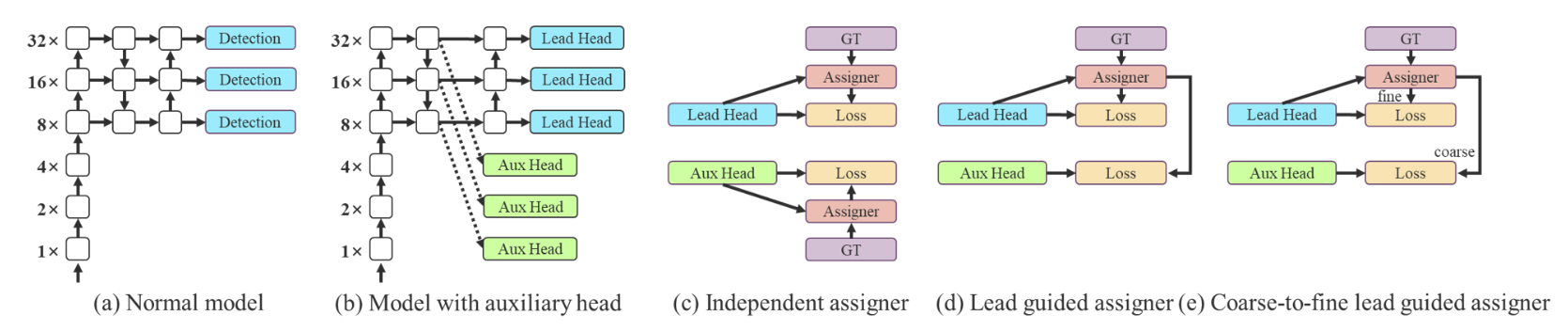
论文简介:YOLOv7 surpasses all known object detectors in both speed and accuracy in the range from 5 FPS to 160 FPS and has the highest accuracy 56. 8% AP among all known real-time object detectors with 30 FPS or higher on GPU V100./YOLOv7在5 FPS到160 FPS的范围内,在速度和准确度上都超过了所有已知的物体检测器,并且在GPU V100上30 FPS或更高的所有已知实时物体检测器中具有最高的准确度56。在GPU V100上30 FPS或更高的所有已知的实时物体检测器中,YOLOv7具有最高的准确度56.8%AP。
论文摘要:YOLOv7在5FPS到160FPS范围内的速度和精度都超过了所有已知的物体检测器,在GPU V100上所有已知的30FPS或更高的实时物体检测器中具有最高精度56.8%AP。YOLOv7-E6物体检测器(56 FPS V100, 55.9% AP)比基于transformer的检测器SWIN-L Cascade-Mask R-CNN(9.2 FPS A100, 53. 9%)的速度和2%的准确率,以及基于卷积的检测器ConvNeXt-XL级联掩码R-CNN(8.6 FPS A100, 55.2% AP)的速度和0.7%的准确率,以及YOLOv7的表现。YOLOR、YOLOX、Scaled-YOLOv4、YOLOv5、DETR、Deformable DETR、DINO-5scale-R50、ViT-Adapter-B和其他许多物体检测器在速度和准确度方面的表现。此外,我们只在MS COCO数据集上从头开始训练YOLOv7,不使用任何其他数据集或预训练的权重。源代码发布在https://github.com/WongKinYiu/yolov7 。
⚡ 论文:Bridging the Gap between Object and Image-level Representations for Open-Vocabulary Detection
论文标题:Bridging the Gap between Object and Image-level Representations for Open-Vocabulary Detection
论文时间:7 Jul 2022
所属领域:计算机视觉
对应任务:Open Vocabulary Object Detection,Zero-Shot Object Detection,开放词汇目标检测,零样本目标检测
论文地址:https://arxiv.org/abs/2207.03482
代码实现:https://github.com/hanoonaR/object-centric-ovd
论文作者:Hanoona Rasheed, Muhammad Maaz, Muhammad Uzair Khattak, Salman Khan, Fahad Shahbaz Khan
论文简介:Two popular forms of weak-supervision used in open-vocabulary detection (OVD) include pretrained CLIP model and image-level supervision./在开放词汇检测(OVD)中使用的两种流行的弱监督形式包括预训练的CLIP模型和图像级监督。
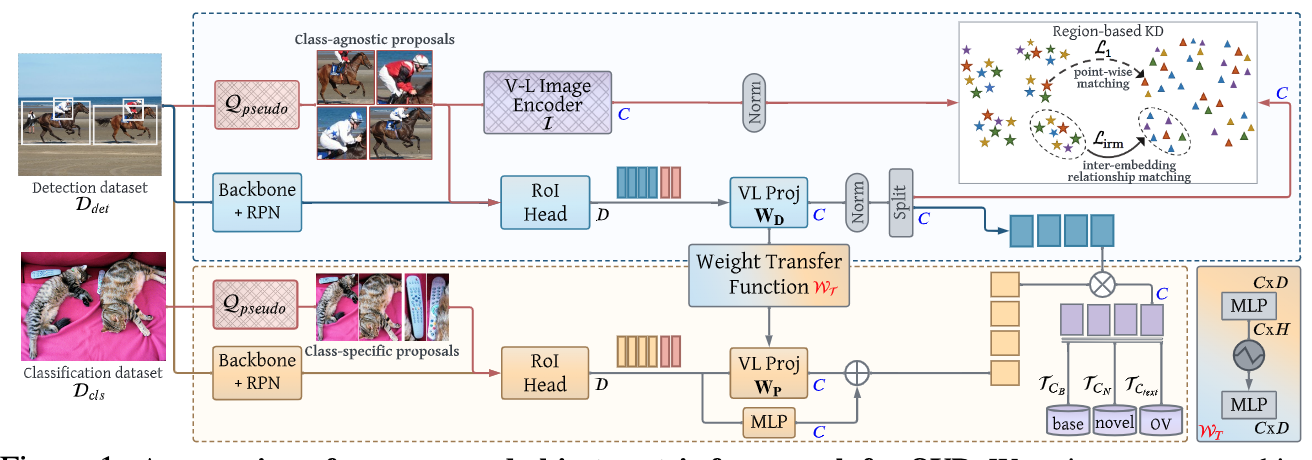
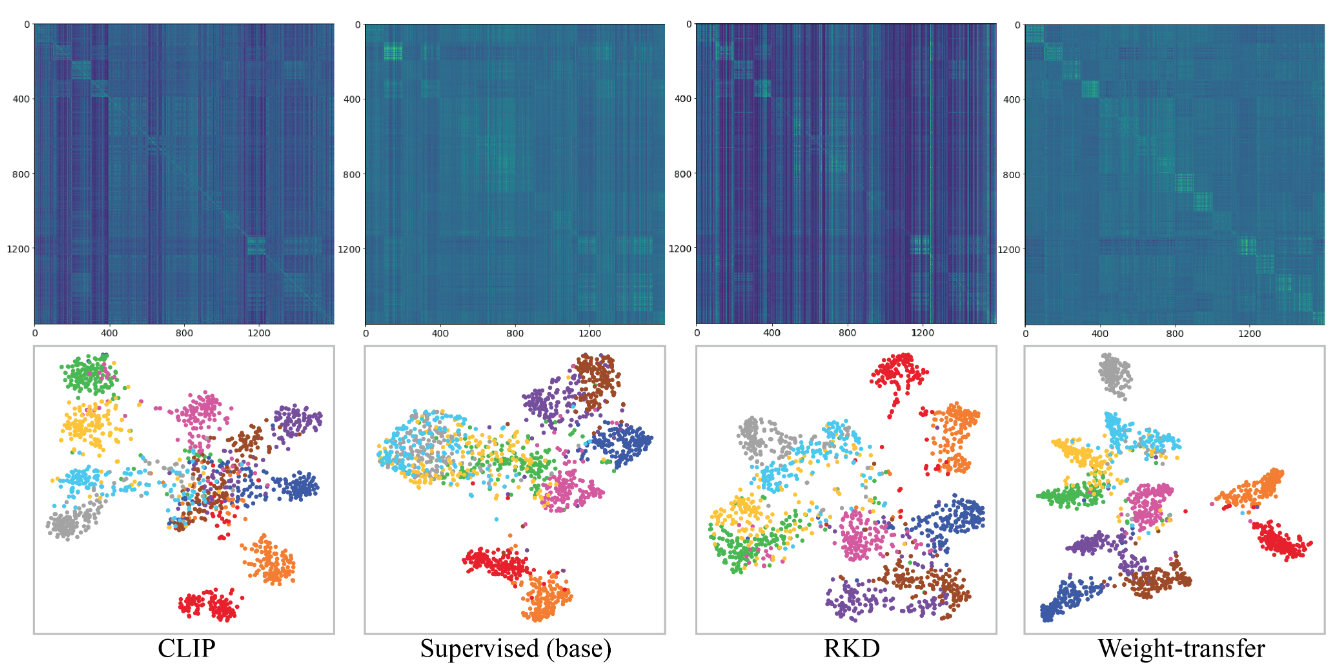
论文摘要:现有的开放词汇物体检测器通常通过利用不同形式的弱监督来扩大其词汇量。这有助于在推理时对新的物体进行概括。在开放词汇检测(OVD)中使用的两种流行的弱监督形式包括预训练的CLIP模型和图像级监督。我们注意到,这两种监督模式对于检测任务来说都不是最理想的排列方式。CLIP是用图像-文本对进行训练的,缺乏对物体的精确定位,而图像层面的监督则是用启发式方法,不能准确地指定局部物体区域。在这项工作中,我们建议通过对CLIP模型的语言嵌入进行以物体为中心的排列来解决这个问题。此外,我们通过使用一个伪标签过程,在视觉上将物体接地,提供高质量的物体建议,并在训练过程中帮助扩大词汇量。我们通过一个新的权重转移函数在上述两种对象对齐策略之间建立了一座桥梁,该函数聚合了它们的互补性优势。从本质上讲,所提出的模型试图在OVD环境中最小化以物体和图像为中心的表示之间的差距。在COCO基准测试中,我们提出的方法在新的类别上实现了40.3的AP50,比以前的最佳性能绝对增加了11.9。对于LVIS,我们超过了最先进的ViLD模型,在少样本的类别上有5.0的掩码AP,总体上有3.4。代码:https://bit.ly/3byZoQp 。
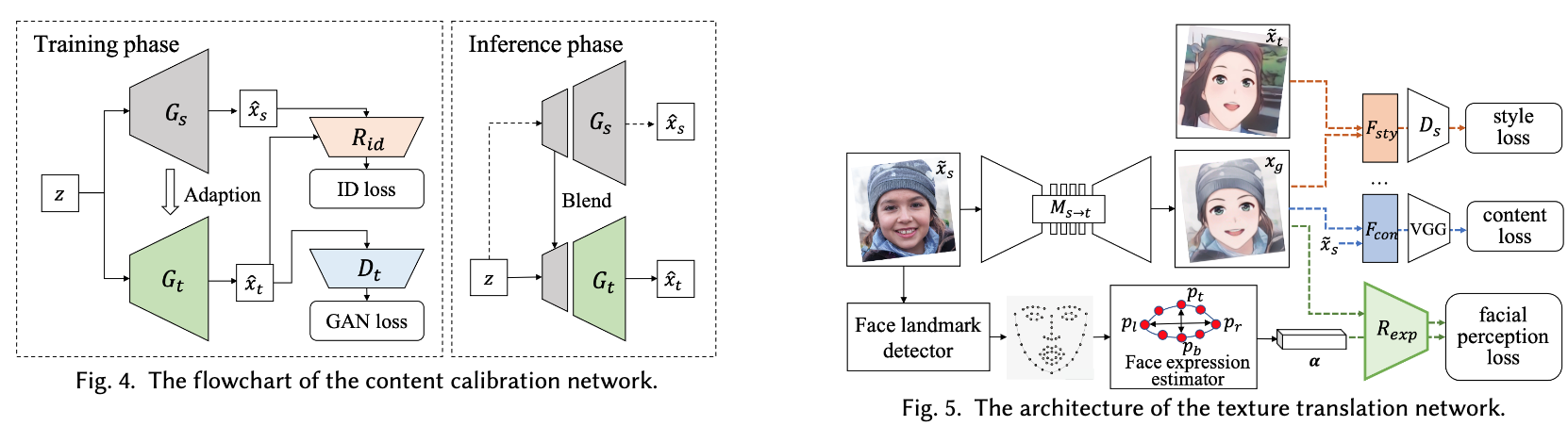
⚡ 论文:DCT-Net: Domain-Calibrated Translation for Portrait Stylization
论文标题:DCT-Net: Domain-Calibrated Translation for Portrait Stylization
论文时间:6 Jul 2022
所属领域:计算机视觉
对应任务:Few-Shot Learning,Style Transfer,Translation,少样本学习,神经风格转换
论文地址:https://arxiv.org/abs/2207.02426
代码实现:https://github.com/menyifang/dct-net
论文作者:Yifang Men, Yuan YAO, Miaomiao Cui, Zhouhui Lian, Xuansong Xie
论文简介:This paper introduces DCT-Net, a novel image translation architecture for few-shot portrait stylization./本文介绍了DCT-Net,一种用于少数照片肖像风格化的新型图像转换架构。
论文摘要:本文介绍了DCT-Net,一种用于少数照片的肖像风格化的新型图像翻译架构。考虑到有限的风格样本(100个),新架构可以产生高质量的风格转换结果,具有合成高保真内容的先进能力和处理复杂场景(如遮挡和配件)的强大通用性。此外,它还能通过一个由部分观察(即风格化的头部)训练的优雅的评估网络实现全身图像的转换。基于几张照片学习的风格转换是具有挑战性的,因为学到的模型很容易在目标领域变得过度拟合,这是因为只有少数训练例子形成的偏向分布。本文旨在通过采用 "先校准,后翻译 "的关键思想来处理这一挑战,并通过以局部为重点的翻译来探索增强的全局结构。具体来说,拟议的DCT-Net由三个模块组成:一个内容适配器借用源照片的强大先验来校准目标样本的内容分布;一个几何扩展模块使用仿生变换来释放空间语义约束;一个纹理翻译模块利用校准分布产生的样本来学习细粒度的转换。实验结果表明,所提出的方法在头部风格化方面优于目前的技术水平,而且在具有自适应变形的全图像翻译方面也很有效。



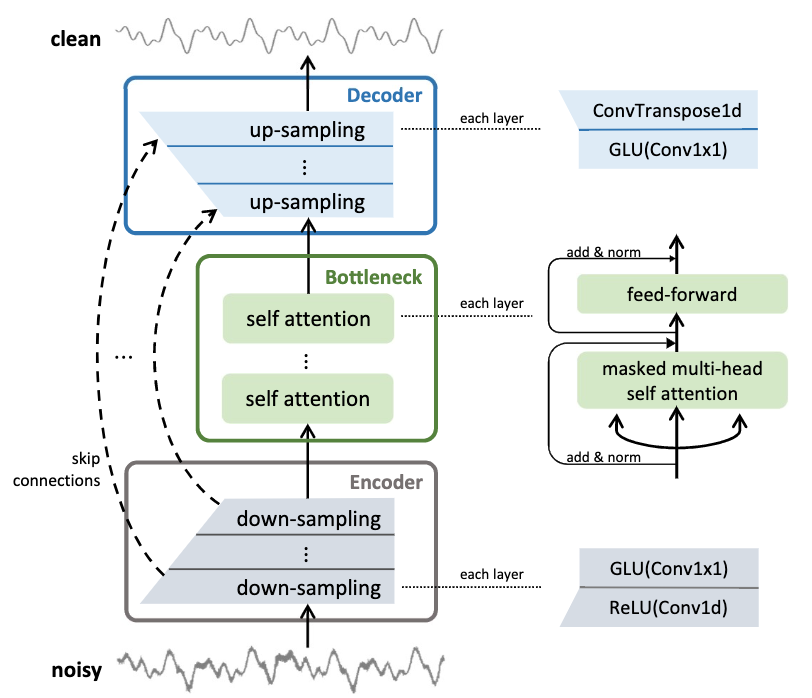
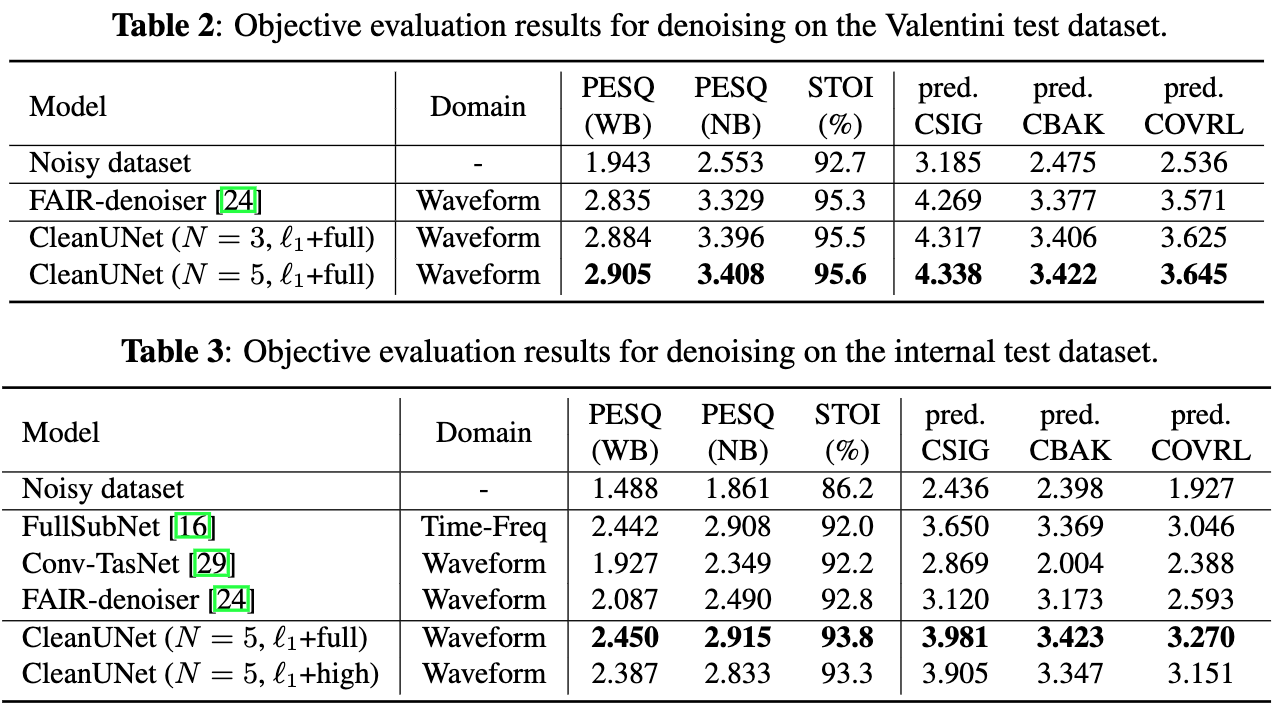
⚡ 论文:Speech Denoising in the Waveform Domain with Self-Attention
论文标题:Speech Denoising in the Waveform Domain with Self-Attention
论文时间:15 Feb 2022
所属领域:语音
对应任务:Denoising,Speech Denoising,降噪,语音降噪
论文地址:https://arxiv.org/abs/2202.07790
代码实现:https://github.com/nvidia/cleanunet
论文作者:Zhifeng Kong, Wei Ping, Ambrish Dantrey, Bryan Catanzaro
论文简介:In this work, we present CleanUNet, a causal speech denoising model on the raw waveform./在这项工作中,我们提出了CleanUNet,一个原始波形基础上的因果语音去噪模型。
论文摘要:在这项工作中,我们提出了CleanUNet,一个原始波形基础上的因果语音去噪模型。所提出的模型是基于一个编码器-解码器架构,结合几个自我关注块来完善其瓶颈表示,这对获得良好的结果至关重要。该模型通过一组在波形和多分辨率谱图上定义的损失进行优化。从各种客观和主观评价指标来看,所提出的方法在去噪后的语音质量方面优于最先进的模型。我们将我们的代码和模型发布在https://github.com/nvidia/cleanunet 。
我们是 ShowMeAI,致力于传播AI优质内容,分享行业解决方案,用知识加速每一次技术成长!点击查看 历史文章列表,在公众号内订阅话题 #ShowMeAI资讯日报,可接收每日最新推送。点击 专题合辑&电子月刊 快速浏览各专题全集。点击 这里 回复关键字 日报 免费获取AI电子月刊与资料包。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












{kind=link}