








ShowMeAI日报系列全新升级!覆盖AI人工智能 工具&框架 | 项目&代码 | 博文&分享 | 数据&资源 | 研究&论文 等方向。点击查看 历史文章列表,在公众号内订阅话题 #ShowMeAI资讯日报,可接收每日最新推送。点击 专题合辑&电子月刊 快速浏览各专题全集。点击 这里 回复关键字 日报 免费获取AI电子月刊与资料包。
📢 15岁男孩溺水遇险,高科技警用机器人开展急速救援
http://www.yunzhou-tech.com/info/363.html
近日山东威海一名15岁男孩在一处海域游泳时,因风浪太大难以上岸,体力不支陷入险境,民警赶赴现场后操控水上救生机器人快速的将男孩救回。这款上演了『急速救援』的水面救生机器人是『海豚1号』,是云洲智能自主研发生产的一款远程遥控操作的智能化救援设备。
『海豚1号』空载航速度达3.6m/s,是普通救生员的三倍,能负载200千克的重量,具备同时救援2-3人的强大应急能力,且有35分钟长续航、800米超远距离遥控等特性,可适应3级海况。救援人员无须下水,只需将其抛掷到水面,在岸边或船上遥控施救即可,大大的提升了水上救援的速度和安全性。

工具&框架
🚧 『StemRoller』免费的音源分离工具
https://github.com/stemrollerapp/stemroller
StemRoller是第一个免费的人声和乐器分离应用程序,可从从歌曲中分离出人声、鼓声、贝斯和其他乐器声部,只需点击一下就可以完成,StemRoller使用Facebook最先进的Demucs算法对歌曲进行拆分,并整合了YouTube的搜索结果。
🚧 『Nativefier』将网页转换成桌面应用(Mac)
https://github.com/nativefier/nativefier
Nativefier 是一个命令行工具,可以轻松地为任何网站创建一个 “桌面应用程序”,方便快捷打开。应用程序基于Electron(它使用Chromium引擎)封装成可在Windows、macOS和Linux上使用的操作系统执行文件(.app、.exe等)。封装完成后,大家无需再打开浏览器在众多标签页中搜索查找想要的内容,而可以直接点击进入对应的网站页面。
🚧 『OpenKS(知目)』领域可泛化的知识学习与计算引擎
https://github.com/ZJU-OpenKS/OpenKS
OpenKS 是知识计算引擎项目中的基础软件架构,由浙江大学牵头,联合北京大学、北京航空航天大学、哈尔滨工业大学、西北工业大学、之江实验室等顶尖学术机构、百度等行业领军企业联合建设。它可实现模型的大规模分布式训练与图计算,解决了从数据到知识,从知识到决策中的三大问题。OpenKS集成大量算法和解决方案,提供了一系列知识学习与计算的多层级接口标准,可供各机构研发人员以统一的形式进行算法模型研究成果的封装、集成与服务,并通过开源机制支持企业和社区开发者根据不同的场景需求对接口服务进行调用和进一步开发。

🚧 『ArXiv LaTeX』论文提交准备工具
本工具中提供了可清理和平整格式化ArXiv LaTeX提交论文的Python脚本。
https://github.com/davidstutz/arxiv-submission-sanitizer-flattener

博文&分享
👍 『机器学习论文撰写指南』How to ML Paper
https://docs.google.com/document/d/16R1E2ExKUCP5SlXWHr-KzbVDx9DBUclra-EbU8IB-iE/edit
作者总结了规范的论文结构,列出以下几个部分及各自内容格式与要点: Abstract、Introduction、Related Work、Background、Method、Experimental Setup、Results and Discussion、Conclusion。此外,指南也给出了常见的写作误区和建议List,可以打印出来,当作论文写作的自查清单!

👍 『Kaggle · 数据科学入门教程』系列Notebook推荐
https://www.kaggle.com/code/kanncaa1/data-sciencetutorial-for-beginners/notebook
本教程介绍成为一名数据科学家所需要的知识技能储备——基本工具(python、R、SQL)、统计学基本知识、数据处理、数据可视化、机器学习等,争取不多不少刚刚好。
- Introduction to Python / Python简介
- Python Data Science Toolbox / Python数据科学工具箱
- Cleaning Data Diagnose / 清洁数据诊断
- Pandas Foundation / Pandas基础
- Manipulating Data Frames with Pandas / 用 Pandas 处理 DataFrame
- Data Visualization / 数据可视化
- Machine Learning / 机器学习
- Deep Learning / 深度学习
- Time Series Prediction / 时间序列预测
- Statistic / 统计学
- Convolutional Neural Network / 卷积神经网络
- Recurrent Neural Network / 递归神经网络
数据&资源
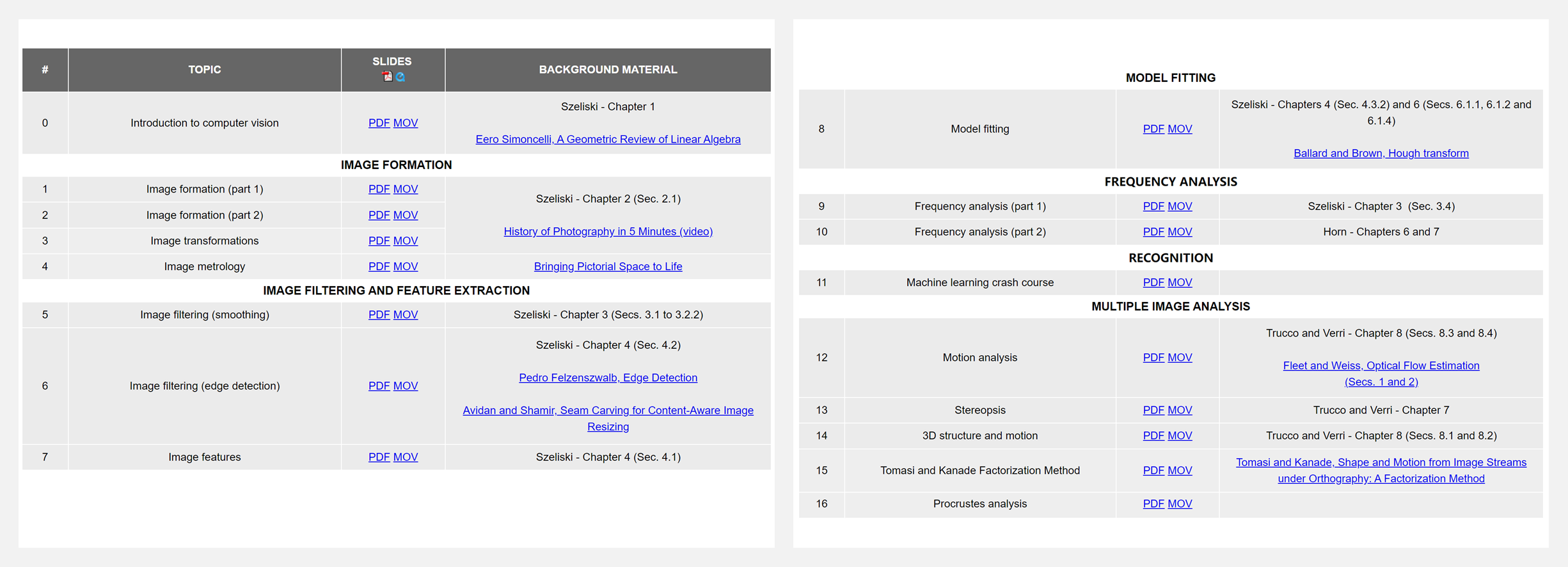
🔥 『EECS 4422 Computer Vision | York University』约克大学《计算机视觉》课程资料
https://www.eecs.yorku.ca/~kosta/Courses/EECS4422/
EECS 4422是约克大学开放的《计算机视觉》课程,课程核心内容覆盖 图像形成过程、图像表示、特征提取、立体视觉、运动分析、三维参数估计和应用等。
研究&论文

可以点击 这里 回复关键字日报,免费获取整理好的论文合辑。
科研进展
- 2022.07.30 『新视角合成』MobileNeRF: Exploiting the Polygon Rasterization Pipeline for Efficient Neural Field Rendering on Mobile Architectures
- 2022.08.10 『图像分类』Patching open-vocabulary models by interpolating weights
- BigScience (ACL) 2022 『图像分类』GPT-NeoX-20B: An Open-Source Autoregressive Language Model
- 2022.05.04 『无数据量化』Patch Similarity Aware Data-Free Quantization for Vision Transformers
⚡ 论文:MobileNeRF: Exploiting the Polygon Rasterization Pipeline for Efficient Neural Field Rendering on Mobile Architectures
论文时间:30 Jul 2022
领域任务:Novel View Synthesis,新视角合成
论文地址:https://arxiv.org/abs/2208.00277
代码实现:https://github.com/google-research/jax3d,https://github.com/google-research/jax3d/tree/main/jax3d/projects/mobilenerf
论文作者:Zhiqin Chen, Thomas Funkhouser, Peter Hedman, Andrea Tagliasacchi
论文简介:Neural Radiance Fields (NeRFs) have demonstrated amazing ability to synthesize images of 3D scenes from novel views./神经辐射场(NeRFs)在从新的视图中合成3D场景的图像方面表现出惊人的能力。
论文摘要:神经辐射场(NeRFs)在从新视图合成三维场景的图像方面表现出惊人的能力。然而,它们依赖于基于射线行进的专门的体积渲染算法,这与广泛部署的图形硬件的能力不匹配。本文介绍了一种新的基于纹理多边形的NeRF表示法,它可以用标准渲染管道有效地合成新的图像。NeRF被表示为一组多边形,其纹理代表二进制不透明度和特征向量。用Z型缓冲器对多边形进行传统的渲染,得到的图像在每个像素上都有特征,这些特征被运行在片段着色器中的一个小型的、依赖于视图的MLP解释,以产生最终的像素颜色。这种方法使NeRFs能够用传统的多边形光栅化管道进行渲染,它提供了大规模的像素级并行性,在包括手机在内的各种计算平台上实现了交互式帧率。
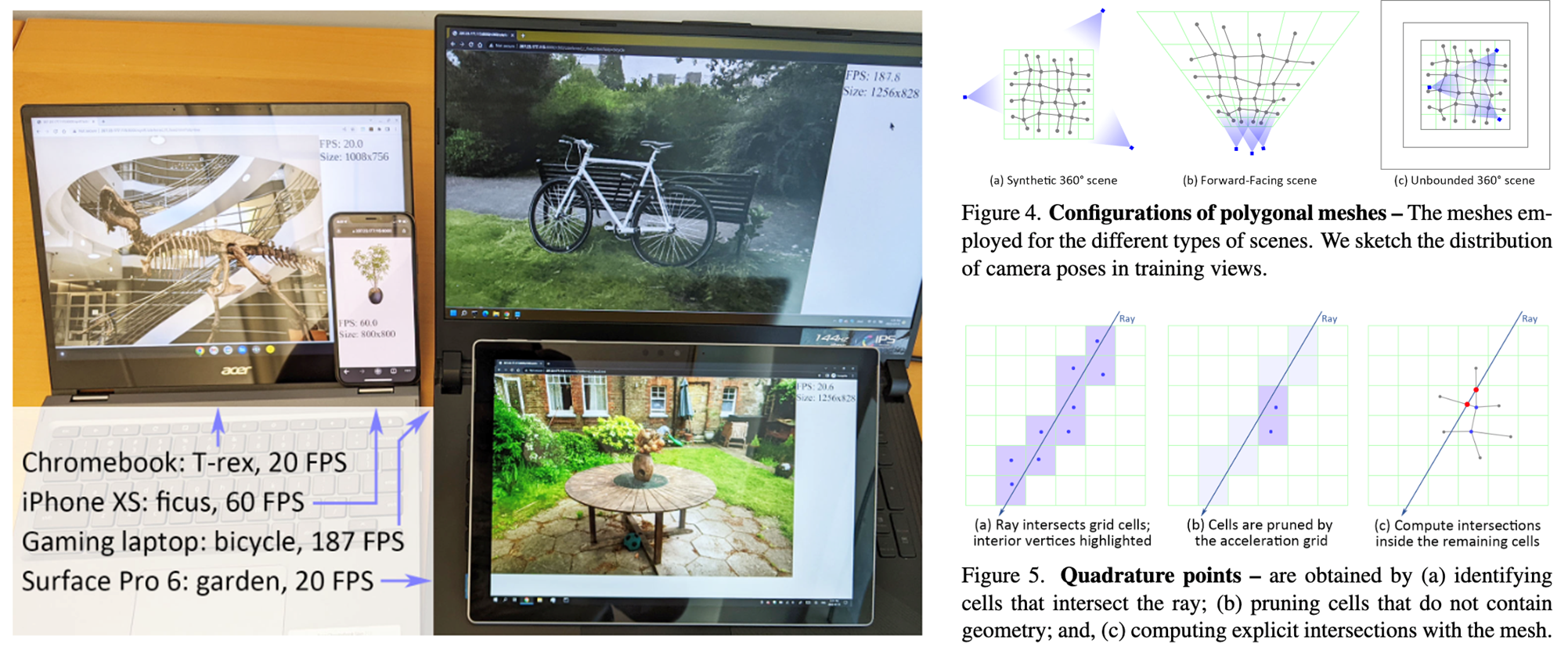
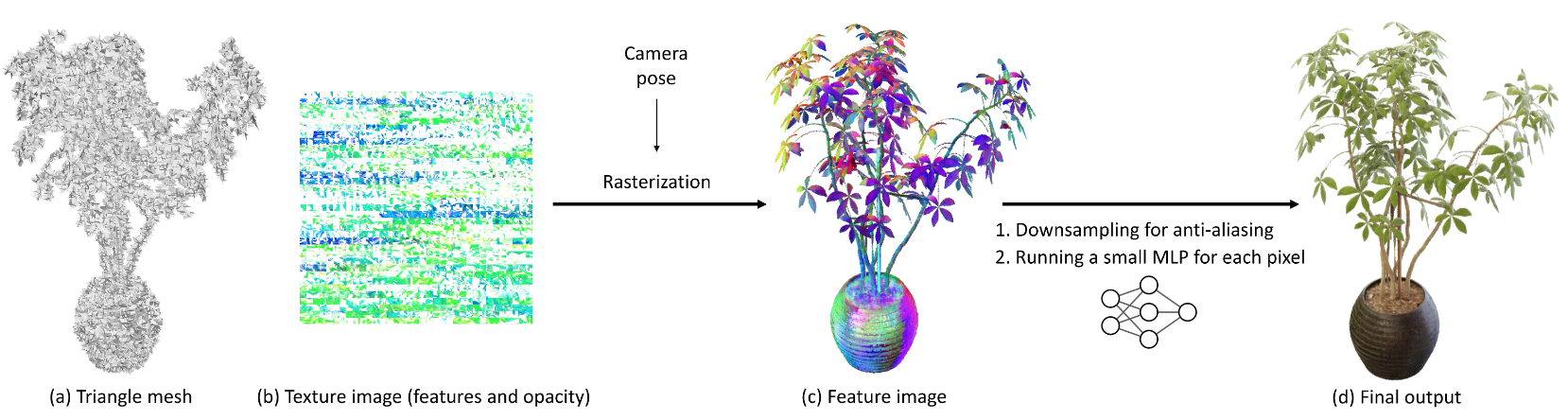
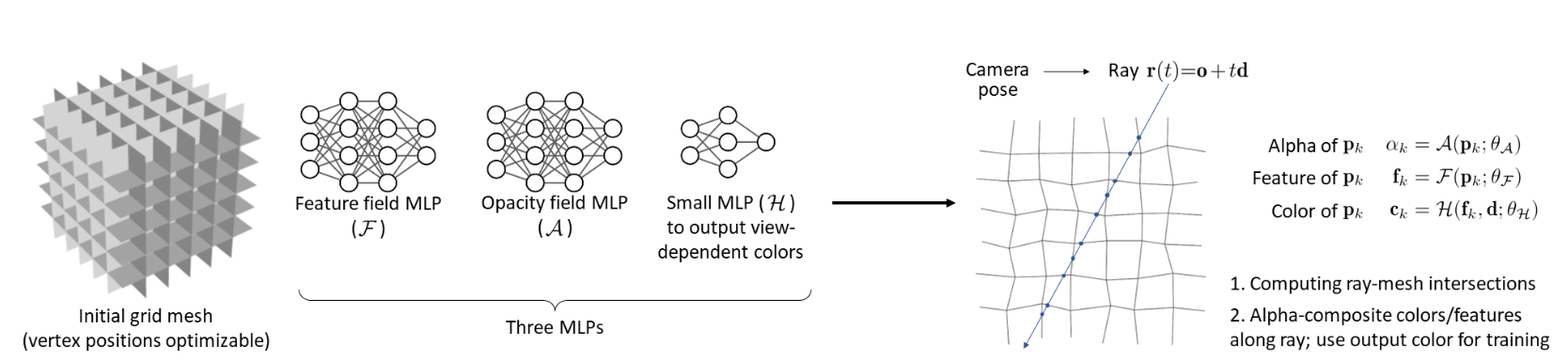

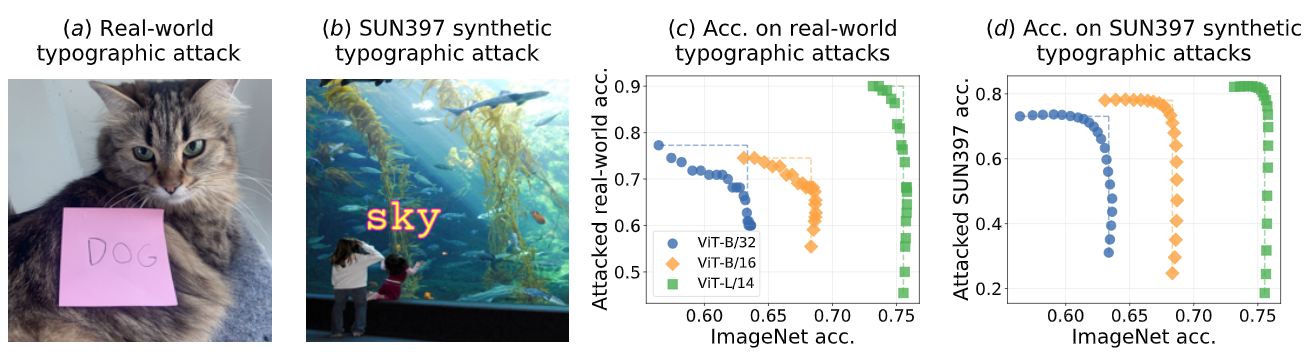
⚡ 论文:Patching open-vocabulary models by interpolating weights
论文时间:10 Aug 2022
领域任务:Image Classification,图像分类
论文地址:https://arxiv.org/abs/2208.05592
代码实现:https://github.com/mlfoundations/patching
论文作者:Gabriel Ilharco, Mitchell Wortsman, Samir Yitzhak Gadre, Shuran Song, Hannaneh Hajishirzi, Simon Kornblith, Ali Farhadi, Ludwig Schmidt
论文简介:We study model patching, where the goal is to improve accuracy on specific tasks without degrading accuracy on tasks where performance is already adequate./我们研究了模型的修补,其目的是在不降低性能已经足够的任务的准确性的情况下提高特定任务的准确性。
论文摘要:像CLIP这样的开放词汇模型在许多图像分类任务中实现了高精确度。然而,仍有一些情况下,它们的零次拍摄性能远非最佳。我们研究了模型的修补,其目标是在不降低性能已经足够的任务的准确性的情况下提高特定任务的准确性。为了实现这一目标,我们引入了PAINT,这是一种修补方法,使用微调前的模型权重和微调后的权重之间的插值来修补一个任务。在九项零拍CLIP表现不佳的任务上,PAINT将准确性提高了15到60个百分点,同时在ImageNet上将准确性保持在零拍模型的一个百分点之内。PAINT还允许一个单一的模型在多个任务上进行修补,并随着模型规模的扩大而改善。此外,我们还发现了一些广泛的转移案例,在一个任务上打补丁可以提高其他任务的准确性,即使这些任务的类别不相干。最后,我们调查了普通基准以外的应用,如计算或减少对CLIP的字体攻击的影响。我们的发现表明,有可能扩大开放词汇模型达到高准确性的任务集,而不需要从头开始重新训练它们。
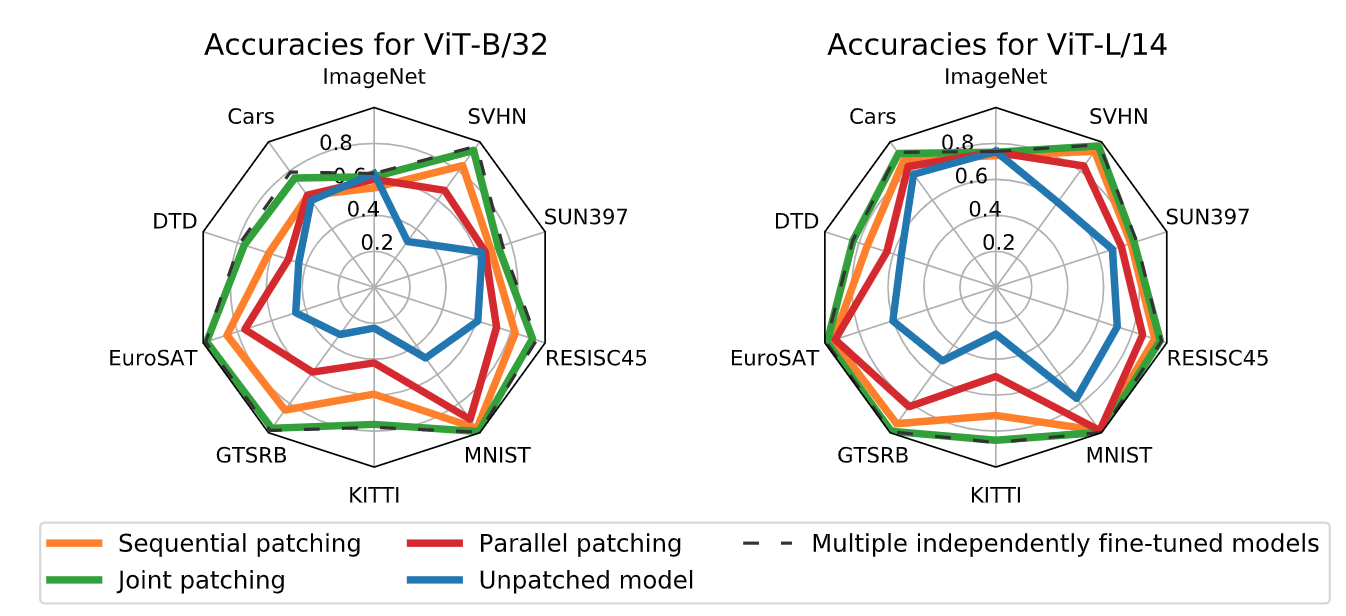
⚡ 论文:GPT-NeoX-20B: An Open-Source Autoregressive Language Model
论文时间:BigScience (ACL) 2022
领域任务:Language Modelling,语言模型
论文地址:https://arxiv.org/abs/2204.06745
代码实现:https://github.com/eleutherai/gpt-neox,https://github.com/labmlai/annotated_deep_learning_paper_implementations,https://github.com/labmlai/neox
论文作者:Sid Black, Stella Biderman, Eric Hallahan, Quentin Anthony, Leo Gao, Laurence Golding, Horace He, Connor Leahy, Kyle McDonell, Jason Phang, Michael Pieler, USVSN Sai Prashanth, Shivanshu Purohit, Laria Reynolds, Jonathan Tow, Ben Wang, Samuel Weinbach
论文简介:We introduce GPT-NeoX-20B, a 20 billion parameter autoregressive language model trained on the Pile, whose weights will be made freely and openly available to the public through a permissive license./我们介绍GPT-NeoX-20B,这是一个在Pile上训练的200亿个参数的自回归语言模型,其权重将通过一个允许的许可免费向公众开放。
论文摘要:我们介绍GPT-NeoX-20B,这是一个在Pile上训练的200亿个参数的自回归语言模型,其权重将通过允许性许可向公众免费公开。据我们所知,这是在提交时拥有公开权重的最大的密集自回归模型。在这项工作中,我们描述了model{}的架构和训练,并评估了它在一系列语言理解、数学和基于知识的任务上的表现。我们发现,GPT-NeoX-20B是一个特别强大的几枪推理器,在评估五枪时,其性能的提升远远超过了类似规模的GPT-3和FairSeq模型。我们开源了训练和评估代码以及模型权重,网址是https://github.com/EleutherAI/gpt-neox。
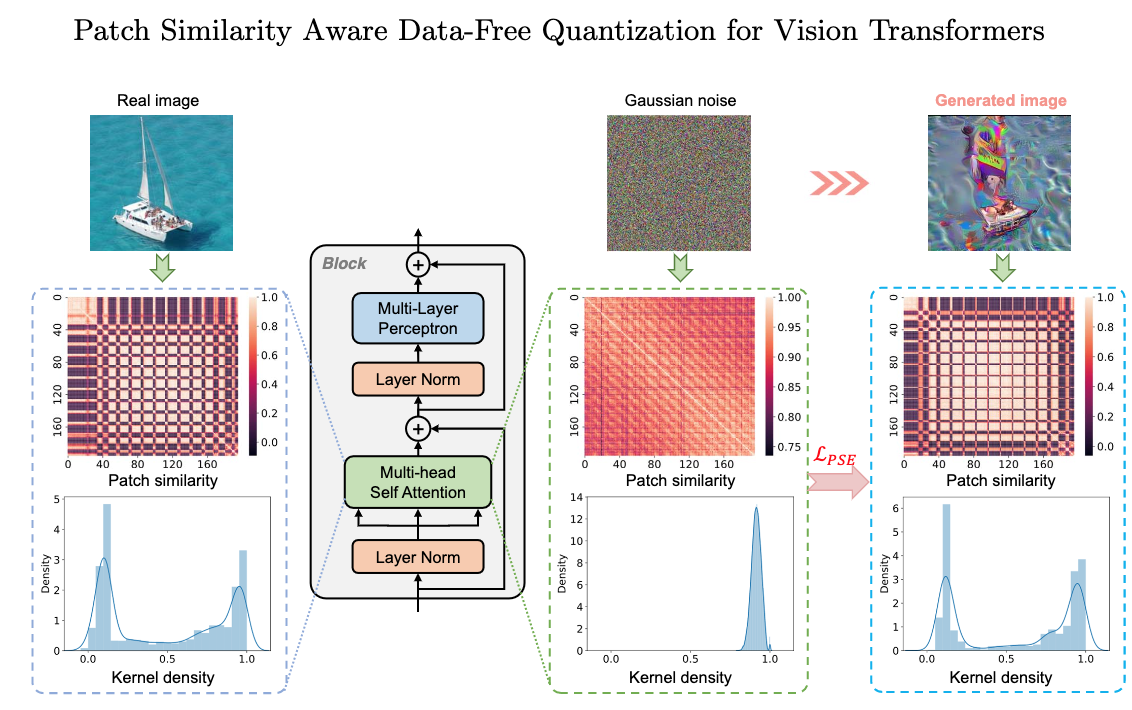
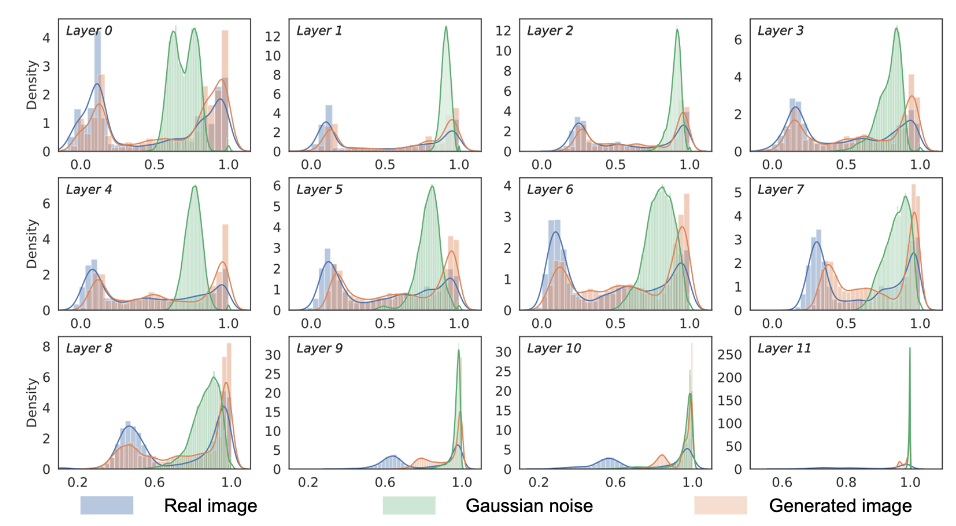
⚡ 论文:Patch Similarity Aware Data-Free Quantization for Vision Transformers
论文时间:4 Mar 2022
领域任务:Data Free Quantization,无数据量化
论文地址:https://arxiv.org/abs/2203.02250
代码实现:https://github.com/zkkli/psaq-vit
论文作者:Zhikai Li, Liping Ma, Mengjuan Chen, Junrui Xiao, Qingyi Gu
论文简介:Vision transformers have recently gained great success on various computer vision tasks; nevertheless, their high model complexity makes it challenging to deploy on resource-constrained devices./视觉transformers最近在各种计算机视觉任务上获得了巨大的成功;然而,它们的高模型复杂性使其在资源有限的设备上的部署具有挑战性。
论文摘要:视觉transformers最近在各种计算机视觉任务上获得了巨大的成功;然而,它们的高模型复杂性使其在资源受限的设备上的部署具有挑战性。量化是降低模型复杂性的有效方法,而无数据量化可以解决模型部署过程中的数据隐私和安全问题,因此受到广泛关注。不幸的是,所有现有的方法,如BN正则化,都是为卷积神经网络设计的,不能应用于模型结构明显不同的视觉变换器。在本文中,我们提出了PSAQ-ViT,一个用于视觉变换器的补丁相似性感知的无数据量化框架,以便能够根据视觉变换器的独特属性生成 "现实的 "样本来校准量化参数。具体来说,我们分析了自我注意模块的属性,并揭示了其在处理高斯噪声和真实图像时的一般差异(补丁相似性)。上述见解指导我们设计了一个相对值指标,以优化高斯噪声来接近真实图像,然后利用它来校准量化参数。在各种基准上进行了广泛的实验和消融研究,以验证PSAQ-ViT的有效性,它甚至可以优于真实数据驱动的方法。

我们是 ShowMeAI,致力于传播AI优质内容,分享行业解决方案,用知识加速每一次技术成长!点击查看 历史文章列表,在公众号内订阅话题 #ShowMeAI资讯日报,可接收每日最新推送。点击 专题合辑&电子月刊 快速浏览各专题全集。点击 这里 回复关键字 日报 免费获取AI电子月刊与资料包。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












{kind=link}