









索引是存储引擎用于快速找到记录的一种数据结构。索引对于良好的性能非常关键,尤其是当表中的数据量很大时,索引对性能的影响就越大。虽然索引对数据库性能而言如此重要,但好多使用其的人却常常忽视它。本片博文就是为大家介绍一些MySQL索引相关的知识
1.认识索引
要理解MySQL中的索引是如何工作的,最简单的方法就是看一下我们书里的目录(索引)部分,我们根据目录来找到其某个内容在哪个章节,锁定某个章之后,我们又可以在该章中锁定其在具体的哪一节,从而就可知道要找的内容在哪一页了。不知这样解释你是否对索引有所认识
2.MySQL索引类型
当我们谈论MySQL索引时,如果没特别指明类型,那几乎都是在指B-Tree索引,它采用B-Tree数据结构来存储数据
其实B-Tree是一种多路查找树,谈到查找,我们平时在设计查找的数据结构选择时不是一般都会用平衡二叉树么?那为啥数据库会放弃它而选择B-Tree这种多路查找树呢?
平衡数二叉与多路查找树之间的抉择
如上文所述,我们平时用到查找时之所以会使用平衡二叉树,是因为我们平时一般数据量都会比较少,完全可以在内存中进行,而数据库中的数据却是非常多的,当大到内存没法满足需求时,该如何处理?此时你一定会想到通过磁盘的调入调出就可以了,没错这的确是解决该问题的合理途径,可是问题又来了,我们都知道数据从磁盘调入调出速度是非常慢的?且通常我们调数据都是一个页一个页的调,此时如果你用二叉树就很难和这个页的大小做协调,而B-Tree却可以,我们可以使B-Tree的每个节点的保存的数据大小和一个页的大小接近就号了
3.B+ Tree组织索引的基本认识
MySQL中使用了B-Tree中的B+ Tree树作为其索引的基本数据结构
B+ Tress作为索引的简单示意图
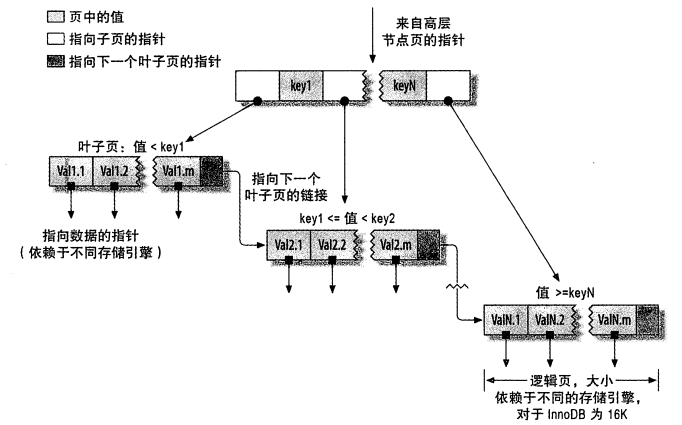
如上图所示,每次存储引擎进行查询的时候,不在需要进行全表扫描了,它首先会从B+ Tree的跟节点出发,跟节点的槽中存放了指向子节点的指针,它根据key值比较找到所查数据的位置信息在具体的哪个子节点中,然后根据子节点指针进入其中,继续上述步骤,当到达叶子节点时,数据要么就在该节点,要么该数据不存在
B+ Tree对索引列是顺序组织存储的,所以很适合范围数据查找
4.B+ Tree索引的限制
假设某索引的关键字为key(key1,key2,key3)
(1)如果不按索引的最左列来查找,则无法使用索引
(2)不能跳过索引中的某些列,也就是说索引的关键字比对是安key1,key2等顺序来的
(3)如果查询条件中某个列为范围查询类似like等关键字,则在其右别才查询的所有列都无法使用索引
5.索引的优点
(1)索引大大减少了服务器扫描的数据量
(2)索引可以帮助服务器避免排序和零时表
(3)索引可以将随机I/O变为顺序I/O
6.索引是最好的解决方案么?
索引对于表查找并不一定是最好的解决方案,当表很小时简单的全表扫描会更高效,且创建索引也是有代价的















 541
541











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









