







在日常使用中,Linux服务器丢包会以多种令人困扰的形式展现出来。当你尝试加载网页时,原本应该瞬间呈现的页面,进度条却像是陷入了泥沼,缓慢地向前挪动,图片长时间无法显示,文字也变得断断续续,仿佛在与你玩捉迷藏 。进行文件传输时,可能会突然遭遇传输中断,进度瞬间归零,之前的等待和努力付诸东流,一切都得重新开始。
对于依赖 Linux 服务器的业务而言,丢包带来的负面影响是极为严重的。在电商平台中,丢包可能导致用户在下单过程中出现卡顿、数据提交失败等情况,不仅破坏了用户的购物体验,还可能直接导致订单流失,造成经济损失。在在线教育领域,丢包会使直播课程画面卡顿、声音中断,严重影响教学质量和学生的学习效果,甚至可能导致学生和家长对平台失去信任。
一、网络丢包概述
对于 Linux 系统的使用者来说,网络性能的优劣直接关系到系统的整体表现。而在网络性能问题中,网络丢包堪称最为棘手的难题之一,它就像隐藏在暗处的杀手,悄无声息地侵蚀着系统的性能。想象一下,当你在服务器上部署了一个关键的应用服务,满怀期待地等待用户的访问和使用。然而,用户却频繁反馈访问速度极慢,甚至出现连接中断的情况。经过一番排查,你发现罪魁祸首竟然是网络丢包。这时候,你就会深刻地意识到,网络丢包问题绝不是一个可以忽视的小麻烦。
从专业角度来看,网络丢包会带来一系列严重的后果。最直观的就是网络延迟的显著增加。当数据包在传输过程中被丢弃,接收方就无法及时收到完整的数据,这就需要发送方重新发送这些丢失的数据包。重传的过程无疑会消耗额外的时间,导致数据传输的延迟大幅上升。在一些对实时性要求极高的应用场景中,如在线游戏、视频会议等,哪怕是几毫秒的延迟增加都可能带来极差的用户体验。在在线游戏中,延迟的增加可能导致玩家的操作出现卡顿,无法及时响应游戏中的各种事件,严重影响游戏的流畅性和竞技性;在视频会议中,延迟则可能使画面出现卡顿、声音不同步等问题,让沟通变得异常困难。
网络丢包还会导致吞吐量的降低。吞吐量是指单位时间内成功传输的数据量,它是衡量网络性能的重要指标之一。当丢包发生时,一部分数据无法正常传输,这就必然会导致实际的吞吐量下降。对于一些大数据传输的场景,如文件下载、数据备份等,吞吐量的降低会大大延长传输时间,降低工作效率。如果你需要从远程服务器下载一个大型文件,原本预计几个小时就能完成的下载任务,可能因为网络丢包导致下载时间延长数倍,甚至可能因为丢包过于严重而导致下载失败,需要重新开始。
对于基于 TCP 协议的应用来说,丢包更是意味着网络拥塞和重传。TCP 协议具有可靠性机制,当它检测到数据包丢失时,会自动触发重传机制,以确保数据的完整性。然而,频繁的重传不仅会增加网络流量,还会进一步加剧网络拥塞,形成一种恶性循环。在高并发的网络环境中,这种恶性循环可能会导致整个网络的瘫痪,使所有依赖网络的应用都无法正常运行;网络丢包对 Linux 系统性能的影响是多方面的,它不仅会降低用户体验,还会影响业务的正常运行,给企业带来巨大的损失。
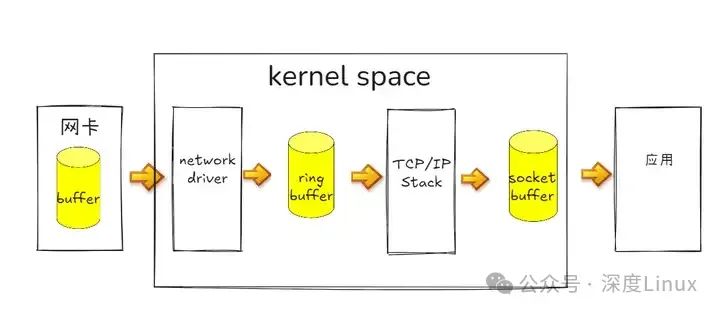
在开始之前,我们先用一张图解释 linux 系统接收网络报文的过程:
-
首先网络报文通过物理网线发送到网卡
-
网络驱动程序会把网络中的报文读出来放到 ring buffer 中,这个过程使用 DMA(Direct Memory Access),不需要 CPU 参与
-
内核从 ring buffer 中读取报文进行处理,执行 IP 和 TCP/UDP 层的逻辑,最后把报文放到应用程序的 socket buffer 中
-
应用程序从 socket buffer 中读取报文进行处理
二、丢包可能发生在哪?
当网络丢包问题出现时,就如同一场悬疑案件,我们需要抽丝剥茧,从各个层面去探寻 “凶手”,也就是丢包发生的原因。在 Linux 系统中,丢包可能发生在网络协议栈的各个层次,每个层次都有其独特的丢包原因和排查方法。
2.1收包流程:数据包的 “入境之路”
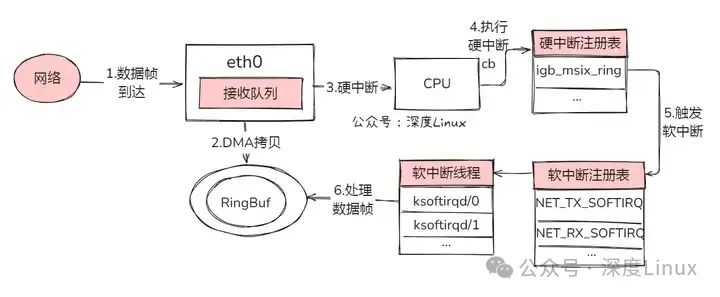
当网卡接收到报文时,这场 “入境之旅” 就开启了。首先,网卡通过 DMA(直接内存访问)技术,以极高的效率将数据包拷贝到 RingBuf(环形缓冲区)中,就好比货物被快速卸到了一个临时仓库。紧接着,网卡向 CPU 发起一个硬中断,就像吹响了紧急集合哨,通知 CPU 有数据抵达 “国门”。
CPU 迅速响应,开始执行对应的硬中断处理例程,在这个例程里,它会将数据包的相关信息放入每 CPU 变量 poll_list 中,随后触发一个收包软中断,把后续的精细活儿交给软中断去处理。对应 CPU 的软中断线程 ksoftirqd 就登场了,它负责处理网络包接收软中断,具体来说,就是执行 net_rx_action () 函数。
在这个函数的 “指挥” 下,数据包从 RingBuf 中被小心翼翼地取出,然后进入协议栈,开启层层闯关。从链路层开始,检查报文合法性,剥去帧头、帧尾,接着进入网络层,判断包的走向,若是发往本机,再传递到传输层。最终,数据包被妥妥地放到 socket 的接收队列中,等待应用层随时来收取,至此,数据包算是顺利 “入境”,完成了它的收包流程。
2.2发包流程:数据包的 “出境之旅”
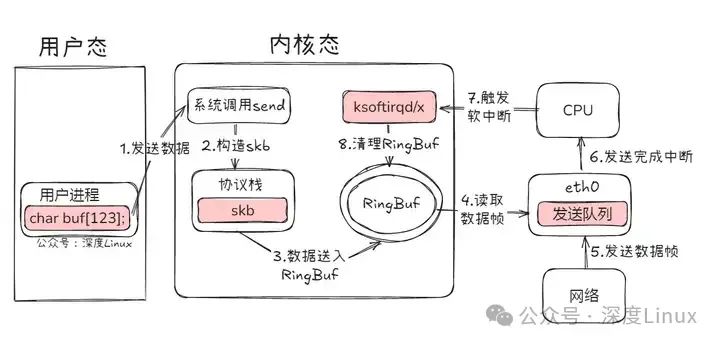
应用程序要发送数据时,数据包的 “出境之旅” 便启程了。首先,应用程序调用 Socket API(比如 sendmsg)发送网络包,这一操作触发系统调用,使得数据从用户空间拷贝到内核空间,同时,内核会为其分配一个 skb(sk_buff 结构体,它可是数据包在内核中的 “代言人”,承载着各种关键信息),并将数据封装其中。接着,skb 进入协议栈,开始自上而下的 “闯关升级”。
在传输层,会为数据添加 TCP 头或 UDP 头,进行拥塞控制、滑动窗口等一系列精细操作;到了网络层,依据目标 IP 地址查找路由表,确定下一跳,填充 IP 头中的源和目标 IP 地址、TTL 等关键信息,还可能进行 skb 切分,同时要经过 netfilter 框架的 “安检”,判断是否符合过滤规则。
之后,在邻居子系统填充目的 MAC 地址,再进入网络设备子系统,skb 被放入发送队列 RingBuf 中,等待网卡发送。网卡发送完成后,会向 CPU 发出一个硬中断,告知 “任务完成”,这个硬中断又会触发软中断,在软中断处理函数中,对 RingBuf 进行清理,把已经发送成功的数据包残留信息清除掉,就像清理运输后的车厢,为下一次运输做好准备,至此,数据包顺利 “出境”,完成了它的发包流程。
三、丢包原因深度剖析
3.1物理链路层
在网络的物理链路层,有诸多因素可能导致 Linux 服务器丢包。网线就像是网络世界中的高速公路,承担着数据传输的重任。然而,随着时间的推移,网线会逐渐老化,就像年久失修的高速公路,路面变得坑坑洼洼。老化的网线内部结构会发生变化,金属导线可能会出现氧化、断裂等情况,这会大大增加信号在传输过程中的衰减 。当信号衰减到一定程度时,数据就无法被准确地传输,从而导致丢包现象的发生。
网络设备之间的接口连接也至关重要。如果接口松动,就好比高速公路上的连接点出现了松动,数据传输的通道就会变得不稳定。接口松动可能会导致接触不良,信号时有时无,数据包在传输过程中就容易丢失 。在一些服务器机房中,由于设备的频繁插拔或者震动,接口松动的情况时有发生,这也是需要重点排查的一个点。
网络设备如路由器、交换机等,在网络中扮演着交通枢纽的角色。它们负责转发数据包,确保数据能够准确地到达目的地。一旦这些设备出现故障,就像交通枢纽发生了拥堵或者瘫痪,整个网络的通信都会受到严重影响。路由器的硬件故障,如内存损坏、CPU 过热等,可能会导致其无法正常处理数据包,从而引发丢包 。交换机的端口故障、背板带宽不足等问题,也会使数据包在交换过程中丢失。
当链路层由于缓冲区溢出等原因导致网卡丢包时,Linux 会在网卡收发数据的统计信息中记录下收发错误的次数。链路层是网络通信的基础,它负责将网络层传来的数据封装成帧,并通过物理介质进行传输。链路层丢包通常是由于硬件故障、网络拥塞或者配置错误等原因导致的。当链路层由于缓冲区溢出等原因导致网卡丢包时,Linux 会在网卡收发数据的统计信息中记录下收发错误的次数。
我们可以通过 ethtool 或者 netstat 命令,来查看网卡的丢包记录:
netstat -i
Kernel Interface table
Iface MTU RX-OK RX-ERR RX-DRP RX-OVR TX-OK TX-ERR TX-DRP TX-OVR Flg
eth0 100 31 0 0 0 8 0 0 0 BMRU
lo 65536 0 0 0 0 0 0 0 0 LRURX-OK、RX-ERR、RX-DRP、RX-OVR ,分别表示接收时的总包数、总错误数、进入 Ring Buffer 后因其他原因(如内存不足)导致的丢包数以及 Ring Buffer 溢出导致的丢包数。
TX-OK、TX-ERR、TX-DRP、TX-OVR 也代表类似的含义,只不过是指发送时对应的各个指标。
这里我们没有发现任何错误,说明虚拟网卡没有丢包。不过要注意,如果用 tc 等工具配置了 QoS,那么 tc 规则导致的丢包,就不会包含在网卡的统计信息中。所以接下来,我们还要检查一下 eth0 上是否配置了 tc 规则,并查看有没有丢包。添加 -s 选项,以输出统计信息:
tc -s qdisc show dev eth0
qdisc netem 800d: root refcnt 2 limit 1000 loss 30%
Sent 432 bytes 8 pkt (dropped 4, overlimits 0 requeues 0)
backlog 0b 0p requeues 0可以看到, eth0 上配置了一个网络模拟排队规则(qdisc netem),并且配置了丢包率为 30%(loss 30%)。再看后面的统计信息,发送了 8 个包,但是丢了 4个。看来应该就是这里导致 Nginx 回复的响应包被 netem 模块给丢了。
既然发现了问题,解决方法也很简单,直接删掉 netem 模块就可以了。执行下面的命令,删除 tc 中的 netem 模块:
tc qdisc del dev eth0 root netem loss 30%删除后,重新执行之前的 hping3 命令,看看现在还有没有问题:
hping3 -c 10 -S -p 80 192.168.0.30
HPING 192.168.0.30 (eth0 192.168.0.30): S set, 40 headers + 0 data bytes
len=44 ip=192.168.0.30 ttl=63 DF id=0 sport=80 flags=SA seq=0 win=5120 rtt=7.9 ms
len=44 ip=192.168.0.30 ttl=63 DF id=0 sport=80 flags=SA seq=2 win=5120 rtt=1003.8 ms
len=44 ip=192.168.0.30 ttl=63 DF id=0 sport=80 flags=SA seq=5 win=5120 rtt=7.6 ms
len=44 ip=192.168.0.30 ttl=63 DF id=0 sport=80 flags=SA seq=6 win=5120 rtt=7.4 ms
len=44 ip=192.168.0.30 ttl=63 DF id=0 sport=80 flags=SA seq=9 win=5120 rtt=3.0 ms
--- 192.168.0.30 hping statistic ---
10 packets transmitted, 5 packets received, 50% packet loss
round-trip min/avg/max = 3.0/205.9/1003.8 ms不幸的是,从 hping3 的输出中可以看到还是 50% 的丢包,RTT 的波动也仍旧很大,从 3ms 到 1s。显然,问题还是没解决,丢包还在继续发生。不过,既然链路层已经排查完了,我们就继续向上层分析,看看网络层和传输层有没有问题。
3.2网卡及驱动层面
网卡硬件故障:网卡作为服务器与网络连接的关键硬件,其状态直接影响着网络通信的质量。当网卡芯片过热时,就像电脑在长时间高负荷运行后会变得卡顿一样,网卡的工作也会变得不稳定 。过热可能会导致芯片内部的电子元件性能下降,无法准确地接收或发送数据包,从而造成丢包。如果网卡受到物理损坏,如接口损坏、电路板短路等,那么数据传输就会中断,丢包现象也会随之出现 。在一些服务器中,由于散热不良或者硬件质量问题,网卡过热和损坏的情况并不少见。
驱动程序异常:驱动程序就像是网卡的指挥官,负责协调网卡与操作系统之间的通信。如果驱动版本与内核不兼容,就好比指挥官和士兵之间的指令传达出现了错误,网卡可能无法正常工作。驱动版本过旧,可能不支持新的内核功能,或者存在一些已知的漏洞,这都可能导致在处理网络数据时出现丢包的情况 。驱动程序损坏也会影响网卡的正常运行。在系统更新、病毒感染等情况下,驱动程序可能会被破坏,导致无法正确处理中断请求,数据包也就无法及时被处理和传输,最终造成丢包。
3.3网络协议栈各层问题
①链路层:在链路层,帧校验失败是导致丢包的常见原因之一。每个网络帧都包含一个校验和,用于验证帧数据在传输过程中是否被篡改 。当接收方接收到帧时,会根据校验和算法重新计算校验和,并与帧中携带的校验和进行对比。如果两者不一致,就说明帧数据可能被损坏,接收方会将该帧丢弃,从而导致丢包。
QoS(Quality of Service,服务质量)配置不当也会引发丢包。QoS 的目的是为不同类型的网络流量提供不同的服务质量保证 。当 QoS 配置不合理时,比如将某些重要的数据包设置为低优先级,这些数据包在网络拥塞时可能会被优先丢弃,从而导致丢包现象的发生。在一些企业网络中,由于对 QoS 的配置不够精细,常常会出现这种情况。
②网络层:路由错误在网络层是一个比较严重的问题。路由就像是网络中的导航系统,负责为数据包指引正确的传输路径 。当路由表出现错误时,比如路由条目丢失、错误的路由指向等,数据包就无法到达正确的目的地,最终会被丢弃。如果服务器的路由表中没有到某个目标网络的正确路由,那么发往该网络的数据包就会被丢弃,这就像导航系统把你指引到了错误的方向,你永远也无法到达目的地。
MTU(Maximum Transmission Unit,最大传输单元)设置不合理也会引发丢包。MTU 是指网络中能够传输的最大数据包大小 。当一个数据包的大小超过了链路的 MTU 时,它就需要被分片成多个小数据包进行传输。在传输过程中,如果某个分片丢失,那么整个数据包就无法被正确重组,从而导致丢包。在一些跨网络的通信中,由于不同网络的 MTU 可能不同,如果没有进行合理的设置和调整,就很容易出现这种情况。
③传输层:在传输层,端口未监听是一个常见的丢包原因。每个网络应用都需要监听特定的端口来接收数据 。如果一个应用程序没有正确监听其对应的端口,那么发送到该端口的数据包就无法被接收,最终会被丢弃。当一个 Web 服务器没有监听 80 端口(HTTP 协议默认端口)时,客户端发送的 HTTP 请求数据包就会被丢弃,导致无法访问该网站。
资源占用超过内核限制也会引发丢包。系统内核为每个网络连接分配了一定的资源,如内存、文件描述符等 。当连接数过多,或者某个连接占用了过多的资源时,系统就可能无法为新的连接分配足够的资源,导致新的数据包无法被处理,从而造成丢包。在高并发的网络环境中,如大型电商网站的促销活动期间,由于大量用户同时访问服务器,很容易出现这种情况。
执行 netstat -s 命令,可以看到协议的收发汇总,以及错误信息:
netstat -s
#输出
Ip:
Forwarding: 1 //开启转发
31 total packets received //总收包数
0 forwarded //转发包数
0 incoming packets discarded //接收丢包数
25 incoming packets delivered //接收的数据包数
15 requests sent out //发出的数据包数
Icmp:
0 ICMP messages received //收到的ICMP包数
0 input ICMP message failed //收到ICMP失败数
ICMP input histogram:
0 ICMP messages sent //ICMP发送数
0 ICMP messages failed //ICMP失败数
ICMP output histogram:
Tcp:
0 active connection openings //主动连接数
0 passive connection openings //被动连接数
11 failed connection attempts //失败连接尝试数
0 connection resets received //接收的连接重置数
0 connections established //建立连接数
25 segments received //已接收报文数
21 segments sent out //已发送报文数
4 segments retransmitted //重传报文数
0 bad segments received //错误报文数
0 resets sent //发出的连接重置数
Udp:
0 packets received
...
TcpExt:
11 resets received for embryonic SYN_RECV sockets //半连接重置数
0 packet headers predicted
TCPTimeouts: 7 //超时数
TCPSynRetrans: 4 //SYN重传数
...etstat 汇总了 IP、ICMP、TCP、UDP 等各种协议的收发统计信息。不过,我们的目的是排查丢包问题,所以这里主要观察的是错误数、丢包数以及重传数。可以看到,只有 TCP 协议发生了丢包和重传,分别是:
-
11 次连接失败重试(11 failed connection attempts)
-
4 次重传(4 segments retransmitted)
-
11 次半连接重置(11 resets received for embryonic SYN_RECV sockets)
-
4 次 SYN 重传(TCPSynRetrans)
-
7 次超时(TCPTimeouts)
这个结果告诉我们,TCP 协议有多次超时和失败重试,并且主要错误是半连接重置。换句话说,主要的失败,都是三次握手失败。不过,虽然在这儿看到了这么多失败,但具体失败的根源还是无法确定。
3.4系统与应用层面
系统负载过高:当 Linux 服务器的 CPU、内存等资源被大量占用时,就像一个人同时要处理多项繁重的任务,会变得力不从心,网络数据的处理也会受到影响。CPU 是服务器的核心处理器,当它被大量占用时,系统无法及时响应网络请求 。网络数据包在缓冲区中等待处理的时间会变长,超过一定时间后,这些数据包就会被丢弃。内存不足也会导致丢包。当内存被大量占用时,系统可能会开始使用交换空间(Swap),而交换空间的读写速度比内存慢很多,这会导致网络数据的处理速度大幅下降,最终造成丢包。在一些运行着多个大型应用程序的服务器中,由于资源竞争激烈,系统负载过高的情况经常发生。
应用程序异常:应用程序自身的问题也可能导致丢包。内存泄漏是一个常见的应用程序问题,就像一个容器有漏洞,水会不断地漏出去 。当应用程序发生内存泄漏时,它会不断地占用内存,导致系统可用内存越来越少。随着可用内存的减少,网络数据的处理会受到影响,最终可能导致丢包。应用程序的逻辑错误也会导致丢包。如果应用程序在处理网络数据时存在逻辑错误,比如错误地解析数据包、无法正确地发送响应等,那么就会导致数据包的丢失。在一些开发不完善的应用程序中,常常会出现这些逻辑错误。
3.5防火墙与 iptables 规则
防火墙在网络安全中起着重要的防护作用,但如果策略设置过于严格,就像一个过于严厉的门卫,可能会把一些合法的网络数据包当作危险分子拦截在外 。当防火墙的规则设置不当,将正常的网络通信流量误判为攻击行为时,就会导致这些数据包被丢弃,从而引发丢包现象。在一些企业网络中,为了加强网络安全,可能会设置非常严格的防火墙策略,但这也可能会影响到正常的业务通信。
iptables 是 Linux 系统中常用的防火墙工具,它通过规则来控制网络数据包的进出 。当 iptables 规则错误配置时,比如 DROP 规则设置不当,会使正常的数据包被错误地丢弃。如果错误地设置了 iptables 规则,将某个应用程序的通信端口设置为 DROP,那么该应用程序的所有网络数据包都会被丢弃,导致无法正常通信。在配置 iptables 规则时,需要谨慎操作,确保规则的正确性,避免因规则错误而导致丢包。
首先,除了网络层和传输层的各种协议,iptables 和内核的连接跟踪机制也可能会导致丢包。所以,这也是发生丢包问题时我们必须要排查的一个因素。
先来看看连接跟踪,要确认是不是连接跟踪导致的问题,只需要对比当前的连接跟踪数和最大连接跟踪数即可。
# 主机终端中查询内核配置
$ sysctl net.netfilter.nf_conntrack_max
net.netfilter.nf_conntrack_max = 262144
$ sysctl net.netfilter.nf_conntrack_count
net.netfilter.nf_conntrack_count = 182可以看到,连接跟踪数只有 182,而最大连接跟踪数则是 262144。显然,这里的丢包,不可能是连接跟踪导致的。
接着,再来看 iptables。回顾一下 iptables 的原理,它基于 Netfilter 框架,通过一系列的规则,对网络数据包进行过滤(如防火墙)和修改(如 NAT)。这些 iptables 规则,统一管理在一系列的表中,包括 filter、nat、mangle(用于修改分组数据) 和 raw(用于原始数据包)等。而每张表又可以包括一系列的链,用于对 iptables 规则进行分组管理。
对于丢包问题来说,最大的可能就是被 filter 表中的规则给丢弃了。要弄清楚这一点,就需要我们确认,那些目标为 DROP 和 REJECT 等会弃包的规则,有没有被执行到。可以直接查询 DROP 和 REJECT 等规则的统计信息,看看是否为0。如果不是 0 ,再把相关的规则拎出来进行分析。
iptables -t filter -nvL
#输出
Chain INPUT (policy ACCEPT 25 packets, 1000 bytes)
pkts bytes target prot opt in out source destination
6 240 DROP all -- * * 0.0.0.0/0 0.0.0.0/0 statistic mode random probability 0.29999999981
Chain FORWARD (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
Chain OUTPUT (policy ACCEPT 15 packets, 660 bytes)
pkts bytes target prot opt in out source destination
6 264 DROP all -- * * 0.0.0.0/0 0.0.0.0/0 statistic mode random probability 0.29999999981从 iptables 的输出中,你可以看到,两条 DROP 规则的统计数值不是 0,它们分别在INPUT 和 OUTPUT 链中。这两条规则实际上是一样的,指的是使用 statistic 模块,进行随机 30% 的丢包。0.0.0.0/0 表示匹配所有的源 IP 和目的 IP,也就是会对所有包都进行随机 30% 的丢包。看起来,这应该就是导致部分丢包的“罪魁祸首”了。
执行下面的两条 iptables 命令,删除这两条 DROP 规则。
root@nginx:/# iptables -t filter -D INPUT -m statistic --mode random --probability 0.30 -j DROP
root@nginx:/# iptables -t filter -D OUTPUT -m statistic --mode random --probability 0.30 -j DROP再次执行刚才的 hping3 命令,看看现在是否正常
hping3 -c 10 -S -p 80 192.168.0.30
#输出
HPING 192.168.0.30 (eth0 192.168.0.30): S set, 40 headers + 0 data bytes
len=44 ip=192.168.0.30 ttl=63 DF id=0 sport=80 flags=SA seq=0 win=5120 rtt=11.9 ms
len=44 ip=192.168.0.30 ttl=63 DF id=0 sport=80 flags=SA seq=1 win=5120 rtt=7.8 ms
...
len=44 ip=192.168.0.30 ttl=63 DF id=0 sport=80 flags=SA seq=9 win=5120 rtt=15.0 ms
--- 192.168.0.30 hping statistic ---
10 packets transmitted, 10 packets received, 0% packet loss
round-trip min/avg/max = 3.3/7.9/15.0 ms这次输出你可以看到,现在已经没有丢包了,并且延迟的波动变化也很小。看来,丢包问题应该已经解决了。
不过,到目前为止,我们一直使用的 hping3 工具,只能验证案例 Nginx 的 80 端口处于正常监听状态,却还没有访问 Nginx 的 HTTP 服务。所以,不要匆忙下结论结束这次优化,我们还需要进一步确认,Nginx 能不能正常响应 HTTP 请求。我们继续在终端二中,执行如下的 curl 命令,检查 Nginx 对 HTTP 请求的响应:
$ curl --max-time 3 http://192.168.0.30
curl: (28) Operation timed out after 3000 milliseconds with 0 bytes received奇怪,hping3 的结果显示Nginx 的 80 端口是正常状态,为什么还是不能正常响应 HTTP 请求呢?别忘了,我们还有个大杀器——抓包操作。看来有必要抓包看看了(查看4.5)。
四、实用排查工具与方法
4.1 ping命令初步检测
ping 命令是我们排查网络丢包问题时最常用的工具之一,就像是网络世界中的 “侦察兵”,能帮助我们快速了解网络的连通性和丢包率 。它的工作原理很简单,通过向目标 IP 地址发送 ICMP(Internet Control Message Protocol)回显请求报文,并等待接收回显应答报文,以此来判断网络是否畅通 。如果网络存在丢包问题,我们就能从 ping 命令的返回结果中发现一些蛛丝马迹。
在 Linux 系统中使用 ping 命令非常方便。打开终端,输入 “ping 目标 IP 地址”,然后按下回车键,就能开始测试了 。比如我们要测试与百度服务器的连接情况,就可以输入 “ping www.baidu.com” 。命令执行后,会不断地向百度服务器发送 ICMP 请求,并显示每次请求的响应时间和结果。在返回结果中,我们重点关注 “丢包率” 这一指标。如果显示 “丢失 = 0”,那就说明在测试过程中没有出现丢包现象,网络连接比较稳定;如果显示 “丢失 = X”(X 大于 0),则表示有 X 个数据包在传输过程中丢失了,丢包率就是(丢失的数据包数 ÷ 发送的数据包总数)× 100% 。
除了基本的使用方法,ping 命令还有一些常用参数,可以帮助我们更全面地测试网络。“-c” 参数用于指定发送的数据包数量 。使用 “ping -c 50 www.baidu.com”,表示只向百度服务器发送 50 个 ICMP 请求,这样可以在短时间内快速获取一定数量的测试数据,方便我们进行分析。“-i” 参数用于指定每次发送数据包的时间间隔 。比如 “ping -i 2 www.baidu.com”,表示每隔 2 秒发送一个数据包,通过调整这个时间间隔,我们可以模拟不同的网络负载情况。“-s” 参数用于指定发送数据包的大小 。默认情况下,ping 命令发送的数据包大小为 64 字节,我们可以使用 “ping -s 1000 www.baidu.com” 来发送大小为 1000 字节的数据包,这样可以测试网络在传输大尺寸数据包时的表现。
4.2 MTR综合诊断
MTR(My Traceroute)工具是网络诊断中的一把 “瑞士军刀”,它巧妙地结合了 ping 和 traceroute 的功能,能为我们提供更加全面和深入的网络诊断信息 。与 ping 命令只能简单地检测网络连通性和丢包率不同,MTR 不仅可以实时显示数据包在网络传输过程中的路径,还能展示每一跳的延迟时间和丢包情况,就像一个精准的导航仪,帮助我们准确定位丢包发生的具体节点。
在 Linux 系统中安装 MTR 工具也很简单。对于基于 Debian 或 Ubuntu 的系统,我们可以在终端中输入 “sudo apt-get install mtr” 来进行安装;对于基于 Red Hat 或 CentOS 的系统,则可以使用 “sudo yum install mtr” 命令来完成安装 。安装完成后,就可以使用 MTR 工具进行网络诊断了。
使用MTR工具时,只需在终端中输入 “mtr目标 IP 地址”,然后按下回车键即可 。例如,我们要诊断到腾讯服务器的网络情况,输入 “mtr www.tencent.com” 。MTR 工具会立即开始工作,向目标服务器发送一系列的数据包,并实时显示数据包在传输过程中经过的每一个节点的信息 。在MTR 的输出结果中,我们可以看到多个重要的信息列。
“Host” 列显示的是节点的IP地址和域名,通过它我们可以了解数据包经过了哪些网络设备;“Loss%”列表示每个节点的丢包率,这是我们最关注的指标之一,如果某个节点的丢包率较高,那就说明丢包问题很可能发生在这个节点上;“Snt”列表示每秒发送的数据包数;“Last”“Avg”“Best”“Wrst”列分别显示最近一次、平均、最短和最长的探测延迟时间,通过这些时间数据,我们可以判断网络的延迟情况和稳定性 。
在实际使用 MTR 工具时,我们还可以结合一些参数来满足不同的诊断需求。“-r” 参数可以让 MTR 以报告模式显示输出结果 。使用 “mtr -r www.tencent.com”,MTR 会在检测完成后,以报告的形式展示所有节点的信息,方便我们进行查看和分析。“-n” 参数用于禁止对 IP 地址进行域名反解析 。有些情况下,域名反解析可能会花费一些时间,影响诊断效率,使用 “mtr -n www.tencent.com” 可以直接显示 IP 地址,加快诊断速度。“-c” 参数可以指定探测的次数 。例如 “mtr -c 50 www.tencent.com”,表示只进行 50 次探测,这样可以在特定次数的测试后获取结果,适用于一些对测试次数有要求的场景。
4.3 netstat查看网络状态
netstat 命令是 Linux 系统中一个功能强大的网络工具,它就像是网络世界的 “观察者”,可以用于查看网络连接、路由表、网络接口统计信息等,帮助我们从多个角度了解网络的运行状态,进而排查网络层和传输层的丢包原因。
通过 netstat 命令,我们可以清晰地看到当前系统的网络连接情况。在终端中输入“netstat -a”,就能列出所有的网络连接,包括处于监听状态的连接和已经建立的连接 。“-a”参数表示显示所有连接,无论是正在监听的还是已经建立的。在输出结果中,“Proto” 列表示套接字使用的协议,如 tcp、udp 等;“Local Address” 列显示本地地址和端口号;“Foreign Address” 列显示远程地址和端口号;“State” 列表示连接的状态,常见的状态有 LISTEN(监听)、ESTABLISHED(已建立连接)、TIME_WAIT(等待一段时间后关闭连接)等 。通过查看这些信息,我们可以判断网络连接是否正常,是否存在异常的连接状态,从而找出可能导致丢包的原因。
netstat 命令还可以用来查看路由表,了解数据包在网络中的传输路径。在终端中输入 “netstat -r”,就能显示内核的 IP 路由表 。“-r” 参数用于显示路由表。路由表中包含了网络目的地址、子网掩码、网关、接口等信息 。通过分析路由表,我们可以检查路由是否正确,是否存在路由错误导致数据包无法正确转发的情况。如果发现路由表中有错误的路由条目,比如路由指向了错误的网关,就需要及时进行修正,以解决丢包问题。
查看网络接口统计信息也是 netstat 命令的重要功能之一。在终端中输入 “netstat -s”,可以打印出网络协议的统计数据 。“-s” 参数用于打印统计数据。在输出结果中,我们可以看到各个网络协议(如 TCP、UDP、ICMP 等)的数据包发送和接收数量、错误数量、丢弃数量等信息 。通过分析这些统计信息,我们可以判断网络接口是否正常工作,是否存在大量的数据包被丢弃的情况。如果发现某个协议的丢弃数据包数量较多,就需要进一步排查原因,可能是网络接口故障、网络拥塞或者其他问题导致的。
4.4 ethtool检查网卡状态
ethtool 工具是专门用于管理和诊断以太网卡的利器,在排查 Linux 服务器丢包问题时,它能帮助我们深入了解网卡的配置和运行状态,判断网卡是否存在硬件或驱动相关的丢包问题,就像一位专业的医生,为网卡进行全面的 “体检”。
使用 ethtool 工具查看网卡配置非常简单。在终端中输入 “ethtool 网卡名称”,就能获取网卡的详细配置信息 。比如要查看 eth0 网卡的配置,输入 “ethtool eth0” 。在输出结果中,我们可以看到网卡的支持的端口类型、链路模式、自动协商状态、速度、双工模式等信息 。通过检查这些配置信息,我们可以判断网卡的配置是否正确,是否与网络环境相匹配。如果发现网卡的配置与网络要求不一致,比如网卡被设置为半双工模式,而网络环境要求全双工模式,就需要及时调整网卡配置,以避免丢包问题的发生。
ethtool 工具还可以查看网卡的统计信息,这对于判断网卡是否存在丢包问题非常有帮助。在终端中输入 “ethtool -S 网卡名称”,可以显示网卡和驱动特定的统计参数 。“-S” 参数用于显示统计参数。在输出结果中,我们重点关注与丢包相关的统计项,如 “rx_dropped”(接收丢弃的数据包数量)、“tx_dropped”(发送丢弃的数据包数量)、“rx_errors”(接收错误的数据包数量)、“tx_errors”(发送错误的数据包数量)等 。如果这些统计项的数值不断增加,就说明网卡可能存在丢包问题。当 “rx_dropped” 的数值持续上升时,可能是网卡接收缓冲区溢出,导致数据包被丢弃;当 “tx_errors” 的数值较大时,可能是网卡发送数据时出现了错误,需要进一步检查网卡硬件或驱动是否正常。
除了查看配置和统计信息,ethtool 工具还能对网卡进行一些设置和操作。使用 “ethtool -s 网卡名称 speed 1000 duplex full autoneg off” 命令,可以强制设置网卡的速度为 1000Mbps、全双工模式,并关闭自动协商 。当怀疑网卡的自动协商功能出现问题,导致与网络设备的连接不稳定时,可以通过这种方式强制设置网卡参数,看是否能解决丢包问题。使用 “ethtool -r 网卡名称” 命令,可以重置网卡到自适应模式 。如果网卡在某些情况下出现异常,重置到自适应模式可能会使其恢复正常工作状态。
4.5 tcpdump抓包分析
tcpdump 命令是网络数据包分析的得力助手,它可以抓取网络数据包,并对这些数据包进行分析,帮助我们深入了解网络通信的细节,找出丢包的具体原因,就像一位经验丰富的侦探,通过对现场线索的分析来解开谜团。
在 Linux 系统中使用 tcpdump 命令抓取网络数据包时,我们可以通过一些参数来灵活控制抓取的范围和条件。在终端中输入 “tcpdump -i 网卡名称”,可以指定在特定的网卡上抓取数据包 。“-i” 参数用于指定网卡名称。比如要在 eth0 网卡上抓取数据包,输入 “tcpdump -i eth0” 。这样,tcpdump 就会开始捕获 eth0 网卡上传输的所有数据包。如果只想抓取特定协议的数据包,可以使用 “-p” 参数 。使用 “tcpdump -i eth0 -p tcp”,表示只抓取 eth0 网卡上的 TCP 协议数据包。如果要抓取特定 IP 地址或端口的数据包,可以使用 “host”“src”“dst”“port” 等参数 。使用 “tcpdump -i eth0 host 192.168.1.100”,表示只抓取与 IP 地址为 192.168.1.100 的主机相关的数据包;使用 “tcpdump -i eth0 port 80”,表示只抓取端口号为 80 的数据包,通常用于抓取 HTTP 协议的数据包。
抓取到数据包后,就需要对这些数据包进行分析,以找出丢包的原因。tcpdump 命令的输出结果包含了数据包的详细信息,如时间戳、源 IP 地址、目的 IP 地址、协议类型、端口号、数据包内容等 。通过分析这些信息,我们可以判断数据包是否正常传输,是否存在异常的数据包行为。
如果发现某个时间段内有大量的重传数据包,就说明可能存在丢包问题,导致数据需要重新传输 。重传数据包的出现可能是因为网络拥塞、信号干扰、链路故障等原因,我们需要进一步排查这些因素,找出具体的丢包原因。如果发现数据包的目的 IP 地址或端口号与预期不符,也可能是网络配置错误或受到了攻击,导致数据包被错误地发送或丢弃,需要及时进行检查和修复。
执行下面的 tcpdump 命令,抓取 80 端口的包如下:
tcpdump -i eth0 -nn port 80
#输出
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on eth0, link-type EN10MB (Ethernet), capture size 262144 bytes然后,切换到终端二中,再次执行前面的 curl 命令:
curl --max-time 3 http://192.168.0.30
curl: (28) Operation timed out after 3000 milliseconds with 0 bytes received等到 curl 命令结束后,再次切换回终端一,查看 tcpdump 的输出:
14:40:00.589235 IP 10.255.255.5.39058 > 172.17.0.2.80: Flags [S], seq 332257715, win 29200, options [mss 1418,sackOK,TS val 486800541 ecr 0,nop,wscale 7], length 0
14:40:00.589277 IP 172.17.0.2.80 > 10.255.255.5.39058: Flags [S.], seq 1630206251, ack 332257716, win 4880, options [mss 256,sackOK,TS val 2509376001 ecr 486800541,nop,wscale 7], length 0
14:40:00.589894 IP 10.255.255.5.39058 > 172.17.0.2.80: Flags [.], ack 1, win 229, options [nop,nop,TS val 486800541 ecr 2509376001], length 0
14:40:03.589352 IP 10.255.255.5.39058 > 172.17.0.2.80: Flags [F.], seq 76, ack 1, win 229, options [nop,nop,TS val 486803541 ecr 2509376001], length 0
14:40:03.589417 IP 172.17.0.2.80 > 10.255.255.5.39058: Flags [.], ack 1, win 40, options [nop,nop,TS val 2509379001 ecr 486800541,nop,nop,sack 1 {76:77}], length 0从 tcpdump 的输出中,我们就可以看到:
-
前三个包是正常的 TCP 三次握手,这没问题;
-
但第四个包却是在 3 秒以后了,并且还是客户端(VM2)发送过来的 FIN 包,说明客户端的连接关闭了
在实际使用 tcpdump 命令时,为了更好地分析数据包,我们还可以将抓取到的数据包保存到文件中,然后使用其他工具进行进一步的分析。使用 “tcpdump -i eth0 -w packet.cap” 命令,可以将抓取到的数据包保存到名为 packet.cap 的文件中 。“-w” 参数用于指定保存数据包的文件名。保存好数据包文件后,我们可以使用 Wireshark 等专业的网络协议分析工具打开这个文件,进行更加详细和直观的分析 。Wireshark 提供了图形化的界面,能够以更清晰的方式展示数据包的结构和内容,方便我们快速定位问题。
根据 curl 设置的 3 秒超时选项,你应该能猜到,这是因为 curl 命令超时后退出了。用 Wireshark 的 Flow Graph 来表示,你可以更清楚地看到上面这个问题:
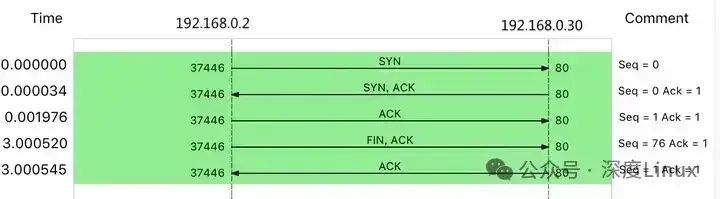
这里比较奇怪的是,我们并没有抓取到 curl 发来的 HTTP GET 请求。那究竟是网卡丢包了,还是客户端就没发过来呢?
可以重新执行 netstat -i 命令,确认一下网卡有没有丢包问题:
netstat -i
Kernel Interface table
Iface MTU RX-OK RX-ERR RX-DRP RX-OVR TX-OK TX-ERR TX-DRP TX-OVR Flg
eth0 100 157 0 344 0 94 0 0 0 BMRU
lo 65536 0 0 0 0 0 0 0 0 LRU从 netstat 的输出中,你可以看到,接收丢包数(RX-DRP)是 344,果然是在网卡接收时丢包了。不过问题也来了,为什么刚才用 hping3 时不丢包,现在换成 GET 就收不到了呢?还是那句话,遇到搞不懂的现象,不妨先去查查工具和方法的原理。我们可以对比一下这两个工具:
-
hping3 实际上只发送了 SYN 包;
-
curl 在发送 SYN 包后,还会发送 HTTP GET 请求。HTTP GET本质上也是一个 TCP 包,但跟 SYN 包相比,它还携带了 HTTP GET 的数据。
通过这个对比,你应该想到了,这可能是 MTU 配置错误导致的。为什么呢?
其实,仔细观察上面 netstat 的输出界面,第二列正是每个网卡的 MTU 值。eth0 的 MTU只有 100,而以太网的 MTU 默认值是 1500,这个 100 就显得太小了。当然,MTU 问题是很好解决的,把它改成 1500 就可以了。
ifconfig eth0 mtu 1500修改完成后,再切换到终端二中,再次执行 curl 命令,确认问题是否真的解决了:
curl --max-time 3 http://192.168.0.30/
#输出
<!DOCTYPE html>
<html>
...
<p><em>Thank you for using nginx.</em></p>
</body>
</html>非常不容易呀,这次终于看到了熟悉的 Nginx 响应,说明丢包的问题终于彻底解决了。
五、针对不同原因的解决策略
5.1物理链路问题处理
当怀疑是物理链路问题导致 Linux 服务器丢包时,我们可以从以下几个方面进行处理。首先是更换网线,在更换网线时,要选择质量可靠的网线。优质的网线在材质和工艺上更有保障,能有效减少信号衰减和干扰。在购买网线时,要注意查看网线的参数和质量认证标志,选择符合网络环境需求的规格。如果网络环境要求高速稳定的传输,就应选择超五类或六类网线 。更换网线的过程并不复杂,先将两端的网线插头从设备上拔下,然后插入新的网线插头即可。在插拔网线时,要注意力度适中,避免损坏设备接口。
检查并紧固接口也是非常重要的一步。仔细检查网络设备之间的所有接口,包括服务器网卡接口、交换机接口、路由器接口等 。查看接口是否有松动、氧化、变形等情况。对于松动的接口,要重新插拔网线,确保插头与接口紧密连接。在插拔网线时,可以听到 “咔哒” 一声,这表示插头已经正确插入接口 。对于氧化的接口,可以使用橡皮擦轻轻擦拭接口金属部分,去除氧化物,以提高接口的导电性 。对于变形的接口,要及时更换相关设备,避免影响网络连接。
排查和更换故障网络设备同样不容忽视。如果经过检查发现是路由器或交换机出现故障,应及时进行维修或更换 。在更换网络设备时,要选择与原设备性能相当或更好的设备,并确保新设备的配置与网络环境相匹配 。如果原交换机是千兆交换机,那么在更换时也应选择千兆交换机,以保证网络的传输速度。在更换设备前,要备份好原设备的配置信息,以便在新设备上快速恢复配置 。更换设备后,要重新测试网络连接,确保网络恢复正常。
5.2网卡与驱动修复
硬件检查与更换:判断网卡硬件是否故障,可以通过多种方法。首先观察网卡指示灯的状态,如果指示灯不亮或者闪烁异常,就可能表示网卡存在硬件问题 。正常情况下,网卡指示灯应该是稳定亮起或者有规律地闪烁。使用硬件检测工具也能帮助我们判断网卡硬件是否正常。一些服务器管理软件提供了硬件检测功能,可以对网卡进行全面的检测 。如果确定网卡硬件出现故障,在更换网卡时,要注意选择与服务器兼容的网卡 。不同型号的服务器对网卡的兼容性可能不同,在购买网卡时,要查看服务器的硬件兼容性列表,选择列表中推荐的网卡型号 。在安装新网卡时,要先关闭服务器电源,然后将新网卡插入服务器的 PCI 插槽中 。插入时要注意方向正确,确保网卡与插槽紧密接触。安装完成后,再打开服务器电源,让系统自动识别新网卡。
驱动更新与修复:要获取和安装最新的网卡驱动,首先需要确定网卡的型号。可以通过查看服务器硬件手册、在系统中使用命令 “lspci | grep -i network” 等方式来确定网卡型号 。确定型号后,前往网卡制造商的官方网站,在支持页面中搜索对应型号的最新驱动程序 。下载驱动程序时,要注意选择与服务器操作系统版本相匹配的驱动 。如果服务器使用的是 CentOS 7 系统,就需要下载适用于 CentOS 7 的网卡驱动。下载完成后,按照驱动安装说明进行安装。一般来说,驱动安装包中会包含安装指南,按照指南中的步骤进行操作即可 。
如果遇到驱动程序损坏的情况,可以尝试修复驱动程序。在 Linux 系统中,可以使用 “modprobe -r 驱动名” 命令先卸载损坏的驱动模块 。然后重新加载驱动模块,使用 “modprobe 驱动名” 命令 。如果问题仍然存在,可以尝试从系统备份中恢复驱动程序文件。如果在安装系统时进行了备份,可以从备份中提取出正确的驱动程序文件,然后将其覆盖到原驱动文件所在的目录 。在恢复驱动文件时,要注意文件的权限和路径设置,确保文件能够被系统正确识别和使用。
4.3协议栈参数优化
①链路层优化:调整 QoS 参数时,需要根据网络中不同应用的需求来进行设置。对于实时性要求较高的应用,如视频会议、在线游戏等,要为它们分配较高的优先级,确保这些应用的数据包能够优先传输 。在 Linux 系统中,可以使用 tc(traffic control)工具来配置 QoS 参数 。使用 “tc qdisc add dev eth0 root handle 1: prio” 命令可以在 eth0 网卡上添加一个优先级队列 。然后使用 “tc filter add dev eth0 parent 1: protocol ip prio 1 u32 match ip dport 80 0xffff flowid 1:1” 命令将目的端口为 80(通常用于 HTTP 协议)的数据包设置为优先级 1 。这样,在网络拥塞时,HTTP 协议的数据包会优先被处理,减少丢包的可能性。
修复链路层配置错误也是优化的重要环节。仔细检查链路层的配置文件,如 /etc/network/interfaces(基于 Debian 系统)或 /etc/sysconfig/network-scripts/ifcfg-eth0(基于 Red Hat 系统) 。确保文件中的配置项正确无误,如 MAC 地址、子网掩码、网关等 。如果发现配置错误,及时进行修改,然后重启网络服务,使新的配置生效 。在 Debian 系统中,可以使用 “sudo systemctl restart networking” 命令重启网络服务;在 Red Hat 系统中,可以使用 “sudo systemctl restart network” 命令 。
②网络层优化:正确配置路由是网络层优化的关键。如果是静态路由,要确保路由表中的路由条目准确无误。使用 “route -n” 命令可以查看当前系统的路由表 。如果发现路由表中有错误的路由条目,比如路由指向了错误的网关,就需要使用 “route del -net 目标网络 netmask 子网掩码 gw 错误网关” 命令删除错误的路由条目,然后使用 “route add -net 目标网络 netmask子网掩码gw正确网关” 命令添加正确的路由 。如果是动态路由,要确保路由协议的配置正确,如 RIP、OSPF 等 。检查路由协议的参数设置,如邻居路由器的 IP 地址、认证信息等 。
合理设置 MTU 值也能有效避免网络层丢包。首先需要确定网络中最小的 MTU 值。可以通过在网络中使用 ping 命令并逐渐增大数据包大小的方式来测试 。使用 “ping -s 1400 -M do 目标 IP 地址” 命令(其中 1400 是数据包大小,可以根据实际情况调整),如果返回 “Packet needs to be fragmented but DF set” 错误,说明当前数据包大小超过了链路的 MTU 值 。逐渐减小数据包大小,直到不再出现该错误,此时的数据包大小就是链路的 MTU 值 。确定 MTU 值后,在服务器的网络配置文件中设置 MTU 值 。在 /etc/network/interfaces 文件中,添加或修改 “mtu 确定的 MTU 值” 配置项 。
③ 传输层优化:调整端口监听配置时,要确保应用程序正确监听其对应的端口。使用 netstat 命令检查端口的监听状态,如 “netstat -an | grep 端口号” 。如果发现端口未被正确监听,检查应用程序的配置文件,确保监听端口的设置正确 。对于一些网络服务,如 Web 服务器、FTP 服务器等,要确保它们的配置文件中指定的监听端口与实际需求一致 。如果需要修改监听端口,在修改配置文件后,重启应用程序,使新的配置生效 。
优化内核资源限制参数也很重要。在 Linux 系统中,内核为网络连接分配了一定的资源,如内存、文件描述符等 。可以通过修改内核参数来优化这些资源的分配 。编辑 /etc/sysctl.conf 文件,添加或修改以下参数:“net.core.somaxconn = 65535”(设置 TCP 监听队列的最大长度)、“net.ipv4.tcp_max_tw_buckets = 6000”(设置 TIME_WAIT 状态的最大数量)、“net.ipv4.tcp_keepalive_time = 1200”(设置 TCP 连接保持活动的时间)等 。修改完成后,使用 “sudo sysctl -p” 命令使新的参数生效 。这些参数的调整可以根据服务器的实际负载情况和网络环境进行优化,以提高传输层的性能,减少丢包现象。
4.4系统与应用优化
①系统负载优化:降低系统负载可以从多个方面入手。优化进程调度是其中之一,在 Linux 系统中,可以使用 top 命令查看当前系统中各个进程的资源占用情况 。如果发现某个进程占用了大量的 CPU 或内存资源,且该进程并非必要进程,可以考虑结束该进程 。使用 “kill -9 进程 ID” 命令可以强制结束进程 。但在结束进程时要谨慎操作,确保不会影响系统的正常运行。
关闭不必要的服务也是降低系统负载的有效方法。使用 “systemctl list-unit-files --type=service” 命令可以列出系统中所有的服务 。检查这些服务,找出那些当前不需要运行的服务,如一些默认启动但实际未使用的网络服务 。使用 “systemctl stop 服务名” 命令可以停止这些服务,使用 “systemctl disable 服务名” 命令可以禁止这些服务在系统启动时自动运行 。通过关闭不必要的服务,可以释放系统资源,使系统有更多的资源用于处理网络请求,从而减少丢包现象的发生。
②应用程序修复:排查应用程序的内存泄漏问题可以使用一些工具,如 valgrind 。valgrind 是一个功能强大的内存调试工具,它可以检测出应用程序中的内存泄漏、内存越界等问题 。使用 valgrind 运行应用程序,如 “valgrind --leak-check=full./ 应用程序名” 。valgrind 会在应用程序运行结束后,输出详细的内存使用报告,指出是否存在内存泄漏以及泄漏的位置 。根据报告中的信息,对应用程序进行修改,修复内存泄漏问题 。
检查应用程序的逻辑错误也很关键。仔细审查应用程序的代码,检查在处理网络数据时是否存在逻辑错误,如错误的数据包解析、无法正确地发送响应等 。可以使用调试工具,如 gdb,对应用程序进行调试 。在 gdb 中设置断点,逐步执行代码,观察变量的值和程序的执行流程,找出逻辑错误的根源 。一旦发现逻辑错误,及时修改代码,重新编译和部署应用程序,确保应用程序能够正常处理网络数据,避免因应用程序异常导致的丢包问题。
4.5防火墙与 iptables 规则调整
合理配置防火墙策略是确保网络正常通信的重要步骤。在配置防火墙时,要遵循最小权限原则,只允许必要的网络流量通过 。如果服务器只提供 Web 服务,那么只需要开放 80 端口(HTTP 协议)和 443 端口(HTTPS 协议)即可 。在 Linux 系统中,可以使用 iptables 命令来配置防火墙策略 。
使用 “iptables -A INPUT -p tcp --dport 80 -j ACCEPT” 命令允许 TCP 协议的 80 端口的流量进入服务器 。使用 “iptables -A INPUT -p tcp --dport 443 -j ACCEPT” 命令允许 TCP 协议的 443 端口的流量进入服务器 。同时,要拒绝其他不必要的流量,使用 “iptables -A INPUT -j DROP” 命令拒绝所有未明确允许的流量 。
检查和修正 iptables 规则时,要仔细查看规则的顺序和内容 。iptables 规则是按照顺序匹配的,所以规则的顺序非常重要 。确保允许规则在拒绝规则之前,否则允许规则将不会生效 。使用 “iptables -L -n” 命令可以查看当前的 iptables 规则列表 。如果发现规则错误,如 DROP 规则设置不当,导致正常的数据包被丢弃,使用 “iptables -D 链名 规则序号” 命令删除错误的规则 。
如果要删除 INPUT 链中的第 3 条规则,使用 “iptables -D INPUT 3” 命令 。然后根据实际需求,重新添加正确的规则 。通过合理配置防火墙策略和检查修正 iptables 规则,可以避免因防火墙和规则错误导致的丢包问题,确保网络的正常运行。
六、实战演练:排查与解决 Nginx 丢包问题
理论上的分析固然重要,但实际操作才是检验真理的关键。下面,我们将通过一个具体的案例,以 Nginx 应用为例,深入探讨如何在实际场景中排查和解决网络丢包问题。
6.1模拟访问与初步判断
假设我们在一台 Linux 服务器上部署了 Nginx 应用,现在怀疑它存在网络丢包问题。我们首先使用 hping3 命令来模拟访问 Nginx 服务。hping3 是一个功能强大的网络工具,它可以发送各种类型的网络数据包,帮助我们测试网络的连通性和性能。执行以下命令:
hping3 -c 10 -S -p 80 192.168.0.30在这个命令中,-c 10表示发送 10 个请求包,-S表示使用 TCP SYN 标志位,-p 80指定目标端口为 80,即 Nginx 服务默认的端口,192.168.0.30是 Nginx 服务器的 IP 地址。执行命令后,我们得到如下输出:
HPING 192.168.0.30 (eth0 192.168.0.30): S set, 40 headers + 0 data bytes
len=44 ip=192.168.0.30 ttl=63 DF id=0 sport=80 flags=SA seq=3 win=5120 rtt=7.5 ms
len=44 ip=192.168.0.30 ttl=63 DF id=0 sport=80 flags=SA seq=4 win=5120 rtt=7.4 ms
len=44 ip=192.168.0.30 ttl=63 DF id=0 sport=80 flags=SA seq=5 win=5120 rtt=3.3 ms
len=44 ip=192.168.0.30 ttl=63 DF id=0 sport=80 flags=SA seq=7 win=5120 rtt=3.0 ms
len=44 ip=192.168.0.30 ttl=63 DF id=0 sport=80 flags=SA seq=6 win=5120 rtt=3027.2 ms
--- 192.168.0.30 hping statistic ---
10 packets transmitted, 5 packets received, 50% packet loss
round-trip min/avg/max = 3.0/609.7/3027.2 ms从输出结果中,我们可以清晰地看到,总共发送了 10 个请求包,但只收到了 5 个回复包,丢包率高达 50%。而且,每个请求的 RTT(往返时间)波动非常大,最小值只有 3.0ms,而最大值却达到了 3027.2ms,这表明网络中很可能存在丢包现象。
6.2链路层排查
初步判断存在丢包问题后,我们首先从链路层开始排查。使用netstat -i命令查看虚拟网卡的丢包记录:
netstat -i得到如下输出:
Kernel Interface table
Iface MTU RX-OK RX-ERR RX-DRP RX-OVR TX-OK TX-ERR TX-DRP TX-OVR Flg
eth0 100 31 0 0 0 8 0 0 0 BMRU
lo 65536 0 0 0 0 0 0 0 0 LRUR在这个输出中,RX-OK表示接收时的总包数,RX-ERR表示总错误数,RX-DRP表示进入 Ring Buffer 后因其他原因(如内存不足)导致的丢包数,RX-OVR表示 Ring Buffer 溢出导致的丢包数,TX-OK至TX-OVR则表示发送时的相应指标。从这里可以看出,虚拟网卡的各项错误指标均为 0,说明虚拟网卡本身没有丢包。
不过,如果使用tc等工具配置了 QoS(Quality of Service,服务质量),tc规则导致的丢包不会包含在网卡的统计信息中。因此,我们还需要检查eth0上是否配置了tc规则,并查看是否有丢包。添加-s选项以输出统计信息:
tc -s qdisc show dev eth0输出结果如下:
qdisc netem 800d: root refcnt 2 limit 1000 loss 30%
Sent 432 bytes 8 pkt (dropped 4, overlimits 0 requeues 0)
backlog 0b 0p requeues 0可以看到,eth0上配置了一个网络模拟排队规则qdisc netem,并且设置了丢包率为 30%(loss 30%)。从后面的统计信息可知,发送了 8 个包,但丢了 4 个。这很可能就是导致 Nginx 回复的响应包被netem模块丢弃的原因。既然找到了问题,解决方法就很简单,直接删除netem模块:
tc qdisc del dev eth0 root netem loss 30%删除后,重新执行hping3命令,看看问题是否解决。然而,从hping3的输出中发现,仍然有 50% 的丢包,RTT 波动依旧很大,说明问题还未得到解决,需要继续向上层排查。
6.3网络层和传输层排查
接下来,我们排查网络层和传输层。在这两层中,引发丢包的因素众多,但确认是否丢包却相对简单,因为 Linux 已经为我们提供了各个协议的收发汇总情况。执行netstat -s命令,查看 IP、ICMP、TCP 和 UDP 等协议的收发统计信息:
netstat -s输出结果非常丰富,这里我们重点关注与丢包相关的信息。例如,从 TCP 协议的统计信息中,我们看到有多次超时和失败重试,并且主要错误是半连接重置,这表明可能存在三次握手失败的问题。这可能是由于网络拥塞、端口被占用、防火墙限制等原因导致的。此时,我们需要进一步分析具体的错误原因,可以结合其他工具和命令,如lsof查看端口占用情况,检查防火墙规则等。
6.4iptables 排查
iptables 是 Linux 系统中常用的防火墙工具,其规则配置不当可能导致数据包被丢弃。首先,我们检查内核的连接跟踪机制,查看当前的连接跟踪数和最大连接跟踪数:
cat /proc/sys/net/nf_conntrack_count
cat /proc/sys/net/nf_conntrack_max假设连接跟踪数只有 182,而最大连接跟踪数是 262144,说明连接跟踪数没有达到上限,不存在因连接跟踪数满而导致丢包的问题。
接着,查看 iptables 规则,使用iptables -L -n命令:
iptables -L -n在输出的规则列表中,我们发现有两条DROP规则,使用了statistic模块进行随机 30% 的丢包。这显然是导致丢包的一个重要原因。我们将这两条规则直接删除,然后重新执行hping3命令。此时,hping3的输出显示已经没有丢包,这说明 iptables 的错误规则是导致之前丢包的原因之一。
6.5端口状态检查与进一步排查
虽然hping3验证了 Nginx 的 80 端口处于正常监听状态,但还需要检查 Nginx 对 HTTP 请求的响应。使用curl命令:
curl -w 'Http code: %{http_code}\\nTotal time:%{time_total}s\\n' -o /dev/null --connect-timeout 10 http://192.168.0.30/结果发现连接超时,这表明虽然端口监听正常,但 Nginx 在处理 HTTP 请求时可能存在问题。为了进一步分析,我们使用tcpdump命令抓包:
tcpdump -i eth0 -n tcp port 80在另一个终端执行curl命令,然后查看tcpdump的输出。发现前三个包是正常的 TCP 三次握手,但第四个包却是在 3 秒后才收到,并且是客户端发送过来的 FIN 包,这说明客户端的连接已经关闭。
重新执行netstat -i命令,检查网卡是否有丢包,发现果然是在网卡接收时丢包了。进一步检查最大传输单元 MTU(Maximum Transmission Unit):
ifconfig eth0 | grep MTU发现eth0的 MTU 只有 100,而以太网的 MTU 默认值是 1500。MTU 过小可能导致数据包在传输过程中需要分片,从而增加丢包的风险。我们将 MTU 修改为 1500:
ifconfig eth0 mtu 1500再次执行curl命令,问题得到解决,Nginx 能够正常响应 HTTP 请求。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









