






3.1能够熟练使用Linux,并在Linux部署相关应用
3.2解JVM性能调优、了解常见JVM垃圾收集算法、Java并发框架与库、了解Java内存模型
1Java并发框架与库
2Java内存模型
java-memory-model| 屏障类型 | 指令示例 | 说明 |
| LoadLoad Barriers | Load1; LoadLoad; Load2 | 确保Load1数据的装载,之前于Load2及所有后续装载指令的装载。 |
| StoreStore Barriers | Store1; StoreStore; Store2 | 确保Store1数据对其他处理器可见(刷新到内存),之前于Store2及所有后续存储指令的存储。 |
| LoadStore Barriers | Load1; LoadStore; Store2 | 确保Load1数据装载,之前于Store2及所有后续的存储指令刷新到内存。 |
| StoreLoad Barriers | Store1; StoreLoad; Load2 | 确保Store1数据对其他处理器变得可见(指刷新到内存),之前于Load2及所有后续装载指令的装载。StoreLoad Barriers会使该屏障之前的所有内存访问指令(存储和装载指令)完成之后,才执行该屏障之后的内存访问指令。 |
StoreLoad Barriers是一个“全能型”的屏障,它同时具有其他三个屏障的效果。现代的多处理器大都支持该屏障(其他类型的屏障不一定被所有处理器支持)。执行该屏障开销会很昂贵,因为当前处理器通常要把写缓冲区中的数据全部刷新到内存中(buffer fully flush)。
happens-before
从JDK5开始,java使用新的JSR -133内存模型(本文除非特别说明,针对的都是JSR- 133内存模型)。JSR-133提出了happens-before的概念,通过这个概念来阐述操作之间的内存可见性。如果一个操作执行的结果需要对另一个操作可见,那么这两个操作之间必须存在happens-before关系。这里提到的两个操作既可以是在一个线程之内,也可以是在不同线程之间。 与程序员密切相关的happens-before规则如下:
- 程序顺序规则:一个线程中的每个操作,happens- before 于该线程中的任意后续操作。
- 监视器锁规则:对一个监视器锁的解锁,happens- before 于随后对这个监视器锁的加锁。
- volatile变量规则:对一个volatile域的写,happens- before 于任意后续对这个volatile域的读。
- 传递性:如果A happens- before B,且B happens- before C,那么A happens- before C。
3JVM内存模型
方法区域存放了所加载的类的信息(名称、修饰符等)、类中的静态变量、类中定义为final类型的常量、类中的Field信息、类中的方法信息,当开发人员在程序中通过Class对象中的getName、isInterface等方法来获取信息时,这些数据都来源于方法区域,可见方法区域的重要性。同样,方法区域也是全局共享的,它在虚拟机启动时在一定的条件下它也会被GC,当方法区域需要使用的内存超过其允许的大小时,会抛出OutOfMemory的错误信息。
在Sun JDK中这块区域对应的为PermanetGeneration,又称为持久代,默认为64M,可通过-XX:PermSize以及-XX:MaxPermSize来指定其大小。
),本地方法栈和运行时常量池(就是面试题里String 放值的地方)。4垃圾收集算法
a) 虚拟机栈(栈帧中的本地变量表)中的引用的对象。
b) 方法区域中的类静态属性引用的对象。
c) 方法区域中常量引用的对象。
d) 本地方法栈中JNI(Native方法)的引用的对象。
复制算法实现简单,运行效率高,但是由于每次只能使用其中的一半,造成内存的利用率不高。现在的JVM用复制方法收集新生代,由于新生代中大部分对象(98%)都是朝生夕死的,所以两块内存的比例不是1:1(大概是8:1)。
垃圾回收前:
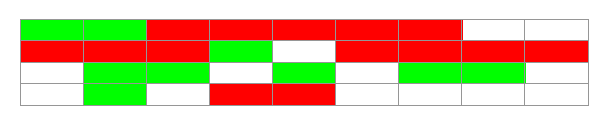
垃圾回收后:

绿色:存活对象 红色:可回收对象 白色:未使用空间
3标记—整理算法和标记—清除算法一样,但是标记—整理算法不是把存活对象复制到另一块内存,而是把存活对象往内存的一端移动,然后直接回收边界以外的内存。
标记—整理算法提高了内存的利用率,并且它适合在收集对象存活时间较长的老年代。
4.分代收集(Generational Collection)
分代收集是根据对象的存活时间把内存分为新生代和老年代,根据个代对象的存活特点,每个代采用不同的垃圾回收算法。新生代采用标记—复制算法,老年代采用标记—整理算法。
垃圾算法的实现涉及大量的程序细节,而且不同的虚拟机平台实现的方法也各不相同。上面介绍的只不过是基本思想。
上面这部分算法是从其他博客转过来的,而且垃圾回收算法根据角度不同还有很多种,因为JVM规范只是说你要有所作为在堆满了的时候,没说到底怎么做,所以是八仙过海各显神通,
上面这四种是最基本的垃圾回收算法,在这四种算法思想之上发展出来其余算法,个人认为更多的是一种内存管理策略,甚至可以看成就是基本算法的组合应用,就像加减乘除与方程式的关系一样,因此将其分开描述。
渐进式算法
这类算法一般由基本算法组成,其核心思想是将内存分区域进行管理,在不同的区域和不同的时间采用不同的内存管理策略,从而避免因全系统的垃圾回收导致程序长时间暂停。这类算法一般有以下几种:
1.火车算法
这种算法把成熟的内存空间划为固定长度的内存块,算法每次在一个块中单独执行,每一个块属于一个集合。此算法的具体执行步骤较复杂,且没有具体的应用场景,在此不浪费笔墨,有兴趣的同学可以自己研究之。
2.分代收集算法
这种算法在sun/oracle公司的Hotspot虚拟机中得到应用,是java程序员需要重点关注的一种算法。
这种算法是通过对对象的生命周期进行分析后得出的,它将堆内存分成了三个部分:年青代,年老代,持久代(相当于方法区)。处于不同生命周期的对象被存储于不同的区域,并使用不同的算法进行回收。这种算法的具体执行细节将会在后续的学习笔记中详细介绍。
从网上得到的资料来看,应该还有一种增量收集算法,但是描述过于模糊,且没有标明出处,查不到相关资料,marker下,回头如有发现再回来补之。
另外需要特别注意的是利用多线程实现的堆垃圾回收技术,这方面资料来源于网络,摘抄如下:
1.串行收集
串行收集使用单线程处理所有垃圾回收工作,因为无需多线程交互,实现容易,而且效率比较高。但是,其局限性也比较明显,即无法使用多处理器的优势,所以此收集适合单处理器机器。当然,此收集器也可以用在小数据量(100M左右)情况下的多处理器机器上。
适用情况:数据量比较小(100M左右);单处理器下并且对响应时间无要求的应用。
缺点:只能用于小型应用。
2.并行收集
并行收集使用多线程处理垃圾回收工作,因而速度快,效率高。而且理论上CPU数目越多,越能体现出并行收集器的优势。
适用情况:“对吞吐量有高要求”,多CPU、对应用响应时间无要求的中、大型应用。举例:后台处理、科学计算。
缺点:应用响应时间可能较长 。
3.并发收集
相对于串行收集和并行收集而言,前面两个在进行垃圾回收工作时,需要暂停整个运行环境,而只有垃圾回收程序在运行,因此,系统在垃圾回收时会有明显的暂停,而且暂停时间会因为堆越大而越长。
适用情况:“对响应时间有高要求”,多CPU、对应用响应时间有较高要求的中、大型应用。举例:Web服务器/应用服务器、电信交换、集成开发环境。
在调优之前,我们需要记住下面的原则:
1、多数的Java应用不需要在服务器上进行GC优化;
2、多数导致GC问题的Java应用,都不是因为我们参数设置错误,而是代码问题;意味着一般的参数设置足够用了
3、在应用上线之前,先考虑将机器的JVM参数设置到最优(最适合);
4、减少创建对象的数量;
5、减少使用全局变量和大对象;
6、GC优化是到最后不得已才采用的手段;意味着JVM自带的GC策略已经足够用了
7、在实际使用中,分析GC情况优化代码比优化GC参数要多得多;
5JVM调优
Q:为什么崩溃前垃圾回收的时间越来越长?
A:根据内存模型和垃圾回收算法,垃圾回收分两部分:内存标记、清除(复制),标记部分只要内存大小固定时间是不变的,变的是复制部分,因为每次垃圾回收都有一些回收不掉的内存,所以增加了复制量,导致时间延长。所以,垃圾回收的时间也可以作为判断内存泄漏的依据
Q:为什么Full GC的次数越来越多?
A:因此内存的积累,逐渐耗尽了年老代的内存,导致新对象分配没有更多的空间,从而导致频繁的垃圾回收
Q:为什么年老代占用的内存越来越大?
A:因为年轻代的内存无法被回收,越来越多地被Copy到年老代
调优是为了1减少年老代空间2减少FULLGC时间
为了达到上面的目的,一般地,你需要做的事情有:
1、减少使用全局变量和大对象;
2、调整新生代的大小到最合适;
3、设置老年代的大小为最合适;
4、选择合适的GC收集器;
性能调优方法:
1线程池
2连接池
3启动参数
(1)针对JVM堆的设置,一般可以通过-Xms -Xmx限定其最小、最大值,为了防止垃圾收集器在最小、最大之间收缩堆而产生额外的时间,我们通常把最大、最小设置为相同的值
(2)年轻代和年老代将根据默认的比例(1:2)分配堆内存,可以通过调整二者之间的比率NewRadio来调整二者之间的大小,也可以针对回收代,比如年轻代,通过 -XX:newSize -XX:MaxNewSize来设置其绝对大小。同样,为了防止年轻代的堆收缩,我们通常会把-XX:newSize -XX:MaxNewSize设置为同样大小
(3)年轻代和年老代设置多大才算合理?这个我问题毫无疑问是没有答案的,否则也就不会有调优。我们观察一下二者大小变化有哪些影响
- 更大的年轻代必然导致更小的年老代,大的年轻代会延长普通GC的周期,但会增加每次GC的时间;小的年老代会导致更频繁的Full GC
- 更小的年轻代必然导致更大年老代,小的年轻代会导致普通GC很频繁,但每次的GC时间会更短;大的年老代会减少Full GC的频率
- 如何选择应该依赖应用程序对象生命周期的分布情况:如果应用存在大量的临时对象,应该选择更大的年轻代;如果存在相对较多的持久对象,年老代应该适当增大。但很多应用都没有这样明显的特性,在抉择时应该根据以下两点:(A)本着Full GC尽量少的原则,让年老代尽量缓存常用对象,JVM的默认比例1:2也是这个道理 (B)通过观察应用一段时间,看其他在峰值时年老代会占多少内存,在不影响Full GC的前提下,根据实际情况加大年轻代,比如可以把比例控制在1:1。但应该给年老代至少预留1/3的增长空间
(4)在配置较好的机器上(比如多核、大内存),可以为年老代选择并行收集算法: -XX:+UseParallelOldGC ,默认为Serial收集
(5)线程堆栈的设置:每个线程默认会开启1M的堆栈,用于存放栈帧、调用参数、局部变量等,对大多数应用而言这个默认值太了,一般256K就足用。理论上,在内存不变的情况下,减少每个线程的堆栈,可以产生更多的线程,但这实际上还受限于操作系统。















 7853
7853

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









