






1熟悉底层中间件、分布式技术(包括缓存、消息系统、热部署、JMX等
首先说说什么是中间件,这个东西看多了你都会晕,其实就是常用的跟你的业务逻辑无关,为你实现功能的组件,比如TOMCAT,JBOSS,NGINX,消息中间件等。
分布式技术这个概念就太大了,所谓分布式就是把一个任务拆分,部署到不同的节点共同处理从而提高处理效率。缓存常用的即使REDIS了,memcache没什么人用了
JMX实在不熟也没使用过有兴趣的自己看吧http://blog.csdn.net/javafreely/article/details/9237799
至于热部署就是在不停止服务器的情况下动态更新和运行代码,http://www.ibm.com/developerworks/cn/java/j-lo-hotdeploy/xi 能找到的都是概念看来离完美或者说普及还有距离啊
消息系统,这个比较常见,比如我们公司的电商系统需要各种通知,这就属于消息系统。比如博主最近在做的传真系统,你在页面上点击了发送实际上只是在后台数据库添加了条任务,那我真正发送成功了后如何去通知用户,就需要用到消息系统。
这个博主明天上班看看代码再说吧。之前用TEAMVIWER远程连接公司电脑,结果发现电脑一旦设了密码就会自动休眠就连不上了蛋疼。
经过对公司代码的检索,发现竟然有使用到JMX的地方,jms用的是阿里巴巴的ROCKETMQ。
这方面不太熟,先这样吧。
2熟悉Maven使用,Git代码管理;熟悉Nginx/Tomcat
公司用了MAVEN,GIT没用还是SVN,这种工具给一段时间熟悉了即可。tomcat之前说过了,NGINX要详细谈谈
NGINX是一个高性能的反向代理,简单说就是决定你的访问会送到哪个服务器上,一般公司有两套系统,当系统进行了升级更新时用用新的替换旧的就是用的NGINX,之前的服务器用APACHE的多,但是性能不好,
之前说过JBOSS和tomcat的区别,这里再结合apache和NGINX一起说说,
APACHE单独用是一个静态服务器,当和JBOSS/TOMCAT一起用是APACHE负责静态和转发。反过来你可以理解为处理静态和作为专业的服务器TOMCAT不如APACHE,不然只用TOMCAT不就可以了么。这时候人们不满足于TOMCAT的性能了,于是有了JETTY,而TOMCAT与JETTY又都是JBOSS集成的WEB容器。
关于MAVEN,首先要说IVY,IVY的问题在于互相依赖,打包的时候异常痛苦,而且如果没有一个持续集成的环境,谁的代码有问题他自己都不知道,找起问题来也很难,所以用了MAVEN,最好配合一个持续集成的平台,MAVEN博主有过研究,但是没那么深入因为工作中他只是一个工具,我给我们小组的项目转完MAVEN后写过一个使用教程,分享给大家。
在实际普及的过程中经常会遇到一些奇怪的问题,后来慢慢也排除了一些坑,比如MAVEN不同版本的差距比较大会导致部署失败,比如MYECLIPSE的版本问题等等,还是要具体问题具体分析,开始的时候组员比较不习惯总觉得有各种问题,这是他们的思维太局限了,没有上升到一个高度,就跟我们公司开始用在线文档管理工具管理每个人的工作情况很多人不理解为什么这么麻烦,他们没有把眼光放在一个管理者的高度去看问题。
文档已上传,审核中所以没有链接,需要的点我名字去找吧。
3有Hadoop, HBase, Storm, Dubbo等经验者优先
很遗憾,之前在北京的公司有用过HADOOP,DUBBO,SOLR技术,做一个大数据搜索的项目,但那时博主还是个菜J虽然现在也是但是那时候太菜,而且那时博主负责的是获取大数据检索出的逻辑并在页面上展示和展示的效果,这里依次说说他们是什么吧。
http://blessht.iteye.com/blog/2095675 这里把HADOOP的前世今生都讲的很清楚了
http://blog.csdn.net/frankiewang008/article/details/41965543 这篇把HBASE讲的很清楚了
我们知道分布式系统可以大大提高处理效率,那么处理大量文件呢?也可以用分布式系统,那么这些文件是如何被存储以及如何在其中进行检索的呢?这就是现在的大数据处理。
HADOOP包括HDFS(Hadoop Distributed File System,Hadoop分布式文件系统和MAPREDUCE,前者是一个理论后者是一种新型数据库。
总的来说Hadoop适合应用于大数据存储和大数据分析的应用,适合于服务器几千台到几万台的集群运行,支持PB级的存储容量。 Hadoop典型应用有:搜索、日志处理、推荐系统、数据分析、视频图像分析、数据保存等。
通俗说MapReduce是一套从海量·源数据提取分析元素最后返回结果集的编程模型,将文件分布式存储到硬盘是第一步,而从海量数据中提取分析我们需要的内容就是MapReduce做的事了。
渐渐的HADOOP形成了一个生态圈,MAPREDUCE基础上产生了HBASE数据库,HBASE利用HDFS作为其文件存储系统,利用MapReduce来处理HBase中的海量数据利,用Zookeeper作为协同服务,主要用于实时随机读/写超大规模数据集。
Map Reduce 是Google提出的一种算法,用于超大型数据集的并行运算。 HDFS 可以支持千万级的大型分布式文件系统。 Zookeeper 提供的功能包括:配置维护、名字服务、分布式同步、组服务等,用于分布式系统的可靠协调系统。
STORM是一个框架,不熟不表。
DUBBO也是一个框架,之所以坚持把不熟的大数据技术写到这里,就是因为这些技术不光可以用于大数据处理,还在负载均衡等很多领域有所应用,下面就谈DUBBO和ZOOKEEPER。
之前说过分布式系统,那么分布式系统之间的互相调用就是RPC,RPC的概念已经提到一个很高的位置了,RMI,WEBSERVICE都可以说是RPC技术,区别就在于使用什么样的协议去互相调用,我们公司目前用的是HESSION,HESSION是基于HTTP的协议。RMI-JRMP协议,WEBSERVICE-SOAP协议。
一个公司如果自己一步步走分布式会是一个痛苦的过程,随着业务发展不断会遇到瓶颈,开始是像我们公司一样NGINX+HESSION,后来发现要把关键服务配上集群,然后当这些都不能满足的时候,就该用上DUBBO了,而DUBBO一般是跟zookeeper配合使用的,DUBBO本身就实现了多少协议,极大的方便了改造过程。
Zookeeper作为Dubbo服务的注册中心,Dubbo原先基于数据库的注册中心,没采用Zookeeper,Zookeeper一个分布式的服务框架,是树型的目录服务的数据存储,能做到集群管理数据 ,这里能很好的作为Dubbo服务的注册中心,Dubbo能与Zookeeper做到集群部署,当提供者出现断电等异常停机时,Zookeeper注册中心能自动删除提供者信息,当提供者重启时,能自动恢复注册数据,以及订阅请求。
那么Zookeeper能作什么事情呢,简单的例子:假设我们有20个搜索引擎的服务器(每个负责总索引中的一部分的搜索任务)和一个总服务器(负责向这20个搜索引擎的服务器发出搜索请求并合并结果集),一个备用的总服务器(负责当总服务器宕机时替换总服务器),一个web的cgi(向总服务器发出搜索请求)。搜索引擎的服务器中的15个服务器提供搜索服务,5个服务器正在生成索引。这20个搜索引擎的服务器经常要让正在提供搜索服务的服务器停止提供服务开始生成索引,或生成索引的服务器已经把索引生成完成可以搜索提供服务了。使用Zookeeper可以保证总服务器自动感知有多少提供搜索引擎的服务器并向这些服务器发出搜索请求,当总服务器宕机时自动启用备用的总服务器。[4] 部署编辑 我需要运行几个ZooKeeper? 你运行一个zookeeper也是可以的,但是在生产环境中,你最好部署3,5,7个节点。部署的越多,可靠性就越高,当然最好是部署奇数个,偶数个不是不可以的,但是zookeeper集群是以宕机个数过半才会让整个集群宕机的,所以奇数个集群更佳。你需要给每个zookeeper 1G左右的内存,如果可能的话,最好有独立的磁盘。 (独立磁盘可以确保zookeeper是高性能的。).如果你的集群负载很重,不要把Zookeeper和RegionServer运行在同一台机器上面。就像DataNodes 和 TaskTrackers一样。[5]
上面这段是百度百科的内容。
大家还可以看这个链接http://cailin.iteye.com/blog/2014486/ 总之ZOOKEEPER最集群的支持是很好的。
dubbo
架构图如下所示:
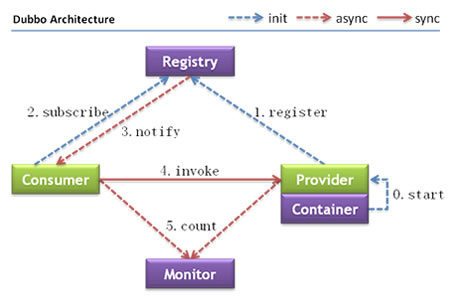
节点角色说明:
Provider: 暴露服务的服务提供方。
Consumer: 调用远程服务的服务消费方。
Registry: 服务注册与发现的注册中心。
Monitor: 统计服务的调用次调和调用时间的监控中心。
Container: 服务运行容器。
这点我觉得非常好,角色分明,可以根据每个节点角色的状态来确定该服务是否正常。
调用关系说明:
0 服务容器负责启动,加载,运行服务提供者。
1. 服务提供者在启动时,向注册中心注册自己提供的服务。
2. 服务消费者在启动时,向注册中心订阅自己所需的服务。
3. 注册中心返回服务提供者地址列表给消费者,如果有变更,注册中心将基于长连接推送变更数据给消费者。
4. 服务消费者,从提供者地址列表中,基于软负载均衡算法,选一台提供者进行调用,如果调用失败,再选另一台调用。
5. 服务消费者和提供者,在内存中累计调用次数和调用时间,定时每分钟发送一次统计数据到监控中心。
由于DUBBO在阿里已经被弃,但是当当等地还在用,并且扩展出可DUBBOX,社区还在其基础上不断进行这优化和更新,目前还是很可靠的。
其实这时候原理还是那些原理,但是拼架构拼设计拼理念,都是为了提高性能提高容错率保证一个稳定高效可扩展的系统。















 2363
2363

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









