







子查询本身并不属于一个新的概念,应该说它是将之前的所有查询进行了新的组合,在一个查询之中,包含了其他若干个小的查询,这样的查询就称为子查询,理论上可以在 SQL 语句任意位置上设置子查询,例如:给定的子查询操作语法。
SELECT [DISTINCT] 列 [别名] , 列 [别名] ,... | 统计函数 (
SELECT [DISTINCT] 列 [别名] , 列 [别名] ,... | 统计函数
FROM 表名称 [别名] , 表名称 [别名] , ...
[WHERE 条件(s)]
[GROUP BY 分组字段 , 分组字段 , 分组字段 ,...]
[HAVING 条件(s)]
[ORDER BY 字段 [ASC | DESC] , 字段 [ASC | DESC] ,...])
FROM 表名称 [别名] , 表名称 [别名] , ...(
SELECT [DISTINCT] 列 [别名] , 列 [别名] ,... | 统计函数
FROM 表名称 [别名] , 表名称 [别名] , ...
[WHERE 条件(s)]
[GROUP BY 分组字段 , 分组字段 , 分组字段 ,...]
[HAVING 条件(s)]
[ORDER BY 字段 [ASC | DESC] , 字段 [ASC | DESC] ,...])
[WHERE 条件(s) (
SELECT [DISTINCT] 列 [别名] , 列 [别名] ,... | 统计函数
FROM 表名称 [别名] , 表名称 [别名] , ...
[WHERE 条件(s)]
[GROUP BY 分组字段 , 分组字段 , 分组字段 ,...]
[HAVING 条件(s)]
[ORDER BY 字段 [ASC | DESC] , 字段 [ASC | DESC] ,...])]
[GROUP BY 分组字段 , 分组字段 , 分组字段 ,...]
[HAVING 条件(s) (
SELECT [DISTINCT] 列 [别名] , 列 [别名] ,... | 统计函数
FROM 表名称 [别名] , 表名称 [别名] , ...
[WHERE 条件(s)]
[GROUP BY 分组字段 , 分组字段 , 分组字段 ,...]
[HAVING 条件(s)]
[ORDER BY 字段 [ASC | DESC] , 字段 [ASC | DESC] ,...])]
[ORDER BY 字段 [ASC | DESC] , 字段 [ASC | DESC] ,...] ;
一般而言,子查询经常会在三个地方出现:WHERE 子句、FROM 子句、 FROM 子句,那么刚开始学习的时候,给出以下的一些不成文规定,以确定子查询出现位置:
· WHERE 子句中出现:子查询返回 单行单列、单行多列、多行单列;
· HAVING 子句中出现:子查询返回 单行单列,但同时都是为了使用统计函数;
· FROM 子句中出现:返回多行多列子查询。
1.1、在WHERE 子句之中定义子查询
WHERE 子句针对于所有的数据进行筛选,在之前,可以在 WHERE 子句之中判断某一个单独的数值,或者是判断某一个范围是否满足,实际上这些都可以和子查询进行连接。
1、子查询返回单行单列
范例: 要求查询出公司工资最低的雇员信息
· 首先应该确定出公司的最低工资是多少,可以直接利用 MIN()函数计算
SELECT MIN(sal) FROM emp;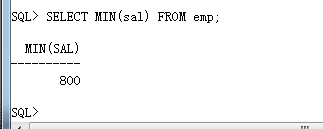
· 以上的查询返回了单行单列,那么可定在 WHERE 子句之中使用,同时还要考虑,肯定有员工的工资为以上查询的结果,可以利用 “=” 判断;
SELECT * FROM emp
WHERE sal=(
SELECT MIN(sal) FROM emp);
范例: 要求查询出低于公司平均工资的全部雇员信息
· 首先应该查询出公司的平均工资,使用 AVG() 函数。
SELECT AVG(sal) FROM emp;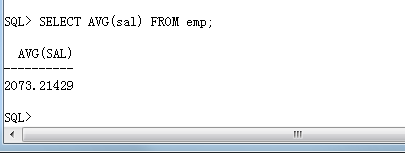
· 比以上查询结果低的工资的雇员信息要进行显示。
SELECT * FROM emp
WHERE sal<(
SELECT AVG(sal) FROM emp);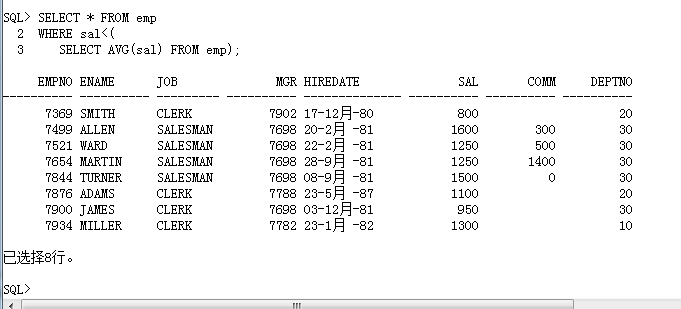
2、子查询返回单行多列(一般少见)
范例: 要求查询出与 SCOTT 从事同一工作,并且工资相同的雇员信息。
· 查询出 SCOTT 工作与工资, 返回单行多列。
SELECT job,sal FROM emp WHERE ename='SCOTT';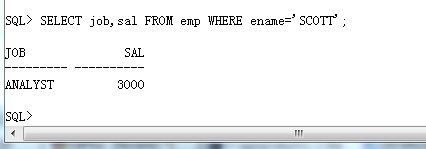
· 两个内容都要相同,直接在 WHERE 子句中进行判断:
SELECT * FROM emp
WHERE (job,sal)=(
SELECT job,sal FROM emp WHERE ename='SCOTT')
AND ename<>'SCOTT';
3、子查询返回多行单列
如果子查询返回的数据是多行多列,那么意味着,返回的是一组范围,那么如果要想进行范围判断,则可以使用三类符号完成:IN、ANY、ALL,下面分别来看:
(1)、IN:满足指定范围
SELECT * FROM emp
WHERE sal IN (SELECT sal FROM emp WHERE job='MANAGER');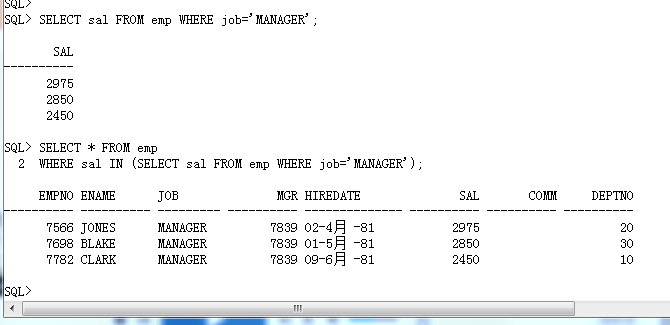
最早使用IN的时候是由用户自己设置的范围,但是现在的范围是通过子查询取得的,同样,如果使用的是 NOT IN 表示不在此范围之中。
SELECT * FROM emp
WHERE sal NOT IN (SELECT sal FROM emp WHERE job='MANAGER');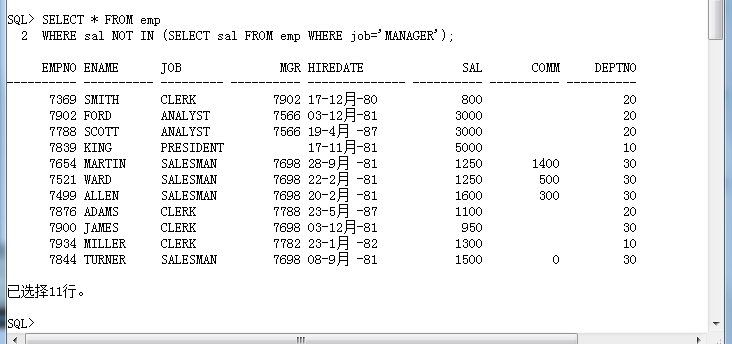
而同时还有一点需要注意的是,在使用 NOT IN 操作的过程中,子查询是不能够存在 NULL。
(2)、ANY:此操作符有三种表现形式:
· =ANY :与 IN 操作符功能一致
SELECT * FROM emp
WHERE sal NOT IN (SELECT sal FROM emp WHERE job='MANAGER');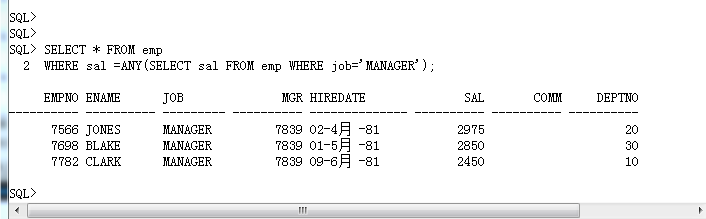
· >ANY :比子查询之中返回的最小的数据要大
SELECT * FROM emp
WHERE sal >ANY(SELECT sal FROM emp WHERE job='MANAGER');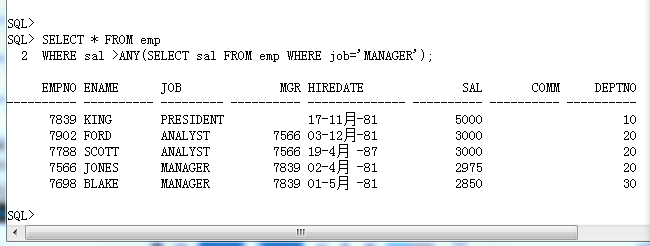
· < ANY :比子查询之中返回的最大的数据要小
SELECT * FROM emp
WHERE sal <ANY(SELECT sal FROM emp WHERE job='MANAGER');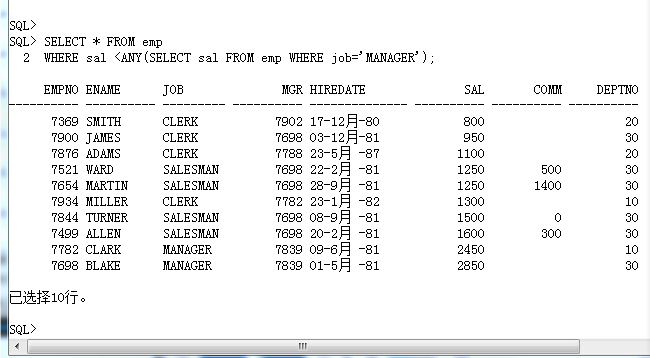
(3)、ALL:此操作符有两种表现形式:
· > ALL :比子查询之中返回的最大的数据要大
SELECT * FROM emp
WHERE sal >ALL(SELECT sal FROM emp WHERE job='MANAGER');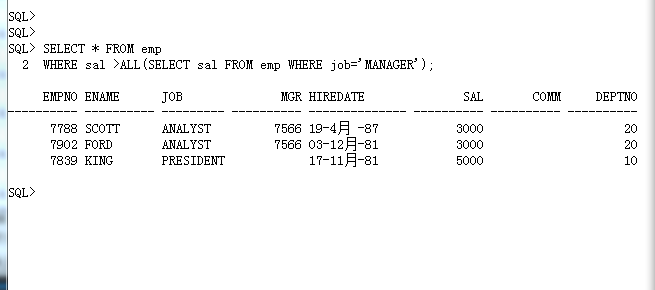
· < ANY :比子查询之中返回的最小的数据要小
SELECT * FROM emp
WHERE sal <ALL(SELECT sal FROM emp WHERE job='MANAGER');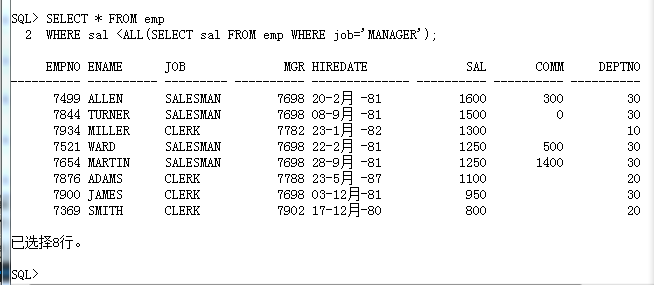
至于以上三个操作符使用哪一种,完全由你的查询需求来决定。
1.2、在HAVING 子句之中定义子查询
在 HAVING 子句之中出现子查询只会返回单行单列,并且会在使用统计函数的情况下出现此类情况。
范例: 要求查询出比公司平均工资还要高的部门编号、部门人数、平均工资。
• 首先应该知道公司的平均工资,返回单行单列。
SELECT AVG(sal) FROM emp;• 下面应该按照部门编号分组,同时设置一个分组后的过滤条件,HAVING子句。
SELECT deptno,COUNT(empno),AVG(sal)
FROM emp
GROUP BY deptno
HAVING AVG(sal)>(
SELECT AVG(sal) FROM emp);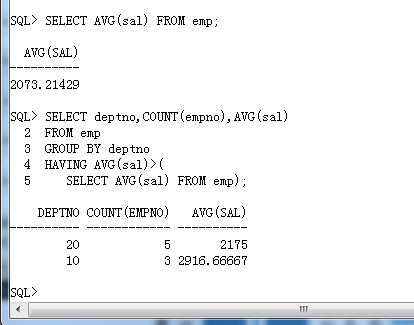
1.3、在FROM 子句之中定义子查询
FROM 子句的主要功能是却定数据的来源,如果说现在在一个子查询返回的数据形式是多行多列,这实际上就是一个标的结构,但是这确实一张临时表,可是 SQL 不管实体表还是临时表,只要是多行多列就会按照表进行读取,所以子查询返回多行多列时,就是一张临时的数据表,必须在 FROM 子句之中出现。
范例: 要求查询出每个部门的编号、名称、位置、部门人数、平均工资
实现方式一: 本题目的要求在之前可以通过多字段分组求出,直接利用 GROUP BY 完成,并且结合多表查询。
SELECT d.deptno,d.dname,d.loc,COUNT(e.empno),AVG(e.sal)
FROM emp e,dept d
WHERE e.deptno(+)=d.deptno
GROUP BY d.deptno,d.dname,d.loc;实现方式二: 利用子查询完成
• 首先现在先查询出部门的完整信息,这个时候只需要依靠dept表即可。
SELECT d.deptno,d.dname,d.loc
FROM dept d;• 之后查询出每个部门编号、部门人数、部门平均工资,只需要emp表即可。
SELECT deptno,COUNT(empno),AVG(sal)
FROM emp
GROUP BY deptno;• 统计查询的结果返回的是多行多列,而且也存在了 deptno 字段的信息,那么能否把前面两个查询变为一个?。
SELECT d.deptno,d.dname,d.loc,temp.count,temp.avg
FROM dept d, (
SELECT deptno,COUNT(empno) count,AVG(sal) avg
FROM emp
GROUP BY deptno) temp
WHERE d.deptno=temp.deptno(+);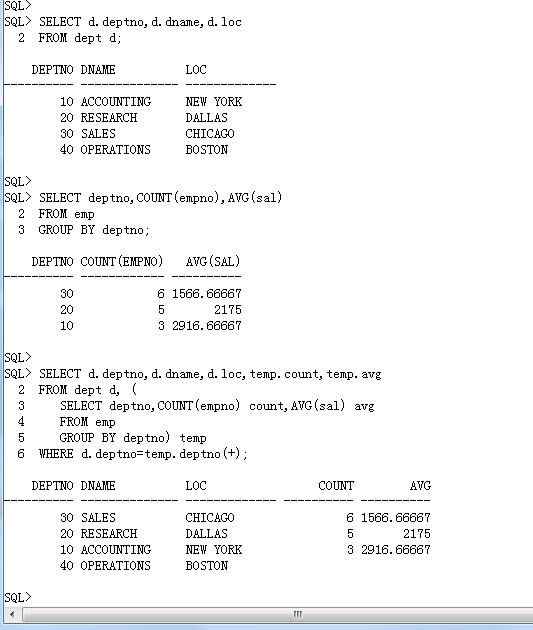
1.4、性能分析
那么现在就会出现一个问题了,两种实现方案都可以实现同样的功能,使用那种更好呢?为了分析这两类的操作,现在可以将emp或dept表的数据量假设扩大100倍,即:emp表的数据量是1400条,dept表的数据量是400条。
• 方式一的数据量:采用的是多表查询,而后进行多字段的分组方式,如果要使用多表查询,那么就一定会出现笛卡尔积,那么此时的操作的数据量是:emp表的1400条 * dept表的400条 = 560000 条
• 方式二的数据量:采用子查询,所以数据量要分开统计:
|- 子查询的数据量:emp表的1400条数据,子查询最多返回400行记录;
|- 将dept表与子查询进行多表连接:dept表的400条 * 子查询最多的400条 = 160000条;
|- 最终的总量:子查询的1400条 + 外部查询的160000条记录 = 161400条记录。
很明显,子查询的性能绝对要高于多表查询的性能,即:在任何的实际开发之中,子查询是解决多表查询中出现性能问题的唯一方式。(或者设置冗余字段)
在FROM子句之中出现子查询还有一个原因:外部查询需要使用统计函数操作,但是整体查询又无法实现分组统计操作的情况下使用。















 494
494

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









