







1、列出薪金高于在部门30工作的所有员工的姓名和薪金、部门名称。
• 确定所需要的数据表:
|- emp表:员工姓名和薪金;
|- dept表:部门名称;
• 确定已知的关联字段:
|- 雇员和部门关联:emp.deptno=dept.deptno
第一步: 找出30工作的所有员工工资
SELECT sal FROM emp WHERE deptno=30;第二步: 以上的查询肯定作为过滤条件出现,那么既然返回的是多行单列数据,那么肯定在 WHERE 中使用,并且可以使用 IN、ANY、ALL 三个操作符,根据题目要求应该使用 > ALL, 找出
所有满足条件的雇员信息
SELECT e.ename,e.sal
FROM emp e
WHERE e.sal>ALL(
SELECT sal FROM emp WHERE deptno=30);第三步: 增加部门名称
SELECT e.ename,e.sal,d.dname
FROM emp e,dept d
WHERE e.sal>ALL(
SELECT sal FROM emp WHERE deptno=30)
AND e.deptno=d.deptno;
2、列出与 “SCOTT” 从事相同工作的所有员工及部门名称,部门人数。
• 确定所需要的数据表:
|- emp表:员工信息;
|- dept表:部门名称;
|- dept表:统计部门人数;
• 确定已知的关联字段:
|- 雇员和部门关联:emp.deptno=dept.deptno
第一步: 找出 SCOTT 的工作,这个结果返回单行单列
SELECT job FROM emp WHERE ename='SCOTT';第二步: 既然查询返回的是单行单列,那么可以在两个地方使用此子查询:WHERE、HAVING,而根据现在的要求明显应该是在WHERE之中使用,下面以上面的结果为参考找到员工的信息
SELECT e.empno,e.ename,e.sal
FROM emp e
WHERE e.job=(
SELECT job FROM emp WHERE ename='SCOTT')
AND ename<>'SCOTT';第三步: 应该继续查询出部门信息,增加dept表
SELECT e.empno,e.ename,e.sal,d.dname
FROM emp e,dept d
WHERE e.job=(
SELECT job FROM emp WHERE ename='SCOTT')
AND ename<>'SCOTT'
AND e.deptno=d.deptno;第四步: 本操作需要找到指定的部门人数,但是在以上的查询之中,明显不可能直接在 SELECT 子句之中使用统计函数了(第一点没有 GROUP BY,第二点统计函数要么单独使用,要么结合 GROUP BY 使用,不能有其他字段),于是下面先单独做一个操作:统计出各个部门的人数
SELECT deptno dno,COUNT(empno) count FROM emp GROUP BY deptno;第五步: 以上查询返回多行多列,而且发现存在有部门编号,可以和第三步的查询进行连接,以消除笛卡尔积。
SELECT e.empno,e.ename,e.sal,d.dname,temp.count
FROM emp e,dept d, (
SELECT deptno dno,COUNT(empno) count
FROM emp
GROUP BY deptno) temp
WHERE e.job=(
SELECT job FROM emp WHERE ename='SCOTT')
AND ename<>'SCOTT'
AND e.deptno=d.deptno
AND d.deptno=temp.dno;
3、列出薪金比 “SMITH” 或 “ALLEN” 多的所有员工的编号,姓名,部门名称,其领导姓名,部门人数。
• 确定所需要的数据表:
|- emp表:员工信息;
|- dept表:部门名称;
|- emp表:领导姓名;
|- emp表:统计信息;
• 确定已知的关联字段:
|- 雇员和部门关联:emp.deptno=dept.deptno
|- 雇员和领导:emp.mgr=memp.empno;
第一步: 列出 “SMITH” 和 “ALLEN” 的薪金, 返回多行单列
SELECT sal FROM emp WHERE ename IN('SMITH','ALLEN');第二步: 子查询的信息只有 WHERE 可以处理,查询出雇员的编号和姓名
SELECT e.empno,e.ename,e.job,e.sal
FROM emp e
WHERE e.sal>ANY(
SELECT sal
FROM emp
WHERE ename IN('SMITH','ALLEN'))
AND e.ename NOT IN ('SMITH','ALLEN');第三步: 加入部门名称
SELECT e.empno,e.ename,e.job,e.sal,d.dname
FROM emp e,dept d
WHERE e.sal>ANY(
SELECT sal
FROM emp
WHERE ename IN('SMITH','ALLEN'))
AND e.ename NOT IN ('SMITH','ALLEN')
AND e.deptno=d.deptno;第四步: 找到领导人姓名,加入emp表关联
SELECT e.empno,e.ename,e.job,e.sal,d.dname,m.ename
FROM emp e,dept d,emp m
WHERE e.sal>ANY(
SELECT sal
FROM emp
WHERE ename IN('SMITH','ALLEN'))
AND e.ename NOT IN ('SMITH','ALLEN')
AND e.deptno=d.deptno
AND e.mgr=m.empno(+);第五步: 部门人数一定非需要使用统计函数完成,本程序已经无法使用统计函数,所以在 FROM 子句之中编写子查询
SELECT e.empno,e.ename,e.job,e.sal,d.dname,m.ename,temp.count
FROM emp e,dept d,emp m,(
SELECT deptno dno,COUNT(empno) count
FROM emp
GROUP BY deptno) temp
WHERE e.sal>ANY(
SELECT sal
FROM emp
WHERE ename IN('SMITH','ALLEN'))
AND e.ename NOT IN ('SMITH','ALLEN')
AND e.deptno=d.deptno
AND e.mgr=m.empno(+)
AND e.deptno=temp.dno;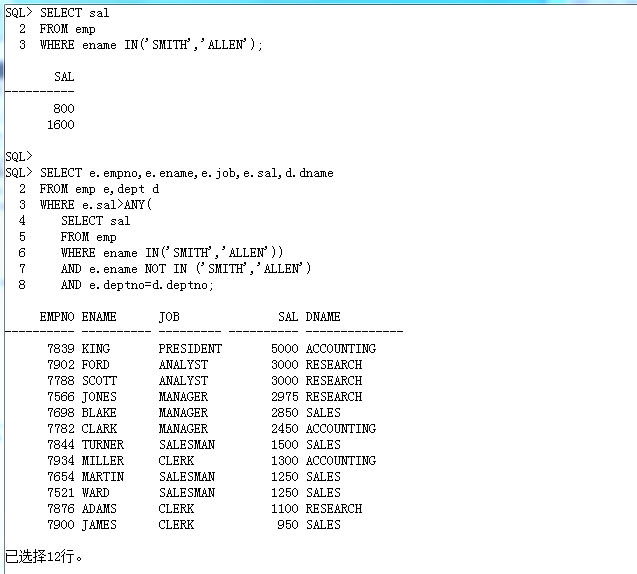
4、列出受雇日期早于其直接上级的所有员工的编号,姓名,部门名称,部门位置,部门人数。
• 确定所需要的数据表:
|- emp表:员工编号和姓名;
|- emp表:确定上级;
|- dept表:部门名称,部门位置;
|- emp表:部门人数;
• 确定已知的关联字段:
|- 雇员和部门关联:emp.deptno=dept.deptno
第一步: 直接使用自身关联,列出受雇佣日期早于其直接上级的所有员工的编号、姓名
SELECT e.empno,e.ename,e.hiredate
FROM emp e,emp m
WHERE e.mgr=m.empno(+) AND e.hiredate<m.hiredate;第二步: 找到部门名称、部门位置
SELECT e.empno,e.ename,e.hiredate,d.dname,d.loc
FROM emp e,emp m,dept d
WHERE e.mgr=m.empno(+)
AND e.hiredate<m.hiredate
AND e.deptno=d.deptno;第三步: 找到部门人数,在 FROM 子句之中完成。
SELECT e.empno,e.ename,e.hiredate,d.dname,d.loc,temp.count
FROM emp e,emp m,dept d,(
SELECT deptno dno,COUNT(deptno) count
FROM emp
GROUP BY deptno) temp
WHERE e.mgr=m.empno(+)
AND e.hiredate<m.hiredate
AND e.deptno=d.deptno
AND e.deptno=temp.dno;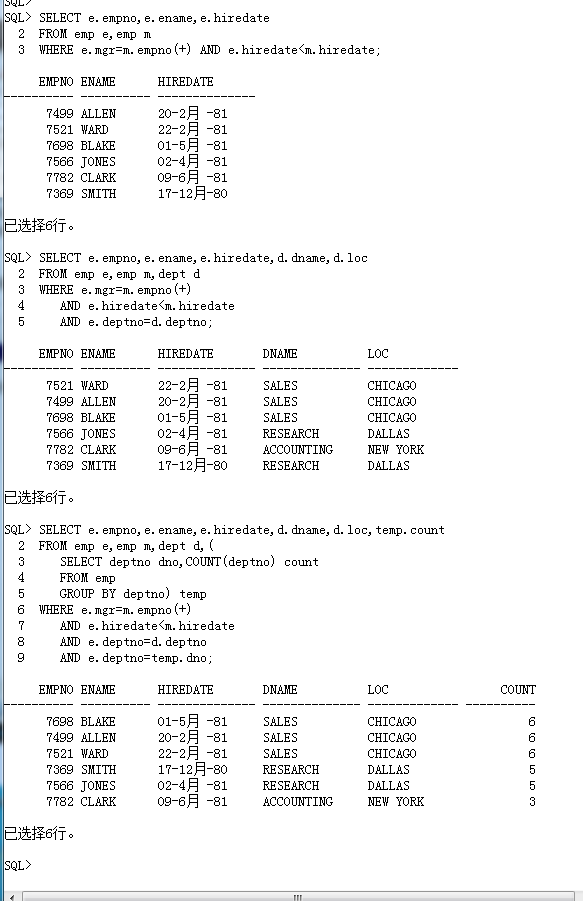
5、列出所有 “CLERK” (办事员)的姓名及其部门名称,部门人数,工资等级。
• 确定所需要的数据表:
|- emp表:员工姓名;
|- dept表:部门名称;
|- emp表:部门人数;
|- salgrade表:工资等级;
• 确定已知的关联字段:
|- 雇员和部门关联:emp.deptno=dept.deptno
|- 雇员和工资等级关联:emp.sal BETWEEN salgrade.losal AND salgrade.hisal;
第一步: 列出所有的”CLERK” 的姓名和部门名称
SELECT e.ename,d.dname
FROM emp e,dept d
WHERE e.deptno=d.deptno
AND e.job='CLERK';第二步: 找出工资等级
SELECT e.ename,d.dname,s.grade
FROM emp e,dept d,salgrade s
WHERE e.deptno=d.deptno
AND e.job='CLERK'
AND e.sal BETWEEN s.losal AND s.hisal;第三步: 找到部门人数,直接子查询
SELECT e.ename,d.dname,s.grade,temp.count
FROM emp e,dept d,salgrade s,(
SELECT deptno dno,COUNT(deptno) count
FROM emp
GROUP BY deptno) temp
WHERE e.deptno=d.deptno
AND e.job='CLERK'
AND e.sal BETWEEN s.losal AND s.hisal
AND e.deptno=temp.dno;
总结
1、 分组查询
• 统计函数:COUNT()、SUM()、AVG()、MAX()、MIN();
• 分组:当一个列上存在重复数据的时候才会考虑到分组,分组使用GROUP BY子句完成,分组的同时必须使用统计函数进行数据的统计;
• 统计函数的使用要求:
|- 统计函数要么单独使用,要么结合GROUP BY一起使用,同时在SELECT子句之中只能出现统计函数和分组字段,其他的任何字段都不允许出现;
|- 统计函数可以嵌套使用,但是嵌套之后的查询之中,不能再出现任何的字段,包括分组字段;
• 在进行分组统计的时候除了针对于实体表分组之外,也可以针对于临时表(查询结果)进行分组,而且允许多字段分组,但是这多个字段的内容必须同时重复;
• 如果要对分组后的数据执行再次的过滤,使用HAVING子句,在分组前的过滤使用WHERE;
2、 子查询:它不是一个新的语法,只是将若干个查询集合在一起形成的复杂查询,子查询的主要目的是:解决多表查询的性能问题,一般在三个地方出现子查询的情况会比较多:
• WHERE子句:子查询返回单行单列(数值)、多行单列(范围,IN、ANY、ALL)、单行多列;
• HAVING子句:子查询返回单行单列(数值),需要对分组后过滤(使用统计函数);
• FROM子句:子查询返回多行多列,当作一张临时表出现。
以上的操作只是完成了DML(数据操作语言)中的一小部分操作。















 2710
2710

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









