







序言
在查找的数据结构中,常见的平衡搜索树的结构,比如AVL树,红黑树,虽然可以完成 O ( l o g N ) O(logN) O(logN)的查找,但是其删除都很麻烦,而且细节还贼多,需要搞好大一会儿才能将原理理解,然后还要花亿小会儿将代码实现,那有没有什么数据结构,删除比较简单且能完成与上述数据结构等效的查找呢?hhh,明知故问,就是本篇要讲的跳表,简单来说其原理跟平衡树一样还是二分的思想,不过采用链表的形式,而不是树的形式,但是在实现方面就简单了很多,下面博主就来展开讲讲。
说明:文章有部分图解采自于论文《 S k i p L i s t s : A P r o b a b i l i s t i c A l t e r n a t i v e t o B a l a n c e d T r e e s Skip Lists: A Probabilistic Alternative to Balanced Trees SkipLists:AProbabilisticAlternativetoBalancedTrees》是 W i l l i a m William William P u g h Pugh Pugh ,也就是跳表的发明者编写发布的,感兴趣的读者可进行阅读拓展,不过是全英的,推荐借助浏览器插件辅助阅读,还可能需要一点点科技。
一、概要
跳表,简单来讲,就是一种有序链表,而纯纯的链表这个东西,查找指定结点的时间复杂度是 O ( N ) O(N) O(N),那大佬是如何实现的呢?其实就是增加一个结点中指向的下一个结点的指针数,结点的结构简单来看就长下图这样:
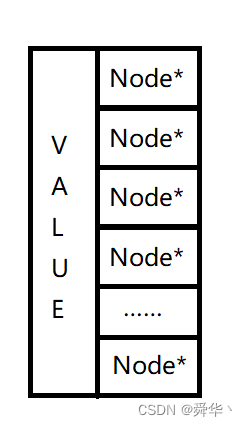
而且每个结点中的指针数还可能各不相同,那么就像这样:

具体是如何搜索的呢?那么再对上述图中填入一些数据,然后分析过程:

-
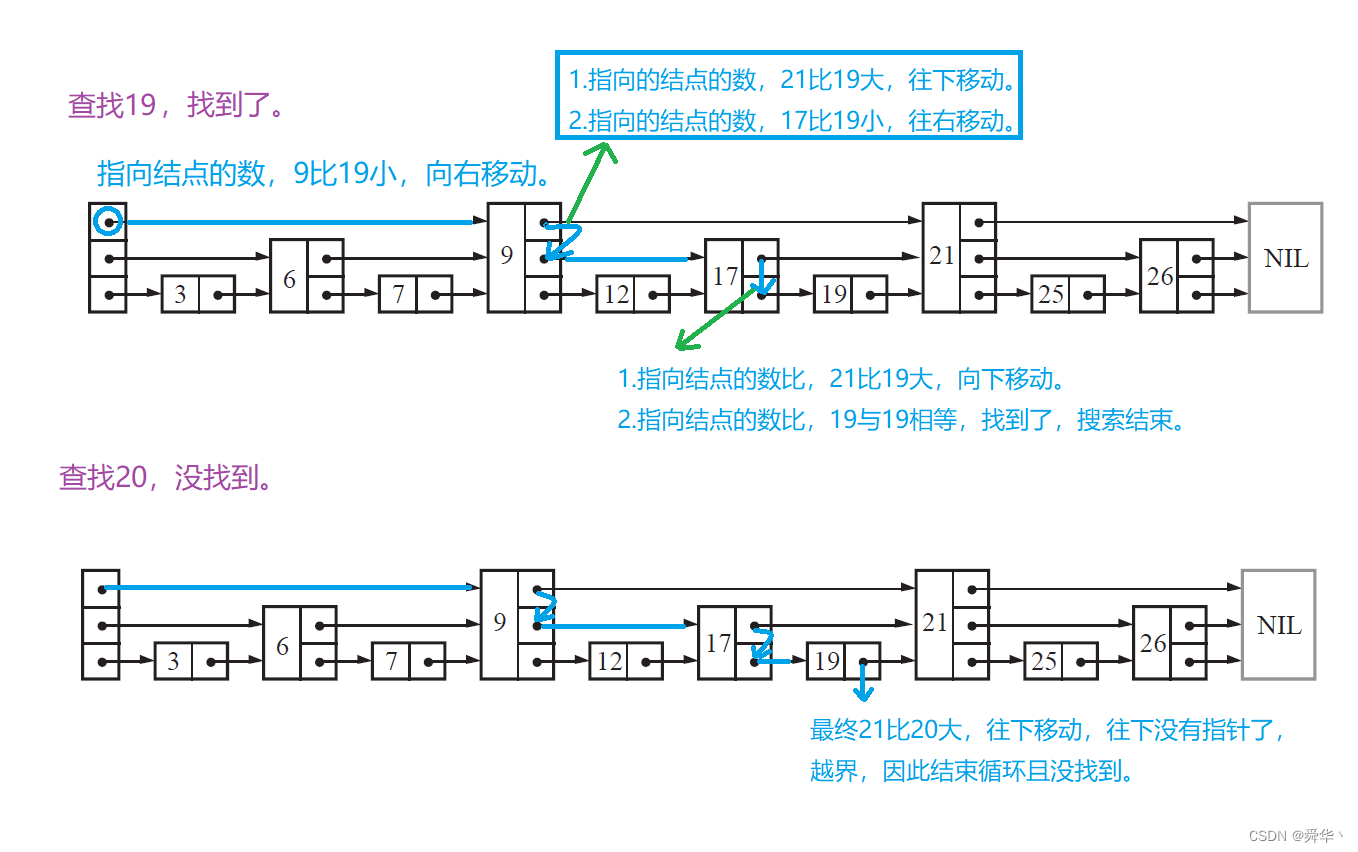
假设要查找的数是17,那么从头开始查找,头存放的指针指向的是值为6的结点,比17小走到6这个结点,看其存放的指针,从上往下第一个指针为空,那就往下查找,第二个指针指向的结点值为25,大于17继续往下查找,第三个指针指向的结点的值为9,小于17就往右查找,继续查找其存放的指针,第一个指针指向结点的值为17,找到了目标值的结点,搜索结束。
-
特殊的情况,即结点存放的指针,从上往下进行遍历,遍历完了,即不能继续往下查找否则就越界了,说明「要查找的值不存在」。
- 说明: 看完这个过程,想必对查找的过程有了一定的了解,但是仅仅凭这一个简单样例,从直观上是不能体会到跳表查找的速度在 O ( l o g N ) O(log N) O(logN)这个级别的,顶多感觉只是提升了常数倍,那么这里给出两个例子,方便读者以具体的例子代入理解。
例一:
- 小明要从地点A 「快速」到达地点B,即赶路,假设地点A到地点B的路程是一条直线。
- 小明会先乘坐「最快的交通工具——飞机」,中间可能会换乘飞机,最终到达地点B所在的省份的机场,然后再乘坐「省份内最快的交通工具——高铁」,到达地点B所在的市区,最终坐「市区最快的交通工具——出租车」,最终到达地点B。
- 回过头再来看跳表中,高度越高的结点,就相当于越快的交通工具,能更快地到达目的地附近,不断往下移动就代表越来越接近目的地了,最终可能会到达目的地,也可能目的地不存在。那么时间复杂度提升的关键就是交通工具是存在「量级」的差别的,从汽车到高铁到飞机,即从低位置到高位置的结点指针,移动速度会以指数级别进行提升。
例二:
- 在修仙世界里面,有一门传说级别的大神通——缩地成寸,但是这门功法很难,分为入门,熟练,精通,大成,凝神,化神,六大境界。
- 为更加形象,这里用数据将这些境界具象化,即相邻两个境界移动的「最大」移动的距离相差64倍,那么化神与入门之间移动的最大距离就差别230次方,这可是指数级别的差异,下面使用「指定境界的名称代指此境界所能达到的最大速度」。
- 那么一位修仙界的巨佬——石昊,把这门功法修炼到了极致——化神!那么石昊要去桃花岛办点事,但是中间过程被几位同境界的巨佬看不惯,联合围攻了,但石昊可是修有秘法的,赶紧用速度为「化神期」逃命,甩开之后,就想着既然到桃花岛还早,那就陪这几个巨佬玩玩,于是就放慢到了速度为「凝神期」,等到他们追上之后,陪他们过了几招,但是不小心被打伤了,放了个大招之后,躲到一个地方偷偷赶路了,速度降为「大成」,后来差点又被发现,速度接着降为「精通」小心翼翼的行动,快到桃花岛时,那地方有石昊的师父,柳神,那几个老家伙不敢轻举妄动,因此都走了,此时石昊把速度降为「熟练期」悠闲的奔向桃花岛,并回过头向那几个巨佬进行了嘲讽。
- 回过头来看,不同境界的速度的差异是巨大的,尤其是最高境界和最低境界,那么从高到低的境界的速度的差别就相当于跳表结点中从高位置的指针到低位置的指针的差别。
希望读者看完这两个例子之后,能够进一步理解跳表的思想,那么就不用从数学的角度进行硬性理解,不用再看时间复杂度证明了,嘿嘿,当然这里也不会提供复杂的证明,如有兴趣可看开头论文。
二、实现
1.推论
如何进行实现,首先一大难点就在于保证高度越高的结点向右移动的速度越快,且能够与高度低的结点拉开指数级别的差距呢?此处大佬就提供了一种大胆的思想,即引入概率进行生成随机高度的结点。具体过程且听下文作者娓娓道来。
大佬在最开始设计时,跳表要一次跳越多个结点才能保证效率,因此要控制「不同高度的结点向右跳过的结点的个数」,但是考虑到严格按照比例来放置指定高度的结点会让删除,插入时的时间复杂度退化为O(N),而且代码的实现还及其的复杂,比如说下面的这张图中,每隔1个高度为1的结点就是一个高度为2的结点。

那么假设当删除6的时候,还要调整对应的关系,即每隔一个结点就要有一个高度为2的结点,那么后面所有结点的高度就要进行调整,这样时间复杂度就退化为了O(N),对插入同样如此。
对此,大佬,不再要求每个结点一次向右跳越的结点数,而是采用概率生成随机高度的结点,这样既保证了插入时不用再调整结点与结点之间的关系,只管插即可,又在一定程度上保证了跳表的效率。比如向下图中中的跳表中插入17。
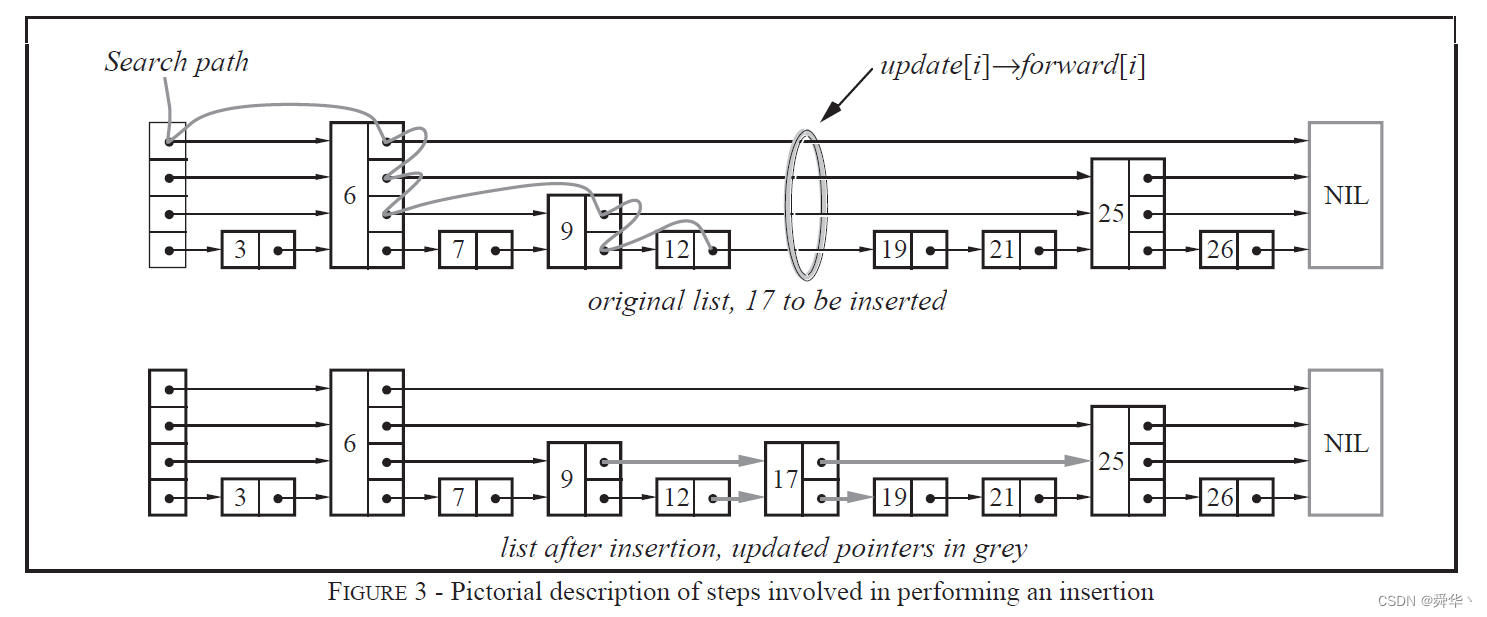
说明:此处向指定位置插入17结点,这个结点的高度是随机生成的。
话说到这里了,随机生成和概率,这俩听起来很玄乎的东西是如何保证效率的呢,该如何理解呢?下面给出核心的随机生成的概率和随机函数:
double p = 0.5;//概率,Redis,一款缓存工具中设置为0.25,都可以,详见论文中的数据表。
int max_value = 32;//结点高度的最大值。
int random()
{
int height = 1; //随机生成结点的高度。
//[0,RNAD_MAX] 当 满足[0,RAND_MAX / 2]时,并且在最大高度范围内时进入循环。
//随机生成的数满足上述区间的概率为1/2,即每次只有0.5的概率进入循环。
while(rand() < p * RAND_MAX && height < max_values)
{
height += 1;
}
return height;
}
据此可推出生成高度从低到高结点的概率,下表中 p p p表示生成的随机数满足范围,高度加一,继续循环; 1 − p 1 - p 1−p表示生成的随机数数不满足范围,终止循环。
| 层数 | 概率公式 | p = 1 2 p = \frac {1 }{ 2} p=21 |
|---|---|---|
| 1 1 1 | 1 − p 1 - p 1−p | 1 2 \frac{1} {2} 21 |
| 2 2 2 | p ∗ ( 1 − p ) p * (1 - p) p∗(1−p) | 1 2 2 \frac{1} {2^2} 221 |
| 3 3 3 | p 2 ∗ ( 1 − p ) p ^2 * (1 - p) p2∗(1−p) | 1 2 3 \frac{1} {2^3} 231 |
| 4 4 4 | p 3 ∗ ( 1 − p ) p ^3 * (1 - p) p3∗(1−p) | 1 2 4 \frac{1} {2^4} 241 |
| 5 5 5 | p 4 ∗ ( 1 − p ) p ^4 * (1 - p) p4∗(1−p) | 1 2 5 \frac{1} {2^5} 251 |
| … | … | … |
| 32 32 32 | p 31 ∗ ( 1 − p ) p ^{31} * (1 - p) p31∗(1−p) | 1 2 32 \frac{1} {2^{32}} 2321 |
这一堆冰冷的数字有什么含义呢?来一块分析一下,假设有
2
34
2^{34}
234 个数据,那么高度为
32
32
32的结点平均只有
4
4
4个,高度为
31
31
31的结点平均有
8
8
8个……此处不再进行一 一列举了,那这有什么含义呢?从结点的结构再来分析一下。
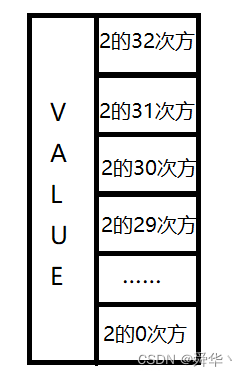
那么对于高度最高的结点,向右移动一次即平均能跳跃
2
32
2^{32}
232 次个结点,而对于高度最低的结点来说,向右移动一次只能跳跃1个结点,这不就是刚才所讲的"缩地成寸"的例子么?不同高度的结点一次向右跳跃的结点数是呈现指数级变化的,且向下移动时就说明到数据附近了,那么这不就是"小明赶路"的例子,此时换乘交通工具,继续向目的地接近不就行了,一直跳到目的地为止,当然也有可能目的地不存在。
- 最后再概括一下,随机 + 概率 == 平均,而平均从数学的程度上就保证了跳表的搜索效率,即时间复杂度平均下来为O(logN),而且平均也保证了插入结点的独立性,不会对整个跳表的搜索效率产生影响。
除此之外,对于空间上的效率,也可以从数学的角度进行推理和证明,下面进行详细的数学公式的计算:
首先,结点的构成有两部分,分别为「数据」 和 「指针数」,对于规模为N的数据,空间复杂度为O(N),那么对于指针数,就要进行对应的数学计算,采用的公式为:生成对应高度结点的概率 * 高度,即使用上文的表格。
设每个结点的平均高度为S,可列出公式 S = 1 ∗ ( 1 − p ) + 2 ∗ p ∗ ( 1 − p ) + … … + k ∗ p k − 1 ∗ ( 1 − p ) = ( 1 − p ) ∑ k ∞ S = 1 * (1 - p) + 2 * p * (1 - p) + …… + k * p^{k-1}* (1 - p) = (1 - p) \sum_k^\infty S=1∗(1−p)+2∗p∗(1−p)+……+k∗pk−1∗(1−p)=(1−p)∑k∞k * pk-1
设 ∑ k ∞ \sum_k^\infty ∑k∞k * pk-1 为 M M M 对其进行错位相减进行化简:
1
+
2
∗
p
+
3
∗
p
2
+
4
∗
p
3
+
…
…
+
k
∗
p
k
−
1
=
M
1 + 2 * p + 3 * p^2 + 4 * p^3 + …… + k * p^{k-1} = M
1+2∗p+3∗p2+4∗p3+……+k∗pk−1=M
①
①
①
1
∗
p
+
2
∗
p
2
+
3
∗
p
3
+
…
…
+
(
k
−
1
)
∗
p
k
−
1
+
k
∗
p
k
=
p
∗
M
1* p + 2 * p^2 + 3 * p^3 + …… + (k - 1) * p^{k-1} + k * p^k = p * M
1∗p+2∗p2+3∗p3+……+(k−1)∗pk−1+k∗pk=p∗M
②
②
②
① − ② ① - ② ①−② 得, 1 + p + p 2 + … … p k − 1 + k ∗ p k = ( 1 − p ) ∗ M 1 + p + p^2 + …… p^{k-1} + k * p ^{k} = (1 - p) * M 1+p+p2+……pk−1+k∗pk=(1−p)∗M;
根据等比公式的前n项和 a n = a 1 ∗ ( 1 − p n ) ( 1 − p ) a_n =\frac {a_1 * (1 - p^n) }{ (1 - p)} an=(1−p)a1∗(1−pn),化简得 M M M = 1 − p k ( 1 − p ) 2 \frac {1 - p^k }{ (1 - p)^2} (1−p)21−pk + k ∗ p k 1 − p \frac {k * p ^k }{1 - p} 1−pk∗pk ,k趋近于无穷大时,又因为p的取值范围在(0,1),因此pk 趋近于0,因此最终化简为, M M M = 1 ( 1 − p ) 2 \frac {1}{ (1 - p)^2} (1−p)21
进一步可得 S = ( 1 − p ) ∗ 1 ( 1 − p ) 2 S = (1 - p) * \frac {1}{ (1 - p)^2} S=(1−p)∗(1−p)21,即 S = 1 1 − p S= \frac {1 }{1 - p} S=1−p1。
根据此公式,当 p p p等于 1 2 \frac {1}{2} 21时,平均下来每个结点的高度为2,也就是说对于N规模的数据,要用 2 ∗ N 2*N 2∗N个指针,因此的总数的规模大概就在 3 ∗ N 3 * N 3∗N左右,即空间复杂度为 O ( N ) O(N) O(N)。
这些讲清楚了,下面的实现只需要看图分析,理清流程,代码实现是很简单的,当然下面还是会举例详细地分析和实现,最后,力扣有一道跳表的题,可以将代码复制到力扣上跑一跑验证一下。
力扣题目链接:1206. 设计跳表,点击蓝色链接即可进入。
首先,先给出基础的框架,下面实现对应功能中就只给出相关的接口,防止代码冗余。
- 结点结构:
struct SkipNode
{
SkipNode(int val,int level)
:_val(val),_pnodes(level,nullptr)
{}
int _val;//值
vector<SkipNode*> _pnodes;//结点指针。
};
-
图解:

-
跳表结构:
class Skiplist
{
typedef SkipNode Node;
Node* _head;//头指针
double p = 0.5;//0.5和0.25都行。
int max_value = 32;//足以应付几十亿的数据了。
public:
Skiplist()
{
//默认给头结点的值为-1,默认设置高度为1
_head = new Node(-1,1);
//种一颗随机数种子
srand(time(nullptr));
}
//查找
bool search(int target);
//插入
void add(int num);
//删除
bool erase(int num);
//生成结点的高度,上文中详细提及过,此处不再赘述。
int random()
{
int height = 1;
while(rand() < p * RAND_MAX && height < max_value)
{
height += 1;
}
return height;
}
};
2.查找
-
图解:
-
实现:
bool search(int target)
{
Node* cur = _head;
//height_index
int hgt_idx = cur->_pnodes.size() - 1; //所在高度的下标
while(hgt_idx >= 0)
{
Node* nxt = cur->_pnodes[hgt_idx];
//如果执行的结点为空,说明到边界了,得往下移动继续查找。
if(nxt == nullptr)
{
hgt_idx--;
continue;
}
int val = nxt->_val;
if(val < target)
{
//小于target,往右移动。
cur = nxt;
}
else if(val > target)
{
//大于target,向下移动。
hgt_idx--;
}
else
{
//找到了。
return true;
}
}
return false;
}
- 总的来说,跟二分查找的思路类似,只是写法不同,感觉不同而已。
3.插入
-
强调:这里实现的是可以插入重复值的跳表,原因在于此实现对标力扣的对应题目,方便借助力扣平台进行测试。
-
图解:
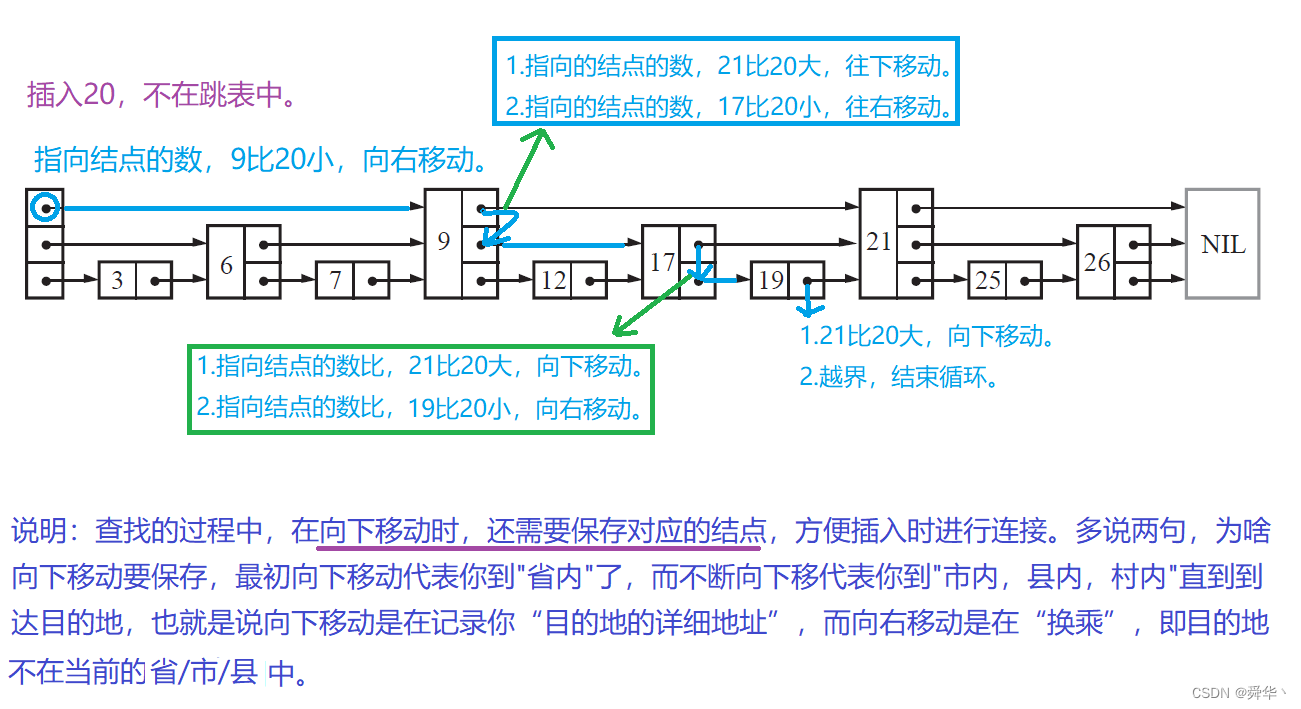
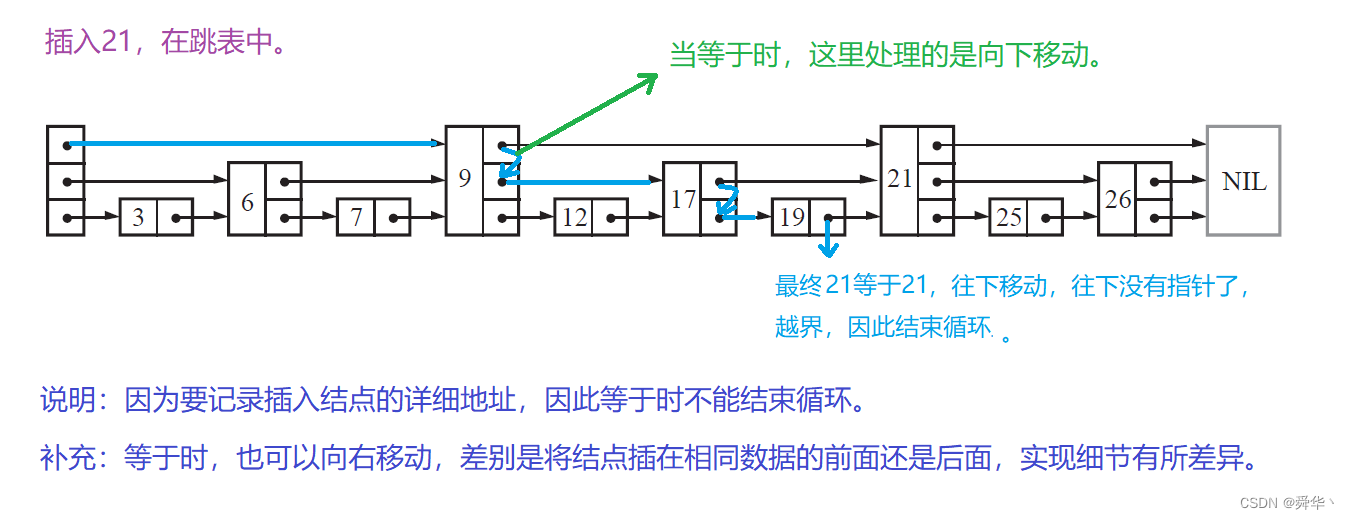
-
说明:由于插入和删除都需要保存链接结点,此处将保存的要链接结点的逻辑封装成了函数,进行呈现。
vector<Node*> SavePrev(int num)
{
Node* cur = _head;
int hgt_idx = cur->_pnodes.size() - 1;
vector<Node*> pre(hgt_idx + 1);
while(hgt_idx >= 0)
{
Node* nxt = cur->_pnodes[hgt_idx];
if(nxt == nullptr)
{
//向下移动
pre[hgt_idx] = cur;
hgt_idx--;
continue;
}
int val = nxt->_val;
if(num <= val)
{
//保存当前结点,向下移动.
pre[hgt_idx] = cur;
hgt_idx--;
}
else
{
//向右移动。
cur = nxt;
}
}
return pre;
}
- 插入实现:
void add(int num)
{
//1.找到对应的结点的前后指针。
auto nodes = SavePrev(num);
//2.开辟对应的结点。
int heg = random();
Node* newnode = new Node(num,heg);
//3.更新头节点和对应的nodes
int hsz = _head->_pnodes.size();
if(heg > hsz)
{
_head->_pnodes.resize(heg,nullptr);
nodes.resize(heg,_head);
}
//4.连接对应的结点
for(int i = 0; i < heg; i++)
{
newnode->_pnodes[i] = nodes[i]->_pnodes[i];
nodes[i]->_pnodes[i] = newnode;
}
}
- 说明:由于结点的高度是随机生成的,可能会高于原先跳表中的最高结点,因此需要让头结点与链接的结点保持同步,即更新头结点中的指针个数,同时nodes中也要进行对齐,更新为头结点指针,方便与新生成的结点进行链接。
4.删除
- 图解:
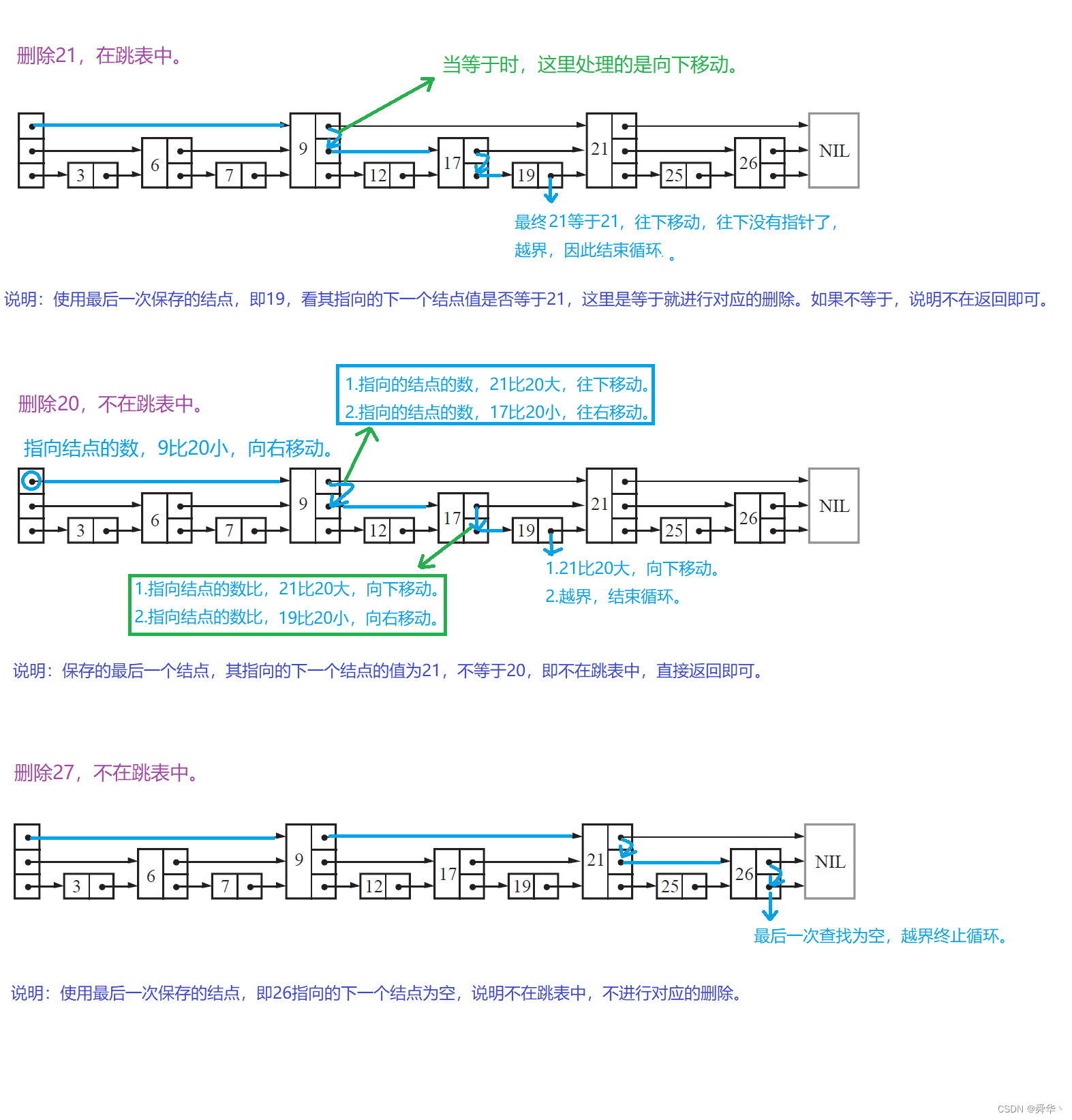
- 实现:
bool erase(int num)
{
auto nodes = SavePrev(num);
Node* end_node = nodes[0];
Node* nxt = end_node->_pnodes[0];
if(nxt == nullptr || nxt->_val != num) return false;
int sz = nxt->_pnodes.size();
for(int i = 0; i < sz; i++)
{
nodes[i]->_pnodes[i] = nxt->_pnodes[i];
}
return true;
}
- 说明:思路与插入类似,除此之外也可以直接用上述的 s e a r c h search search函数判断 n u m num num在不在,区别是多查找一次。
5.打印
- 打印很简单,直接从最低层的结点向后遍历即可,这里给出的原因是出bug了,方便进行测试。
void print()
{
Node *cur = _head;
while(cur)
{
Node* nxt = cur->_pnodes[0];
if(nxt == nullptr) break;
cout << nxt->_val << " ";
cur = nxt;
}
cout << endl;
}
尾序
今天的分享到这里就结束了,希望读者能够对跳表能够有更加深刻的理解,我是舜华,期待与你的下一次相遇!















 2419
2419











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









