







1.利用map()函数,把用户输入的不规范的英文名字,变为首字母大写,其他小写的规范名字。输入:['adam', 'LISA', 'barT'],输出:['Adam', 'Lisa', 'Bart']:

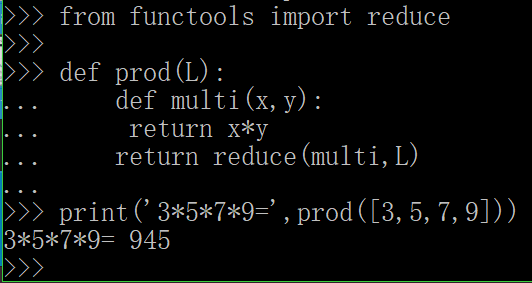
2.Python提供的sum()函数可以接受一个list并求和,请编写一个prod()函数,可以接受一个list并利用reduce()求积:
3.利用map和reduce编写一个str2float函数,把字符串'123.456'转换成浮点数123.456:















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









