







Spark运行wordcount
一、 启动HDFS和Spark

二、 启动Spark-shell连接集群
./spark-shell--master spark://master:7077 --executor-memory 512m --driver-memory 500m

三、 用Scala脚本运行wordcount
代码:
sc.textFile("hdfs://master:9000/hadooptest/wordcount/input/words.txt").flatMap(_.split("")).map(x=>(x,1)).reduceByKey(_+_).map(x=>(x._2,x._1)).sortByKey(false).map(x=>(x._2,x._1)).take(10)
运行结果:

四、 逐行进行Scala脚本运行
1. val rdd=sc.textFile("hdfs://master:9000/hadooptest/wordcount/input/words.txt")
2. rdd.cache()
3. var wordcount = rdd.flatMap(_.split("")).map(x=>(x,1)).reduceByKey(_+_)
4. wordcount.take(10)
5. val wordsort = wordcount.map(x=>(x._2,x._1)).sortByKey(false).map(x=>(x._2,x._1))
6. wordsort.take(10)
五、 观察运行情况


点击:Application ID

六、 使用Spark-submit测试
从Spark1.0.0开始,Spark提供了一个易用的应用程序部署工具bin/spark-submit,可以完成Spark应用程序在local、Standalone、YARN、Mesos上的快捷部署。

七、 用spark-submit运行自带例子,计算圆周率π的值
命令:
./spark-submit --master spark://master:7077 --classorg.apache.spark.examples.SparkPi --executor-memory 512m/usr/spark/spark-2.1.1-bin-hadoop2.6/examples/jars/spark-examples_2.11-2.1.1.jar200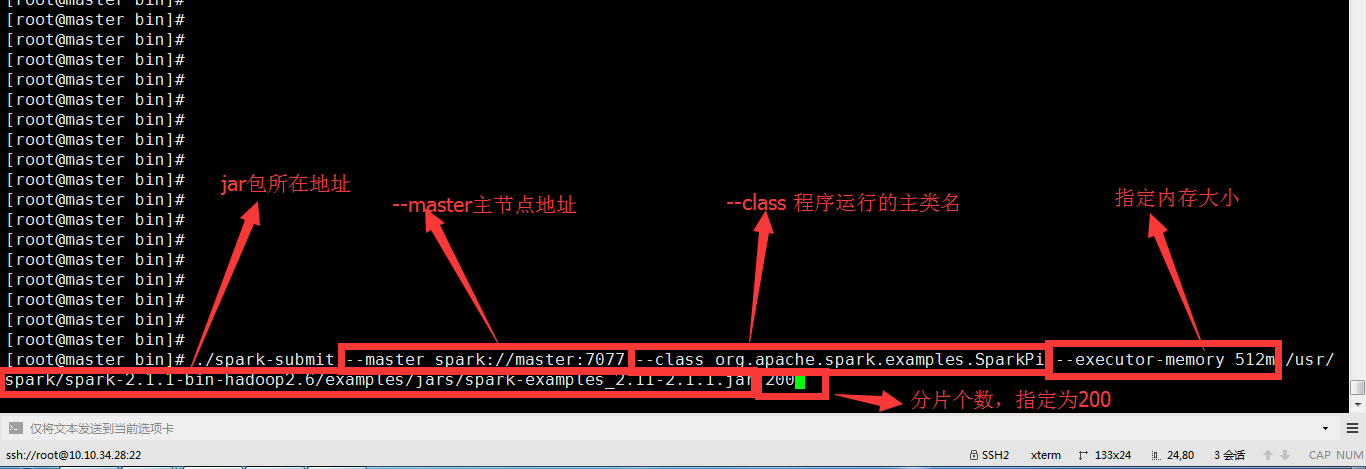
运行完成:

运算结果:
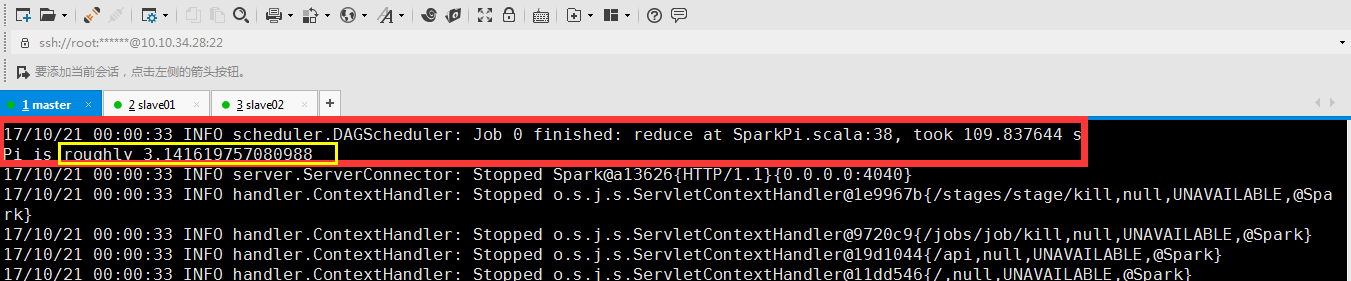
八、 观察运行情况


九、 在IDEA中编写wordcount程序
spark shell仅在测试和验证我们的程序时使用的较多,在生产环境中,通常会在IDE中编制程序,然后打成jar包,然后提交到集群,最常用的是创建一个Maven项目,利用Maven来管理jar包的依赖。
1. 创建一个项目




2. 加入pom文件依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi=http://www.w3.org/2001/XMLSchema-instance
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.simon.spark</groupId>
<artifactId>spark-first</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>1.7</maven.compiler.source>
<maven.compiler.target>1.7</maven.compiler.target>
<encoding>UTF-8</encoding>
<scala.version>2.11.8</scala.version>
<scala.compat.version>2.11</scala.compat.version>
</properties>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.1.1</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>2.1.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.4</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<testSourceDirectory>src/test/scala</testSourceDirectory>
<plugins>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.0</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
<configuration>
<args>
<arg>-make:transitive</arg>
<arg>-dependencyfile</arg>
<arg>${project.build.directory}/.scala_dependencies</arg>
</args>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.18.1</version>
<configuration>
<useFile>false</useFile>
<disableXmlReport>true</disableXmlReport>
<includes>
<include>**/*Test.*</include>
<include>**/*Suite.*</include>
</includes>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.3</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>com.simon.spark.WordCount</mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>3. 将src/main/java和src/test/java分别修改成src/main/scala和src/test/scala,与pom.xml中的配置保持一致

4. 创建一个Scala类

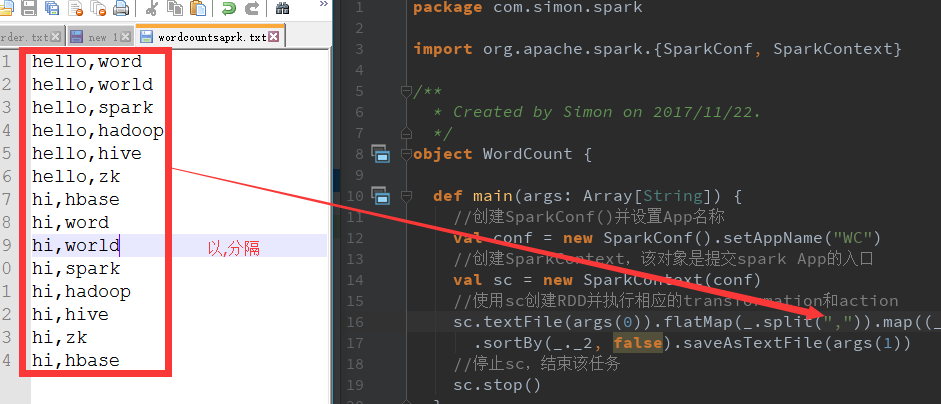
5. 编写spark的wordcount程序
import org.apache.spark.{SparkConf, SparkContext}
/**
* Created by Simon on 2017/11/22.
*/
object WordCount {
def main(args: Array[String]) {
//创建SparkConf()并设置App名称
val conf = new SparkConf().setAppName("WC")
//创建SparkContext,该对象是提交spark App的入口
val sc = new SparkContext(conf)
//使用sc创建RDD并执行相应的transformation和action
sc.textFile(args(0)).flatMap(_.split(" ")).map((_, 1)).reduceByKey(_+_, 1)
.sortBy(_._2, false).saveAsTextFile(args(1))
//停止sc,结束该任务
sc.stop()
}
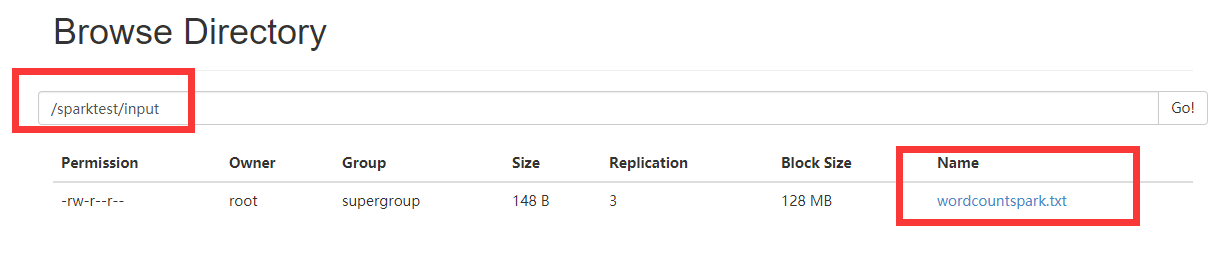
}6. 上传wordcount文件到hdfs
7. 打包程序


控制台:


打包出错。解决:
注释掉 -make:transitive

重新打包。


8. 上传jar包

9. spark-submit提交任务
注意 --参数的顺序
./spark-submit \
--class com.simon.spark.WordCount \
--master spark://master:7077 \
--executor-memory 1G \
--total-executor-cores 4 \
/usr/simonsource/spark-first-1.0-SNAPSHOT.jar \
hdfs://master:9000/sparktest/input/wordcountspark.txt\
hdfs://master:9000/sparktest/output
10.查看web页面
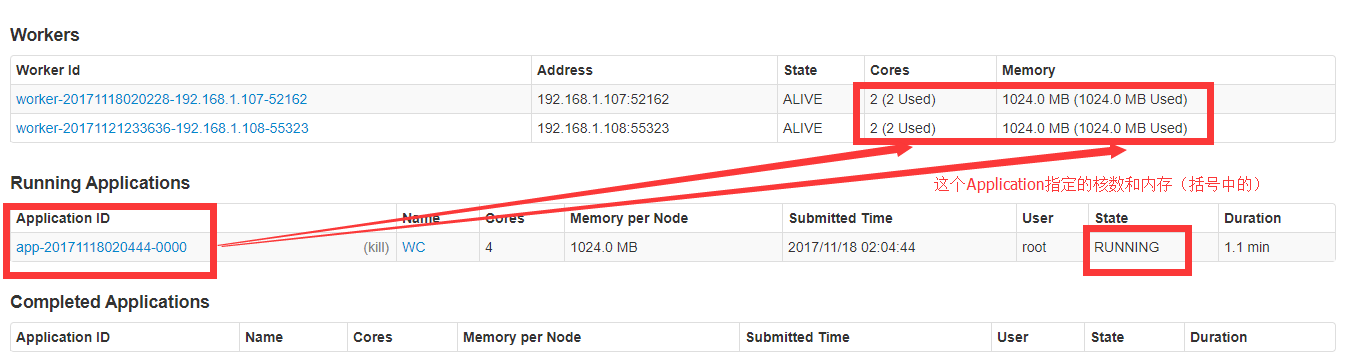
11.输出结果

报错了。但是输出路径输出了结果:

查看输出结果:

报错不影响运行结果。初步认定是内存分配问题,将DataNode节点的内存核数多分配即可解决。
十、 创建Java工程运行spark wordcount
1. 新建项目
2. 导入pom文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.simon.spark</groupId>
<artifactId>sparkJavaFirst</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<encoding>UTF-8</encoding>
<scala.version>2.11.8</scala.version>
<scala.compat.version>2.11</scala.compat.version>
</properties>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.1.1</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>2.1.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.4</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/java</sourceDirectory>
<testSourceDirectory>src/test/java</testSourceDirectory>
<plugins>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.0</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
<configuration>
<args>
<!--<arg>-make:transitive</arg>-->
<arg>-dependencyfile</arg>
<arg>${project.build.directory}/.scala_dependencies</arg>
</args>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.18.1</version>
<configuration>
<useFile>false</useFile>
<disableXmlReport>true</disableXmlReport>
<includes>
<include>**/*Test.*</include>
<include>**/*Suite.*</include>
</includes>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.3</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>com.simon.spark.WordCount</mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>3. 新建Java类
importorg.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import scala.Tuple2;
import java.util.Arrays;
/**
* Created by Simon on 2017/11/22.
*/
public class WordCount {
public static void main(String[] args) {
SparkConf sc = new SparkConf();
sc.setMaster("spark://master:7077").setAppName("wordcountjava");
JavaSparkContext jsc = new JavaSparkContext(sc);
JavaRDD<String> textFile = jsc.textFile("hdfs://master:9000/sparktest/input/wordcountspark.txt");
JavaRDD<String> words = textFile.flatMap( s -> Arrays.asList(s.split(",")).iterator());
JavaPairRDD<String, Integer> pairs = words.mapToPair(s -> new Tuple2<String, Integer>(s, 1));
JavaPairRDD<String, Integer> counts = pairs.reduceByKey((a, b) -> a + b);
//如果要实现按单词出现的次数从高低排名,1,首先要tuple的key value值,然后再按key排序,然后再交换过来
JavaPairRDD<Integer, String> tmp = counts.mapToPair(s->new Tuple2<Integer, String>(s._2,s._1)).sortByKey(false);
JavaPairRDD<String, Integer> result = tmp.mapToPair(s->new Tuple2<String, Integer>(s._2,s._1));
result.saveAsTextFile("hdfs://master:9000/sparktest/outputjava");
jsc.stop();
}
}4. 设置打包main class





5. 打包


6. 打包完成

7. 上传

8. 运行程序
./spark-submit \
--class WordCount
/usr/simonsource/sparkJavaFirst.jar
9. 结果














 303
303











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









