






参考文章:
GitHub - km1994/LLMs_interview_notes: 该仓库主要记录 大模型(LLMs) 算法工程师相关的面试题
https://www.zhihu.com/people/sudit/posts
https://github.com/zjhellofss/kuiperdatawhale/tree/main/slides
https://zhuanlan.zhihu.com/p/680262133
https://zhuanlan.zhihu.com/p/678602674
https://zhuanlan.zhihu.com/p/680075822
1 文章1:基础为主,但是面广
1.1 CUDA 基础
1. 线程组织结构:网格(grid)、线程块(block)和线程(thread)
一个 kernel 所启动的所有线程称为一个网格 grid
线程块是向GPU进行调度的最小单位,GPU同时支持多个线程块的执行,旧的不走新的不来
最大线程块儿大小是1024(开普勒架构后)
最大支持三维;大致与硬件结构中的GPU、SM(流式多处理器)和SP(流式处理器)一一对应。
2. 存储体系结构,以及优缺点:全局内存(Global Memory)、共享内存(Shared Memory)、常量内存(Constant Memory)/纹理内存(Texture Memory)和本地内存(Local Memory)
(图片上传不了)
共享内存比访问全局内存至少快个10倍;常量内存专门只能用于存储只读数据,纹理内存只能用于存储二维图像数据,这两种内存类型的访问速度都相当快,可以与共享内存相媲美。为了减少共享内存的计算负载。我们可以将一部分数据分配给纹理内存和常量内存,而不是将所有数据推送到共享内存中。
3. **怎么获取GPU新特性**:看官网,看发布会,还能。。。看guidebook?(最好问个业内的)
4. CUDA stream的概念:多个CUDA操作在不同的stream中并行执行,从而提高GPU的利用率和性能。
5. GPU和CPU各自优势:CPU复杂任务、轻度计算、低指令延迟(多级缓存)
GPU简单任务、繁重计算、高吞吐量
6. NPU、CPU、GPU区别:NPU仿生物神经网络而构建的,神经元操作很快,在深度学习的处理效率方面优势明显,但它需要定制化,不通用。
7. 半精度浮点数FP16的组成(真的问这个?!):1!5!精度范围是 2^−24。但是有溢出问题、精度也差。
8. TensorCore的加速原理:一个时钟周期干多件事,包括矩阵乘加;混合精度(中间变量32精度,不是说又可以又可以)
9. MPI,OpenMP以及CUDA各自适用的加速场景
MPI支持高效方便的点对点、广播和组播。从概念上讲,MPI应该属于OSI参考模型的第五层或者更高。它适用于需要在大规模分布式系统上进行高性能计算的场景,如集群计算等。
集合通信,可以谈一下Ring-Allreduce吗,为什么深度学习需要Ring-Allreduce?如果linear的话,就要一定的时间,才能全部传递到GPU0上,进行归约。如果是ring完全由系统中GPU之间最慢的连接决定。
Openmp执行模式采用fork-join的方式,其中fork创建新线程或者唤醒已有的线程,join将多个线程合并。适用于单台计算机上的多核并行计算。
CUDA用于GPU加速计算的并行计算平台和编程模型,适用于需要大规模并行计算的科学计算、机器学习、深度学习等领域。
10. RDMA:DMA,著名外挂原理,数据搬运不用CPU参与。R,remote,通讯的时候使用DMA,从一个主机内存直接访问另一个。
- 零拷贝(Zero-copy) - 应用程序能够直接执行数据传输,在不涉及到网络软件栈的情况下。数据能够被直接发送到缓冲区或者能够直接从缓冲区里接收,而不需要被复制到网络层。
- 内核旁路(Kernel bypass) - 应用程序可以直接在用户态执行数据传输,不需要在内核态与用户态之间做上下文切换。
- 不需要CPU干预(No CPU involvement) - 应用程序可以访问远程主机内存而不消耗远程主机中的任何CPU。远程主机内存能够被读取而不需要远程主机上的进程(或CPU)参与。远程主机的CPU的缓存(cache)不会被访问的内存内容所填充。
- 消息基于事务(Message based transactions) - 数据被处理为离散消息而不是流,消除了应用程序将流切割为不同消息/事务的需求。
- 支持分散/聚合条目(Scatter/gather entries support) - RDMA原生态支持分散/聚合。也就是说,读取多个内存缓冲区然后作为一个流发出去或者接收一个流然后写入到多个内存缓冲区里去。
11. 如何进行kernel的优化?
异步API(不认同,kernel本身要你异步?)
锁页内存(哥们,这和核有什么关系)
访存:全局内存合并(对齐字节)、控制L2访存命中率;避免bank冲突
线程级别并行:说白了,让更多的warp驻留SM(线程快大小、ss使用、reg使用)
指令级优化:计算访存比、指令级并行(后续指令不依赖前面的指令,那么指令之间就可以并行)(数据预取(Prefetch)、指令重排,将依赖的语句中间加入其他语句)
regsiter效率(SASS汇编层面)
用TensorCore
12. CPU上哪些并行优化方法?
编译器优化、算法优化(力扣,时间复杂度)、异步处理(提升程序并行)、多线程而非多进程(不用上下文切换)、善用缓存
SIMD指令集,提高向量运算效率。
CPU绑定、优先级调整、为进程设置资源限制、NUMA优化(尽量访问本地内存)、中断负载均衡
13. ARM相关的库(什么东西?)
14. PTX是什么
类似于汇编语言,但比汇编语言更易于编写和阅读。基本单位是线程块(thread block),线程是GPU上独立执行的最小单元。包含:加载内存、存储内存、线程同步和分支跳转等。还提供了一些针对GPU架构的优化指令,例如cooperative groups、shared memory和atomic operations等,这些指令能够更好地利用GPU的计算能力。
15. roofline模型,如何确定BLOCK_SIZE
计算强度(Operational Intensity,OI,是指算法的计算量和数据量之比)和内存带宽两个指标。
计算密集型和访存密集型两种。
BLOCK_SIZE需要结合具体硬件环境和程序特点。
16. GPU资源调度方法
17. 稀疏矩阵存储格式,应用场景,计算方法
三元组、按行列压缩、对角线数组;最小割算法、稀疏矩阵乘法等计算的复杂度通常远远低于稠密矩阵乘法、加速方法也不一样
18. CPU指令吞吐量和延迟
时钟频率、时钟周期、机器周期(一个指令的时间)、指令吞吐量(CPU每秒钟能够执行的指令数)、指令时延(一个指令所需的时间,通常以时钟周期为单位)
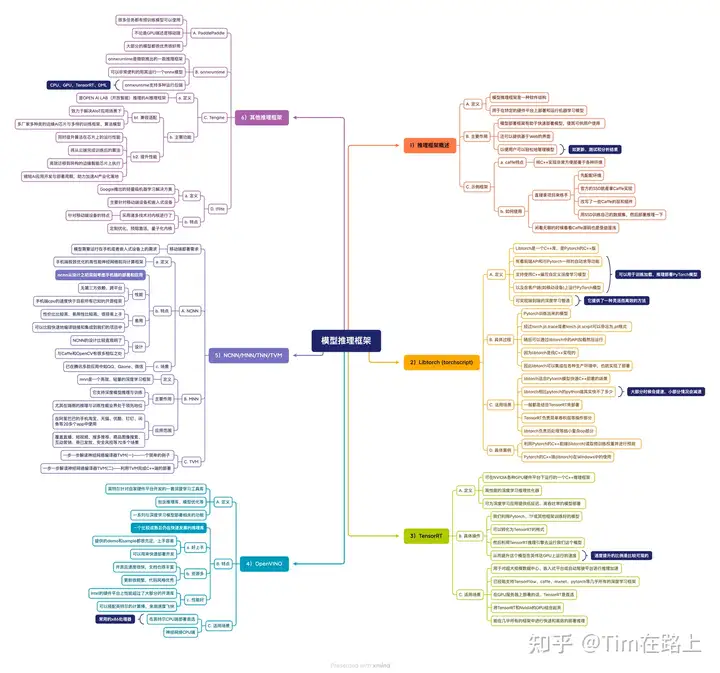
1.2 AI 框架知识
1. ONNX:开放的IR,主要用于不同深度学习框架之间的模型转换和互操作性。ONNX通过定义一套标准化的算子和模型格式来实现这一点。无论你使用何种训练框架训练模型(比如TensorFlow/Pytorch/OneFlow/Paddle),在训练完毕后你都可以将这些框架的模型统一转换为ONNX这种统一的格式进行存储,不涉及模型的优化过程。
2. TVM的整体结构(?)
前端:多种深度学习框架的模型作为输入;
中间表示(IR)
自动调度(AutoTVM/AutoScheduler):为了在特定硬件上获得最佳性能;
运行时
编译流程
3. 推理优化的意义
深度学习的广泛应用和以Transformer大模型为基座的深度算法的普及,tensorflow或者pytorch的推理性能远远跟不上了。高计算复杂度、大内存需求、并行性限制等问题。
模型压缩技术:通过知识蒸馏、权重剪枝、量化
高效变体的开发:针对自注意力机制的高计算复杂度,开发了如Transformers的变体
硬件加速和专用推理引擎
动态量化和混合精度推理
4. 推理优化的常用方法
模型压缩:剪枝、量化(存储、运算、通信更快)、蒸馏
加速推理:cache,多算子融合(减少kernel启动)、计算图优化(减少节点数量、高效代替低效、并行分支优先)
5. 框架源码(6666)
6. TensorRT如何进行自定义算子开发?(兄弟,快来不及了!)
其次,开始实现自定义算子,主要分为三步,定义插件类,实现算子逻辑和注册插件,下面分别展开说说。
- 定义插件类:继承
nvinfer1::IPluginV2接口,实现其虚函数,包括算子计算(enqueue)、输出维度(getOutputDimensions)、数据类型和格式配置(configureWithFormat)、初始化与清理(initialize和terminate)、序列化与反序列化(serialize和deserialize)等 - 核心实现:在
enqueue函数中实现算子的具体计算逻辑,可能需要使用CUDA等技术在GPU上进行并行计算以提高效率。 - 注册插件:通过实现
nvinfer1::IPluginCreator接口并注册插件,使得TensorRT能够识别和使用自定义算子。
再次,是构建使用自定义算子代码
- 创建插件实例:在网络构建过程中,使用插件工厂或直接调用插件类的构造函数创建自定义算子实例,并将其嵌入到模型中。
- 序列化和反序列化:确保自定义算子能够被正确地序列化和反序列化,以便模型的保存和加载。
最后,测试和验证
- 验证正确性和性能:通过与预期结果或其他框架的对比,验证自定义算子的实现是否正确、性能是否达标,并确保其在不同条件下的鲁棒性。
7. TensorRT实现了哪些推理优化?
常量折叠(提前计算,计算时直接用)、算子融合(比如CBR,减少了内存访问和计算步骤)、量化(显著减少模型的大小和推理时间,同时也减少了内存带宽的需求)、层自动调整(针对特定的硬件平台自动选择最优的算法)、多流执行(利用GPU的并行处理能力,通过多流执行来同时处理多个推理请求)
8. 算子融合为什么能加速推理,有哪些,怎么实现?
减少了内存访问次数和数据传输量、减少了CPU和GPU之间的同步点
9. 模型量化的加速原理
从浮点数(如FP32)转换为低精度的格式(如INT8或FP16);
模拟量化(模型训练的时候就模拟量化的效果)
量化校准(通过在量化前后对模型进行校准,选择最优的量化参数(如量化比例和零点),以最小化量化误差。常用的校准方法包括最小最大值校准、百分位校准)
10. ONNX Runtime实现机制
ONNX格式的模型,开放格式;
通过提供一系列的“执行提供程序”(Execution Providers,EPs)来支持不同的硬件,根据可用的执行提供程序和硬件资源自动选择最适合当前环境的执行路径。
11. 推理框架的关注部分
核心部分:模型解析器、图优化器(减少不必要的计算、算子融合)、执行引擎(特定硬件执行任务)、硬件抽象层(为不同硬件提供定制化支持)
主要关注:确保模型能够在多种平台上高效运行利用硬件特点优化、图优化技术。通过算子融合、优化数据传输路径等,减少不必要的计算和内存访问,提升模型执行的效率。
12. 各种框架优劣势
https://pic1.zhimg.com/80/v2-7986459da1d010438c3bb6064d7c0688_720w.webp
trt和ort就不说了。TensorFlow Lite,专为移动设备。
TensorFlow像是搞数据的人研发的,Pytorch才像是搞算法人研发的。
TensorFlow考虑了分布式计算、大规模数据处理和生产环境的需求。TensorFlow使用静态计算图,需要先定义后运行,适合于大型模型和复杂的神经网络。
Pytorch设计理念侧重于灵活性和直观性
13. 分布式训练的并行模式
数据并行和模型并行
数据并行:通过梯度聚合和同步来更新模型参数。大量的通信开销、需要额外的内存来存储模型副本和梯度
模型并行:将模型分解为多个部分,与其他设备交换中间结果。更复杂的编程和通信模式,容易出现性能瓶颈
14. 分布式训练有什么面临的问题
通信开销和延迟(可以混合精度训练+RDMA)、容错性和可伸缩性、
15. MPI怎么用于AI框架(不要这么巧好吗)
数据并行:MPI提供了消息传递的能力,可以在不同计算节点之间传输数据,实现数据的并行处理。
参数同步:模型参数需要进行同步,以保持一致性和提高训练效果。
集群扩展:通过MPI,可以实现任务的分发和调度,从而实现在集群中进行规模化的训练和推理。
容错性
16. 移动端和在服务器的推理优化
17. 自动驾驶推理框架(不干)
18. 反向传播原理和源码
自己看
19. 推理模型调度方法(不干)
20. 推荐模型怎么部署(不干)
21. 计算图切分,怎么用于大模型推理
2 文章2:CUDA基础
基础夯实,就像扎马步,倒不下来,就还有反击余地
2.1 概念
SIMD,全称为“Single Instruction Multiple Data”,单个指令同时操作多个数据点,CPU也有,向量运算(向量寄存器)。
SIMT,全称为“Single Instruction Multiple Threads”,即“单指令多线程”,是SIMD技术的一种扩展,主要应用于GPU(图形处理器)的体系结构中。多线程听从一个controller的指挥。
2.2 编译相关
nvcc 先将设备代码编译为 PTX(parallel thread execution)伪汇编代码,再将 PTX 代码编译为二进制的 cubin 目标代码。
在源设备代码编译为 PTX 代码时,需要使用 -arch=compute_XY 来指定一个虚拟架构的计算能力,在将 PTX 代码编译为 cubin 代码时,需要使用选项 -code=sm_ZW 指定一个真实架构的计算能力,真实架构号必须大于等于虚拟架构号。
2.3 加速相关
缩减数据传输所花时间的比例
算术强度是指其中算术操作的工作量(时间)与必要的内存操作的工作量(时间)之比。
提高每个流处理器能够驻留的线程数量(叫线程块数量也对?):并行规模和资源限制决定
2.4 内存组织结构
动态全局内存和静态全局内存(是否编译期间决定)
静态全局变量需要要用 cudaMemcpyFromSymbol 和 cudaMemcpyToSymbol读写
常量内存也是全局内存的一种,物理位置上都位于芯片外,但是由于常量缓存;const 参数也会被分配在常量内存上;常量数组封装在结构体内,然后将结构体作为 const 参数传给核函数
寄存器:单个线程可以使用的寄存器数上限为 255(每个寄存器可以存放 4 字节数据),一个线程块可以使用的寄存器数上限为 64k。
共享内存:共享内存分为静态共享内存和动态共享内存两种。静态是核函数定义,用个标识符。动态则需要内部定义extern共享,并且kernel启动的时候第三个参数加上。
SM 中应该包含如下结构(如图所示):寄存器内存、共享内存、常量缓存、纹理和表面缓存、L1 Cache、调度器和核心
限制驻留SM的有:寄存器内存、共享内存、本身只能主流1024/2048的线程
使用 __launch_bounds__ 修饰符:该修饰符可以指定每个线程块的最大线程数,以及每个 SM 至少应该被分配多少个块。
--maxrregcount 可以指定每个线程能够使用的寄存器数量,多出的部分,会溢出到局部内存中.
2.4.1 加速策略
使用 cudaMalloc 分配的内存首地址是 256 字节的整数倍。
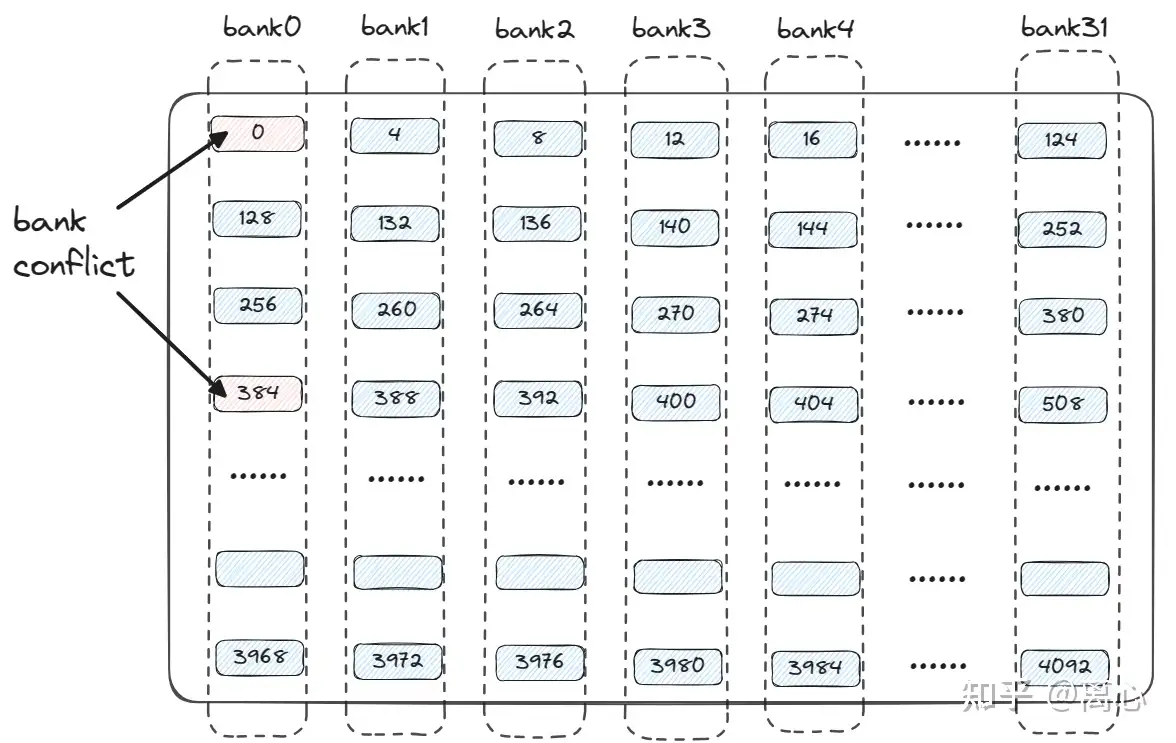
Bank Conflict: https://pic3.zhimg.com/80/v2-4a3bd273debc4a0f96bbe18deac23d4e_1440w.webp
一个线程分配一个访问端口,不同线程不会分配同一个访问端口。不同线程如果访问同一个bank不同数据,就会冲突。
原子操作伤害性能。
2.5 CUDA线程束
SIMT: 同一时刻,一个线程束中的线程只能执行一个共同的指令或者闲置。
线程束的同步函数与表决函数。所谓shfl:
广播某个线程的寄存器值,取向上、向下距离为x的某个进程的值,或者用xor进行通信。但是线程束洗牌函数共享范围不超过一个线程束大小。
2.6 异步执行
我们可以将 Host2Device Memcpy,Call Kernel Function,和 Device2Host Memcpy 三个操作组合成流水线并行的工作流,每个时刻设备最多可以同时执行三个 CUDA 操作
异步内存传输,需要锁页内存。
2.7 其它零碎解释
不可分页内存的优势:性能、数据一致性和稳定性;风险:资源占用和内存泄漏
流水线并行优势:吞吐量、处理时间和资源利用率。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}