







前言
在上一篇文章中,介绍了一些多进程的基本知识,相比较于python单进程速度还是要快上不少的,今天我们就用一个简单的小实践来体现一下多进程的具体实现,很简单哟~
正文
马上快要五一了,想出去玩玩,就去看了下机票价格,但是呢网上的机票网站太多太复杂,嘿嘿嘿,英雄无用武之地,马上撸起代码,爬取了携程的5月1号的一些机票信息,由于是一个简单的小实践,并没有爬取太多的数据,就给大家讲个一个小思路,了解多进程的用法就好。
首先我们先看看页面
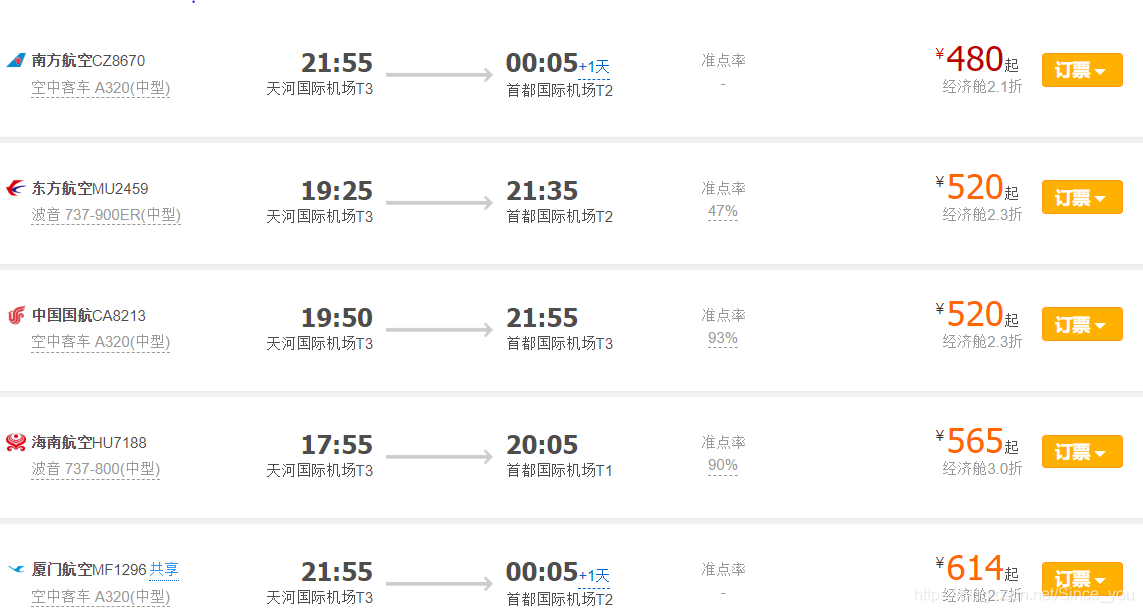
打开开发者工具,我们想看看这些数据是不是在源码内呢,随便搜索一个值,我们就拿480去源码内搜了下,不出所料,不在里面。那么正常的请求是肯定不能请求到数据了。这边要么使用selenium去爬取数据,要么解析它的源码js,返回数据。当然这两种方案都比较麻烦,我这么懒得人,肯定不愿意啊。突然喜洋洋附体,脑袋上闪过一盏灯,有没有api接口呀。说去找就去找,嘿嘿,还是很人性化的,一会就让我找到了,如下图:
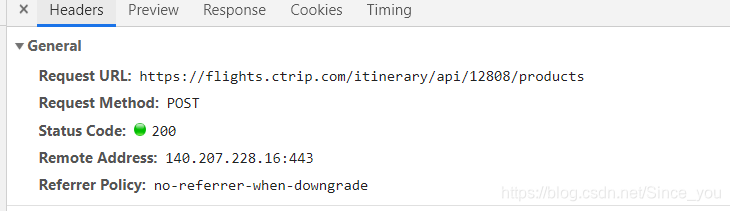

我们发现呀,他是一个post请求,传入的data是一个字典,数据返回也是一大串json数据,找到了这个,下面就简单多了,解析一下json就好了。看下完整源码:
import requests
import json
from multiprocessing import Pool
import pymysql
from requests.exceptions import Timeout
def get_detail_info(data):
url = "https://flights.ctrip.com/itinerary/api/12808/products"
conn = pymysql.connect(host="localhost",user="xxx",password="xxx",port=3306,db="xc",charset="utf8",autocommit=True)
cur = conn.cursor()
headers = {
"accept": "*/*",
"accept-encoding": "gzip, deflate, br",
"accept-language": "zh-CN,zh;q=0.9",
"content-length": "225",
"content-type": "application/json",
"origin": "https://flights.ctrip.com",
"referer": "https://flights.ctrip.com/itinerary/oneway/wuh-bjs?date=2019-05-01",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36"
}
try:
req = requests.post(url,data = json.dumps(data),headers = headers,timeout = 10)
except Timeout:
print("超时啦————————————————————————————")
json_value = json.loads(req.text) # 返回的是一个json格式
routelist = json_value["data"]["routeList"]
for i in routelist:
flights = i["legs"]
for flight in flights:
airlineName = flight["flight"]["airlineName"]
de_airportName = flight["flight"]["departureAirportInfo"]["airportName"]+flight["flight"]["departureAirportInfo"]["terminal"]["name"]
ar_airportName = flight["flight"]["arrivalAirportInfo"]["airportName"]+flight["flight"]["arrivalAirportInfo"]["terminal"]["name"]
departureDate = flight["flight"]["departureDate"]
arrivalDate = flight["flight"]["arrivalDate"]
cabins = flight["cabins"]
for cabin in cabins:
price = cabin["price"]["price"]
sql = "insert into airline(airlineName,de_airportName,ar_airportName,departureDate,arrivalDate,price)values(%s,%s,%s,%s,%s,%s)"
params = (airlineName,de_airportName,ar_airportName,departureDate,arrivalDate,price)
cur.execute(sql,params)
if __name__ == '__main__':
pool = Pool(processes=2)
data = [{"flightWay": "Oneway", "classType": "ALL", "hasChild": "false", "hasBaby": "false", "searchIndex": 1,"airportParams": [{"dcity": "WUH", "acity": "BJS", "dcityname": "武汉", "acityname": "北京", "date": "2019-05-01","dcityid": 477, "acityid": 1}]},{"flightWay": "Oneway", "classType": "ALL", "hasChild": "false", "hasBaby": "false", "searchIndex": 1,"airportParams": [{"dcity": "WUH", "acity": "SHA", "dcityname": "武汉", "acityname": "上海", "date": "2019-05-01","dcityid": 477, "acityid": 2}]},{"flightWay": "Oneway", "classType": "ALL", "hasChild": "false", "hasBaby": "false", "searchIndex": 1,"airportParams": [{"dcity": "WUH", "acity": "CAN", "dcityname": "武汉", "acityname": "广州", "date": "2019-05-01","dcityid": 477, "acityid": 32}]}]
pool.map(get_detail_info, data)
结果如下:
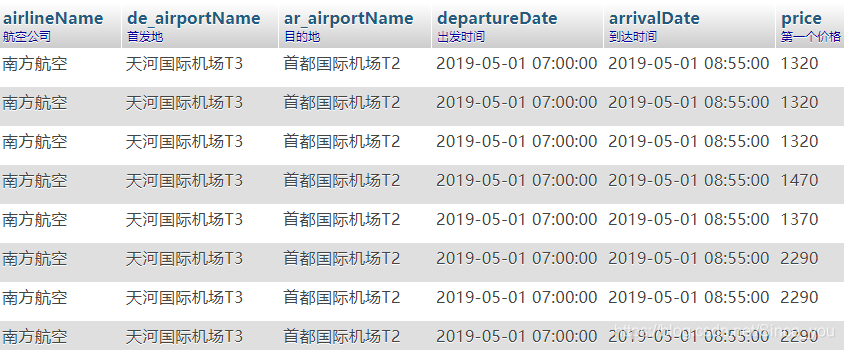
上面导入多进程Pool这个属性,给进程池内最大容量为2,调用了map方法,就可以运行了多进程了,是不是很简单。把它录入数据库后,就大功告成了,我就简单的解析了几个字段,有兴趣的可以自己去看看。后面就可以根据自己的情况,无论是做时间序列预测还是其他分析都是可以的,欢迎大家踊跃发言。
同时欢迎访问个人博客主页… …














 828
828











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









