






 本文介绍了一个使用Java和jsoup库实现的爬虫项目,旨在抓取特定航空公司旗下的所有航班信息。项目分为两个阶段:首先根据航空公司获取所有航班号,再进一步抓取各航班的飞行轨迹数据。
本文介绍了一个使用Java和jsoup库实现的爬虫项目,旨在抓取特定航空公司旗下的所有航班信息。项目分为两个阶段:首先根据航空公司获取所有航班号,再进一步抓取各航班的飞行轨迹数据。
接到一个爬虫项目,java编写的调用jsoup。来调取国内民航的轨迹。第一步,先进行根据飞机所属于的航空公司,然后根据改航空公司爬出所有的的航班号。第二步,根据查询出的航班号进行飞行轨迹的的数据爬去。本博客先进行第一阶段的项目代码编写。
所用的网站:http://zh.flightaware.com/
上面包括所需要爬取的数据。
文件所需要的jar包:
然后就是在主文件中进行
public class FlightInfo {
public static List<String> airlines = new ArrayList<>(); //存储航空公司
public static void main(String[] args) {
// TODO Auto-generated method stub
FlightNumber fln = new FlightNumber();
fln.readProperties("config.properties");
airlines = fln.readAirlines();
/*for (int i = 0; i < airlines.size(); i++) {
fln.GetFlightNo(airlines.get(i));
}*/
fln.GetFlightNo("CSN");
}
在fln中进行爬取的操作:
public class FlightNumber {
String Flight_Base_URL = null;
List<String> airline_list = null;
/**
* 读取配置文件
*
* @param propfile
* 配置文件名称
*/
public void readProperties(String propfile) {
Properties pps = new Properties();
try {
pps.load(new FileInputStream(propfile));
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
Flight_Base_URL = pps.getProperty("FLIGHT_BASE_URL");
}
// 从flightaware网站获取每个航空公司的所有航班,并将其写入文件xxx.txt,其中xxx是航空公司的
// ICAO码。
public List<String> readAirlines() {
// 读配置文件,获取所有航空公司的ICAO码,将其放入airline_list
if (airline_list == null)
airline_list = new ArrayList<String>();
airline_list.clear();
airline_list = Tools.readTxtFile("fleetlist.txt");
return airline_list;
/* for (int i = 0; i < airline_list.size(); i++) {
System.out.println(airline_list.get(i));
}
*/
// 遍历airline_list,针对每个航空公司,获取其所有的航班号,放入flight_list
}
//若返回值非0,表示还有未解析的页面,需要再次访问URL
//icao是航空公司的ICAO码
public void GetFlightNo(String icao)
{ int count = 0;
int i = 0;
String flight_url = Flight_Base_URL;
flight_url = flight_url.replace("{ICAO}", icao);
flight_url = flight_url.replace("{OFFSET}", String.valueOf(i));
System.out.println("connect to: " + flight_url);
org.jsoup.nodes.Document doc = Tools.UrlConnect(flight_url);
if(doc == null)
{
System.out.println("Failed to connect: " + flight_url);
return;
}
//System.out.println(doc.toString());
/*
*进行doc的HTML的解析
*
*/
System.out.println("执行解析!!!");
while(true){
int flag = Tools.soupHtml(doc);
if(flag == 1){
flight_url = Flight_Base_URL;
count = count+20;
flight_url = flight_url.replace("{ICAO}", icao);
flight_url = flight_url.replace("{OFFSET}", String.valueOf(count));
//System.out.println("connect to: " + flight_url);
doc = Tools.UrlConnect(flight_url);
if(doc == null)
{
System.out.println("Failed to connect: " + flight_url);
return;
}
}
else
break;
}
}所需要的配置文件:config.properties
FLIGHT_BASE_URL = http\://zh.flightaware.com/live/fleet/{ICAO}?;offset\={OFFSET};order\=ident;sort\=ASC
其中fleetlist.txt
CGN CSC LKE CYZ CQH OKA CCA CKK GDC CSN UEA CFA CSH HXA GCR DKH CHH CBJ JAE JOY CUA KNA CXA CES HBH CQN CHB QDA CDG TBA YZR CSZ
上面的都是放在一列的,但是为了节省空间,我将所有的航空公司放在一起,中间用两个空格隔开。
然后使用自己写的工具类,进行爬去。
public class Tools {
/**
* Method: saveHtml Description: save String to file
*
* @param url_str
* the url string for connection
* @param filepath
* file path which need to be saved
*/
public static org.jsoup.nodes.Document UrlConnect(String url_str) {
URL url = null;
try {
url = new URL(url_str);
} catch (MalformedURLException e) {
e.printStackTrace();
}
org.jsoup.nodes.Document doc = null;
int sec_cont = 1000;
try {
URLConnection url_con = url.openConnection();
url_con.setDoOutput(true);
url_con.setReadTimeout(10 * sec_cont);
url_con.setRequestProperty("User-Agent",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)");
InputStream htm_in = url_con.getInputStream();
doc = Jsoup.parse(htm_in, "UTF-8", url_str);
} catch (Exception e) {
return null;
}
return doc;
}
/**
* 功能:Java读取txt文件的内容 步骤:1:先获得文件句柄 2:获得文件句柄当做是输入一个字节码流,需要对这个输入流进行读取
* 3:读取到输入流后,需要读取生成字节流 4:一行一行的输出。readline()。 备注:需要考虑的是异常情况
*
* @param filePath
*/
public static List<String> readTxtFile(String filePath) {
List<String> str = new ArrayList<String>();
String fp = filePath;
try {
String encoding = "GBK";
File file = new File(fp);
if (file.isFile() && file.exists()) { // 判断文件是否存在
InputStreamReader read = new InputStreamReader(
new FileInputStream(file), encoding);// 考虑到编码格式
BufferedReader bufferedReader = new BufferedReader(read);
String lineTxt = null;
while ((lineTxt = bufferedReader.readLine()) != null) {
if (!lineTxt.equals("")) {
str.add(lineTxt);
}
}
read.close();
} else {
System.out.println("找不到指定的文件");
}
} catch (Exception e) {
System.out.println("读取文件内容出错");
e.printStackTrace();
}
return str;
}
/**
* Method: saveHtml Description: save String to file
*
* @param filepath
* file path which need to be saved
* @param str
* string saved
*/
public static void saveFile(String filepath, String str) {
File file = new File(filepath);
if (file.exists())
file.delete();
try {
OutputStreamWriter outs = new OutputStreamWriter(
new FileOutputStream(filepath, true), "utf-8");
outs.write(str);
outs.close();
} catch (IOException e) {
System.out.println("Error at save file...");
e.printStackTrace();
}
}
/**
* 得到pathname目录下的所有文件
*
* @param pathname
* @return 返回一个文件名的列表
*/
public static List<String> getAllFileNames(String pathname) {
File file = new File(pathname);
if (!file.exists())
return null;
List<String> valueFiles = new ArrayList<String>();
File[] fs = file.listFiles();
for (int i = 0; i < fs.length; i++) {
valueFiles.add(fs[i].getName());
}
return valueFiles;
}
/**
* 得到正确的下一天,考虑跨月,跨年
*
* @param year
* @param month
* @param day
* @return 返回“yyyy/mm/dd”格式的下一天字符串
*/
public static String nextDay(int year, int month, int day) {
String res;
int flag = 0;
int calendar[][] = {
{ 0, 31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31 },
{ 0, 31, 29, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31 } };
day++;
if ((year % 4 == 0 && year % 100 != 0) || (year % 400 == 0))
flag = 1;
if (day > calendar[flag][month]) {
day = 1;
month++;
}
if (month > 12) {
year++;
month = 1;
}
res = year + "/" + month + "/" + day;
return res;
}
/**
* 解析html
*/
public static int soupHtml(org.jsoup.nodes.Document doc){
int flag = 0,j;
//System.out.println("解析开始!!!");
Elements trs = doc.select("table.prettyTable").select("tr");
int i;
for(i=0;i<trs.size();i++){
String txt = null;
Elements tds = trs.get(i).select("td");
for (j=0; j<tds.size(); j++){
txt = tds.get(j).firstElementSibling().text();
}
if(txt!=null){
System.out.print(txt+" ");
}
}
//循环查询是否遍历完全
String is_over= doc.select("span").select("a").html();
String s[] = is_over.split("\n");
if(s[0].equals("后20条") ) {
flag=1;
}
if(flag == 1){
return 1;
}
else
return 0;
}
}
其中爬取的网页如下所示:
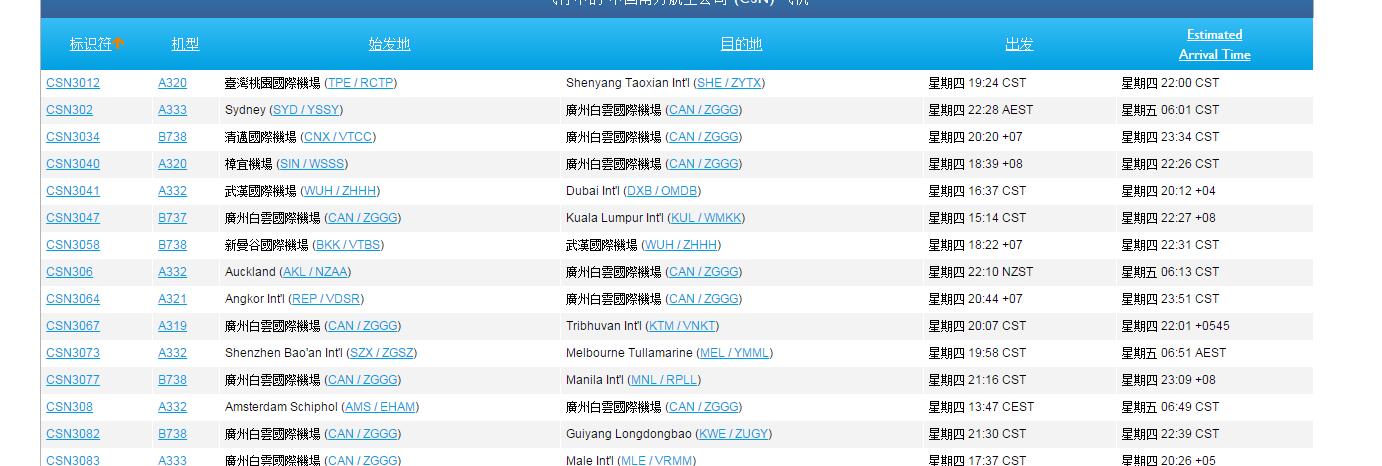
前面的标识符就是某航空公司的航班号,然后将这些航班号爬去下来,然后进行保存,网址就是配置文件中的地址,代码运行时进行临时替换。然后就能动态的进行爬取。
其中只是修改其中的offset的选项,让其+20。jsoup对html的解析:下面的讲解非常有帮助,类似与jQuery的用法。
jsoup的用法:
第一步 获取html文档对象。
Document对象:用于接收html的文档内容
Jsoup.connect(String url).get():用于指定网址,返回值为Document对象
ps:如果需要解析访问较慢的网站的话需要加上timeout方法,以放抛出RuntimeException异常。
//文档对象,用来接收html页面
Document document = null;
try {
//获取指定网址的页面内容
document = Jsoup.connect("http://www.baidu.com/").timeout(50000).get();
} catch (IOException e) {
e.printStackTrace();
}
//获得文件对象
File input = new File("/tmp/input.html");
//获得文档对象
Document doc = Jsoup.parse(input, "UTF-8", "http://example.com/");第二步 通过选择器得到想要的Dom结点
jsoup提供了丰富的选择器,选择器的方便程度媲美jQuery,其中的筛选选择器,父选择器等更是jQuery上本身就拥有的,具体该怎么用这个选择器呢?相信习惯jQuery的童鞋很快就会适应jsoup选择器的。
首先我们需要认识一下Elements对象,Elements类实现了java.lang.List接口,主要用于保存选择器选择到的结点。
接下来我们来看一下Document对象获取结点的步骤:
//通过Document的select方法获取class为abc的Elements结点集合
Elements elements = document.select(".abc");
//得到结点的第一个对象
Element element = elements.get(0);
//获取想要的属性值
String href = element.attr("href");共三步,就可以得到想要的结果了,是不是很方便呢?
并且第二个步骤是可以省略的,下面让我们来看一下Elements的attr()方法的源码
/**
Get an attribute value from the first matched element that has the attribute.
@param attributeKey The attribute key.
@return The attribute value from the first matched element that has the attribute.. If no elements were matched (isEmpty() == true),
or if the no elements have the attribute, returns empty string.
@see #hasAttr(String)
*/
public String attr(String attributeKey) {
for (Element element : contents) {
if (element.hasAttr(attributeKey))
return element.attr(attributeKey);
}
return "";
}上边两个方法可以清除的看到当我们输入结点名称时,他会自动遍历所有集合内所有结点是否拥有此属性,如果拥有此属性即跳出返回结果,如无法找到含有此属性的结点则返回 Empty。
jsoup的选择器除了上面的例子里的类选择器还有下面的丰富选择器,大家可根据需要来选择使用。
Selector选择器
tagname: 通过标签查找元素,比如:ans|tag: 通过标签在命名空间查找元素,比如:可以用fb|name语法来查找<fb:name>元素#id: 通过ID查找元素,比如:#logo.class: 通过class名称查找元素,比如:.masthead[attribute]: 利用属性查找元素,比如:[href][^attr]: 利用属性名前缀来查找元素,比如:可以用[^data-]来查找带有HTML5 Dataset属性的元素[attr=value]: 利用属性值来查找元素,比如:[width=500][attr^=value],[attr$=value],[attr*=value]: 利用匹配属性值开头、结尾或包含属性值来查找元素,比如:[href*=/path/][attr~=regex]: 利用属性值匹配正则表达式来查找元素,比如:img[src~=(?i)\.(png|jpe?g)]*: 这个符号将匹配所有元素
Selector选择器组合使用
el#id: 元素+ID,比如:div#logoel.class: 元素+class,比如:div.mastheadel[attr]: 元素+class,比如:a[href]- 任意组合,比如:
a[href].highlight ancestor child: 查找某个元素下子元素,比如:可以用.body p查找在"body"元素下的所有p元素parent > child: 查找某个父元素下的直接子元素,比如:可以用div.content > p查找p元素,也可以用body > *查找body标签下所有直接子元素siblingA + siblingB: 查找在A元素之前第一个同级元素B,比如:div.head + divsiblingA ~ siblingX: 查找A元素之前的同级X元素,比如:h1 ~ pel, el, el:多个选择器组合,查找匹配任一选择器的唯一元素,例如:div.masthead, div.logo
伪选择器selectors
:lt(n): 查找哪些元素的同级索引值(它的位置在DOM树中是相对于它的父节点)小于n,比如:td:lt(3)表示小于三列的元素:gt(n):查找哪些元素的同级索引值大于n,比如:div p:gt(2)表示哪些div中有包含2个以上的p元素:eq(n): 查找哪些元素的同级索引值与n相等,比如:form input:eq(1)表示包含一个input标签的Form元素:has(seletor): 查找匹配选择器包含元素的元素,比如:div:has(p)表示哪些div包含了p元素:not(selector): 查找与选择器不匹配的元素,比如:div:not(.logo)表示不包含 class="logo" 元素的所有 div 列表:contains(text): 查找包含给定文本的元素,搜索不区分大不写,比如:p:contains(jsoup):containsOwn(text): 查找直接包含给定文本的元素:matches(regex): 查找哪些元素的文本匹配指定的正则表达式,比如:div:matches((?i)login):matchesOwn(regex): 查找自身包含文本匹配指定正则表达式的元素- 注意:上述伪选择器索引是从0开始的,也就是说第一个元素索引值为0,第二个元素index为1等
第三步 修改结点属性
对于仅仅要读取数据的朋友们来说上面两步已经足以完成需求,而对于有修改文档内容需求的来说Jsoup同样提供了强大的属性赋值,例如:
//为结点添加内容
element.html(内容);
//添加属性
element.attr(属性名,属性值)
//添加类
element.addClass(类名)

















 847
847

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









