







TRAR: Routing the Attention Spans in Transformer for Visual Question Answering
一、Background
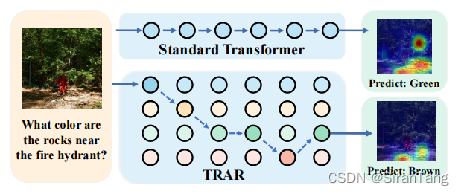
With its superior global dependency modeling capabilities, Transformer and its variants have become the primary structure for many visual and language tasks. However, in tasks such as visual question answering (VQA) and directed expression understanding (REC), multimodal prediction usually requires visual information from macro to micro. Therefore, how to dynamically schedule global and local dependency modeling in Transformer becomes an emerging problem.
二、Motivation
1)In some V&L tasks, such as visual question answering (VQA) and directed expressive comprehension (REC), multimodal reasoning usually requires visual attention from different receptive fields. Not only should the model understand the overall semantics, but more importantly, it needs to capture the local relationships in order to answer the right answer.
2)In this paper, the authors propose a new lightweight routing scheme called Transformer Routing (TRAR), which enables automatic attention selection without increasing computation and video memory overhead.
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2433
2433











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









