







英文文本处理:有分词,去停用词,提取词干,词性分析,依赖分析,命名实体识别等步骤。目的是为了文本分类建模和文本相似度建模做到更高的准确率。后面会用到深度学习提高准确率。
1.英文文本处理与NLTK库
文本处理解决分类,解决情感分析,解决翻译等等一系列问题。接下来我们来看一下,在英文文本当中,
基本的处理文本的一些操作。
- 1.1 英文Tokenization(标记化/分词)
不能直接送到模型当中进行分析的。成段的文字直接送到算法或模型是没办法理解的。我们通常把文本切成小的有意义的独立单位(字,词,短语),这个过程叫tokenization。在NLTK中提供了2种不同方式的tokenization,sentence tokenization 和 word tokenization,前者把文本进行“断句”,后者对文本进行“分词”。
#准备工作:读取文本
import nltk
from nltk import word_tokenize,sent_tokenize
#读入数据
corpus = open('./data/text.txt','r').read() #read()读取整个文章
#查看类型
print("corpus的数据类型为:",type(corpus))
print(corpus)
结果:
corpus的数据类型为: <class 'str'>
A ``knowledge engineer'' interviews experts in a certain domain and tries to embody their knowledge in a computer program
for carrying out some task. How well this works depends on whether the intellectual mechanisms required for the task are
within the present state of AI. When this turned out not to be so, there were many disappointing results. One of the first expert
systems was MYCIN in 1974, which diagnosed bacterial infections of the blood and suggested treatments. It did better than
medical students or practicing doctors, provided its limitations were observed. Namely, its ontology included bacteria,
symptoms, and treatments and did not include patients, doctors, hospitals, death, recovery, and events occurring in time. Its
interactions depended on a single patient being considered. Since the experts consulted by the knowledge engineers knew
about patients, doctors, death, recovery, etc., it is clear that the knowledge engineers forced what the experts told them into a
predetermined framework. In the present state of AI, this has to be true. The usefulness of current expert systems depends on
their users having common sense.
步骤1.断句分词
为了处理数据的输入形态
#断句
sentences = sent_tokenize(corpus)
sentences
结果:
["A ``knowledge engineer'' interviews experts in a certain domain and tries to embody their knowledge in a computer program for carrying out some task.",
'How well this works depends on whether the intellectual mechanisms required for the task are within the present state of AI.',
'When this turned out not to be so, there were many disappointing results.',
'One of the first expert systems was MYCIN in 1974, which diagnosed bacterial infections of the blood and suggested treatments.',
'It did better than medical students or practicing doctors, provided its limitations were observed.',
'Namely, its ontology included bacteria, symptoms, and treatments and did not include patients, doctors, hospitals, death, recovery, and events occurring in time.',
'Its interactions depended on a single patient being considered.',
'Since the experts consulted by the knowledge engineers knew about patients, doctors, death, recovery, etc., it is clear that the knowledge engineers forced what the experts told them into a predetermined framework.',
'In the present state of AI, this has to be true.',
'The usefulness of current expert systems depends on their users having common sense.']
#分词
words = word_tokenize(corpus)
words[:20]
结果:
['A', '``', 'knowledge', 'engineer', "''", 'interviews', 'experts', 'in', 'a', 'certain',
'domain', 'and', 'tries', 'to', 'embody', 'their', 'knowledge', 'in', 'a', 'computer']
- 1.2 停用词(stop_words)
在自然语言处理的很多任务中,我们处理的主体“文本”中有一些功能词经常出现,然而对于最后的任务目标并没有帮助,甚至会对统计方法带来一些干扰,我们把这类词叫做停用词,通常我们会用一个停用词表把它们过滤出来。比如英语当中的定冠词/不定冠词(a,an,the等)。
步骤2.停用词
为了剔除干扰的词
#导入内置停用词
from nltk.corpus import stopwords
stop_words = stopwords.words('english')
#看头10个
stop_words[0:10]
结果:
['i', 'me', 'my', 'myself', 'we', 'our', 'ours', 'ourselves', 'you', "you're"]
#使用列表推导式去掉停用词
filtered_corpus = [w for w in words if w not in stop_words]
filtered_corpus[:20]
['A', '``', 'knowledge','engineer',"''", 'interviews','experts','certain','domain','tries',
'embody','knowledge', 'computer', 'program', 'carrying', 'task','.', 'How','well','works']
#查看停用词数量
print("我们总共剔除的停用词数量为:",len(words) - len(filtered_corpus))
我们总共剔除的停用词数量为: 72
-
1.3 词性标注(part-of-speech tagging)
抽取关键词或者做一些命名实体识别或者做句法分析都会以词性标注做一个先手。是指为分词结果中的每个单词标注一个正确的词性的程序,也即确定每个词是名词、动词、形容词或者其他词性的过程。
词性标注是很多NLP任务的预处理步骤,如句法分析,经过词性标注后的文本会带来很大的便利性,但也不是不可或缺的步骤。 词性标注的最简单做法是选取最高频词性,主流的做法可以分为基于规则和基于统计的方法,包括:- 基于最大熵的词性标注
- 基于统计最大概率输出词性
- 基于HMM的词性标注
步骤3.词性标注
(非必须)
#词性标注
from nltk import pos_tag
tags = pos_tag(filtered_corpus)
tags[:20]
#很多时候要加载语料库,提示你加载什么,添加就好,这边给个示例
# nltk.download('averaged_perceptron_tagger')
结果:
[('A', 'DT'),
('``', '``'),
('knowledge', 'NN'),
('engineer', 'NN'),
("''", "''"),
('interviews', 'NNS'),
('experts', 'NNS'),
('certain', 'JJ'),
('domain', 'NN'),
('tries', 'NNS'),
('embody', 'VBP'),
('knowledge', 'JJ'),
('computer', 'NN'),
('program', 'NN'),
('carrying', 'NN'),
('task', 'NN'),
('.', '.'),
('How', 'WRB'),
('well', 'RB'),
('works', 'VBZ')]
具体的词性标注编码和含义见如下对应表:
| POS Tag | Description | Example |
|---|---|---|
| CC | coordinating conjunction | and |
| CD | cardinal number | 1, third |
| DT | determiner | the |
| EX | existential there | there, is |
| FW | foreign word | d’hoevre |
| IN | preposition or subordinating conjunction | in, of, like |
| JJ | adjective | big |
| JJR | adjective, comparative | bigger |
| JJS | adjective, superlative | biggest |
| LS | list marker | 1) |
| MD | modal | could, will |
| NN | noun, singular or mass | door |
| NNS | noun plural | doors |
| NNP | proper noun, singular | John |
| NNPS | proper noun, plural | Vikings |
| PDT | predeterminer | both the boys |
| POS | possessive ending | friend‘s |
| PRP | personal pronoun | I, he, it |
| PRP$ | possessive pronoun | my, his |
| RB | adverb | however, usually, naturally, here, good |
| RBR | adverb, comparative | better |
| RBS | adverb, superlative | best |
| RP | particle | give up |
| TO | to | to go, to him |
| UH | interjection | uhhuhhuhh |
| VB | verb, base form | take |
| VBD | verb, past tense | took |
| VBG | verb, gerund or present participle | taking |
| VBN | verb, past participle | taken |
| VBP | verb, sing. present, non-3d | take |
| VBZ | verb, 3rd person sing. present | takes |
| WDT | wh-determiner | which |
| WP | wh-pronoun | who, what |
| WP$ | possessive wh-pronoun | whose |
| WRB | wh-abverb | where, when |
- 1.4 chunking(组块分析/浅层分析)
Chunking的理解最好联系上POS-Tagging。简单来说POS-Tagging返回了解析树的最底层,就是一个个单词。但是有时候你需要的是几个单词构成的名词短语,而非个个单词,在这种情况下,您可以使用 chunker获取您需要的信息,而不是浪费时间为句子生成完整的解析树。举个例子:与其要单个字,不如要一个词,例如,将“南非”之类的短语作为一个单独 的词,而不是分别拆成“南”和“非”去理解。
步骤4.chunking
# Example of a simple regular expression based NP chunker.
import nltk
sentence = "the little yellow dog barked at the cat"
#Define your grammar using regular expressions
grammar = ('''
NP: {<DT>?<JJ>*<NN>} # NP
''')
chunkParser = nltk.RegexpParser(grammar)
tagged = nltk.pos_tag(nltk.word_tokenize(sentence))
print(tagged)
结果:
[('the', 'DT'), ('little', 'JJ'), ('yellow', 'JJ'), ('dog', 'NN'), ('barked', 'VBD'), ('at', 'IN'), ('the', 'DT'), ('cat', 'NN')]
tree = chunkParser.parse(tagged)
for subtree in tree.subtrees():
print(subtree)
结果:
(S
(NP the/DT little/JJ yellow/JJ dog/NN)
barked/VBD
at/IN
(NP the/DT cat/NN))
(NP the/DT little/JJ yellow/JJ dog/NN)
(NP the/DT cat/NN)
tree.draw()
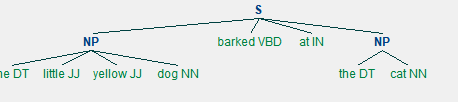
- 1.5 命名体识别
命名实体识别(Named Entity Recognition,简称NER),又称作“专名识别”,是指识别文本中具有特定意义的实体,主要包括人名、地名、机构名、专有名词等。通常包括两部分:1) 实体边界识别;2) 确定实体类别(人名、地名、机构名或其他)。
步骤5.命名体识别
from nltk import ne_chunk, pos_tag, word_tokenize
sentence = "John studies at Stanford University."
print(ne_chunk(pos_tag(word_tokenize(sentence))))
(S
(PERSON John/NNP)
studies/NNS
at/IN
(ORGANIZATION Stanford/NNP University/NNP)
./.)
- 1.6 stemming(词干提取)和lemmatizing(词性还原)
不同的时态和语态表达的含义是一样的,run,runing,仅仅是所在场景会有一些差别。如果要做情感分析的问题的话,对于时态和语态可能没有那么的关心。要对这些词做归一化。
很多时候我们需要对英文当中的时态语态等做归一化,这个时候我们就需要stemming和lemmatizing这样的操作了。比如"running"是进行时,但是这个词表征的含义和"run"是一致的,我们在识别语义的时候,希望能消除这种差异化。这样模型就能更容易总结出规律。lemmatizing更高级,运行会慢一点,考虑了词义关联的一种映射。而不像stemming,仅仅是一种规则。
步骤6.Stemming和Lemmatizing
# 可以用PorterStemmer
from nltk.stem import PorterStemmer
stemmer = PorterStemmer()
stemmer.stem("running")
'run'
# 也可以用
from nltk.stem import SnowballStemmer
stemmer2 = SnowballStemmer("english") #指定语种
stemmer2.stem("growing")
'grow'
# Lemmatization和Stemmer很类似,不同的地方在于它还考虑了词义关联等信息
# Stemmer的速度更快,但是它通常只是一系列的规则
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
lemmatizer.lemmatize("makes")
'make'
- 1.7 WordNet(词义解析)
很多词语义相关,比如“酒店”“宾馆”,“喜欢”“爱”,WordNet就是这样的一个百科全书,用它把所有词义相近的都替换成一个词。然后文章中全部出现“宾馆”或者都是“酒店”,这样模型看到很多次的”宾馆”或者“酒店”就能学得出它的含义或者更好的表示。也就是说如果一个意思,一会变一个样,可能就增加模型的学习难度了。
这里第六步和第七步一般在英文文本中做预处理,模型能对数据更好的训练,学习的更充分。
步骤7.WordNet
from nltk.corpus import wordnet as wn
wn.synsets('man')
结果:
[Synset('man.n.01'),
Synset('serviceman.n.01'),
Synset('man.n.03'),
Synset('homo.n.02'),
Synset('man.n.05'),
Synset('man.n.06'),
Synset('valet.n.01'),
Synset('man.n.08'),
Synset('man.n.09'),
Synset('man.n.10'),
Synset('world.n.08'),
Synset('man.v.01'),
Synset('man.v.02')]
# 第一种词义
wn.synsets('man')[0].definition()
'an adult person who is male (as opposed to a woman)'
# 第二种词义
wn.synsets('man')[1].definition()
‘someone who serves in the armed forces; a member of a military force’
wn.synsets('dog')
[Synset('dog.n.01'),
Synset('frump.n.01'),
Synset('dog.n.03'),
Synset('cad.n.01'),
Synset('frank.n.02'),
Synset('pawl.n.01'),
Synset('andiron.n.01'),
Synset('chase.v.01')]
# 查词义
wn.synsets('dog')[0].definition()
'a member of the genus Canis (probably descended from the common wolf) that has been domesticated by man since prehistoric times; occurs in many breeds'
# 造句
dog = wn.synset('dog.n.01')
dog.examples()[0]
'the dog barked all night'
# 上位词
dog.hypernyms()
[Synset('canine.n.02'), Synset('domestic_animal.n.01')]














 727
727











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









