







这一篇可能就是NLTK的最后一篇了,这里做个NLP的应用总结。
信息摘要提取
这个相信大家都不陌生,给定的文章,故事,新闻通常需要针对其内容自动生成摘要。需要重点说一下,这种应用一般需要一些深度学习的NLP而不是简单的解析句子的结构,往往是解析整个文本的结构和内容。信息摘要的一种理论逻辑是重要的句子中通常包含着重要的词汇,而跨语料库的差异词绝大多数都是重要的词汇。因此,只要句子中包含具有很大差异性的词汇,它就是重要的。
信息提取是从非结构化文本中提取有意义的信息过程。同时,IE也是一种被广泛使用且非常重要。通常情况下信息提取的引擎会利用海量的非结构化文档来生成某种结构化/半结构化的知识库,然后再围绕着该知识库来部署构建相关的应用。
机器翻译(Machine translation)
机器翻译指的是如何将一种语言翻译成另外一种语言,概括来说,是从原始文本为出发点,先对目标句子进行标识化处理,后者被解析成树状结构,以确保这些句子的正确表达。紧接着就是语义结构,它包含了这些句子所表达的含义;然后就是中间语言这个层面,该中间语言是一种独立于所有语言之外的抽象状态。目前有两种不同的翻译方式,一种是直接翻译,当拥有了大型语料库以及海量的目标语言词汇时,依赖于相关语言的大型语料库来实现某种类型的翻译应用是有可能的;另外一种就是语法翻译,这种翻译方法会试着去构建一个针对原始语言的解析器,这个解析器实际上已经拥有了一部分语义的能力。
信息检索(Information retrieval,简称IR)
这个最熟悉也是最出名的当属Google Search,它会根据用户的输入查询出相关的信息。一般的做法是构建一种反向索引机制,即由词汇找到其出现过的文档。这个还是比较成熟的技术,网上有许多相关的资料,大家可以搜索“布尔检索”“TF-IDF”等。
语音识别
这是个既古老又非常热门的应用。几乎在第一次世界大战时代以来一直是科学家们尝试解决的问题,目前伴随着人工智能和大数据的兴起,其仍然是计算机领域最热门的话题之一。语音识别的第一步就是把语音转为文本,这样语音识别的问题就转化为文本分析了。首先需要准备一个语音序列,我们称之为音素,因为语音分割本身就是一个很大的问题。只要语音处理好了,下一步就可以通过可用的训练数据来形成某种约束模型。
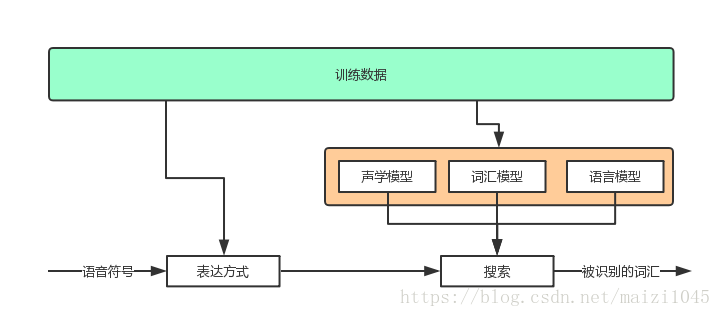
上图是一个系统的简单架构图,其中最复杂就是橙色框里的模型。声学模型解决了音素的建模,词汇模型所要解决的是基于小型句子分段来进行的。单独的语言模型都是基于单元词法和二元词法来进行的。
除了扯这些还有文本分类,问答系统,对话系统,词义消岐,主题建模,语言检测,光符识别(即书面文本识别,GoogleBook)等一些应用,这里暂时不介绍,因为书看到这里才发现买错书了,而且NLTK的功能都很旧了,思想也不符合主流的研究方向,所以下个阶段准备换个方向搞搞,还本书看看。














 444
444











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









