







最近研究了下数据库优化方案,对于分库分表有了些最基本的了解,写下这边文章,以此纪念
一、存储

1、垂直切分
首先将数据库DB中的数据根据业务的关系划分,或者说表之间的关系,垂直划分成3个数据库DB1、DB2、DB3。
比如我们可以将数据库中配置信息、区域划分等划分成一个库,将人员信息、人员持有的卡的信息划分成一个库,然后再将人员的刷卡记录划分成一个库。
2、水平切分
当垂直划分后,对于数据增长缓慢的,可由单一数据库承载,则不需要划分。例如配置信息、区域信息,一旦添加好后,数据量基本不再增加,此时单一数据库就可以承载。
而数据量巨大,且增速迅猛的,则需要进行水平分割,水平分割后可再视数据量的大小,以及预测接下来数据量的增速而将其与其他表水平切分后的数据存入一个数据库,或者单独存入一个数据库。
3、水平切分的实现
(1)、Range分区:通过字段的范围进行分区,该方法适合于按时间周期进行存储的数据,但该方法分区后的数据存储不均匀。
(2)、Hash分区:该方法基于分区字段的Hash值,它可将数据均匀的分布到预先定义的分区中,但对数据的管理比较弱。
附:我们可以规定每张表中存储数据的上限,比如定义一张表中的记录上限为300万条(此处的300万条只是我的猜测,可以找一个最有的记录上限),一旦一张表中的记录达到该上限,那就重新新建一张与该表结构相同但表名略有不同的新表,如原先表为history_201303_1,而新表即为history_201303_2;这样在后面读取数据的时候可以提高读取的效率。
4、垂直、水平切分后表信息的记录
在将数据库进行垂直、水平切分后,原先的数据将被存放于不同的数据库及表中,为了方便数据的读取,我们需要记录下原数据被切分后的数据库地址、数据库名称及表名,该信息可存放在xml文件中。
Xml的格式为:<record>
<row>
<col>原表名</col>
<col>切分后数据库地址</col>
<col>切分后数据库名称</col>
<col>切分后表名</col>
</row>
<row>
<col>原表名</col>
<col>切分后数据库地址</col>
<col>切分后数据库名称</col>
<col>切分后表名</col>
</row>
………
</record>
原表明:进行数据库优化前,该表的名称
切分后数据库地址:数据库优化后,新生成的表所在的数据库地址
切分后数据库名称:数据库优化后,新生成的表所在的数据库名称
切分后表名:数据库优化后,新生成的表的名称5、存储过程的使用
在进行数据迁移的过程中,其实是在对同一个sql语句的不停执行,此时使用存储过程能明显提高数据迁移的效率。
二、读取
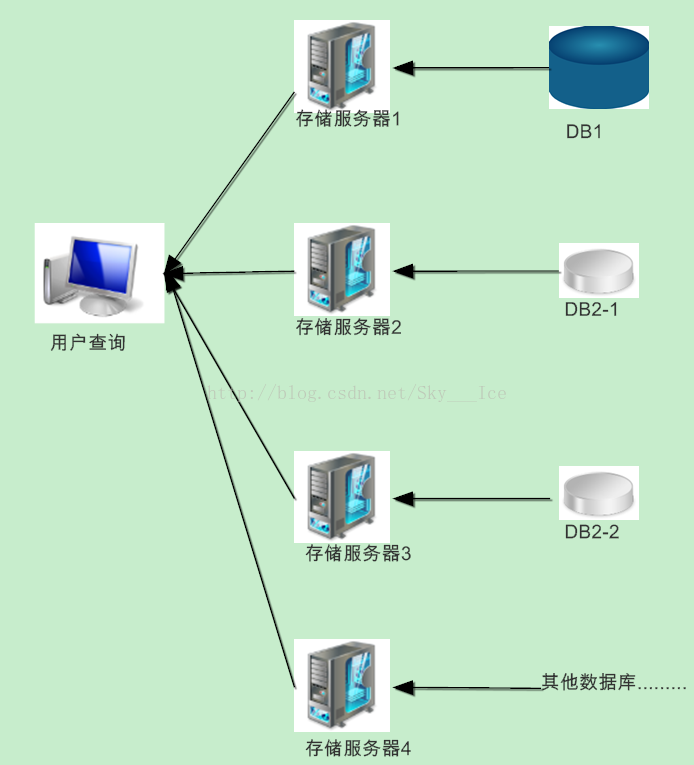
1、根据参数读取数据
根据传入的参数来构造所查找的数据库以及表名。
(1)、在同一个数据库中分表的查询
此时可以根据原先分表时记录的xml文档获得数据库地址、名称、表名来查询,如果该记录被分在多张表中,我们还可以使用线程来实现多张表查询,最后将查询结果汇总到一个数据集中生成报表。
(2)、在不同数据库中的分表查询
该实现方法与同一个数据库中分表查询类似,只是在读取xml文档时将读取多个数据库地址、名称、表明,然后也使用线程来对多个库中多张表同时查询,最后将查询结果汇总到一个数据集汇总生成报表。
2、SQL语句的优化
(1)、多表级联查询时使用别名,这样查询数据比建立连接表快1.5倍
(2)、避免where字句中对字段进行null值判断,否则将导致引擎放弃使用索引而进行全表扫描,可在null上设置默认值0或者””(空)。
(3)、尽量避免!=、<>操作符,以及or来连接条件,同时in和not也要慎用,因为这些都将无法使用索引。
(4)、对于想校验某条记录是否存在,尽量不要使用count(*),因为这样效率非常低,可使用Exists代替。















 237
237

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









