






Mysql数据库优化
1. 优化概述
存储层:存储引擎、字段类型选择、范式设计
设计层:索引、缓存、分区(分表)
架构层:多个mysql服务器设置,读写分离(主从模式)
sql语句层:多个sql语句都可以达到目的的情况下,要选择性能高、速度快的sql语句
2. 存储引擎
什么是存储引擎:
我们使用的数据是通过一定的技术存储在数据当中的,数据库的数据是以文件形式组织的硬盘当中的。技术不只一种,并且每种技术有自己独特的性能和功能体现。
存储数据的技术和其功能的合并就称为“存储引擎”。
在mysql中经常使用的存储引擎:Myisam或Innodb等等。
借用网上的一张图片
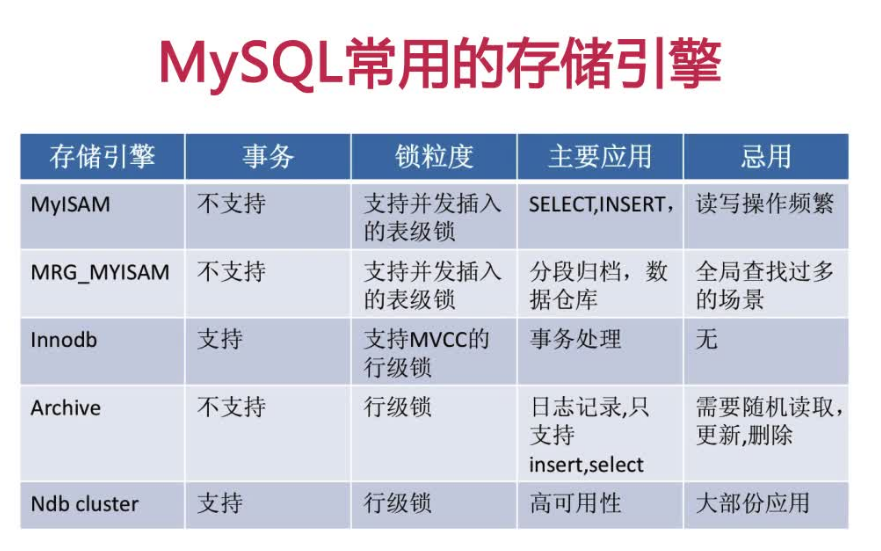
数据库的数据存储在不同的存储引擎里边,所有的特性就与当前的存储引擎有一定关联。
需要按照项目的需求、特点选择不同的存储引擎。
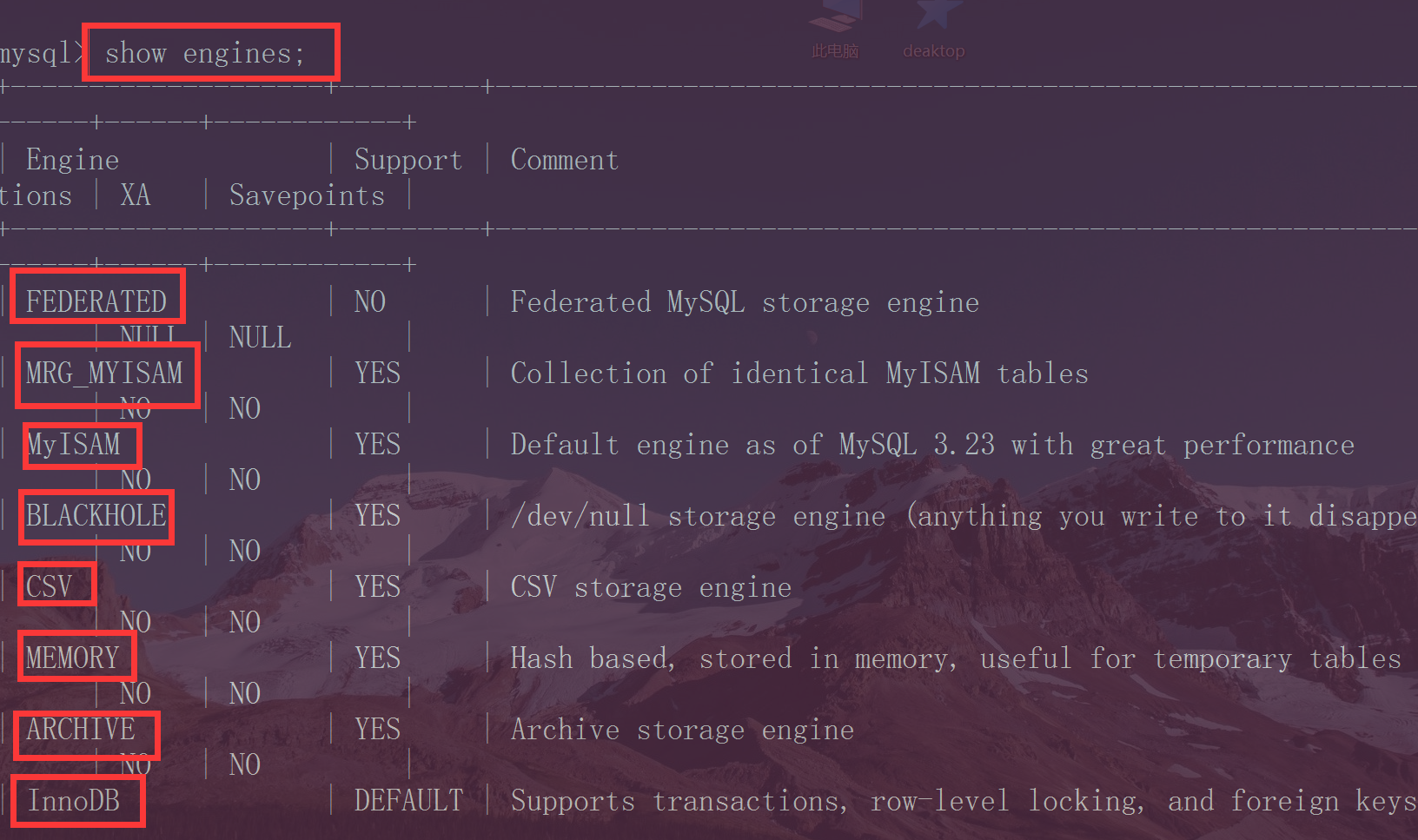
查看mysql中支持的全部存储引擎:
2.1 innodb
数据库每个数据表的数据设计三方面信息:表结构、数据、索引

技术特点:支持事务、行级锁定、外键
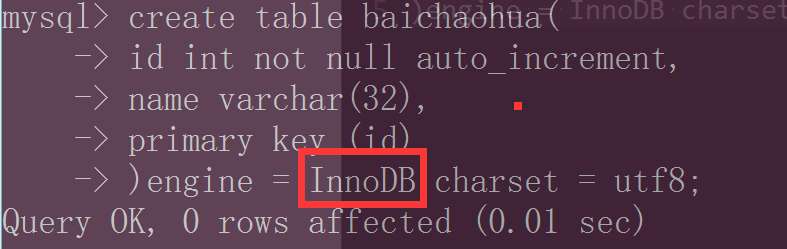
1)表结构、数据、索引的物理存储
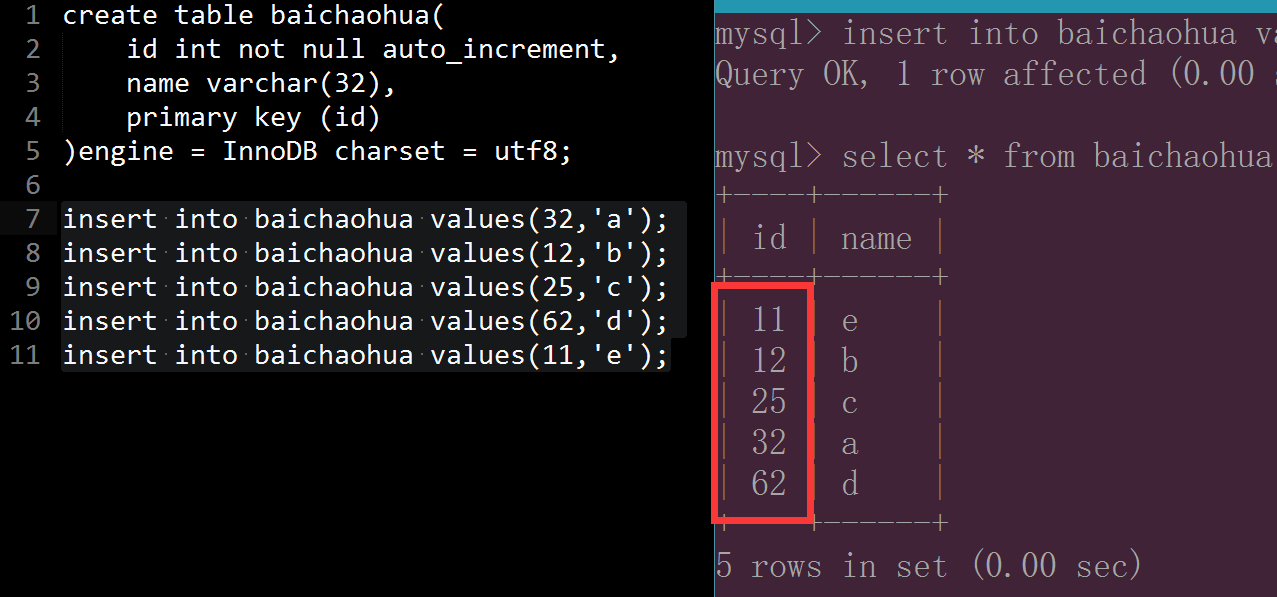
创建一个innodb数据表:
该类型 数据、索引 的物理文件位置:
所有innodb表的数据和索引信息都存储在以下ibdata1文件中

给innodb类型表 的数据和索引创建自己对应的存储空间:
默认情况下每个innodb表的 数据和索引 不会创建单独的文件存储
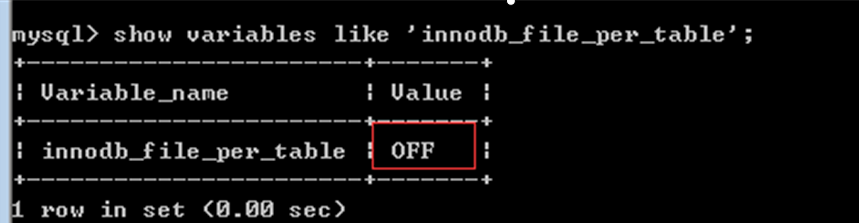
设置变量,使得每个innodb表有独特的数据和索引 存储文件:
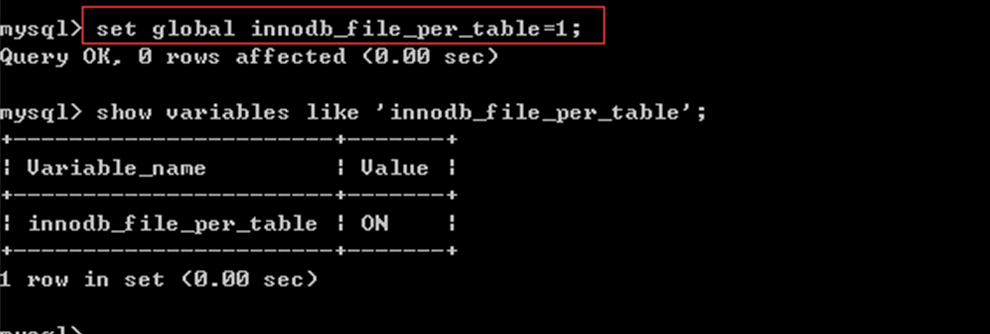
重新创建数据表的话数据表就对应有单独的数据和索引文件:
(后期无论innodb_file_per_table的设置状态如何变化,order2的数据和索引都有独立的存储位置)
2)数据存储顺序
innodb表数据的存储是按照主键的顺序排列每个写入的数据。
该特点决定了该类型表的写入操作较慢。
3)事务、外键
该类型数据表支持事务、外键
事务:把许多写入(增、改、删)的sql语句捆绑在一起,要么执行、要么不执行
事务经常用于与“钱”有关的方面。
四个特性:原子、一致、持久、隔离
具体操作:
start transaction;
许多写入sql语句
sql语句有问题
rollback;回滚
commit;提交
rollback和commit只能执行一个
外键:两个数据表A和B,B表的主键是A表的普通字段,在A表看这个普通的字段就是该表的“外键”,外键的使用有”约束”。
约束:以上两个表,必须先写B表的数据,再写A表的数据
并且 A表的外键取值必须来之B表的主键id值,不能超过其范围。
真实项目里边很少使用“外键”,因为有约束。
4) 并发性
该类型表的并发性非常高
多人同时操作该数据表
为了操作数据表的时候,数据内容不会随便发生变化,要对信息进行“锁定”
该类型锁定级别为:行锁。只锁定被操作的当前记录。
2.2 Myisam
1) 结构、数据、索引独立存储
该类型的数据表 表结构、数据、索引 都有独立的存储文件:
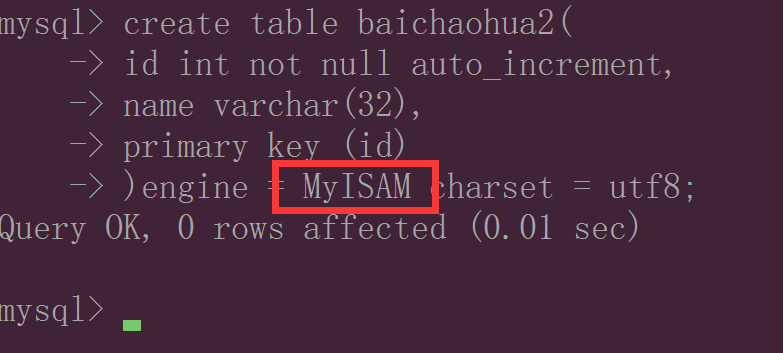
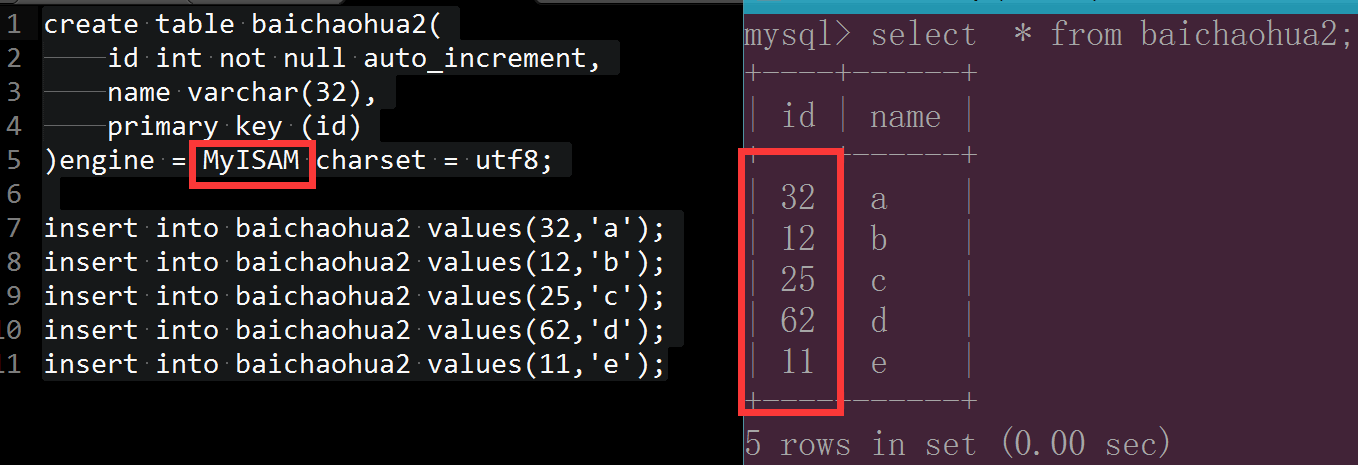
创建Myisam数据表
存在data文件夹中三个文件分别对应的是:、

*.frm:表结构文件
*.MYD:表数据文件
*.MYI:表索引文件
每个myisam数据表的 结构、数据、索引 都有独立的存储文件
特点:独立的存储文件可以单独备份、还原。
2) 数据存储顺序
myisam表数据的存储是按照自然顺序排列每个写入的数据。
该特点决定了该类型表的写入操作较快。
3) 并发性
该类型并发性较低
该类型的锁定级别为:表锁
4)压缩机制
如果一个数据表的数据非常多,为了节省存储空间,需要对该表进行压缩处理。
复制当前数据表的数据:
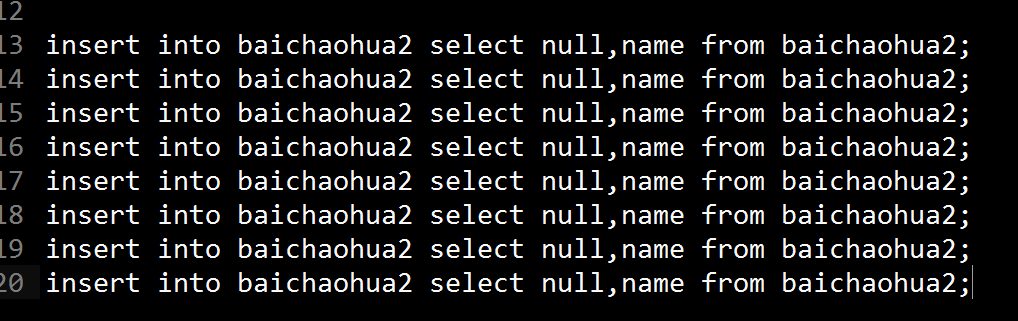
不断复制使得数据表的数据变为500多万条:
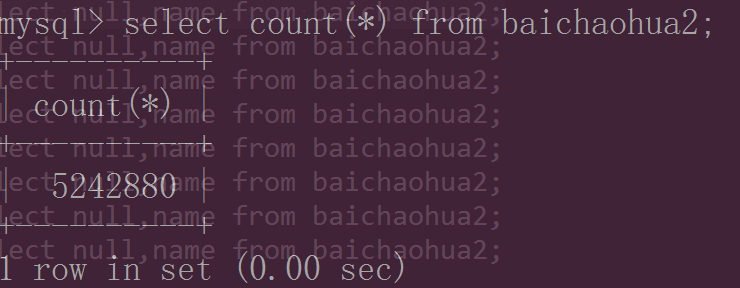
对应的存储500万条信息的文件的物理大小为将近100多兆:

开始压缩数据表的数据
压缩:myisampack.exe 表名
重建索引:myisamchk.exe -rq 表名
解压缩:myisamchk.exe --unpack 表名
表信息被压缩的75%的空间:
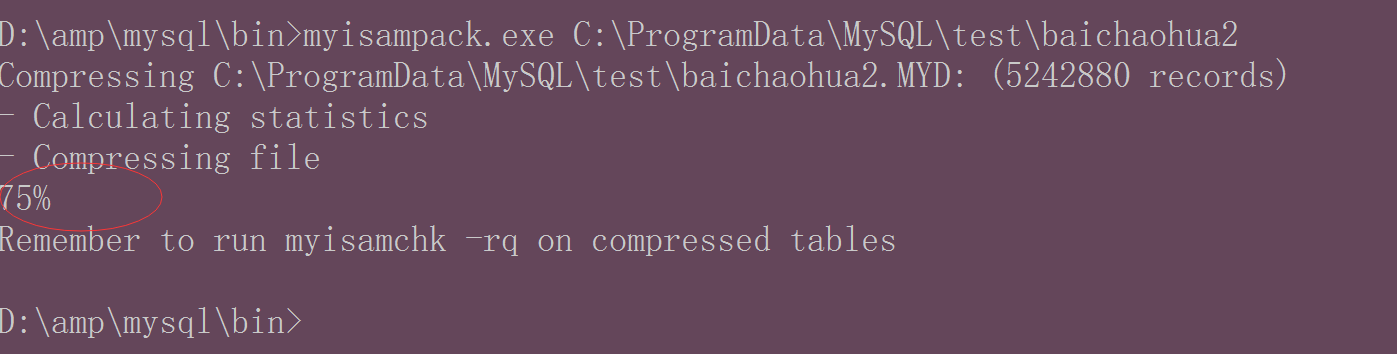
压缩后的大小为:
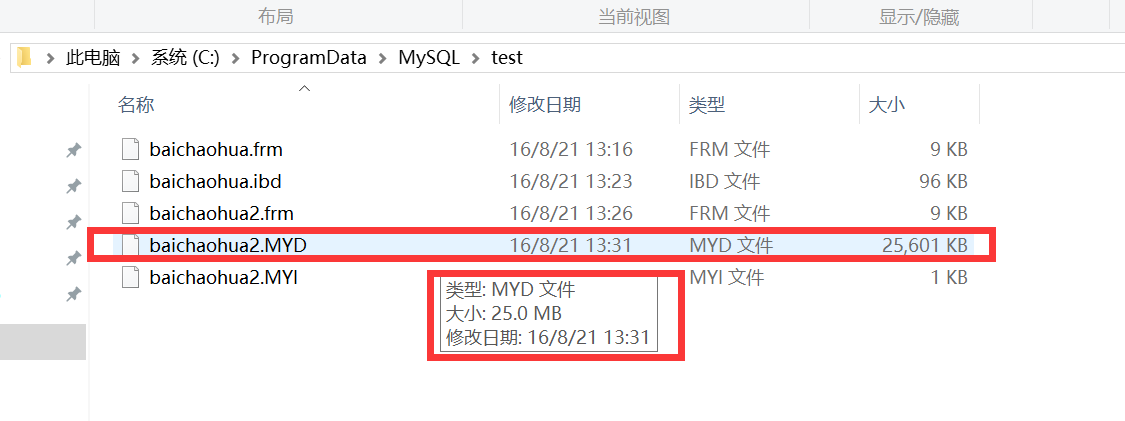
数据表有压缩,但是索引没有了,需要重建索引。
刷新数据表:flush table 表名
但是出现了这么一个情况:
压缩的数据表是只读表,不能写信息:(read only)
总结:压缩的数据表有特点:不能频繁的写入操作,只是内容固定的数据表可以做压缩,存储全国地区信息的数据表
如果必须要写数据:就解压该数据表,写入数据,再压缩
innodb存储引擎:适合做修改、删除
Myisam存储引擎:适合做查询、写入
3.3 Archive
归档型存储引擎,该引擎只有写入、查询操作,没有修改、删除操作
比较适合存储“日志”性质的信息。
3.4 memory
内存型存储引擎,操作速度非常快速,比较适合存储临时信息,
服务器断电,给存储引擎的数据立即丢失。
3. 存储引擎的选择
Myisam和innodb
网站大多数情况下“读和写”操作非常多,适合选择Myisam类型
例如 dedecms、phpcms内容管理系统(新闻网站)、discuz论坛
网站对业务逻辑有一定要求(办公网站、商城)适合选择innodb
Mysql5.5默认存储引擎都是innodb的
4. 字段类型选择
4.1 尽量少的占据存储空间
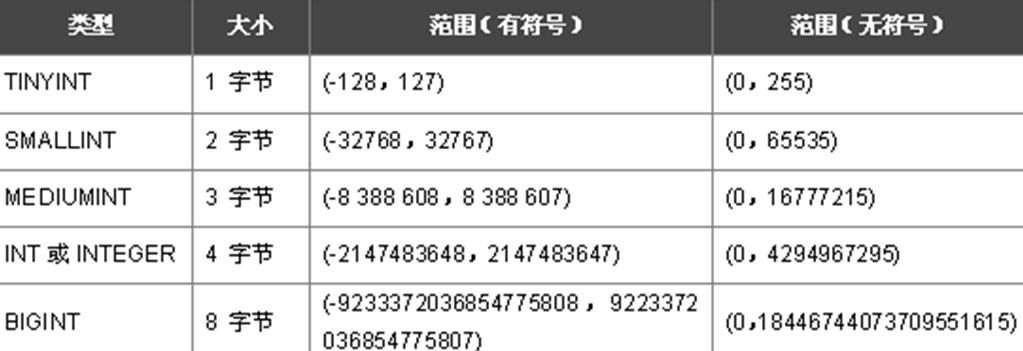
int整型
年龄:tinyint(1) 0-255之间
乌龟年龄: smallint(2)
mediumint(3)
int(4)
bigint(8)
时间类型date
time()时分秒
datetime()年月日 时分秒
year()年份
date()年月日
timestamp()时间戳(1970-1-1到现在经历的秒数)
根据不同时间信息的范围选取不同类型的使用
4.2 数据的整合最好固定长度
char(长度)
固定长度,运行速度快
长度:255字符限制
varchar(长度)
长度不固定,内容比较少要进行部位操作,该类型要保留1-2个字节保存当前数据的长度
长度:65535字节限制
存储汉字,例如字符集utf8的(每个汉字占据3个字节),最多可以存储65535/3-2字节
存储手机号码:char(11)
4.3 信息最好存储为整型的
时间信息可以存储为整型的(时间戳)
select from_unixstamp(时间戳) from 表名
set集合类型 多选:set(‘篮球’,’足球’,’棒球’,’乒乓球’);
enum枚举类型 单选: enum(‘男’,’女’,’保密’);
推荐使用set和enum类型,内部会通过整型信息参数具体计算、运行。
ip地址也可以变为整型信息进行存储(mysql内部有算法,把ip变为数字):
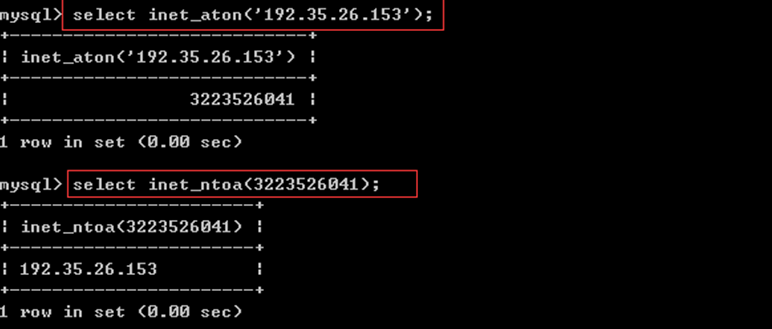
mysql: inet_aton(ip) inet_ntoa(数字)
php: ip2long(ip) long2ip(数字)
总结2:
1.存储引擎
数据存储技术格式
Myisam
innodb
2.字段类型选择
原则:占据空间小、数据长度最好固定、数据内容最好为整型的
5. 逆范式
数据库设计需要遵守三范式。
两个数据表:商品表Goods、分类表Category
Goods: id namecat_id price
101 iphone6s 2003 6000
204 海尔冰箱 4502 2000
......
Category: cat_id name goods_num
2003 手机
4502 冰箱
.....
需求:
计算每个分类下商品的数量是多少?
select c.cat_id,c.name,count(c.*) from category as c left join goods as g on g.cat_id=c.cat_id;
上边sql语句是一个多表查询,并且还有count的聚合计算。
如果这样的需求很多,类似的sql语句查询速度没有优势,
如果需要查询速度提升,最好设置为单表查询,并且没有聚合计算。
解决方法是:给Category表增加一个商品数量的字段goods_num
那么优化后的sql语句:
select cat_id,name,goods_num from category;
但是需要维护额外的工作:goods商品表增加、减少数据都需要维护goods_num字段的信息。
以上对经常使用的需求做优化,增加一个goods_num字段,该字段的数据其实通过goods表做聚合计算也可以获得,该设计不满足三范式,因此成为”逆范式”.
三范式:
① 一范式:原子性,数据不可以再分割
② 二范式:数据没有冗余
order goods
ida 编号1下单时间商品信息1商品价格商品描述商品产地
idb 编号1下单时间商品信息2商品价格 商品描述 商品产地
idb 编号1下单时间商品信息3商品价格 商品描述 商品产地
订单表 id 编号1 下单时间 g1,g2,g3
③ 三范式
数据表每个字段与当前表的主键产生直接关联(非间接关联)
userid name height weight orderid 编号 订单时间
优化:
userid name height weight
userid orderid
orderid 编号 订单时间
6. 索引index
索引是优化数据库设计,提升数据库性能非常显著的技术之一。
各个字段都可以设计为索引,经常使用的索引为主键索引primary key
索引可以明显提升查询sql语句的速度
6.1 是否使用索引速度的差别
对一个没有索引的数据表进行数据查询操作:
没有索引,查询一条记录消耗1.49s的时间:
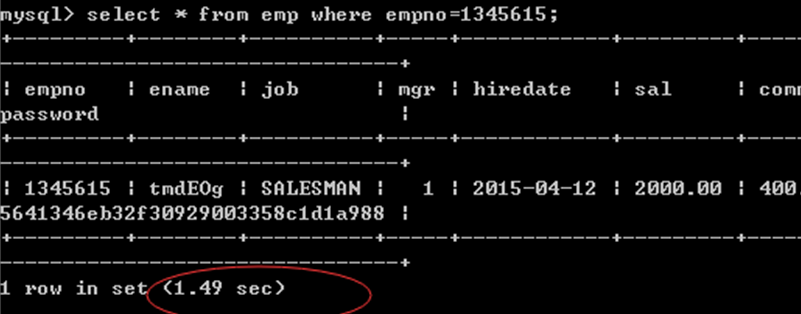
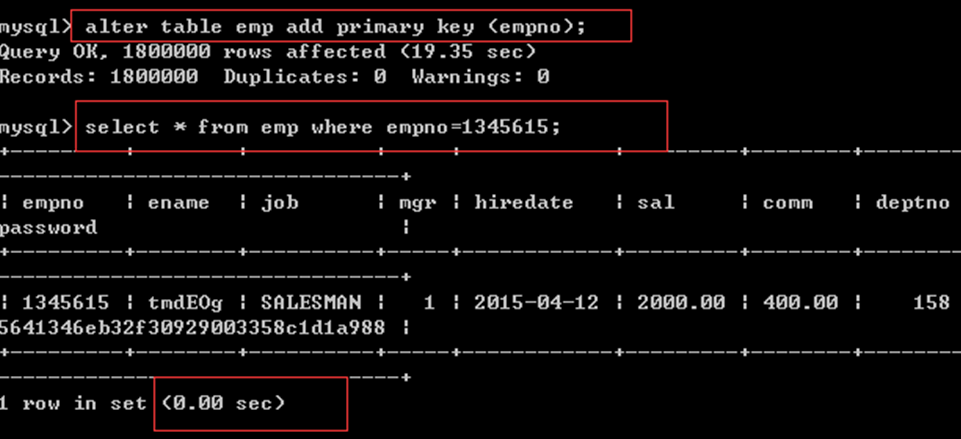
一旦设置索引,再做数据查询,时间提升是百倍至千倍级的:
6.2 什么是索引
索引本身是一个独立的存储单位,在该单位里边有记录着数据表某个字段和字段对应的物理空间。
索引内部有算法支持,例如二分查找,可以使得查询速度非常快。
有了索引,我们根据索引为条件进行数据查询速度就非常快
① 索引本身有”算法”支持,可以快速定位我们要找到的关键字(字段)
② 索引字段与物理地址有直接对应,帮助我们快速定位要找到的信息
一个数据表的全部字段都可以设置索引
6.3 索引类型
四种类型:
① 主键 primary key
auto_increment必须给主键索引设置
信息内容要求不能为null,唯一
② 唯一 unique index
信息内容不能重复
③ 普通 index
没有具体要求
④ 全文 fulltext index
myisam数据表可以设置该索引
复合索引:索引关联的字段是多个组成的,该索引就是复合索引。
1) 创建索引
创建: 创建表时;创建数据表后添加并设置各种索引:
2)删除索引
alter table 表名 drop primary key; //删除主键索引
注意:该主键字段如果存在auto_increment属性,需要先删除之
alter table 表名 modify 主键 int not null comment‘主键’;
去除数据表主键字段的auto_increment属性:
禁止删除主键,原因是内部有auto_increment属性:
alter table 表名 drop index 索引名称; //删除其他索引(唯一、普通、全文)
6.4 执行计划explain
针对查询语句设置执行计划,当前数据库只有查询语句支持执行计划。
每个select查询sql语句执行之前,需要把该语句需要用到的各方面资源都计划好
例如:cpu资源、内存资源、索引支持、涉及到的数据量等资源
查询sql语句真实执行之前所有的资源计划就是执行计划。
我们讨论的执行计划,就是看看一个查询sql语句是否可以使用上索引。
具体操作:
explain 查询sql语句\G;
一条sql语句在没有执行之前,可以看一下执行计划。
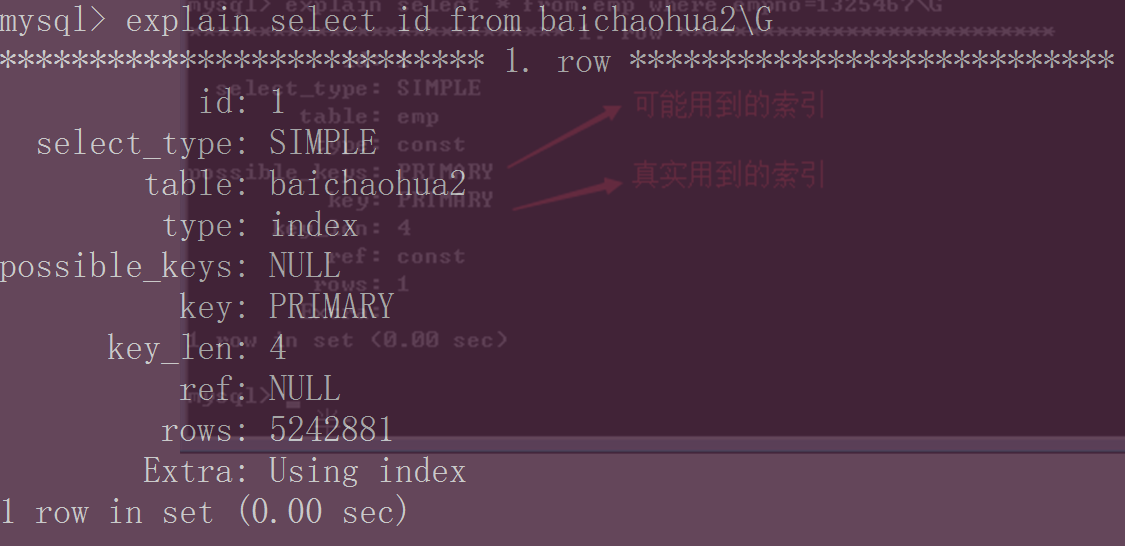
主键索引删除后,该查询语句的执行计划就没有使用索引(执行速度、效率低)
6.5 索引适合场景
1) where查询条件
where 之后设置的查询条件字段都适合做索引。
2) 排序查询
order by 字段 //排序字段适合做索引
where 和 order by后边的条件字段都可以适当设置索引
3) 索引覆盖
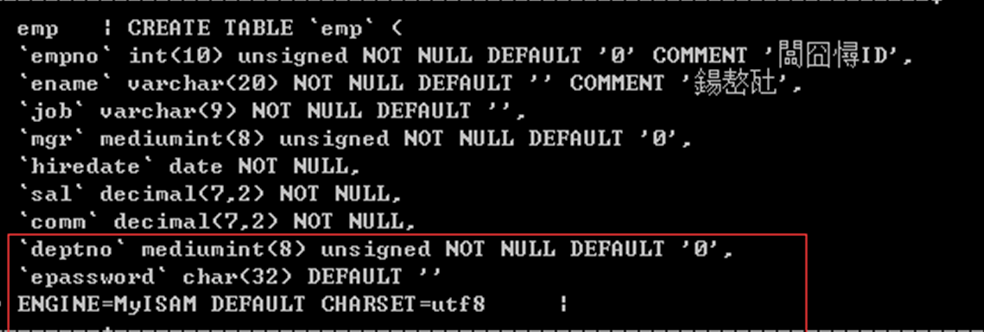
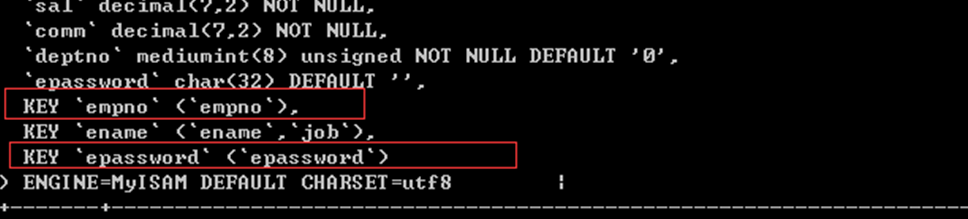
给ename和job设置一个复合索引:

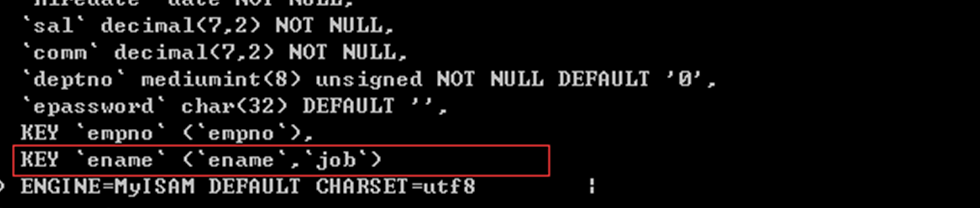
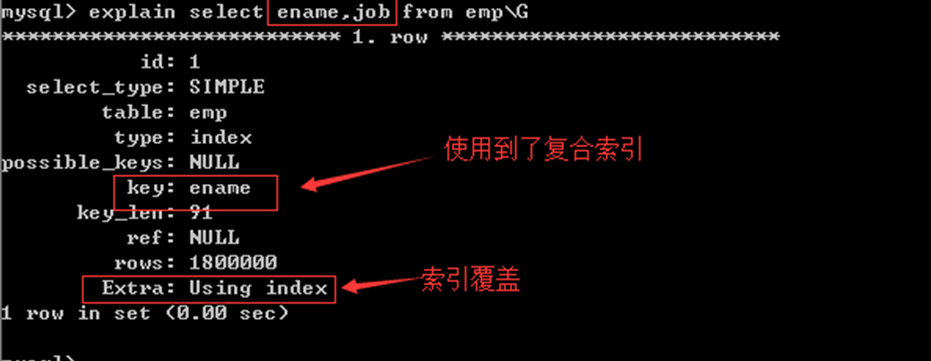
索引覆盖:我们查询的全部字段(ename,job)已经在索引里边存在,就直接获取即可
不用到数据表中再获取了。因此成为”索引覆盖”
该查询速度非常快,效率高,该索引也称为”黄金索引”
索引本身需要消耗资源的(空间资源、升级维护困难):
4) 连接查询
join join on
goods : id namecat_id...
category: cat_id name ...
在Goods数据表中给外键/约束字段cat_id设置索引,可以提高联表查询的速度
6.6 索引原则
1)字段独立原则
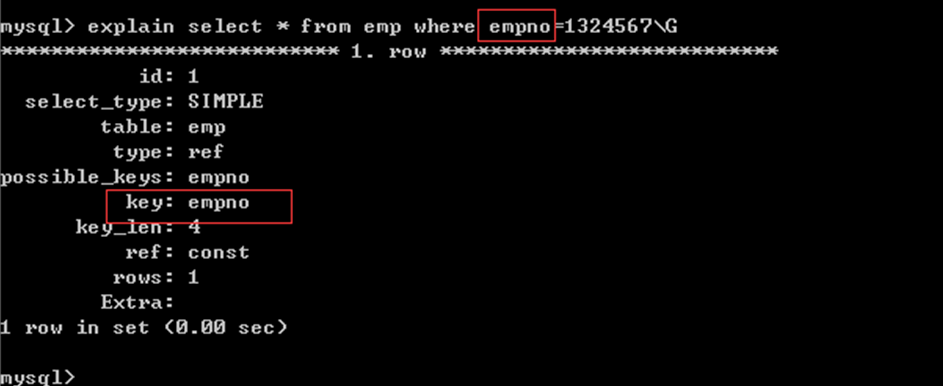
select * from emp where empno=1325467; //empno条件字段独立
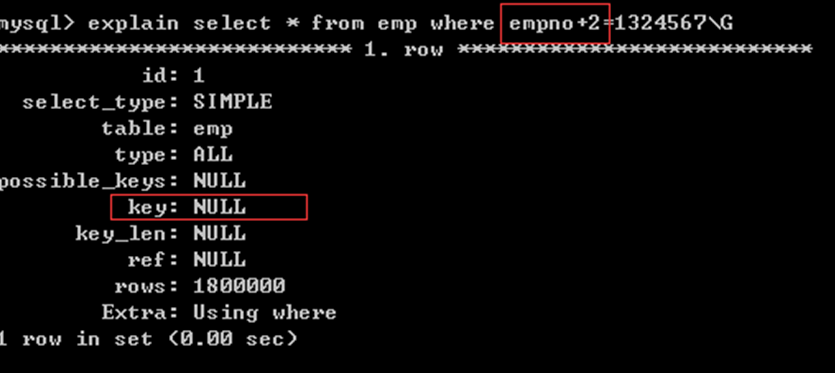
select * from emp where empno+2=1325467; //empno条件字段不独立
只有独立的条件字段才可以使用索引
独立的条件字段可以使用索引:
不独立的条件字段不给使用索引:
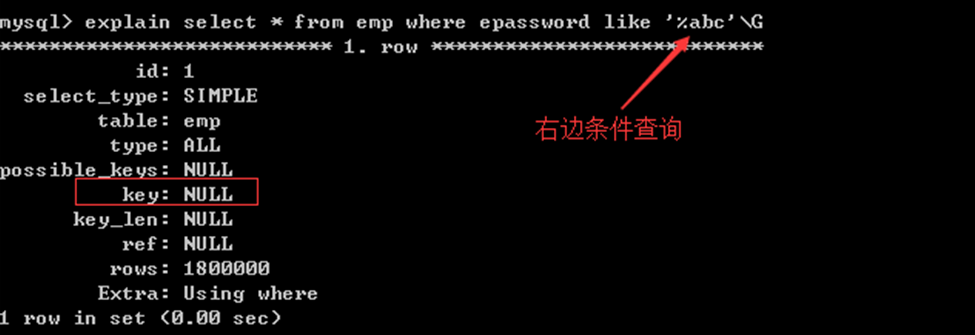
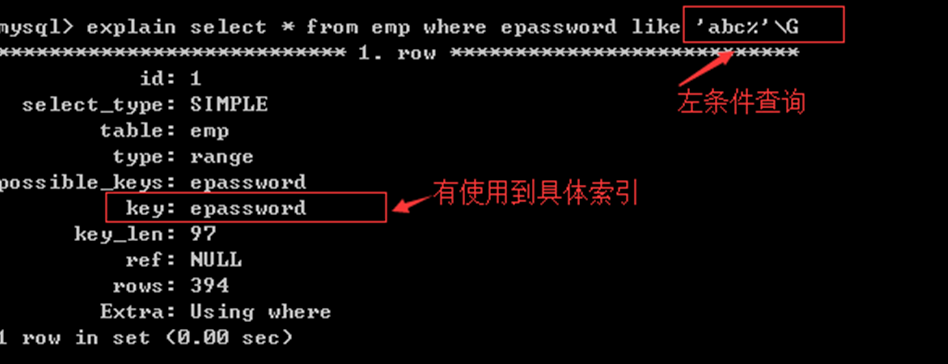
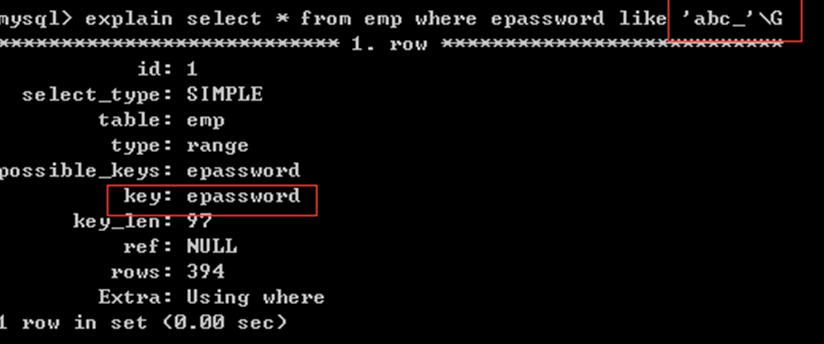
2) 左原则
模糊查询,like % _
%:关联多个模糊内容
_: 关联一个模糊内容
select * from 表名 like“beijing%”; //使用索引
select * from 表名 like“beijing_”; //索引索引
查询条件信息在左边出现,就给使用索引
XXX% YYY_ 使用索引
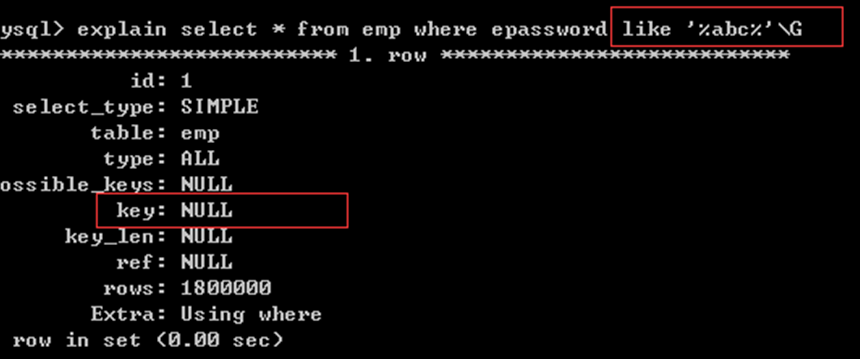
%AAA% _ABC_ %UUU 不使用索引
没有使用索引(中间条件查询):
3) 复合索引
ename复合索引 内部有两个字段(ename,job)
① ename(前者字段)作为查询条件可以使用复合索引
② job(后者字段)作为查询条件不能使用复合索引
复合索引的第一个字段可以使用索引:
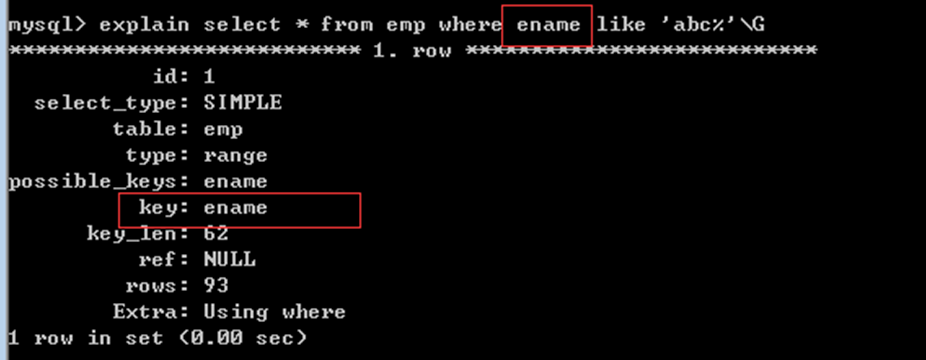
复合索引的其余字段不能使用索引:
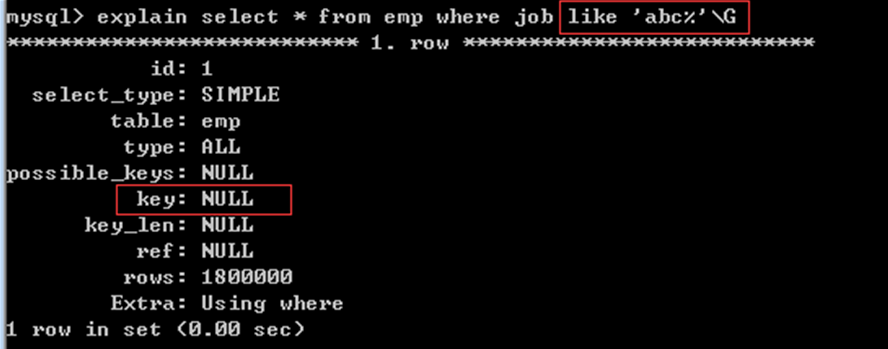
如果第一个字段的内容已经确定好,第二个字段也可以使用索引:
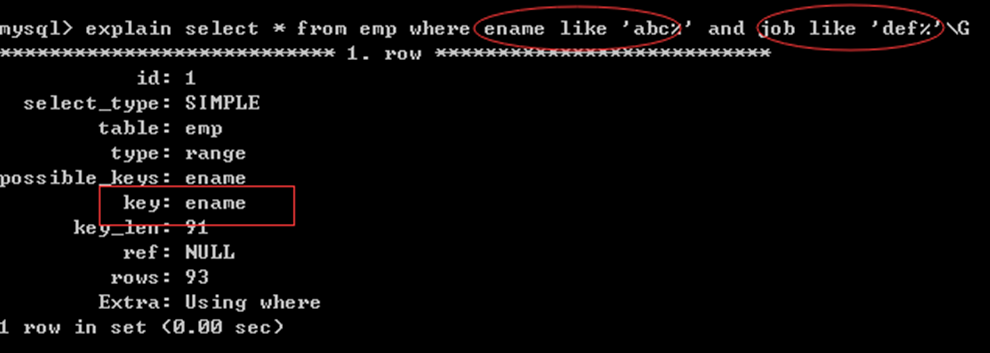
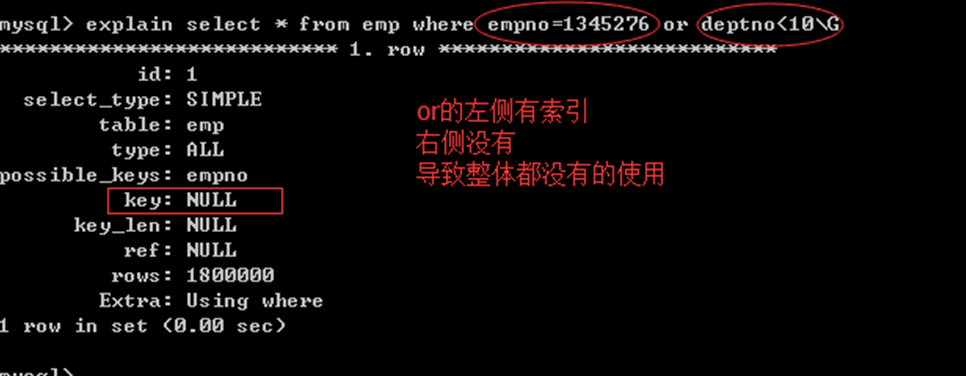
4) OR原则
OR左右的关联条件必须都具备索引 才可以使用索引:
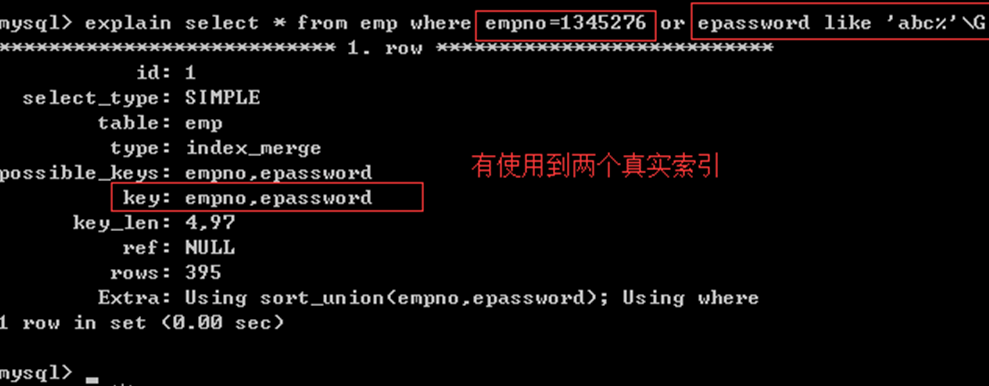
or的左右,只有一个有索引,导致整体都没有的使用:
总结3:
1.逆范式
2.索引
索引是数据表的某个字段作为关键字,该关键字与信息的物理地址进行对应
通过索引查找信息,内部有算法,速度有保证,索引信息找到就找到记录的物理地址
进而获得该记录信息
索引类型:主键、唯一、普通、全文
创建:创建数据表时设置索引
给已有数据表设置索引
删除:alter table 表名 drop primary key;
//删除主键,需要先删除auto_incremenet
alter table 表名 drop index 索引名
3.exlain执行计划
针对 查询sql语句 可以设置执行计划
4.索引适合场景:where、order by、索引覆盖、连接查询(约束字段)
5.索引使用原则:左原则、字段独立、复合索引、or原则














 2681
2681











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









