






-
原理解释
-
在注意力机制中,注意力分数的计算是通过 Query 矩阵
和 Key 矩阵
的点积实现的,即
。假设
是
行(一个
维的向量),
是
行(同样是
中的元素
为:
-
如果
和
是均值为 0、方差为 1 的独立随机变量,那么根据方差的性质,
-
也就是说,
的值会变得很靠近0或1,容易出现梯度消失问题。
-
这里介绍为什么会出现梯度消失问题,记
为
,则
对
的导数如下:
-
由上式可知,如果
,使得
。
-
-
示例代码:
-
# 验证不除以根号d会导致注意力分数靠近0或1的现象 import torch import torch.nn as nn import matplotlib.pyplot as plt class Attention(nn.Module): def __init__(self, d_model): super().__init__() self.d_model = d_model def forward(self, Q, K, V, scale=False): attention_scores = torch.matmul(Q, K.transpose(-1, -2)) if scale: attention_scores = attention_scores / torch.sqrt( torch.tensor(self.d_model, dtype=torch.float32)) attention_weights = torch.softmax(attention_scores , dim=-1) output = torch.matmul(attention_weights, V) return output, attention_weights # 初始化参数 batch_size = 1 seq_len = 4 d_model = 512 # 随机生成Q、K、V张量 Q = torch.randn(batch_size, seq_len, d_model) K = torch.randn(batch_size, seq_len, d_model) V = torch.randn(batch_size, seq_len, d_model) # 创建注意力层 attention_layer = Attention(d_model) # 不进行缩放的情况 _, attention_weights_no_scale = attention_layer(Q, K, V , scale=False) # 进行缩放的情况 _, attention_weights_scale = attention_layer(Q, K, V, scale=True) # 打印并可视化注意力权重 print("不除以根号d的注意力权重:") print(attention_weights_no_scale) print("除以根号d的注意力权重:") print(attention_weights_scale)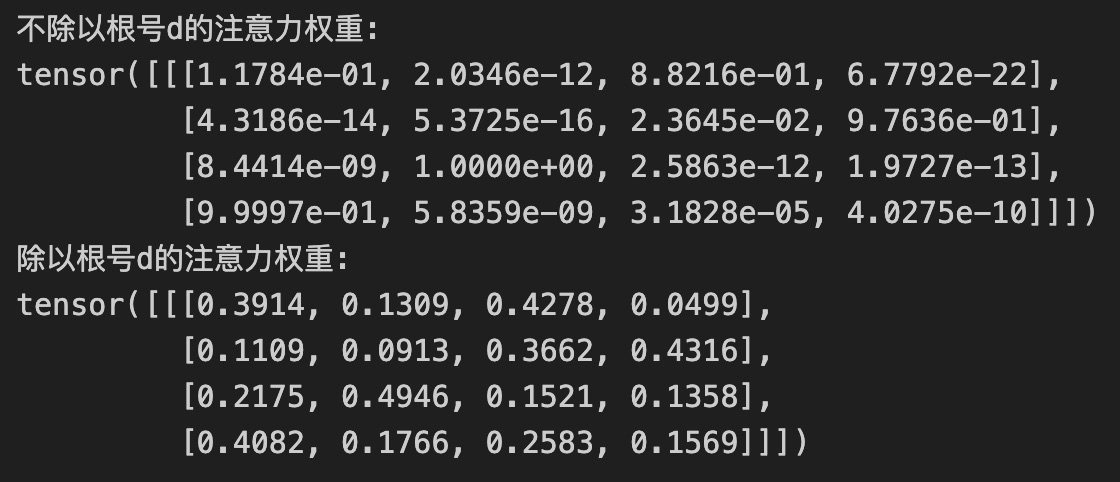
✅ 这道题的题解来自于《大厂搜广推算法高频考题》面试笔记。有需求的同学们可以点击链接,祝大家算法岗面试效率翻倍!
-


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









