






反压机制
Spark Streaming 1.5 以前的体系结构
在 Spark 1.5 版本之前,Spark Streaming 的体系结构如下所示:
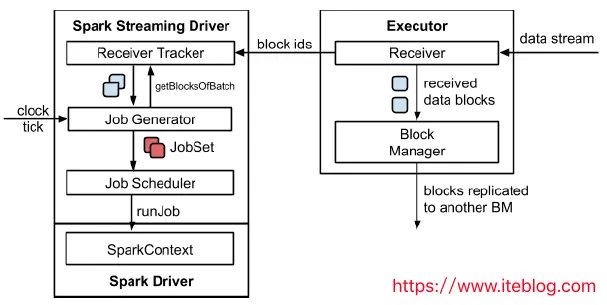
- 数据是源源不断的通过 receiver 接收,当数据被接收后,其将这些数据存储在 Block Manager 中;为了不丢失数据,其还将数据备份到其他的 Block Manager 中;
- Receiver Tracker 收到被存储的 Block IDs,然后其内部会维护一个时间到这些 block IDs 的关系;
- Job Generator 会每隔 batchInterval 的时间收到一个事件,其会生成一个 JobSet;
- Job Scheduler 运行上面生成的 JobSet。
Spark Streaming 1.5 之后的体系结构
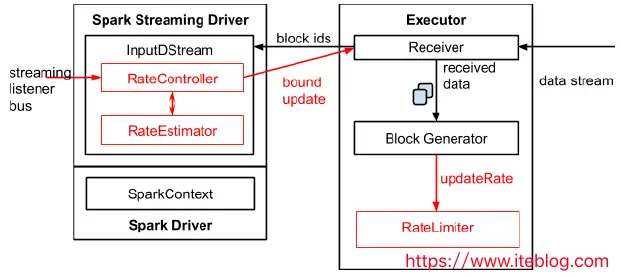
- 为了实现自动调节数据的传输速率,在原有的架构上新增了一个名为 RateController 的组件,这个组件继承自 StreamingListener,其监听所有作业的 onBatchCompleted 事件,并且基于 processingDelay 、schedulingDelay 、当前 Batch 处理的记录条数以及处理完成事件来估算出一个速率;这个速率主要用于更新流每秒能够处理的最大记录的条数。速率估算器(RateEstimator)可以又多种实现,不过目前的 Spark 2.2 只实现了基于 PID 的速率估算器。
- InputDStreams 内部的 RateController 里面会存下计算好的最大速率,这个速率会在处理完 onBatchCompleted 事件之后将计算好的速率推送到 ReceiverSupervisorImpl,这样接收器就知道下一步应该接收多少数据了。
-
如果用户配置了 spark.streaming.receiver.maxRate 或 spark.streaming.kafka.maxRatePerPartition,那么最后到底接收多少数据取决于三者的最小值。也就是说每个接收器或者每个 Kafka 分区每秒处理的数据不会超过 spark.streaming.receiver.maxRate 或 spark.streaming.kafka.maxRatePerPartition 的值。
详细的过程如下图所示:
















 8200
8200

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









