









前言:插入排序
概念:
希尔排序(Shell Sort)是插入排序的一种优化版本,由Donald Shell于1959年提出。希尔排序通过引入增量序列,将原始数据分成多个子序列进行插入排序,从而提高排序效率。希尔排序的时间复杂度依赖于增量序列的选择,但通常在O(
)到O(
)之间。
对于插入排序来说,在正常情况下是优于冒泡排序的,插入排数在面对逆序数组时才会有最差的时间利用率(默认插入排序排的是升序),为了优化插入排序的算法,第一部便是预排序(让数组接近有序),再者,插入排数,这中框架,便是插入排序的优化排序-----希尔排序
算法步骤:
希尔排序的基本思想
- 间隔序列:选择一个间隔序列,常见的间隔序列有希尔增量(n/2, n/4, ..., 1)或其他递减序列。
- 分组:根据间隔序列中的值,将数组分成多个子序列。
- 插入排序:对每个子序列进行插入排序。
- 减小间隔:逐渐减小间隔,直到间隔为1。
- 完成排序:当间隔为1时,整个数组已经接近有序,此时再次进行插入排序,完成排序。
我们来对一个例子进行单趟的简单理解:
给定gap=3:

分组:(只是在原数组看,并不是直接拿出来做成一组一组的)

分组后,对子数列进行插入排序:(也是在原数组进行插入排序,只是索引是根据分的组进行插入排序的)

原数组通过本次预排序后: 
经过预排序后,数组整体就变得比上一次更接近有序
其实我们的插入排序便是gap=1的排序结果
整体使用希尔增量序列:

希尔排序的通俗解释
想象一下,你有一副没有排序的扑克牌,你想要把它们按顺序排列好。如果一张一张地比较和移动,那会非常慢。希尔排序提供了一个更聪明的方法来加速这个过程。
-
分组:首先,你不是一张一张地比较,而是把牌分成几组,每组的牌数逐渐减少。比如,一开始你比较每5张牌,然后是每3张,接着是每2张,最后是每1张。
-
小范围内排序:在每组内,你进行简单的排序,就像你在玩单人纸牌游戏一样,把牌一张一张地放到合适的位置上。
-
逐渐缩小范围:随着牌组的大小逐渐减小,你比较和排序的范围也在缩小。这意味着你不需要每次都从头开始比较,只需要在更小的范围内进行。
-
最终排序:当你的牌组大小减小到1时,整个牌堆就几乎已经排好序了。这时候,你只需要再进行一次简单的排序,就像你在整理最后几张牌一样。
为什么希尔排序快?
-
跳跃比较:希尔排序通过“跳跃比较”,即不是每张牌都直接比较,而是跳过一些牌,这样可以更快地找到牌的正确位置。
-
局部有序:在每组内进行排序,使得牌堆逐渐变得局部有序,这样在下一轮排序时,需要比较和移动的牌数就更少了。
-
接近完成:当牌组大小减小到1时,整个牌堆已经接近完全有序,最后的排序就非常快。
时间复杂度分析:
希尔排序的时间复杂度取决于所选择的间隔序列。不同的间隔序列会导致不同的时间复杂度。以下是一些常见的情况:
-
原始希尔增量:如果使用原始的希尔增量序列(n/2, n/4, ..., 1),希尔排序的时间复杂度大约是O(
)到O(
-
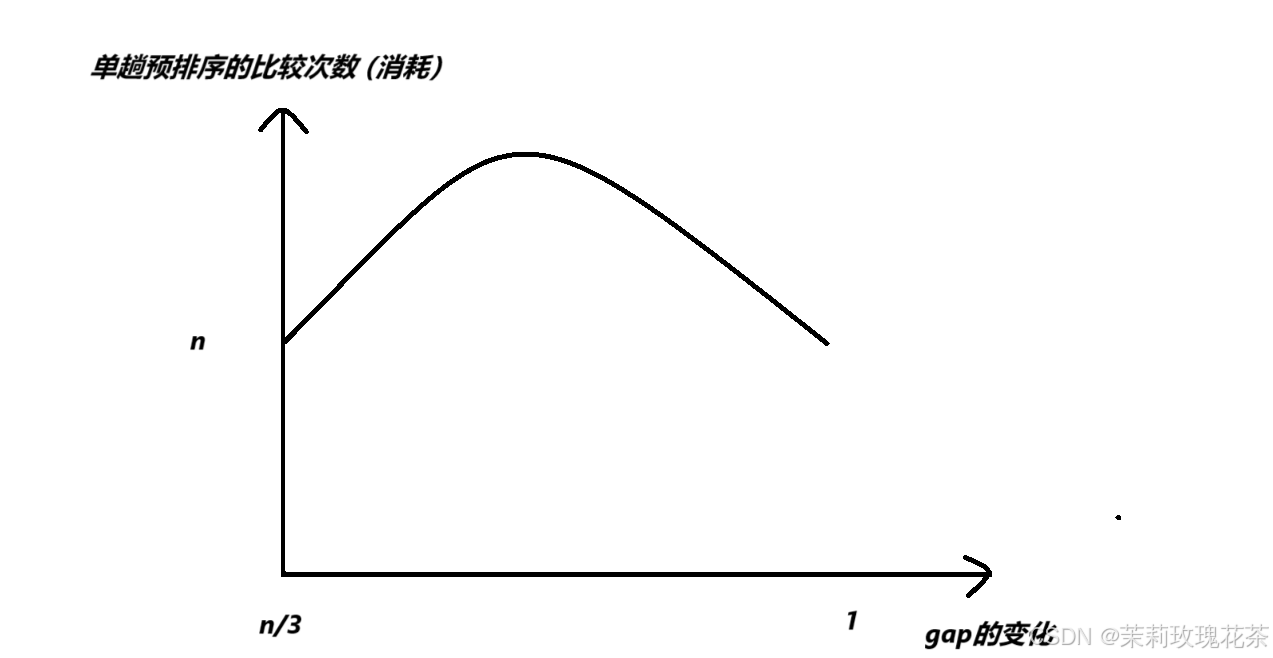
Sedgewick增量:如果使用Sedgewick提出的增量序列(大约是
,k为整数,直到增量大于n/3),希尔排序的时间复杂度可以降低到O(
-
Ciura增量:Ciura提出了一种特殊的增量序列,使得希尔排序的时间复杂度接近O(
-
常见的增量还有gap/3+1,时间复杂度大约为O(
)。
代码实现:
使用希尔增量序列的希尔排序的C++代码:
#include <iostream>
using namespace std;
// 希尔排序函数
void shellSort(int arr[], int n)
{
// 初始间隔,可以理解为一开始我们看5张牌
for (int gap = n / 2; gap > 0; gap /= 2)
{
// 从第gap个元素开始,对每组进行插入排序
for (int i = gap; i < n; i++)
{
// 当前要插入的牌
int temp = arr[i];
// 在arr[i]之前的元素中,找到temp应该插入的位置
int j;
// 与前面每gap个元素比较,如果前面的牌比temp大,就向后移动
for (j = i; j >= gap && arr[j - gap] > temp; j -= gap)
{
arr[j] = arr[j - gap];
}
// 将temp插入到正确的位置
arr[j] = temp;
}
}
}效果实现:
/ 打印数组的函数
void printArray(int arr[], int size) {
for (int i = 0; i < size; i++) {
cout << arr[i] << " ";
}
cout << endl;
}
// 主函数
int main() {
int arr[] = { 9, 1, 2, 5, 7, 4, 8, 6, 3, 5 };
int n = sizeof(arr) / sizeof(arr[0]);
cout << "Original array: ";
printArray(arr, n);
shellSort(arr, n);
cout << "Sorted array: ";
printArray(arr, n);
return 0;
}Original array: 9 1 2 5 7 4 8 6 3 5
Sorted array: 1 2 3 4 5 5 6 7 8 9
D:\2024C语言\data-structure\shell_Sort\x64\Debug\shell_Sort.exe (进程 2252)已退出,代码为 0 (0x0)。
按任意键关闭此窗口. . .这个代码示例展示了希尔排序的基本过程:
-
初始化间隔:我们从数组长度的一半开始,逐渐减小间隔,直到间隔为1。
-
插入排序:在每个间隔上,我们对数组进行插入排序,就像我们在整理每5张牌一样。
-
打印数组:在排序前后,我们打印数组,以便直观地看到排序的效果。
当你运行这段代码时,你会看到原始的无序数组被排序成有序数组。这个过程模拟了希尔排序如何通过分组和逐渐缩小范围来加速排序过程。
希尔排序就像是在玩一个有策略的纸牌游戏,通过分组和逐渐缩小比较范围,使得整个排序过程更加高效。虽然它可能不如一些更高级的排序算法(如快速排序或归并排序)那么快,但它的实现相对简单,而且在某些情况下,特别是数据已经部分有序时,它可以非常高效。

















 582
582

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









