







一、商品上新业务介绍
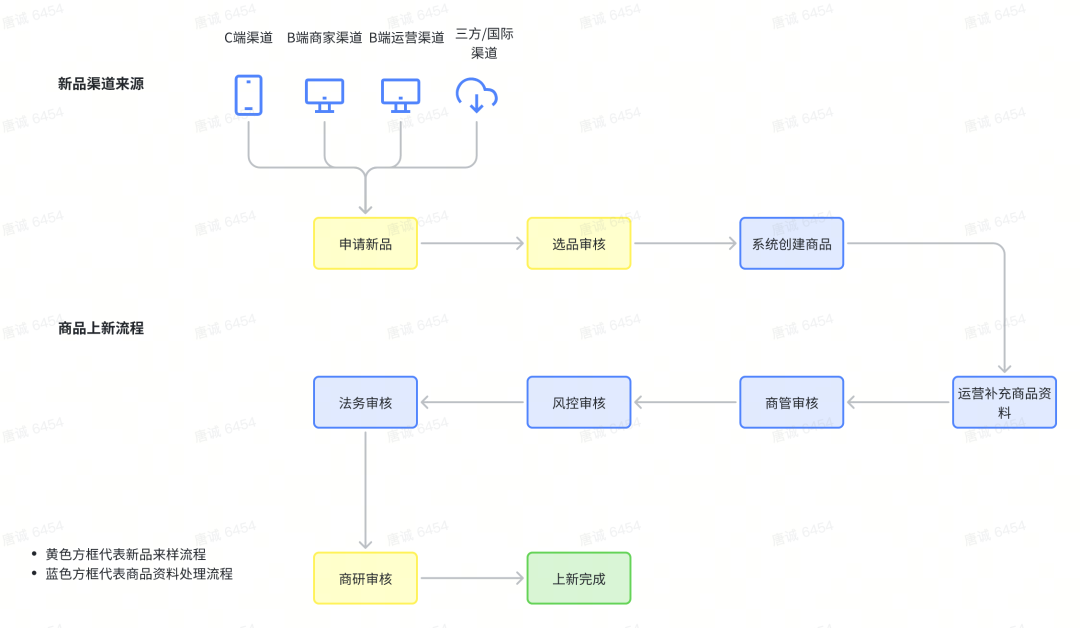
商品上新即为在得物平台上架一个新的商品,一个完整的商品上新流程从各种不同的来源渠道提交新品申请开始,需要历经多轮不同角色的审核,主要包括:
- 选品审核:根据新品申请提交的资料信息判定是否符合上架要求;
- 商品资料审核:对商品资料正确和完整性的审核,包含商管、风控、法务的多轮审核;
- 商研审核:商研审核是针对该商品在平台鉴别支持能力的判断,这也是得物业务的特色之处。
这几轮审核中,选品审核与商研审核特定归属为新品来样流程,仅在商品上新业务中出现,他决定了商品是否可在得物平台售卖;商品资料审核归属于商品资料处理流程,他决定了当前商品资料是否符合在C端展示的要求。
因此,在系统实现中,必然涉及新品来样流程和商品资料处理流程的状态流转,前者涉及新品来样表,后者主要为商品SPU主表,本文重点讨论新品来样流程的流转与状态机接入,新品来样流程的来源渠道属性非常明显,不同的渠道业务逻辑与流程都存在或大或小的区别。
二、为什么考虑接入状态机
- 状态枚举值个数较多,且相互间的流转条件不明确,了解业务流程必须仔细研究代码,上手和维护成本高。
- 状态的转移完全由代码随意指定,状态间随意流转存在风险。
- 部分状态流转不支持幂等,重复操作可能造成不符合预期的后果。
- 新增状态、修改状态流转成本高、风险大,代码修改范围不可控,测试需要全流程回归。
三、商品上新流程中涉及的状态
新品来样状态枚举
对应新品来样表的status字段,包含如下枚举值(为方便说明,进行了适度简化):
public enum NewProductShowEnum {
DRAFT(0, "草稿"),
CHECKING(1, "选品中"),
UNPUT_ON_SALE_UNPASS(2, "选品不通过"),
UNPUT_ON_SALE_PASSED(3, "商研审核中"),
UNPUT_ON_SALE_PASSED_UNSEND(4, "商品资料待审核"),
UNPUT_ON_SALE_PASSED_UNSEND_NOT_PUT(5, "鉴别不通过"),
UNPUT_ON_SALE_PASSED_SEND(6, "请寄样"),
SEND_PRODUCT(7, "商品已寄样"),
SEND_PASS(8, "寄样鉴别通过"),
SEND_REJECT(9, "寄样鉴别不通过"),
GONDOR_INVALID(10, "作废"),
FINSH_SPU(11, "新品资料审核通过"),
}
SPU状态枚举
对应商品SPU主表的status字段,包含如下枚举值(为方便说明,进行了适度简化):
public enum SpuStatusEnum {
OFF_SHELF(0, "下架"),
ON_SHELF(1, "上架"),
TO_APPROVE(2, "待审核"),
APPROVED(3, "审核通过"),
REJECT(4, "审核不通过"),
TO_RISK_APPROVE(8, "待风控审核"),
TO_LEGAL_APPROVE(9, "待法务审核"),
}
商品上新业务流程中涉及SPU的状态流转部分,以商品的状态流转为准,商品状态流转也进行了状态机接入(但不是本文讨论的内容),本文将主要讨论新品来样表status的状态流转。
四、新品来样所有事件
- 保存新品草稿
- 提交新品申请
- 选品通过
- 选品不通过
- 选品驳回后重新提交
- 发起商研审核
- 商研审核-支持鉴别
- 商研审核-不支持鉴别
- 商研审核-商品信息有误
- SPU审核驳回超过X天
- 发起寄样
- 寄样进度更新
共12个。
五、新品来样状态流转
上文提到,不同的商品来源渠道对应的上新流程有所差别,这意味着不同渠道的状态流转也是不同的,以下为B端卖家渠道示意:
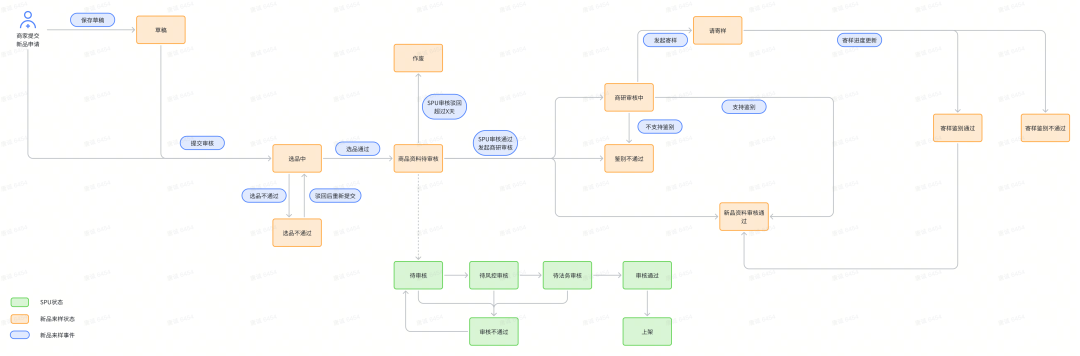
图中橙色方框代表新品来样状态,绿色方框代表SPU状态,蓝色圆角框代表触发状态变更的事件,有箭头连线的地方代表可以从当前状态流转到下一状态。
注意某些事件触发时,需要流转到的目标状态不是固定的,需要经过一系列的逻辑判断,才能决定最终要流转到的目标状态。
六、状态机技术选型
选择Spring StateMachine作为实际使用的状态机框架,具体过程和细节可参考这篇文章得物商品状态体系介绍,本文不再详述。
七、状态机接入面临的困难
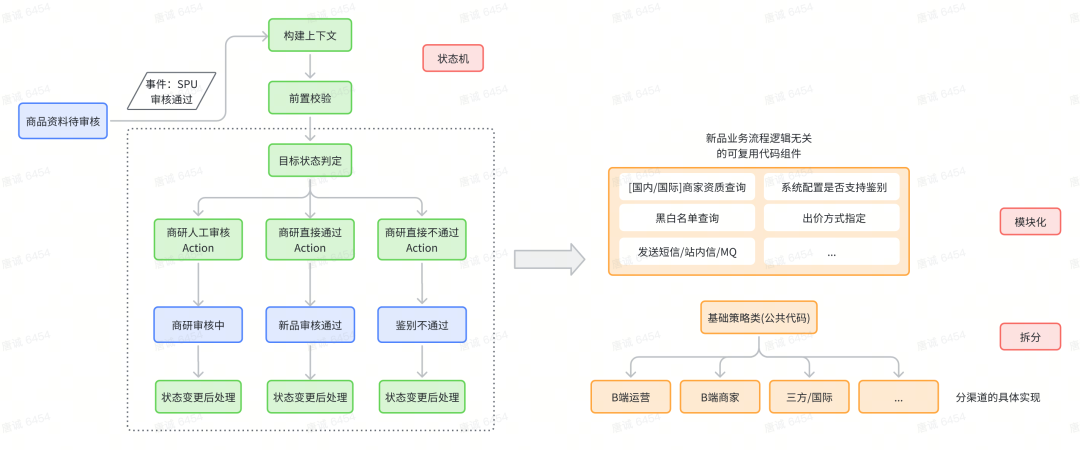
目前新品来样的代码中还面临着不同渠道之间代码耦合的问题,需要在本次接入中一起解决,否则状态机接入的成本会很高,质量也难以保证,后续维护更加困难。即使理想状态下经过了上述的状态机的改造,不进行其他改造,还会存在两方面的问题:
- 对目标状态判断逻辑的耦合;
- 实际执行动作的耦合。
可以简单理解为状态机的guard(判断是否满足执行前提条件)和action(实际执行的动作)的实现里有一个超大的接口,里面包含了所有渠道间不同的判断目标状态、执行不同的action的代码,想从中了解到某个渠道具体做了什么事阅读起来非常困难。
问题集中反映在新品来样的选品审核、商研审核接口的代码中(这部分也是新品来样业务逻辑最多最复杂的部分),它夹杂了所有渠道所有通过不通过的逻辑、选品和商研的逻辑,全部糅合在一起,代码冗长且可读性不好,同时还存在大事务的问题(事务中多次RPC调用),因此在状态机接入的同时需要将这些代码进行拆分和合并,具体包括:
- 不同渠道的代码使用策略模式拆分;
- 不同状态、不同的操作事件处理逻辑归纳到状态机不同状态&事件的guard和action类中;
- 对不同渠道中相同的代码处理逻辑封装成一个个的代码模块,在各自渠道中调用。
总体的改造方式如下图所示:
八、预期收益
从上文可以了解到,虽然是状态机接入,实际上是要完成两方面的改造,一是完成对整个上新流程中分渠道、分操作的业务代码的解耦,这部分的改造,能够:
- 解决之前新品申请链路中的大事务问题,如:提交报名、新品审核;
- 各商品来源渠道之间业务隔离,代码变更范围更加可控,更利于测试;
- 提高代码的可扩展性,降低代码理解门槛,提高日常需求的迭代开发效率。
二是状态机的接入,可以解决新品来样流程中的状态流转问题,包括:
- 统一集中管理状态变更规则,便于学习上手和后期维护;
- 避免不合法、重复的状态流转;
- 新增状态、状态流程之间的顺序调整变得更容易,代码修改更可控。
九、详细设计
按渠道拆分的合理性
从不同的商品来源渠道发起新品来样,是不同的角色通过不同的端来提交新品的过程,角色和端的组合是固定的,并不能随意组合,单独看角色或者端,并不具备共同的业务特征,只有特定的角色X端确定了才能确定一个完整的业务流程。
每个渠道的新品申请的能力也是不同的,比如商家对商品信息的掌握是最完整的,因此新品申请时就可以填写一个完整的商品资料,并且业务流程也比其他渠道多,相比而言App端仅能填写很少的商品信息,一旦申请被拒绝了就不能再修改提交了。因此不同渠道之间的差异是天然存在的,并且受制于渠道本身可能会一直存在下去。
因此在部分操作下按渠道拆分是有一定合理性和必要性的。
业务操作按渠道解耦
业务操作通用接口
新品来样中的很多重要节点的单条记录(批量操作也会转成单条处理)业务操作(比如提交新品申请、选品审核、商研审核)都可以抽象成“请求预处理 -> 操作校验 -> 执行业务逻辑 -> 持久化操作 -> 相关后处理动作”,因此设计一个通用的接口类来承载新品来样不同渠道不同业务操作的执行流程:
public interface NspOperate<C> {
/**
* 支持的商品来源渠道
* @return
*/
Integer supportApplyType();
/**
* 支持的操作类型
* @return
*/
String operateCode();
/**
* 请求预处理
* @param context
*/
void preProcessRequest(C context);
/**
* 校验
* @param context
*/
void verify(C context);
/**
* 执行业务逻辑
* @param context
*/
void process(C context);
/**
* 执行持久化
* @param context
*/
void persistent(C context);
/**
* 后处理
* @param context
*/
void post(C context);
}
一些说明:
- 后续状态机的每个事件都与该接口的操作类型一一对应。 此外,还可以定义其他操作类型,用于不涉及状态流转的场景(比如:编辑新品申请、根据新品申请创建SPU)。
- process方法的定义较为宽泛,在不同的业务操作中,实际执行的内容可能区别很大,比如提交新品审核可能只做一些数据组装的动作,而商研审核中则需要对本次操作后的目标状态进行判断。因此子类可以基于自己的业务需要,再进一步拆分定义新的待实现方法。
- persistent持久化方法单独定义出来,是为了支持只在该方法上加事务,目前系统的代码中其实也有类似的设计,但事务加的太宽泛,包括了校验、业务处理等整个执行流程,中间可能包含了各种RPC调用,这也是导致大事务的其中一个重要原因,因此这里明确该方法的实现只有读写DB操作,不包含任何业务逻辑。
- 每一个该接口的实现以“商品来源渠道+操作类型”形成唯一键进行Spring Bean的管理,同时为了兼顾有些操作是不区分商品来源的,故允许定义一个特殊的applyType(比如-1)代表当前实现支持所有渠道。在获取实现时,优化获取当前渠道的实现,找不到则尝试查找全渠道的实现:
public NspOperate getNspOperate(Integer applyType, String operateCode) {
String key = buildKey(applyType, operateCode);
NspOperate nspOperate = operateMap.get(key);
if (Objects.isNull(nspOperate)) {
String generalKey = buildKey(-1, operateCode);
nspOperate = operateMap.get(generalKey);
}
AssertUtils.throwIf(Objects.isNull(nspOperate), "NspOperate not found! key = " + key);
return nspOperate;
}
业务操作实现类
根据目前的业务场景,为了便于部分代码的重用,对业务操作的实现最多有3层继承关系:
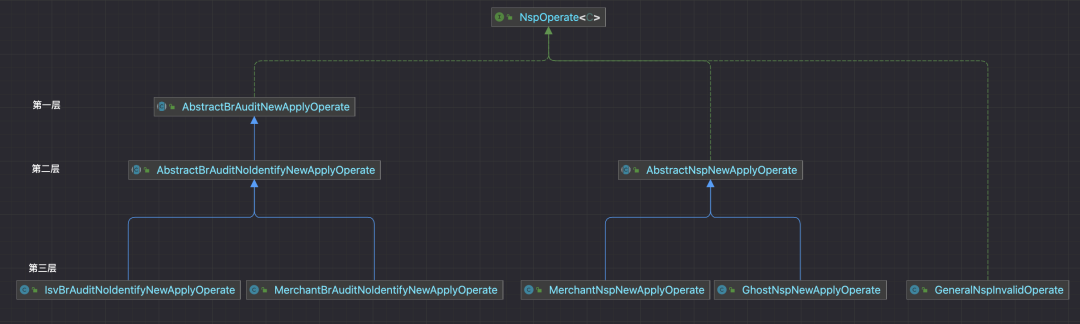
- 第一层:对操作类型(业务事件)聚合的维度,比如商研审核,可以在这里定义商研审核中共用的代码、自定义方法,比如:商研审核通用的入参校验,字段非空之类。
- 第二层:具体到操作类型维度(业务事件),比如商研审核-支持鉴别、商研审核-不支持鉴别等,这里可以定义操作类型维度下所有商品来源渠道的公共代码。比如:不支持鉴别时原因必填,商研审核调用多个系统的一连串的判断逻辑。
- 第三层:具体到商品来源渠道级别的具体实现,可以复用父类中的代码。
并不是每种业务操作都需要有这3层实现,实际使用中三种情况都会出现,比如:
- 只有一层:新品来样作废,与商品来源渠道无关,所有渠道都使用相同逻辑,只有一个实现类即可。
- 只有两层:提交新品申请,区分到不同的商品来源渠道即可。
- 有三层:新品商研审核,商研审核下还分多种操作类型(业务事件),如:商研审核-支持鉴别、商研审核-不支持鉴别、商研审核-发起寄样等,每种操作类型下各个商品来源渠道有各自的实现。
状态机接入
状态机定义
从上文的状态流转图来看,新品来样的状态流转还是比较清楚的,但实际上每个渠道的状态流程都会出现一些细小的差别,为避免来源渠道拆分的不彻底,也综合考虑到状态机配置的成本不高,因此决定每个渠道构建自己的状态机配置。
以C端渠道为例,状态机的配置如下:
@Configuration
@Slf4j
@EnableStateMachineFactory(name = "newSpuApplyStateMachineFactory")
public class NewSpuApplyStateMachineConfig extends EnumStateMachineConfigurerAdapter<NewProductShowEnum, NewSpuApplyStateMachineEventsEnum> {
public final static String DEFAULT_MACHINEID = "spring/machine/commodity/newspuapply";
@Resource
private NewSpuApplyStateMachinePersist newSpuApplyStateMachinePersist;
@Resource
private NspNewApplyAction nspNewApplyAction;
@Resource
private NspNewApplyGuard nspNewApplyGuard;
@Bean
public StateMachinePersister<NewProductShowEnum, NewSpuApplyStateMachineEventsEnum, NewSpuApplySendEventContext> newSpuApplyMachinePersister() {
return new DefaultStateMachinePersister<>(newSpuApplyStateMachinePersist);
}
@Override
public void configure(StateMachineConfigurationConfigurer<NewProductShowEnum, NewSpuApplyStateMachineEventsEnum> config) throws Exception {
config.withConfiguration().machineId(DEFAULT_MACHINEID);
}
@Override
public void configure(StateMachineStateConfigurer<NewProductShowEnum, NewSpuApplyStateMachineEventsEnum> config) throws Exception {
config.withStates()
.initial(NewProductShowEnum.STM_INITIAL)
.state(NewProductShowEnum.CHECKING)
.state(NewProductShowEnum.UNPUT_ON_SALE_UNPASS)
.state(NewProductShowEnum.UNPUT_ON_SALE_PASSED_UNSEND)
.state(NewProductShowEnum.UNPUT_ON_SALE_PASSED)
.choice(NewProductShowEnum.STM_UNPUT_ON_SALE_PASSED_UNSEND)
.choice(NewProductShowEnum.STM_UNPUT_ON_SALE_PASSED)
.state(NewProductShowEnum.UNPUT_ON_SALE_PASSED_UNSEND_NOT_PUT)
.state(NewProductShowEnum.OTHER_UNPASS_FOR_SPU_STUDYER)
.state(NewProductShowEnum.FINSH_SPU)
.state(NewProductShowEnum.GONDOR_INVALID)
.states(EnumSet.allOf(NewProductShowEnum.class));
}
@Override
public void configure(StateMachineTransitionConfigurer<NewProductShowEnum, NewSpuApplyStateMachineEventsEnum> transitions) throws Exception {
transitions.withExternal()
//提交新的新品申请
.source(NewProductShowEnum.STM_INITIAL)
.target(NewProductShowEnum.CHECKING)
.event(NewSpuApplyStateMachineEventsEnum.NEW_APPLY)
.guard(nspNewApplyGuard)
.action(nspNewApplyAction)
//选品不通过
.and().withExternal()
.source(NewProductShowEnum.CHECKING)
.target(NewProductShowEnum.UNPUT_ON_SALE_UNPASS)
.event(NewSpuApplyStateMachineEventsEnum.OM_PICK_REJECT)
.guard(nspOmRejectGuard)
.action(nspOmRejectAction)
//选品通过
.and().withExternal()
.source(NewProductShowEnum.CHECKING)
.target(NewProductShowEnum.UNPUT_ON_SALE_PASSED_UNSEND)
.event(NewSpuApplyStateMachineEventsEnum.OM_PICK_PASS)
.guard(nspOmPassGuard)
.action(nspOmPassAction)
//发起商研审核
.and().withExternal()
.source(NewProductShowEnum.UNPUT_ON_SALE_PASSED_UNSEND)
.target(NewProductShowEnum.STM_UNPUT_ON_SALE_PASSED_UNSEND)
.event(NewSpuApplyStateMachineEventsEnum.START_BR_AUDIT)
.and().withChoice()
.source(NewProductShowEnum.STM_UNPUT_ON_SALE_PASSED_UNSEND)
.first(NewProductShowEnum.UNPUT_ON_SALE_PASSED, nspStartBrAuditWaitAuditStatusDecide, nspStartBrAuditWaitAuditChoiceAction)
.then(NewProductShowEnum.UNPUT_ON_SALE_PASSED_UNSEND_NOT_PUT, nspStartBrAuditRejctStatusDecide, nspStartBrAuditRejctChoiceAction)
.last(NewProductShowEnum.FINSH_SPU, nspStartBrAuditFinishChoiceAction)
//商研审核-支持鉴别
.and().withExternal()
.source(NewProductShowEnum.UNPUT_ON_SALE_PASSED)
.target(NewProductShowEnum.FINSH_SPU)
.event(NewSpuApplyStateMachineEventsEnum.BR_HUMAN_AUDIT_SUPPORT_ALL)
.guard(nspBrAuditSupportAllGuard)
.action(nspBrAuditSupportAllAction)
//商研审核-商品信息有误
.and().withExternal()
.source(NewProductShowEnum.UNPUT_ON_SALE_PASSED)
.target(NewProductShowEnum.OTHER_UNPASS_FOR_SPU_STUDYER)
.event(NewSpuApplyStateMachineEventsEnum.BR_HUMAN_AUDIT_WRONG_INFO)
.guard(nspBrAuditWrongInfoGuard)
.action(nspBrAuditWrongInfoAction)
//商研审核-不支持鉴别
.and().withExternal()
.source(NewProductShowEnum.UNPUT_ON_SALE_PASSED)
.target(NewProductShowEnum.UNPUT_ON_SALE_PASSED_UNSEND_NOT_PUT)
.event(NewSpuApplyStateMachineEventsEnum.BR_HUMAN_AUDIT_SUPPORT_NONE)
.guard(nspBrAuditRejectGuard)
.action(nspBrAuditRejectAction)
;
}
}
状态机的状态与新品来样DB表中的status字段完全映射,状态机事件与上文图中的事件完全匹配。 新品来样中有一些收到事件后需要经过一系列逻辑判断才能得出目标状态的场景,这里会借助状态机的Choice State,完成对目标状态的判断和流转。
明确一下状态机相关的元素哪些是独立拆分的,哪些是共用的:

可以看到只有状态机的配置类是每个渠道不同的,因此成本不高。guard和action的实现类如何实现所有渠道共用会在下文说明。
Guard与Action的实现
从上文状态机的具体配置中可以看到,新品来样流程中涉及两类状态流转:
- 触发事件后的目标状态是固定的,比如选品审核时触发了选品不通过事件,新品申请的目标状态将确定为选品不通过;
- 触发事件后的目标状态需要经过代码逻辑判断,为此状态机配置中引入了choice state,比如发起商研审核的事件,新品申请的目标状态可能是直接不支持鉴别,也可能是新品申请直接通过,也可能是需要人工审核。
在Spring状态机的设计中,这两类状态流转,gurad和action承担的职责会有所差异:
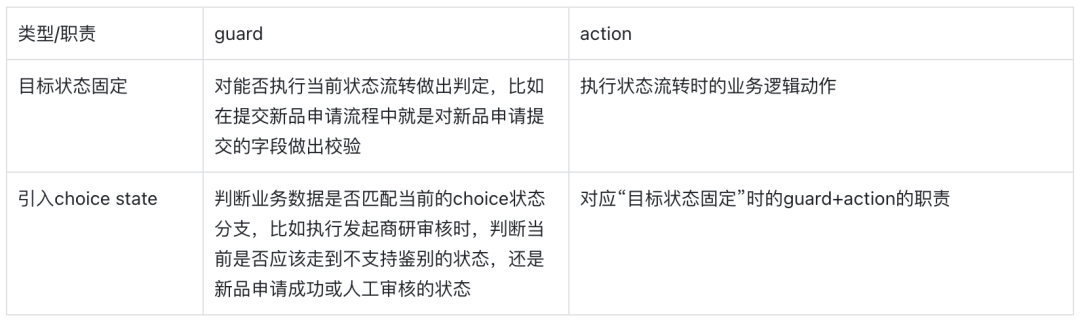
因此这两类guard和action的实现逻辑会有所不同。
然而,对于同一个事件/Choice state下的guard和action,不同商品来源渠道之间是可以共用的,因为已经实现了按商品来源渠道的业务代码拆分,只需要在实现中路由到具体的NspOperate业务实现类即可。下面给出示例:
目标状态固定的guard:
@Component
public class NspNewApplyGuard extends AbstractGuard<NewProductShowEnum, NewSpuApplyStateMachineEventsEnum, NewSpuApplySendEventContext> {
@Resource
private NewSpuApplyOperateHelper newSpuApplyOperateHelper;
@Override
protected boolean process(StateContext<NewProductShowEnum, NewSpuApplyStateMachineEventsEnum> context) {
final CatetorySendEventContextRequest<NewSpuApplyContext> request = getSendEventContext(context).getRequest();
NewSpuApplyContext ctx = request.getParams();
Integer applyType = ctx.getApplyType(); //从业务数据中取出商品来源
NspOperate<NewSpuApplyContext> nspOperate = newSpuApplyOperateHelper.getNspOperate(applyType, NewSpuApplyStateMachineEventsEnum.NEW_APPLY.getCode()); //固定的事件code
//做请求的预处理
nspOperate.preProcessRequest(ctx);
//对业务数据做校验,校验不通过即抛出异常
nspOperate.verify(ctx);
//正常执行完上述2个方法,代表是可以执行的
return Boolean.TRUE;
}
}
guard中只需根据商品来源和固定的事件code获取到NspOperate实现类,并调用NspOperate的preProcessRequest和verify方法完成校验即可。
目标状态固定的action:
@Component
public class NspNewApplyAction extends AbstractSuccessAction<NewProductShowEnum, NewSpuApplyStateMachineEventsEnum, CategorySendEventContext> {
@Resource
private NewSpuApplyOperateHelper newSpuApplyOperateHelper;
@Override
protected void process(StateContext<NewProductShowEnum, NewSpuApplyStateMachineEventsEnum> context) {
final CatetorySendEventContextRequest<NewSpuApplyContext> request = getSendEventContext(context).getRequest();
NewSpuApplyContext ctx = request.getParams();
Integer applyType = ctx.getApplyType(); //从业务数据中取出商品来源
NspOperate<NewSpuApplyContext> nspOperate = newSpuApplyOperateHelper.getNspOperate(applyType, NewSpuApplyStateMachineEventsEnum.NEW_APPLY.getCode()); //固定的事件code
//执行业务逻辑
nspOperate.process(ctx);
//持久化
nspOperate.persistent(ctx);
//后处理
nspOperate.post(ctx);
}
}
action中同样根据商品来源和固定的事件code获取到NspOperate实现类,并调用NspOperate的后几个方法完成业务操作。
Choice state中的guard:
guard需要根据当前渠道和事件做目标状态的判定,这里单独抽象出一个接口供guard实现调用,NspOperate中如果需要用到类似逻辑也可以引用这个单独的接口,因此不会有代码重复:
public interface NspStatusDecider<C, R> {
/**
* 支持的商品来源渠道
* @return
*/
Integer supportApplyType();
/**
* 支持的操作类型
* @return
*/
String operateCode();
/**
* 判定目标状态
* @param context
*/
R decideStatus(C context);
}
@Component
public class NspBrAuditNoIdentifyGuard extends AbstractGuard<NewProductShowEnum, NewSpuApplyStateMachineEventsEnum, NewSpuApplySendEventContext> {
@Resource
private NewSpuApplyOperateHelper newSpuApplyOperateHelper;
@Override
protected boolean process(StateContext<NewProductShowEnum, NewSpuApplyStateMachineEventsEnum> context) {
final CatetorySendEventContextRequest<NewSpuApplyContext> request = getSendEventContext(context).getRequest();
NewSpuApplyContext ctx = request.getParams();
Integer applyType = ctx.getApplyType(); //从业务数据中取出商品来源
NspStatusDecider<NewSpuApplyContext, Result> nspStatusDecider = newSpuApplyOperateHelper.getNspStatusDecider(applyType, NewSpuApplyStateMachineEventsEnum.BR_HUMAN_AUDIT_SUPPORT_NONE.getCode()); //固定的事件code
//判定目标状态
Result result = nspStatusDecider.decideStatus(ctx);
ctx.setResult(result); //将判定结果放入上下文,其他的guard可以引用结果,避免重复判断
return Result.isSuccess(result); //根据判定结果决定是否匹配当前guard对应的目标状态
}
}
Choice state中的action:
@Component
public class NspBrAuditNoIdentifyAction extends AbstractSuccessAction<NewProductShowEnum, NewSpuApplyStateMachineEventsEnum, CategorySendEventContext> {
@Resource
private NewSpuApplyOperateHelper newSpuApplyOperateHelper;
@Override
protected void process(StateContext<NewProductShowEnum, NewSpuApplyStateMachineEventsEnum> context) {
final CatetorySendEventContextRequest<NewSpuApplyContext> request = getSendEventContext(context).getRequest();
NewSpuApplyContext ctx = request.getParams();
Integer applyType = ctx.getApplyType(); //从业务数据中取出商品来源
NspOperate<NewSpuApplyContext> nspOperate = newSpuApplyOperateHelper.getNspOperate(applyType, NewSpuApplyStateMachineEventsEnum.BR_HUMAN_AUDIT_SUPPORT_NONE.getCode()); //固定的事件code
//做请求的预处理
nspOperate.preProcessRequest(ctx);
//对业务数据做校验
nspOperate.verify(ctx);
//执行业务逻辑
nspOperate.process(ctx);
//持久化
nspOperate.persistent(ctx);
//后处理
nspOperate.post(ctx);
}
}
与目标状态固定的action的唯一不同在于多执行了NspOperate的preProcessRequest和verify方法。
不根据不同渠道间使用不同的guard和action实现,而使用单独的策略类来划分不同的渠道实现,出于下面两点考虑:
- 有更换状态机实现的可能,因此不希望状态机实现相关的代码与业务逻辑代码耦合;
- 不涉及状态机的场景,同样存在按渠道拆分逻辑的需要,比如新品申请编辑等等。
商品上新过程中与SPU状态流转的联动
当新品来样进入“商品资料待审核”状态之后,将由SPU状态机流程接管后续SPU的状态流转,直至SPU状态抵达“审核通过”后,新品来样状态流转到商研审核阶段。在这期间,SPU的每次信息和状态变更都需要通知到新品来样(通过MQ或应用内event),再对新品来样记录做对应的业务处理。
后续扩展分析
对于日后新品申请流程中可能涉及的变更,评估本次改造的扩展性。
新增商品来源渠道
配置新的状态机,针对新渠道实现各种业务操作和事件的实现即可,不会影响到现有渠道。
新品来样新增状态节点
修改状态机配置,增加新的事件和对应的实现类即可。
新品来样调整状态间顺序
修改状态机配置,评估涉及的业务操作实现类的修改,修改范围是明确和可控的。
十、小结
我们通过策略模式将不同商品来源渠道的业务逻辑解耦,保留共性,各自实现自己的差异化逻辑,为未来的业务需求变更提供扩展性;通过状态机的引入明确和规范了新品流程中的状态流转,确保状态正确、合法地流转,同时为未来的业务流程的变更打下坚实的基础。
本次改造一方面解决了目前实现中的顽疾,降低了现有代码的上手难度,另一方面也兼顾了开发效率,后续不管是新增来源渠道或是修改业务流程,都可以保障代码修改范围的可控、可测,也不会增加额外的工作量,能够更有效、更安全稳定地支撑业务。
*文/甜橙
本文属得物技术原创,更多精彩文章请看:得物技术官网
未经得物技术许可严禁转载,否则依法追究法律责任!














 7776
7776











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









