







1. 典型相关分析及相关知识
1.1介绍
- 典型相关分析是用来分析向量(组)X和Y之间映射关系的方法。
一般的线性回归问题中,都具有一个或多自变量X和因变量Y,其数学表达形式为:假设 X∈Rm,Y∈Rm ,那么可以建立等式Y=AX,矩阵表示如下
其中 yi=wiTx ,形式和线性回归一样,可以用解n元一次方程组的方法来解得 wi ,当特征数量n较小时可以使用正规方程方法,即 wi=(XTX)−1XTYi 其中 X 是xi 的训练集, Y 是yi 的训练集。如果 XTiXi 不可逆,也就是说训练集有线性相关向量,此时可以采用梯度下降算法进行参数求解。
以上为一般线性回归的内容,探求的是自变量X和因变量Y之间的线性关系 。如果将X和Y都看成整体,考察这两个整体之间的关系,可以将整体表示成X和Y各自特征间的线性组合,也就是考察 aTx 和 bTy 之间的关系。
举一个简单的例子,以便表述该方法的实现步骤 。我们想考察一个学生的运动能力(运动时长,运动强度 )与他的学习能力(学习时长,学习效率 )之间的关系,那么形式化为:
u=a1x1+a2x2 和 v=b1y1+b2y2
然后使用Pearson相关系数来度量u和v的关系
ρX,Y=corr(X,Y)=cov(X,Y)σXσY=E[(X−uX)(Y−uY)]σXσY (1.2)
我们期望寻求一组最优解a和b,使得Corr(u,v)最大这样得到的a和b就是使得u和v具有最大关联的权重。

1.2推导求解
1.2.1协方差矩阵
协方差的作用是判断两个变量是否为同向变化,若都是增大的方向,协方差为正值,若两个变量为反向变化,则协方差为负值。协方差的数值大小,表明程度的大小。其数学表达式如下
- Cov(X,Y)=E((X−E(X))(Y−E(Y))) (1.3)
若X,Y不是实数,而是一个列向量,协方差计算出的矩阵即为协方差矩阵,以下为协方差矩阵计算过程。
例,样本数据为 x1=(1,2)T,x2=(3,6),x3=(4,2)T,x4=(5,2)T 所有样本都是二维的, X,Y 表示为
X=(1,3,4,5)T,Y=(2,6,2,2)T
协方差计算公式为
∑ij=cov(Xi,Xj)=E[(Xi−ui)(Xj−uj)] (1.4)
由于这里只有X,Y两列,所以得到的协方差矩阵是2 × 2的矩阵形式。
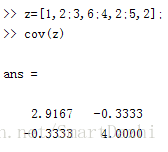
∑11=(1−3.25,3−3.25,5−3.25,5−3.25)×(1−3.25,3−3.25,5−3.25,5−3.25)T×14−1=2.9167
∑12=(1−3.25,3−3.25,5−3.25,5−3.25)×(2−3,6−3,2−3,2−3)T×14−1=−0.3333
∑21=(2−3,6−3,2−3,2−3)×(1−3.25,3−3.25,5−3.25,5−3.25)T×14−1=−0.3333
∑22=(2−3,6−3,2−3,2−3)×(2−3,6−3,2−3,2−3)T×14−1=4.0000matlab计算实例
至此无论是二维数据,还是高维数据,均可由公式(1.4)计算的出协方差矩阵。
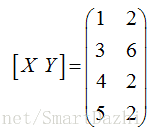
1.2.1 CCA公式推导
- 给定两组向量x和y,x的维度为
p1
,y的维度为
p2
,默认
p1≤p2
。形式化表示如下:
z=[x y],E[z]=[x¯ y¯]
∑ 是z的协方差矩阵,左上角 ∑11 为x自己的协方差矩阵;右上角 ∑12 是Cov(x,y);左下角 是Cov(y,x), ∑11 与 ∑12 互为转置关系;右下角 ∑22 为y的协方差矩阵。
由本文开始所举的运动能力与学习能力关系的例子入手,定义
u=aTx,v=bTy
我们可以计算出u和v的方差和协方差:
Var(u)=Var(aTx)=1N∑i=1N(aTx−aTx¯)2=aT1N∑i=1N(x−x¯)2a=aT∑11a
同理得 Var(v)=bT∑22b
Cov(u,v)=Cov(aTx,bTy)=aTCov(x,y)b=aT∑12b
综上整理, Var(u)=aT∑11a,Var(v)=bT∑22b,Cov(u,v)=aT∑12b
最后,终于到了计算 Corr(u,v) 的时刻了,根据(1.2)相关系数计算公式有
ρuv=Corr(u,v)=aT∑12baT∑11a√bT∑22b√ (1.5) - 让我们再回到运动能力与学习能力例子,若是分析这两种能力之间的关系,那么我们该探求两种能力的最强关系,还是最弱关系?显然对于本例探求最弱关系是没有意义的,接下从表征两种能力关系的
ρuv
入手,求出
ρuv
最大值时,对应系数a,b的具体值。
求 ρuv 的最大值,这是一个优化问题。由于公式(1.5)中等式左侧的分子与分母中同有a,b,这会使分子和分母同时缩放,从而求不出最优解。所以添加限制条件:
aT∑11a=1,bT∑22b=1
Maximize→aT∑12b
构造拉格朗日函数来求解最优解,推导如下:
L=aT∑12b−λ2(aT∑11a−1)−θ2(bT∑22b−1)
对 函数求偏导,得
∂L∂a=∑12b−λ∑11a
∂L∂b=aT∑12−θbT∑22
令 ∂L∂a=0 , ∂L∂b=0 ,得:
∑12b−λ∑11a=0 (1.6)
∑21a−θ∑22b=0 (1.7)
等式(1.6)两端乘 aT ,等式(1.7)两端乘 bT ,得:
aT∑12b−λaT∑11a=0
bT∑21a−θbT∑22b=0
约束条件 : aT∑11a=1 , bT∑22b=1 ,则有
λ=aT∑12b,θ=bT∑21a
仔细观察,其实 λ=θ=aT∑12b
对照公式(1.5)来看 ρuv 能取多大值,完全取决于 aT∑12b ,也就是这里的 λ ,所以接下来的任务是求最大的 λ 。
将上面等式(1.6)(1.7)变换得
∑−111∑12b=λa (1.8)
∑−122∑21a=λb (1.9)
将上式写成矩阵形式
令 B=[∑110 0∑22 ],A=[0∑21∑120],w=[ab] 则有
B−1Aw=λw (1.10)
求 λ 则转化为求特征值,只不过我们当前需要的是数值最大的那个特征值。
求矩阵 B−1A 的特征值和特征向量理论上完全可行,只不过维度过大,算法复杂度较高,不如分块而治之,故将(1.9)带入(1.8),整理得:
∑−111∑12∑−122∑21a=λ2a (1.11)
通过求矩阵 ∑−111∑12∑−122∑21 的特征值 λ2 和对应的特征向量 a ,再将λ 和特征向量 a 带入等式(1.9)中,即可得 。
假设按照上述过程,得到了最大时λ1 的 a1 和 b1 。那么 a1 和 b1 称为典型变量(canonical variates), λ1 即为u和v的最大相关系数。
至于求第二特征变量对 ,及第三特征变量等等,这些为数值上第二大特征值 对应的特征向量,第三大特征值 对应的特征向量,其计算方法同上述过程。
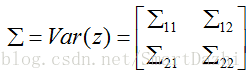
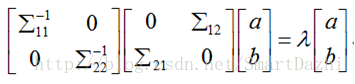
1.3 CCA在特征子空间投影的应用
典型相关性分析法是一种最大相关性策略,利用该方法可挖掘不同模态信息底层特征之间的潜在相关关系,学习最优子空间投影矩阵,以实现异构特征空间转换。
通过维基百科公开数据库Wikipedia articles,可获得图像文本的特征数据压缩文件,分别有2173个“图片—文本”训练样本中的图像和文本提取出的特征,图像特征是128维的SIFT特征,文本特征是由10个主题的LDA文本模型生成的10维特征。关于图像和文本的特征提取方法与过程,不是本文叙述的着重点,暂时不予叙述。
基于相关性的跨模态信息检索实质上就是在同形特征子空间O中,采用某种距离计算方法,度量查询信息资源与被检索信息资源之间的相关性,并按照相关性大小排序[1]。我们现在有图像特征矩阵,大小为2173 × 128,文本特征矩阵,大小为2173 × 10。
根据参考文献[1]可以知道,可使用CCA计算出图像特征与文本特征的相关系数及特征子空间参数矩阵,典型相关性分析的形式表示为:
[Wx,Wy,r]=cca(X,Y) (1.12)
其中的X表示的就是文本的向量表示,Y就是图像的向量表示,图像特征与文本特征的相关系数记为 r=[r1,r2⋯rd]T 且 r1≥r2≥⋯≥rd ,图像特征对应的特征子空间参数矩阵记为Wx,大小为128 × d;文本特征对应的特征子空间参数矩阵记为Wy,大小为10 × d。
特征子空间投影:- Ox=X×Wx,Ox 为2173 × d
-
Oy=Y×Wy,Oy
为2173
×
d
至此,利用典型相关性分析在子空间特征投影完成。
参考文献
[1] 丁恒,陆伟.基于相关性的跨模态信息检索研究[J].现代图书情报技术,2016,266(1):17-23















 2310
2310

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









