






“以史为鉴,可以知兴替”。深度神经网络模型在训练过程中产生的历史信息往往被大家所忽视,为了充分利用这一信息,该文提出利用历史训练模型(checkpoints)当作负模型(以此构建负样本)的对比学习通用框架,并在多个图像复原问题中验证了该框架的有效性。
论文链接:https://ojs.aaai.org/index.php/AAAI/article/view/28412/
代码链接:https://github.com/Aitical/MCLI
1 概述
图像复原是计算机视觉领域的基础研究内容之一,致力于从低质量图像中恢复出对应的高质量结果,包括图像超分辨率、去雾、去雨以及去模糊等任务。深度学习技术的发展为图像复原领域带来了革命性的进步,基于卷积神经网络 (CNN) 和 Transformer架构的深度图像复原模型在这一领域引起了广泛关注。尽管随着基础模型的不断改进多种图像复原任务的测试指标也在不断提升,但本质上图像复原方法尝试求解低质量输入到高质量输出的反向映射,是一个不适定问题 (ill-posed problem),仍然充满挑战。
引入更多的任务或者数据先验有助于目标任务的求解,近期的许多研究工作关注于自监督约束的设计 (Self-Supervised Regularization),尤其是基于对比自监督学习的对比范式在底层视觉任务的应用逐渐引起大家关注。 与高层视觉的自监督预训练相比,有监督范式下的底层图像复原任务有对应的高质量真值作为参考,这使得负样本信息的探索和利用变得尤为重要,也是众多研究工作关注的重点,例如,在去雾任务中,低质量输入图像直接作为负样本,或利用预训练模型产生负样本;在图像超分辨率任务中,则使用质量相近的图像作为难负样本。
然而,现有的对比学习约束虽然已经取得一定成效,但依然存在局限性。这些方法往往基于特征的任务先验展开 (task-oriented prior),并且负样本的生成和方法的有效性验证通常针对于特定目标任务,这也限制了它们在面对不同图像复原任务的泛化性。自然地,我们思考:能否有一种通用的对比学习方法可以提高多种图像复原任务的性能?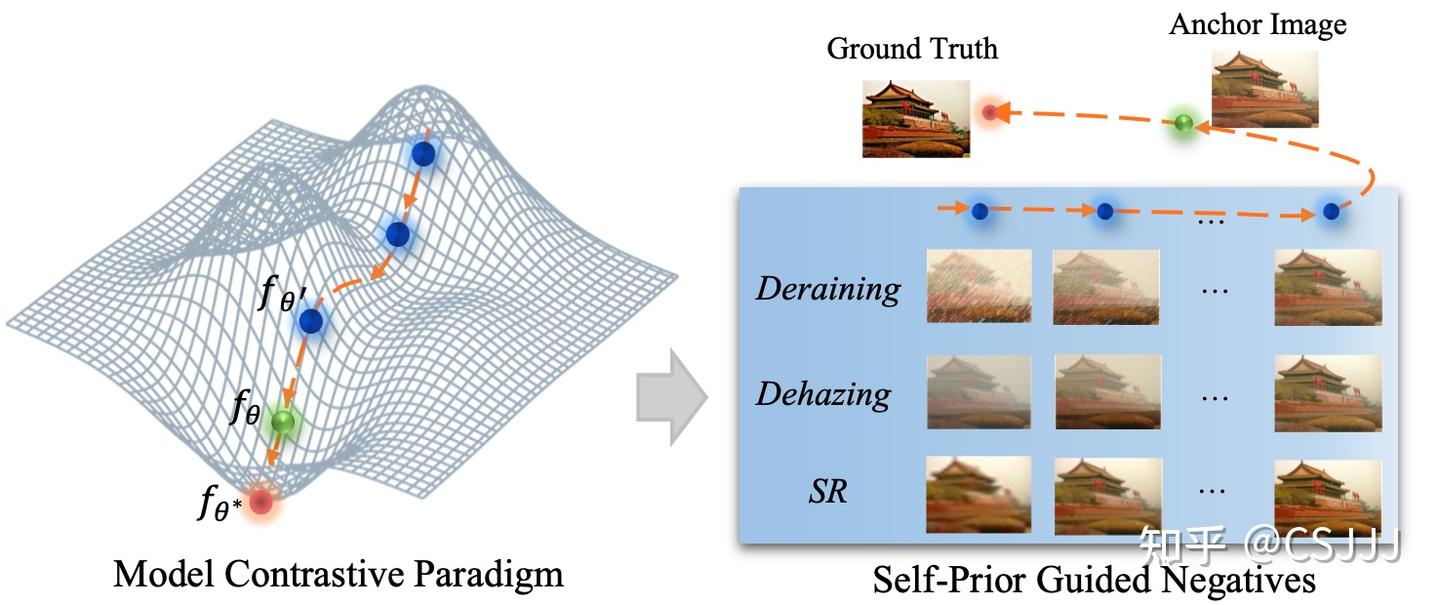
图1. 模型对比学习示例:挖掘目标模型优化过程的中间结果作为自适应负样本。
为了回答这一问题,首先我们深入分析现有方法,不难发现现有工作的局限性主要源于负样本的构造过程,这一过程需要基于较强的任务先验。 所以在该工作中,我们将视角从负样本构造转向了目标模型本身。当我们关注目标模型自身时,我们发现此前研究工作忽视的目标模型优化过程的中间结果,即在优化过程中保存的历史模型。在相邻的迭代周期内,这些历史模型与当前目标模型有着相近的参数分布,进而有着相近图像质量的图像复原结果,我们认为这些中间结果为负样本生成提供了新的可能性。不难发现,这些中间结果天然就是目标模型的“难负样本”,并且是自适应的负样本,随着目标模型的收敛,对应的中间结果由难到易的生成负样本,更重要的是,这一过程是任务无关的,仅依赖于目标模型的优化过程,可以泛化到多种基于图像复原任务,如图1所示,我们为模型对比学习过程提供了一个Toy example以帮助大家更好的理解这一观察。基于此,本文提出了一种全新的图像复原领域任务通用的对比学习范式:模型对比学习 (Model Contrastive Learning for Image Restoration, MCLIR)。不同于以往复杂的负样本挖掘策略,我们的方法核心在于目标模型与历史模型之间的对比范式构造,模型对比约束不依赖于特定的任务先验知识,可以轻松应用到多种图像复原任务和多种模型结构中。实验验证部分,通过对多种图像复原任务和不同模型结构的综合评测来验证本文提出的模型对比学习框架的有效性,部分对比如图2所示,利用本文提出的模型对比学习的框架重训的多种图像复原任务模型均可获得显著提升。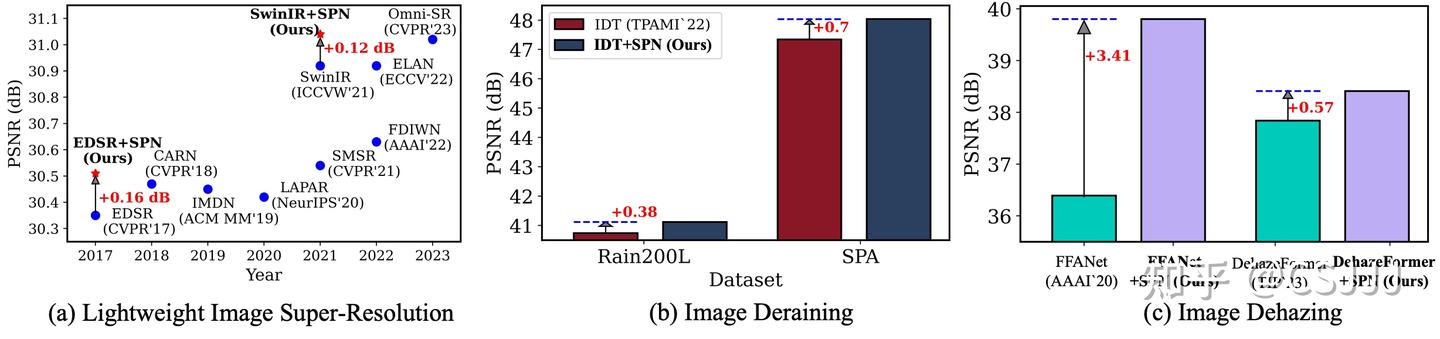
图2. 多种图像复原任务中,利用本文提出的模型对比学习范式重训现有的图像复原模型,均可取得进一步的性能提升。
在后续的研究工作中,我们也对本文所提出的模型对比学习持续优化,并进一步简化了整个框架的方法设计,极大的精简了改方法结合现有工作的迁移成本。希望我们的研究能够为底层视觉图像复原领域提供一种简洁且高效的对比学习方法,能够为更多的研究者提供一些关键且有趣的研究内容,能够进一步推动底层视觉相关研究的进展。
2 方法
2.1 方法概述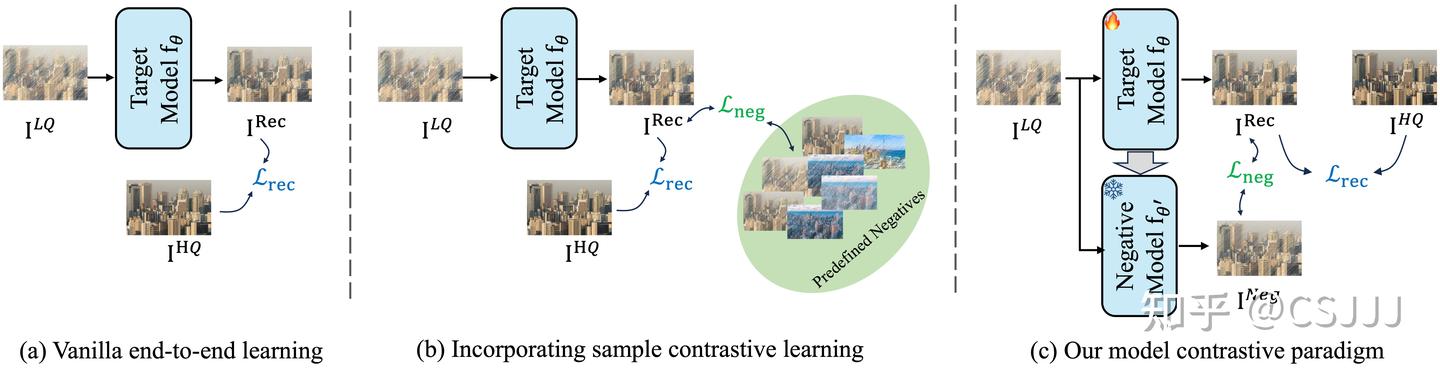
图3. 图像复原任务基础优化范式对比。图 (a) 是一般的端到端学习过程,利用有监督图像复原数据训练目标图像复原模型。 图 (b) 是现有研究工作提出的对比学习学习约束的一般范式,即通过任务相关的先验指导负样本构造以实现对比约束[1][2][3]。图 (c) 是本文提出的模型对比学习框架。
我们梳理了几种典型的图像复原方法学习范式,如图3所示。和现有工作相比,我们扩展了一般的端到端训练框架,引入“负模型”设计。相较于目标模型,负模型用于产生当前重建结果的难负样本,负模型参数不参与训练而是利用指数滑动平均策略 (EMA) 缓慢同步目标模型参数。相较于现有方法,本文提出的模型对比学习范式更具通用性,不需要目标任务先验来指导负样本设计,并且在实现上可以作为现有图像复原方法“即插即用”的优化模块。本文重点关注端到端的深度学习框架。 给定低质量输入图像 ILQ ,目标模型 θ( θ 表示模型参数)对其进行处理,生成重建图像 IRec 。图像的高质量对应物表示为 IHQ 。 fθ 的优化通过最小化重建损失 Lrec 来指导,定义为:
![]()
其中 Lrec 通常依赖于平均绝对误差(MAE)和均方误差(MSE)等指标。 现有的图像恢复对比学习方法利用负样本 INeg ,将标准的端到端学习扩展为包含负损失 Lneg :
![]()
其中,负样本 INeg 是预定义的,基于任务特定的先验生成,这限制了它们在不同图像恢复任务中的泛化能力。 本文提出了一种新颖的图像恢复模型对比范式,从任务特定的负样本转变为源自目标模型本身的负样本。我们将目标模型指定为 fθ ,表示其在给定训练迭代 t 中的状态。一个关键创新是开发了延迟模型 fθ′ (负模型),用于生成自适应负样本以训练 fθ 。这种方法简化了现有方法中的整个过程,为图像恢复提供了一个通用框架。负模型的实现细节和相应的损失函数将在后续部分进行阐述相较于一般的端到端有监督训练过程,现有研究工作则是基于目标任务先验,分析和挖掘适合目标任务的负样本用于构造对比学习约束,例如使用低质量输入图像作为负样本 [1]、通过退化构造和重建结果图像质量相近的难负样本 [2]以及通过利用其他多个预训练模型的结果生成一致性负样本 [3]。
2.2 负模型挖掘
免了模型检查点之间存在显著差距以及频繁处理的不可行性所带来的挑战,尤其是对于较大的模型而言。具体而言,我们引入了指数移动平均(EMA)的高效策略来实现平滑的负模型。负模型的更新方程如下:
![]()
在这个方案中, w 表示更新权重, s 是更新步长, t 表示当前迭代。为了确保延迟参数的保留,我们采用了较长的步长,选择性地每隔 s 次迭代更新负模型 fθ 。通过这种方式,我们 α 能够在训练过程中利用延迟模型生成信息丰富的负样本,同时避免了频繁更新负模型带来的计算开销。这使得我们的方法在实践中更加高效和可扩展。
2.3 负样本损失
在我们的模型对比范式的核心,损失函数在目标重建IRec和其负样本对应物 INeg 之间起到调解作用。我们采用预训练的 VGG 网络作为嵌入网络,将样本映射到潜在特征空间。因此,提出的负损失 Lneg 可表述为:
![]()
此外,我们的模型对比范式可以通过添加更多负模型来纳入多个负样本。为了获得更强的鲁棒性,我们采用多个不同的步长来获得几个延迟模型。考虑多个负样本的组合负损失表示为:
![]()
与现有方法相比,我们的负正则化是一种自先验引导的损失函数,其中负样本源自目标模型本身。更重要的是,它具有通用性,可转移到现有的图像恢复模型,同时保留原始学习策略。通常,图像恢复任务采用重建损失 ,依赖于平均绝对误差(MAE)和均方误差(MSE)等指标。为了验证我们的模型对比范式的有效性,我们在不同的图像恢复任务和架构中重新训练了许多现有方法。重建损失的具体形式取决于重新训练的方法。通常,在我们的模型对比范式中,总损失函数定义为:
![]()
其中,Lrec表示现有方法中采用的相应重建损失,λ 是平衡系数。这种简单的公式使我们能够将提出的 SPN 与现有的图像恢复方法相结合,增强它们对各种任务的灵活性和适应性。
3 实验验证
3.1 图像超分辨率
从表1中可以看出,使用我们提出的模型对比范式重新训练的模型在所有测试数据集上都取得了更好的性能。无论是基于 CNN 的 EDSR 还是基于 Transformer 的 SwinIR,我们的方法都能带来一致的性能提升。这证明了我们提出的模型对比范式在图像超分辨率任务中的有效性和通用性。值得注意的是,我们的方法在不同的放大倍数( ×2 和 ×4 )下都取得了性能提升,表明其对不同难度级别的图像超分辨率任务都有很好的适应性。图4是图像超分辨率任务主观结果对比,可以看到利用本文提出的模型对比框架重新训练的SwinIR-light 和SwinIR 模型结果相较于原模型结果有着更多图像细节信息。
表1. 图像超分辨率任务结果对比,我们选取基于CNN结构的EDSR和基于Transformer结构的SwinIR作为基准模型,并利用本文提出的MCLIR进行重训。
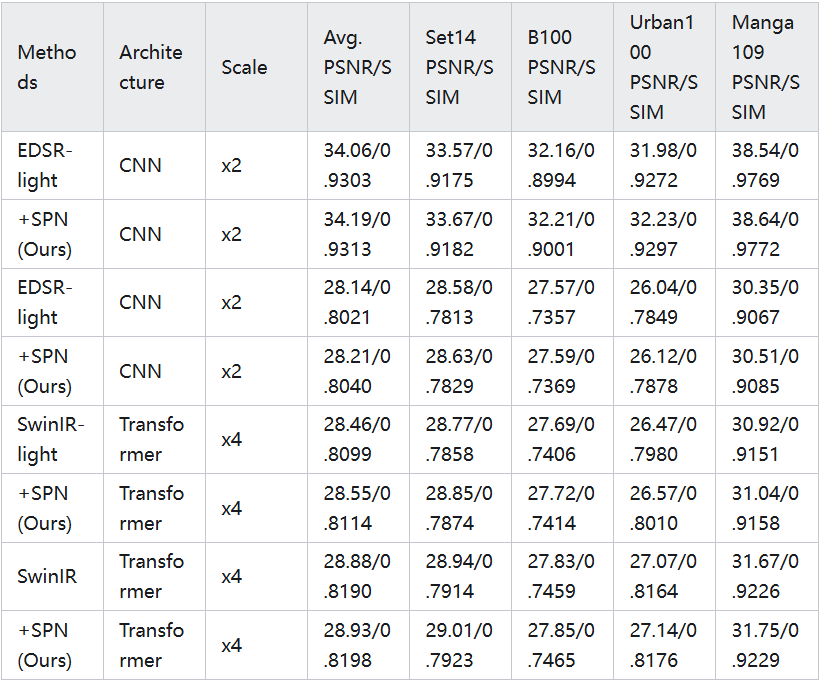

图4. 图像超分辨率任务主观结果对比。
3.2 图像去雨
为了进一步验证我们提出的模型对比范式的有效性,我们在图像去雨任务中进行了实验。我们选取了最近的一些先进方法作为比较对象,包括 MPRNet、DualGCN、SPDNet、Uformer-S、Restormer 和 DRSformer 等。此外,我们以 IDT 作为基准模型,使用我们的方法对其进行了重新训练。实验结果如表2所示。如图5所示,利用本文提出的模型对比范式重训的IDT模型可以取得更好的客观指标。更重要的是,通过与原IDT模型结果的差值图可以发现,我们的模型对比学习框架可以让模型更好的学习雨退化去雨。
表2. 图像去雨任务基准对比。
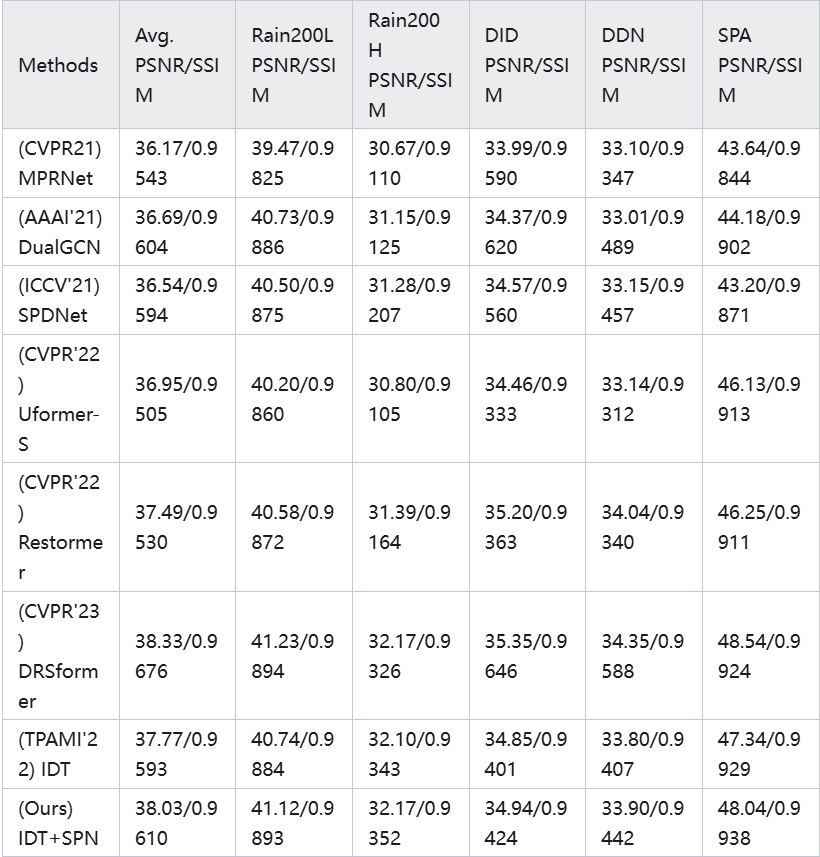
从表中可以看出,使用我们提出的模型对比范式重新训练的 IDT 模型(IDT+SPN)在所有测试数据集上都取得了最好的性能,超过了其他所有比较方法。在平均性能方面,IDT+SPN 的 PSNR 和 SSIM 分别达到了 38.03 dB 和 0.9610,比原始的 IDT 模型分别提高了 0.26 dB 和 0.0017。具体来看,在 Rain200L、Rain200H、DID、DDN 和 SPA 这五个数据集上,IDT+SPN 都取得了最优的性能。特别是在 SPA 数据集上,IDT+SPN 的 PSNR 和 SSIM 分别达到了 48.04 dB 和 0.9938,比最近的 DRSformer 方法分别高出 0.50 dB 和 0.0014,优势明显。

图5. 图像去雨任务主观结果对比。
3.3 图像去雾
为了全面评估我们提出的模型对比范式在图像去雾任务中的性能,我们在 ITS 和 RESIDE-6K 两个数据集上进行了实验并选取了一些最新的图像去雾方法作为比较对象,包括 AECR-Net、SFNet 和C2PNet 等。此外,我们以 FFANet 和 DehazeFormer 作为基准模型,使用我们的方法对其进行了重新训练。实验结果如表3所示。
表3. 图像去雾任务基准对比。
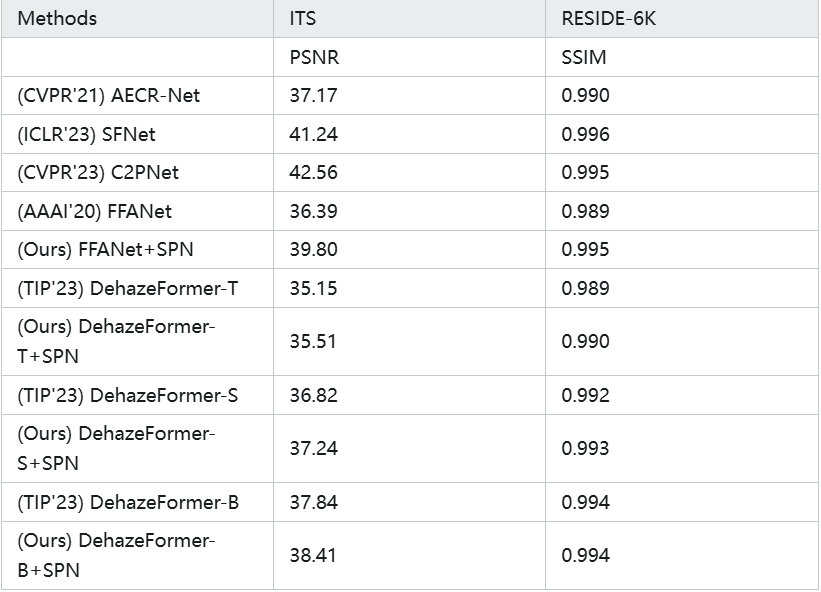
从表中可以看出,使用我们提出的模型对比范式重新训练的模型在两个数据集上都取得了显著的性能提升。以 FFANet 为例,FFANet+SPN 在 ITS 数据集上的 PSNR 和 SSIM 分别达到了 39.80 dB 和 0.995,比原始的 FFANet 模型分别提高了 3.41 dB 和 0.006;在 RESIDE-6K 数据集上的 PSNR 和 SSIM 也分别提高了 0.69 dB 和 0.003。对于 DehazeFormer 系列模型,无论是轻量级的 DehazeFormer-T,还是中等规模的 DehazeFormer-S 和大规模的 DehazeFormer-B,使用我们的方法重新训练后都取得了一致的性能提升。特别是 DehazeFormer-B+SPN,在 ITS 数据集上的 PSNR 达到了 38.41 dB,超过了所有其他比较方法。
3.4 图像去模糊
为了进一步验证我们提出的模型对比范式在图像去模糊任务中的有效性,我们在 GoPro 数据集上进行了实验。我们选取了一些最新的图像去模糊方法作为比较对象,包括 MIMO-UNet、HINet、MAXIM、Restormer 和 UFormer 等。此外,我们以 NAFNet 作为基准模型,使用我们的方法对其进行了重新训练。实验结果如表4所示。
表4. 图像去模糊基准对比。
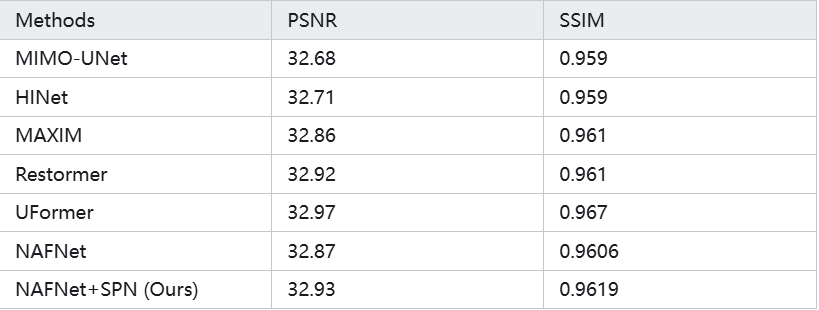
从表中可以看出,使用我们提出的模型对比范式重新训练的 NAFNet 模型(NAFNet+SPN)在 GoPro 数据集上取得了最优的性能。具体来说,NAFNet+SPN 的 PSNR 达到了 32.93 dB,比原始的 NAFNet 模型提高了 0.06 dB,也超过了其他所有比较方法。
3.5 与现有对比学习方法的对比结果
为了进一步分析我们提出的模型对比范式与现有对比范式的区别和优势,我们选取了两个代表性的图像复原任务,即图像去雾和图像超分辨率,并分别选择了这两个任务中基于对比学习的最新方法作为比较对象。实验结果如表5所示。
表5. 与现有底层视觉领域对比学习方法对比。
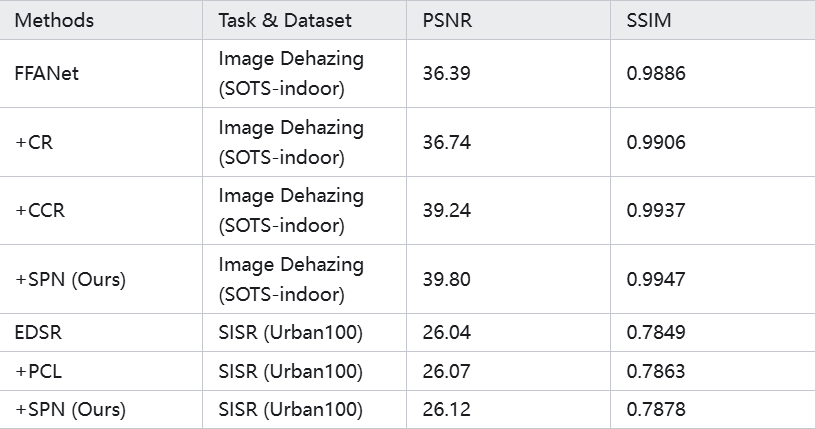
对于图像去雾任务,我们以 FFANet 作为基准模型,分别使用 CR [1]、CCR [3] 和我们提出的 SPN 方法进行训练。可以看出,使用 SPN 训练的 FFANet 模型在 SOTS-indoor 数据集上取得了最优的性能,PSNR 和 SSIM 分别达到了 39.80 dB 和 0.9947,超过了使用 CR 和 CCR 训练的模型。这表明我们提出的模型对比范式在图像去雾任务中的有效性优于现有的对比学习方法。
对于图像超分辨率任务,我们以 EDSR 作为基准模型,分别使用 PCL [2] 和我们提出的 SPN 方法进行训练。可以看出,使用 SPN 训练的 EDSR 模型在 Urban100 数据集上的 PSNR 和 SSIM 分别达到了 26.12 dB 和 0.7878,超过了使用 PCL 训练的模型。这表明我们提出的模型对比范式在图像超分辨率任务中同样具有优势。
值得注意的是,现有的对比学习方法通常是针对特定任务而提出的,如 CR 和 CCR 是针对图像去雾任务,而 PCL 是针对图像超分辨率任务。相比之下,我们提出的模型对比范式是任务无关的,可以灵活地应用于不同的图像恢复任务,展现出了更强的通用性和适应性。
4 总结
在本研究中,我们为底层视觉图像复原领域提出了一种创新的模型对比学习框架。与现有方法中面向任务的负样本构建方式不同,我们提出的模型对比范式通过从目标模型本身构建负样本,扩展了现有的有监督图像复原方法的学习范式,具有任务无关性和通用性。我们提出的对比约束实现简单直观,易于集成到现有的图像复原模型中。利用MCLIR重新训练了多个图像图像模型,并在各种任务和架构上都取得了显著的性能提升。此外,我们还与现有的底层视觉任务中对比学习方法进行了深入的比较和分析。结果表明,我们提出的模型对比范式在不同任务中都优于现有的任务相关的对比学习方法,展现出了更强的适应性和灵活性。这为图像复原领域提供了一种新的范式,为进一步提升图像恢复性能提供了新的思路和方向。我们期待与学界同仁进一步交流和合作,共同推进图像复原技术的发展和应用。
5 主要参考文献
[1] Wu H, Qu Y, Lin S, et al. Contrastive learning for compact single image dehazing[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2021: 10551-10560.
[2] Wu G, Jiang J, Liu X. A practical contrastive learning framework for single-image super-resolution[J]. IEEE Transactions on Neural Networks and Learning Systems, 2023.
[3] Zheng Y, Zhan J, He S, et al. Curricular contrastive regularization for physics-aware single image dehazing[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2023: 5785-5794.


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









