






目录
上篇补充:

xlwt.XFStyle() : 定义样式
xlwt. Font() :定义字体
font.bold =True 文本加粗
=False 文本不加粗
font.underline =True :文本加下划线
=False :文本不加下划线
font.colour_index = 0 : 黑;1:白;2:红;3:绿;4:蓝;5:黄;6:紫
xlwt. Alignment ():定义对齐方式
配套出现:
align.horz =2 : 水平居中 1:左;2:中;3:右
align.vert =1 : 垂直居中 0:上;1:中;2:下
一、前期准备
由于 Python 标准库中默认不包含pandas 库,因此需要用户自己下载安装。
具体安装方法如下:
命令行安装:pip install pandas
(更具体的内容可见上一篇)
二、Excel文件的读取
1.导入模块 pandas

用于数据处理与分析
import 模块名:导入整个模块
pd = pandas
2.打开工作簿
(1)

read_excel() : 从Excel文件中读取数据
注:电脑上直接复制的是转义字符 ‘ \ ’ , 在' '前加r可将其变成路径!!!
3.读取文件数据
(1)读取数据并创建文件对象

data为创建的文件对象

矩形中的data:是为了输出文件对象中的内容。
read_excel() : 从Excel文件中读取数据
index_col : 索引列,可以是整数或整数列表
具体解释:
原工作簿:
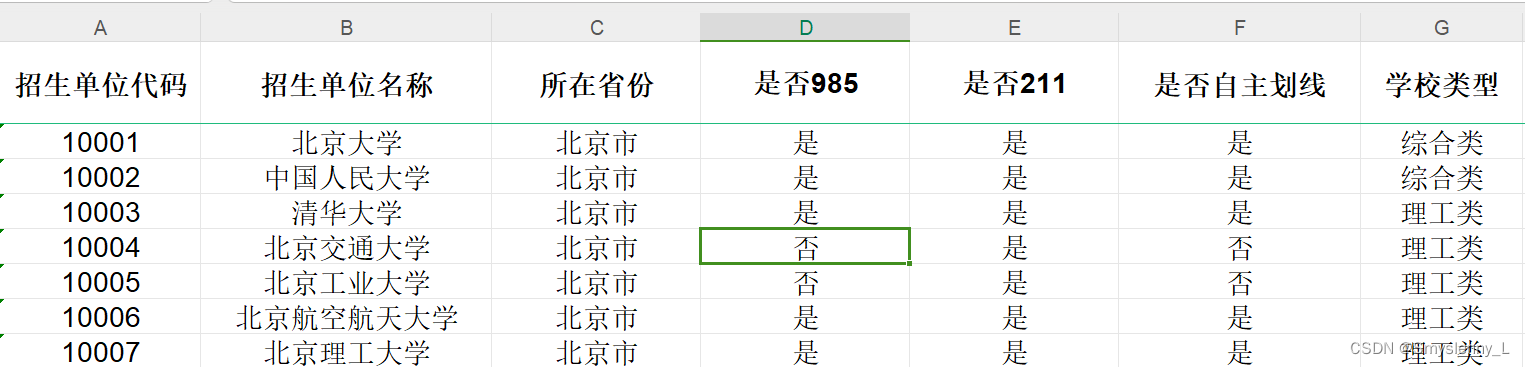
若 index_col = 0:(列从第0列开始)
原工作簿的第0列输出为第0列
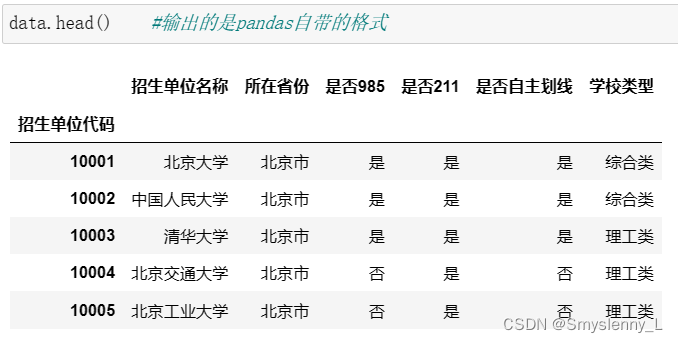
若 index_col = 3:(列从第0列开始)
原工作簿的第3列输出为第0列
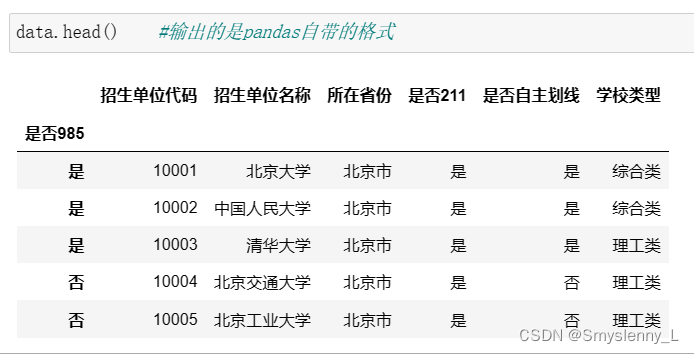
1' head(n):获取前n行数据,n默认为5,结果为 DataFrame
即 head():获取前5行数据
data.head() :输出的是pandas自带的格式
print(data.head()) : 输出的是直接打印的格式
即:

2' tail(n) :获取后n行数据,n默认为 5,结果为 DataFrame
data.tail(10):

3' count() :统计各列中非空值的数量,结果为 Series
data.count() [每列一共870行]

dtype : int64 : 用于表示64位整数类型。
64位整数类型具有很大的范围,可用于存储非常大的整数。
4.写入保存

data[data.所在省份== '上海市'] : 用来选择data数据集中省份为“上海市”的行。
注:比较两个值是否相等:使用双引号
to_excel(文件名) : 将数据保存到 Excel文件中















 1506
1506











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









