







这篇主要介绍:
- Search API
- URI Search详解
- Request Body与Query DSL
- Query String & Simple Query String查询
Search API
elasticsearch的搜索API可分为两大类
- URI Search
- 在URL中使用查询参数
- Request Body Search
- 使用Elasticsearch提供的,基于JSON格式的更加完备的Query domain Specific Language(DSL)
1.指定查询的索引
| 语法 | 范围 |
|---|---|
| /_search | 集群上所有的索引 |
| /index1/_search | index1 |
| /index1,index2/_search | index1和index2 |
| /index*/_search | 以index开头的索引 |
2.URI查询
- 使用“q”,指定查询字符串
- “query string syntax”,KV键值对
例子:
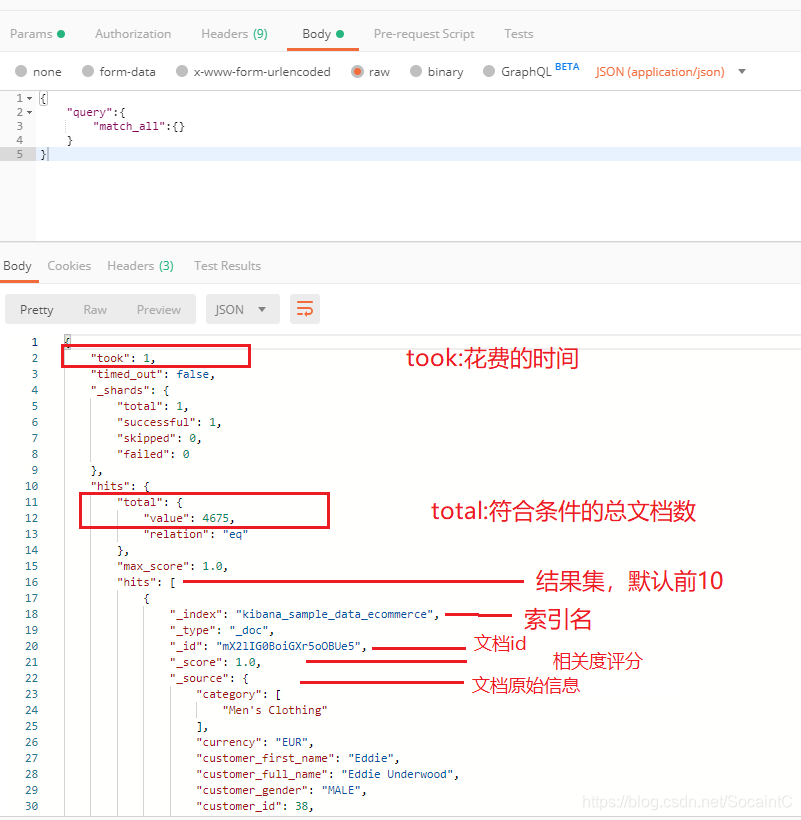
curl -XGET "http://192.168.74.112:9200/kibana_sample_data_ecommerce/_search?q=customer_first_name:Eddie" -H 'Content-Type:application/json' -d'
{
"query":{
"match_all":{}
}
}'
# 支持GET POST
# kibana_sample_data_ecommerce是需要操作的索引名
# _search表示执行搜索
# q用来表示查询内容,搜索叫做Eddie的客户
# query表示查询
# match_all表示返回所有的文档
搜索查询结果如下:
3.搜索的相关性relevance
- 搜索是用户和搜索引擎的对话
- 用户关心的是搜索结果的相关性
- 是否已经找到所有相关内容
- 不相关的返回内容有多少
- 文档的打分是否合理
- 结合业务需求,平衡结果排名
web搜索
- Page Rank算法
- 不仅仅是内容
- 更重要的是内容的可信度
电商搜索
- 搜索引擎角色-销售
- 提高用户购物体验
- 提升网站销售业绩
- 去库存
4.衡量相关性
- Informatica Retrieval
- Precision(查准率) - 尽可能返回较少的无关文档
- Recall(查全率) - 尽量返回较多的相关文档
- Ranking - 是否能够按照相关度进行排序
Precision & recall
- Precision准确率
- 准确率针对预测结果而言,表示的是预测为正的样本中所少是真正的正样本。所以说预测为正就有两种可能,一种是把正预测为正(true positive),另一种就是把负类预测为正类(false positive)
- 表达式: P = T P T P + F P P = \frac{TP}{TP+FP} P=TP+FPTP
- Recall 召回率
- 召回率针对原有样本而言,表示的是样本中的正例有多少本预测正确了。也有两种可能,一种是把原来的正类预测为正类(true positive),另一种是把原来的正类预测为负类(false nagative)。
- 表达式: R = T P T P + F N R = \frac {TP} {TP+FN} R=TP+FNTP

在elasticsearch中,提供了很多查询和相关的参数改善搜索的Precision和Recall
URI search
顾名思义,URI search就是通过URI进行查询
通过URI query实现搜索
GET /movies/_search?q=2012&df=title&sort=year:desc&from=0&size=10&timeout=1szhi
- q 指定查询语句,使用 Query String Syntax
- df 默认字段,不指定时候,会对所有字段进行查询
- Sort 排序 ,可以指定 from 和 size 用于分页
- Profile 可以查看查询如何执行的
1.指定字段 v.s 泛查询
- q=title:2012 / q=2012
# 指定字段查询,加profile查看查询如何执行的
GET /movies/_search?q=title:2012
{
"profile": "true"
}
# 查询结果profile中的部分信息,可看出查询类型是termQuery,参数是title:2012
{"query" : [
{
"type" : "TermQuery",
"description" : "title:2012"
}
]
}
# 泛查询,针对_all,所有字段
GET /movies/_search?q=2012
{
"profile": "true"
}
# 查询结果profile中的部分信息,使用DisjunctionMaxQuery,对所有字段查询,性能较差
{"query" : [
{
"type" : "DisjunctionMaxQuery",
"description" : "(title.keyword:2012 | id.keyword:2012 | year:[2012 TO 2012] | genre:2012 | @version:2012 | @version.keyword:2012 | id:2012 | genre.keyword:2012 | title:2012)"
}
]
}
2.Term v.s Phrase
- Term : Beautiful Mind 等效于 Beautiful OR Mind
- Phrase : 查询语句要用引号引起来,“Beautiful Mind”,等效于 Beautiful AND Mind。Phrase查询,还要求前后顺序要保持一致
# Term query
GET /movies/_search?q=title:Beautiful Mind
{
"profile": "true"
}
# Phrase query
GET /movies/_search?q=title:"Beautiful Mind"
{
"profile": "true"
}
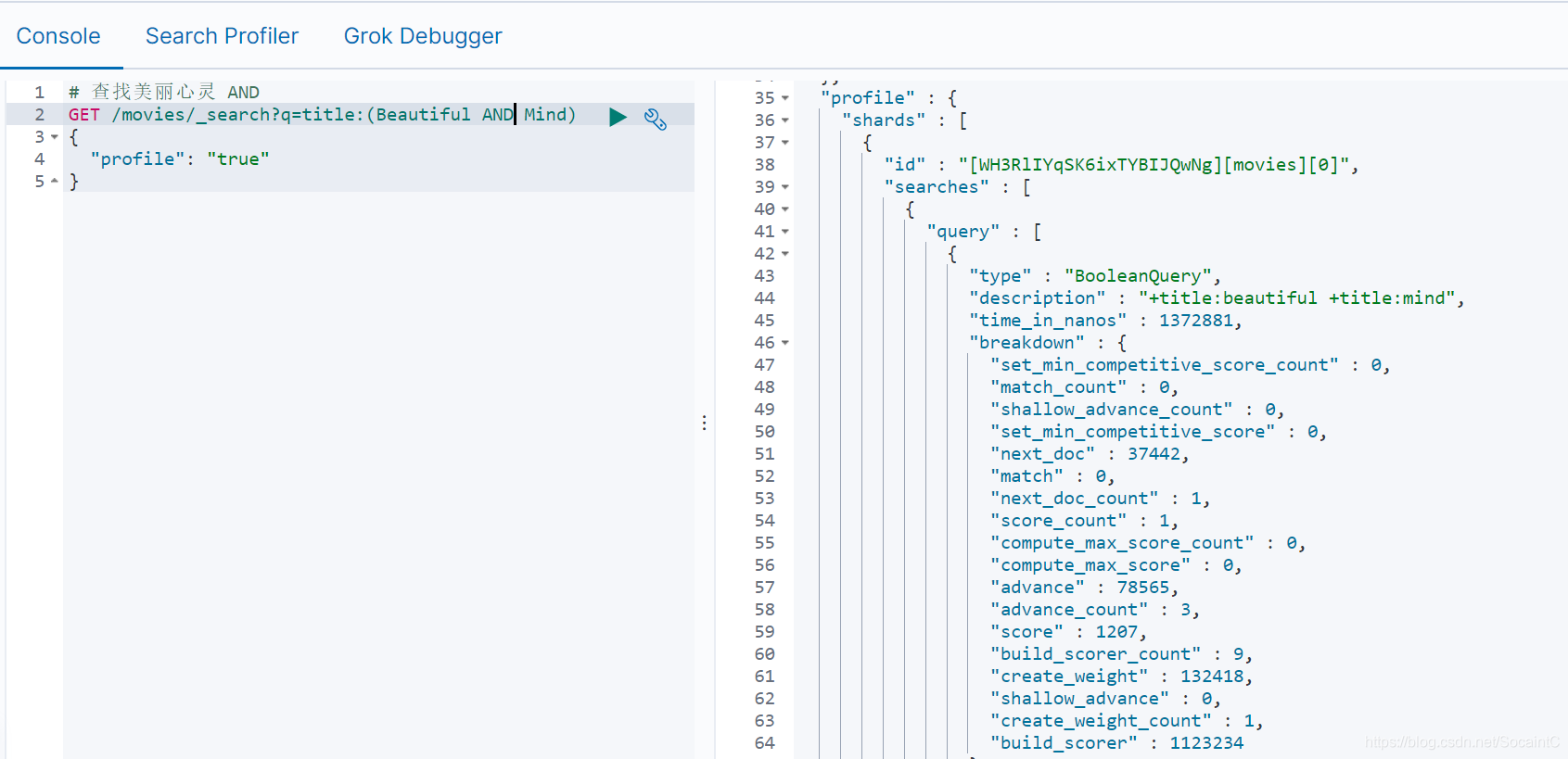
分组与引号
- title:(Beautiful AND Mind),当你去查询一个term query时,要用括号把查询内容括起来
# 分组
GET /movies/_search?q=title:(Beautiful Mind)
{
"profile": "true"
}
- 如果是phrase query 就用引导,title=“Beautiful Mind”
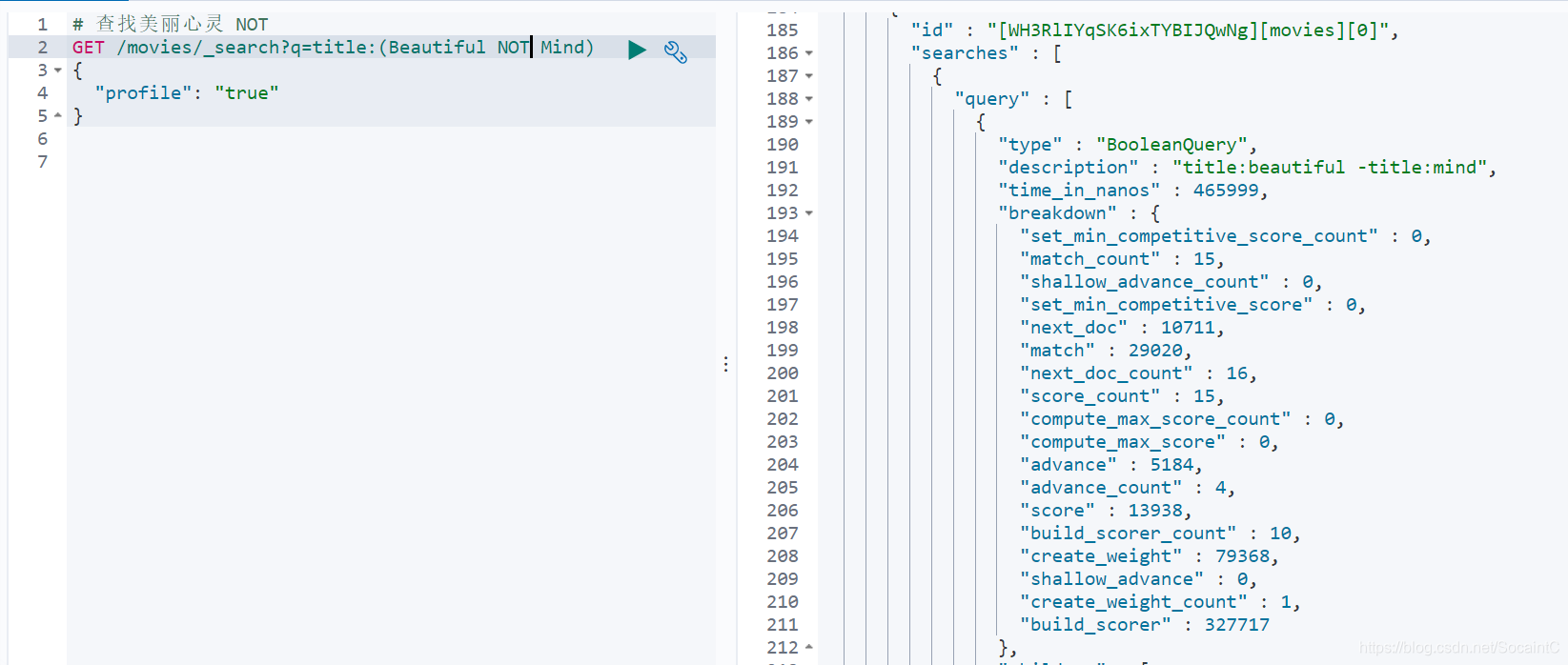
3.布尔操作
AND/OR/NOT或者&&/||/!- 必须大写
- 例如:tile:{matrix NOT reloaded}
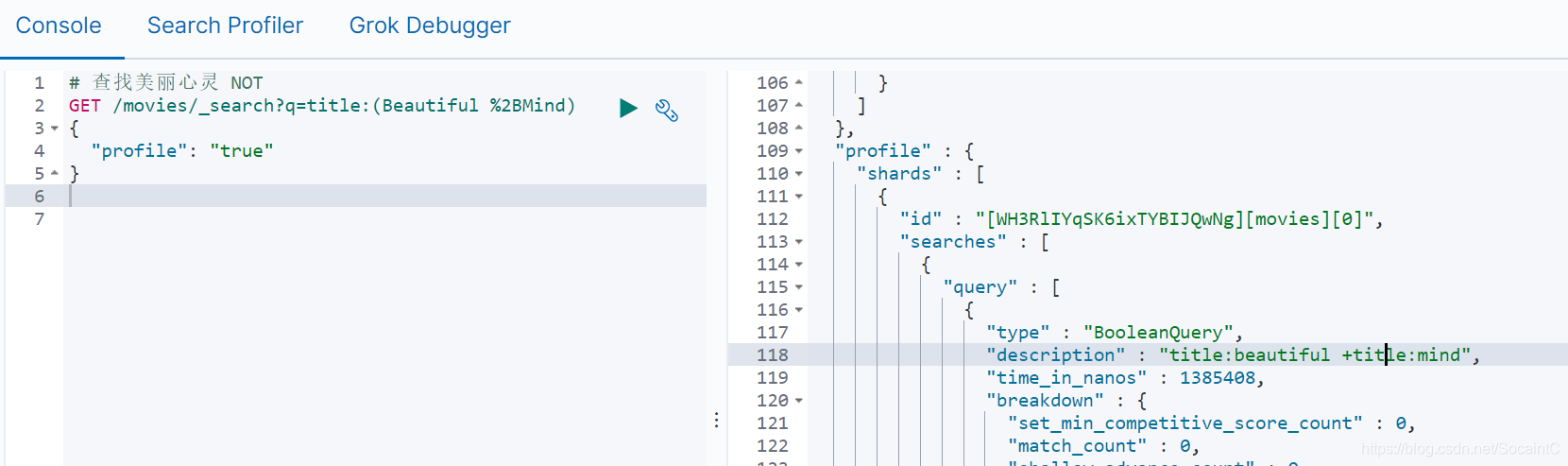
4.分组
+表示 must-表示 must_not- title:{+matrix -reloaded}
举例:
- 查找美丽心灵,指定分组和布尔操作AND
- 查找美丽心灵,指定分组和布尔操作NOT
- 查找美丽心灵,分组+,必须要有mind
5.范围查询
- 区间表示:
[]闭区间,{}开区间- year:{2019 TO 2018}
- year:[* TO 2018]
算数符号
- year:>2010
- year:(>2010 && <=2018)
- year:(+>2010 +<=2018)
# 范围查询,区间写法 / 数学写法
GET /movies/_search?q=year:>=1980
{
"profile": "true"
}
6.通配符查询
通配符查询效率低,占用内存大,不建议使用。特别是放在前面限制
- ?代表一个字符,*代表0或者多个字符
- title:mi?d
- title:be*
- 正则表达
- title:[bt]oy
- 模糊匹配与近似查询
- title:befutifl~1
- title:“lord rings”~2
# 通配符查询,title有b的查询出来
GET /movies/_search?q=title:b*
{
"profile": "true"
}
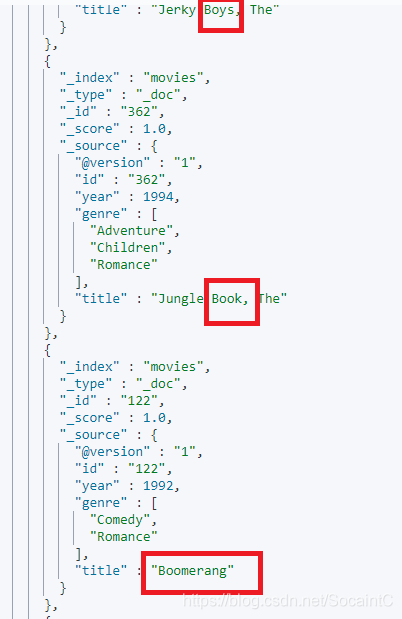
# 模糊匹配&近似度匹配
# 通过近似度匹配的查询方式,即便是输错了一个字母,beautiful有关title也可以查询出来
GET /movies/_search?q=title:beautifl~2
{
"profile": "true"
}
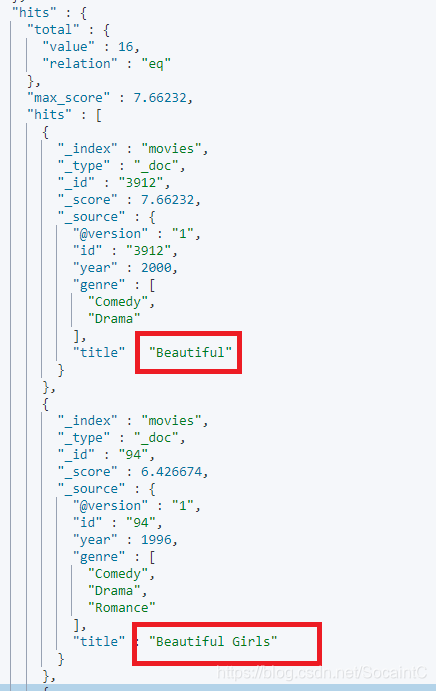
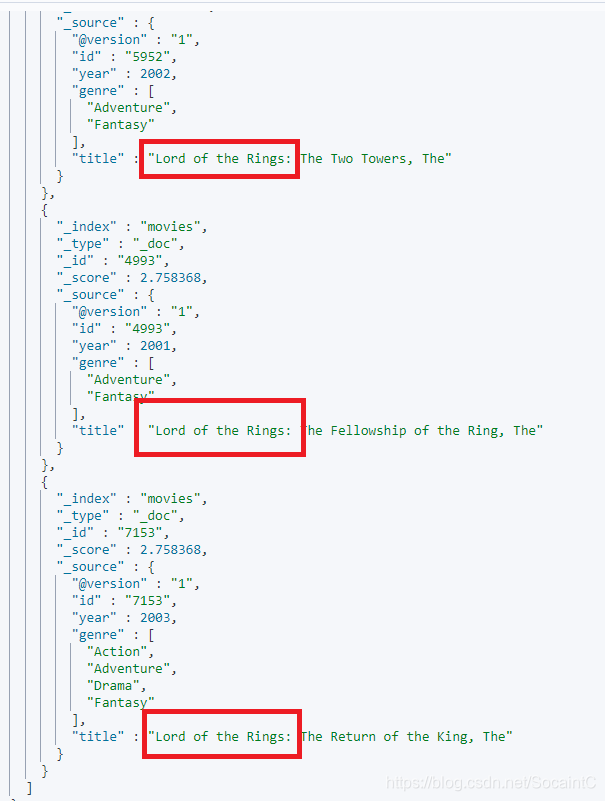
GET /movies/_search?q=title:"Lord Rings"~2
{
"profile": "true"
}
Request Body 和Query DSL
在elasticsearch中,一些高阶的使用方法只能通过Request Body Search实现
举例:
- 将查询语句通过 HTTP Request Body发送给Elasticsearch
- Query DSL
POST /movies,404_idx/_search?ignore_unavailable=true
{
"profile": "true",
"query": {
"match_all": {}
}
}
1.分页
可以在request body中加入from和size达到一个分页的效果
POST /kibana_sample_data_ecommerce/_search
{
"from": 10,
"size": 20,
"query": {
"match_all": {}
}
}
- from从10开始,默认返回10个结果
- 获取靠后的分页成本较高
2.排序
可在request请求中加入 sort 参数用于排序。
- 最好在“数字型”与“日期型”字段上排序
- 因为对于多值类型或分析过的字段排序,系统会选一个值,无法得知该值
GET kibana_sample_data_ecommerce/_search
{
"sort": [
{
"order_date": "desc"
}
],
"from": 10,
"size": 5,
"query": {
"match_all": {}
}
}
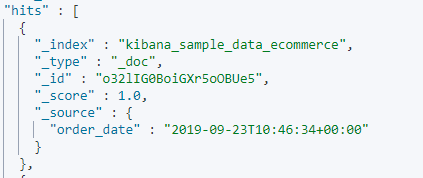
3._source filtering
比如说文档很大,很多类型的字段并不需要,那就可以在request中加入 _source 对查询字段进行过滤,加上你需要查询的字段信息即可。
- 如果
_source没有存储,那就只返回匹配的文档的元数据 _source只支持使用通配符_source["name*","desc*"]
GET kibana_sample_data_ecommerce/_search
{
"_source": ["order_date"],
"from": 10,
"size": 5,
"query": {
"match_all": {}
}
}
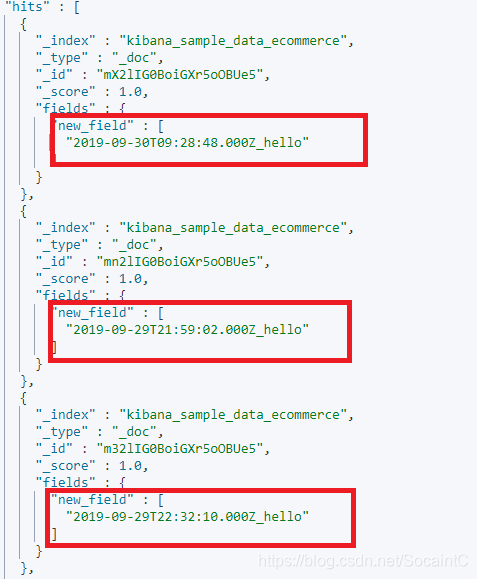
4.脚本字段
脚本字段就是可以用elasticsearch的 painless 脚本去计算出一个结果出来
- 例子:对order_date字段进行处理,加后缀_hello
GET kibana_sample_data_ecommerce/_search
{
"script_fields": {
"new_field": {
"script": {
"lang": "painless",
"source": "doc['order_date'].value+'_hello'"
}
}
},
"query": {
"match_all": {}
}
}
5.使用查询表达式-Match
在URI search有Term Search和Phrase Search,那的request body search中,是通过 query match 的方式进行实现的
例子:
# last OR christmas,类似于Term查询,match中填写字段:限定值
POST /movies/_search
{
"query":{
"match":{
"title":"Last Christams"
}
}
}
# last AND christmas,类似于phrase查询,在operator中指定
GET /movies/_search
{
"query":{
"match":{
"title": {
"query":"Last Christams",
"operator":"AND"
}
}
}
}
6.短语搜索-Match Phrase
在phrase查询中,query中的词必须是按照顺序出现的,才会有命中结果,slop=1代表query中间可以由1个其他的字符进去,进行模糊命中
GET /movies/_search
{
"query":{
"match_phrase":{
"title":{
"query":"one love",
"slop":1
}
}
}
}
[外链图片转存失败(img-FOXdGJ9K-1569432597842)(E:\学习\elasticSearch\ES2\Elasticsearch入门2.assets\match phrase.png)]
Query String & Simple Query String查询
1.Query String
在URI中是可以使用query string的,那同样在DSL中也支持query String的使用
2.Simple Query String Query
- 类似于Query String,但是会忽略错误的语法,同时只支持部分查询语法
- 不支持 AND OR NOT ,会当做字符串处理
- Term 之间默认的关系是OR,可以指定Operator
- 支持部分逻辑
+替代AND|替代OR-替代NOT
3.举例演示
# 插入用户1
PUT /users/_doc/1
{
"name":"Zhang San",
"about":"java,elasticsearch,product"
}
# 插入用户2
PUT /users/_doc/2
{
"name":"Li San",
"about":"python,golang"
}

总结
request body DSL中包含了很多非常高级强大的用法,更精彩的部分在接下来的提高文档中介绍。本篇主要是讲述了elasticsearch的search API,对URI search和Request Body DSL的操作,用法做了介绍。实操部分较多,还需多多练习















 1157
1157

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









