







AI时代,大模型对知识创作的冲击
AI时代,我们还需要写博客吗?(CSDN百万访问纪念文章)
不知不觉,从2016年1月2日学Python时我写第一篇csdn博客已经过去整整8个年头,我的博客也刚刚突破百万级别的访问量。作为一名工作内容主要围绕大模型能力的开发者,特此写一篇纪念文章,谈谈AI时代,大模型和博客等严重依赖人来编写的知识类内容创作的关系,以及目前大模型应用对知识创作的冲击和影响,也欢迎各位读者在评论区谈谈你的看法。
从Python开始的博客之路
2016年那会,我在上海的一所大学读计科,老师授课时跟我们吐槽:“国内的课程设计太过时了,啊,还在教C语言,国外早就开始教Python了”。彼时程序员圈子流行的梗还是“PHP世界上最好的语言”,但Python和Ruby的当时的讨论度确实很高。老师所言,自然激起了我的好奇心,于是就在网上百度Python的相关信息。
百度的查询结果来前几位自知乎,从知乎帖子里面我看到多位答主推荐一本《笨办法学Python》(适合非计算机背景,不适合科班),号称是Python的最佳入门书籍,于是我就靠着这本舶来品进入了Python的世界。在练习书中的程序时,有时候遇到问题,书中讲的并不是很详细,再度百度,查询结果来自CSDN,我经常靠着来自几篇不同博客拼凑起来的信息将问题解决,完成练习程序的编写。为了将学习这本书时练习的代码和解决的问题记录下来,我也开启了个人的CSDN博客之旅。
我个人认为互联网的核心精神有3个:创新、分享、普惠。AI由于跟互联网有着一脉相承的关系,也应该继承这些核心价值,为全人类创造一个更美好的未来。
创新不必多谈,分享即我为人人,人人为我的知识和其他资源的共享精神,这也是为什么可以通过百度检索到CSDN博客,解决Python编程问题的本源,普惠则是指互联网共享的知识和资源一般免费或者至少比现实世界的载体成本更低,也慢慢引申为共享单车、拼车、拼团等更加广义的普惠。
没有大模型之前,博客是程序员主要的知识来源,准确获取博客信息,靠的百度/Google这种基建级别的互联网设施搜索引擎。
从查博客到问模型
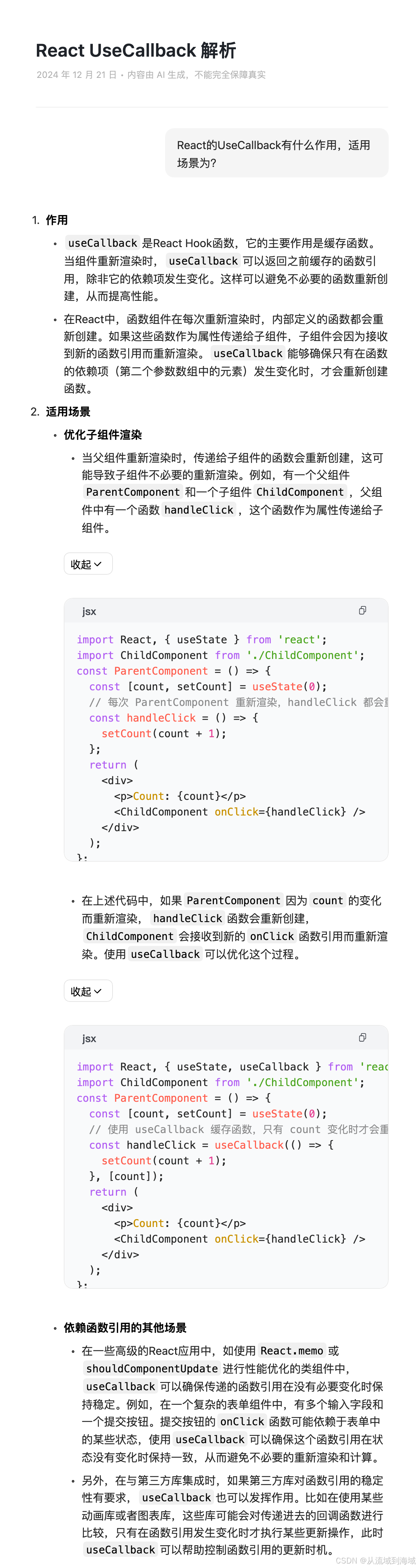
最近在开发内部智能平台时,为赶工期mentor拉了一个正儿八经的前端研发帮我加速,前端组老大表示临近年底,大家都很忙,我亲自来帮你们吧。感谢之余,我在事后认真看了一下大佬的代码,因为是比较简单的react项目,所以和工程原有的代码总体大差不差,唯一的一个明显差别是大佬的方法上全都包了一层UseCallBack。
于是我打开字节的大模型应用豆包PC端,问她“React的UseCallBack有什么作用,适用场景为?”。豆包给出了如下答复,精准且全面地回答了我的问题,而且贴心的给出了一小段代码示例。
https://www.doubao.com/thread/wef2f6a9b7d197c26
百度自己也在原有的检索结果列表之上添加了大模型回答,结果列表依然是和2016年一样的CSDN博客。

大模型时代,程序员有了另外一个选择,就是直接向大模型提问,直接得到技术问题的回复。
这个新选择,相比于一个博客一个博客看下来,从中找出自己需要的信息,效率显然是更高的。
AI从不生产内容,AI只是内容的搬运工 / 复读机
使用模型回答知识类问题,在AI领域不是新鲜事,我硕士实习那会做得就是KBQA(Knowledge-Based Question Answering)。但是像如今这么好的效果,一方面是海量数据超大参数规模的大模型,确实比那会的Bert更加强大,一方面则是由于RAG(检索增强生成)技术,使得模型能够以输入上下文的形式获取最新最准确最全面的信息,结合自身的语义能力,生成如上一节例子那般准确全面的回复内容。
大模型回答知识类问题,技术流程简化说明为以下:
也就是说,和我当年通过几篇CSDN博客找到问题答案一样,大模型也是先看了几篇博客,获取到问题相关的专业性知识之后,生成了准确全面的回复。从这个角度而言,AI是内容的搬运工。
加之,文本类大模型本身训练的时候就是靠着从互联网上获取到的大量文本信息(当然也包括博客)完成的,使用时通过预测下一个token来生成回复。从这个角度而言,AI是内容的复读机。
(关于大模型的基本原理我有一篇比较详细的博客:大模型基础知识 - 语言模型及其演进 公开版)
因而是先有了内容,再有了大模型,如果没有人类生成内容,则不会产生大模型,如果人类停止生产内容,那么大模型的知识则不会得到更新。
我的观点是创作是一件十分必要的事情,如果只有消费者,没有生产者,那么技术一样不会向前进步。只是AI的出现,让我们可以从低价值的内容生产中解放出来,去生产更高价值的内容。
目前大模型也只是能在垂直领域回答比较粗浅的问题,随着问题的深度增加,RAG检索不到相关的知识或者检索到了也无法很好的理解消化,模型并不能很好地回复具备一定思考深度的问题,这也是当前对话式大模型正在努力的方向。
粗浅内容将被大模型替代,我们需要更有深度的内容
作为一个新进百万访问博主,大家不妨看看我的博客文章列表,从随手一写的手记、粗浅的概念解释、某项技术的入门概念、课堂笔记、专门撰写的博客、翻译、论文解读、全英文博客等等应用仅有。你会发现一个现象,也是我对博客的一个基本认知:越是粗浅的内容,访问量越大,越是比较有深度的内容,访问量越小。
这也符合常理,一个领域刚入门的新人体量肯定比专家大,大部分人的需求就是粗浅的内容,少部分专家才需要更有深度的内容。
所以即使大模型仅能回复粗浅问题,已经能够解决大部分头部问题了。
这对于博主而言,看上去不是好事情,高ROI的粗浅内容创作,马上就要被AI取代了,越来越多的人会转向问大模型,而不是通过搜索引擎查到博客,再一个一个看下去。这对于读者而言,毋庸置疑是好事情,信息获取的成本变低了,效率变高了。
总体来看,我觉得是好事情,所有粗浅问题得到了大模型的高效解答,那么程序员总体的技术水平得到了提高,总体水平提高之后,大家开始问有深度的问题,这时候大模型歇菜,再度打开搜索引擎,期待着某篇CSDN博客能恰好给出回答,但结果不尽人意,只能通过好几篇博客拼凑出来的信息再加上自己的思考得出答案。
我们不如就把粗浅内容的赛道让给模型,投入深度内容的创作中,这其实也就是社会进步的过程。
劣质内容将被大模型替代,我们需要更多优质的内容
另外博客也存在一些问题,博客没有报刊或者书籍的审校机制,门槛很低,所以存在一部分博客是爬虫爬的,文字格式混乱,一部分博客质量不佳,难以阅读,一部分博客介绍的内容并不完全正确,等等。
也就是劣质内容的问题,不过这个问题大模型也一样,一旦RAG检索到的结果不够优质,那么大模型的回复也很难优质。
大模型对粗浅问题的回复,质量还是不错的,优于一些劣质博客,这部分劣质博客一定会越来越没有市场。
因而无论想看到更优质的内容,还是想要有更优质的大模型,都不能停下创作的脚步。
乐观看待变化
我对AI的发展持比较乐观的态度,任何社会的发展都是落后的生产力被先进的生产力淘汰,大模型对知识创作的冲击也是如此。你做的事情越来越有深度,同时也因为大模型的帮衬,做更有深度的事情变得越来越简单,这意味着付出同样的精力你做的事情价值越来越高,也意味着你的价值越来越高,整个社会的价值越来越高。
这也就是我所理解的,大模型赋能人类。
不必考虑先有鸡还是先有蛋,大胆创作更优质更有深度的内容,与这个世界分享你的知识和见识吧。如果没有新内容产生,也不会有更强的大模型或者未来更新的AI技术造福我们的社会。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









