






目录
4.2.1、 Local Variable Table——局部变量表,相当于寄存器
4.5.Native Method Stack--本地方法栈
5.2.1 标记清除(mark sweep) - 位置不连续 产生碎片 效率偏低(两遍扫描)
5.2.2 拷贝算法 (copying) - 没有碎片,浪费空间
5.2.3标记压缩(mark compact) - 没有碎片,效率偏低(两遍扫描,指针需要调整)
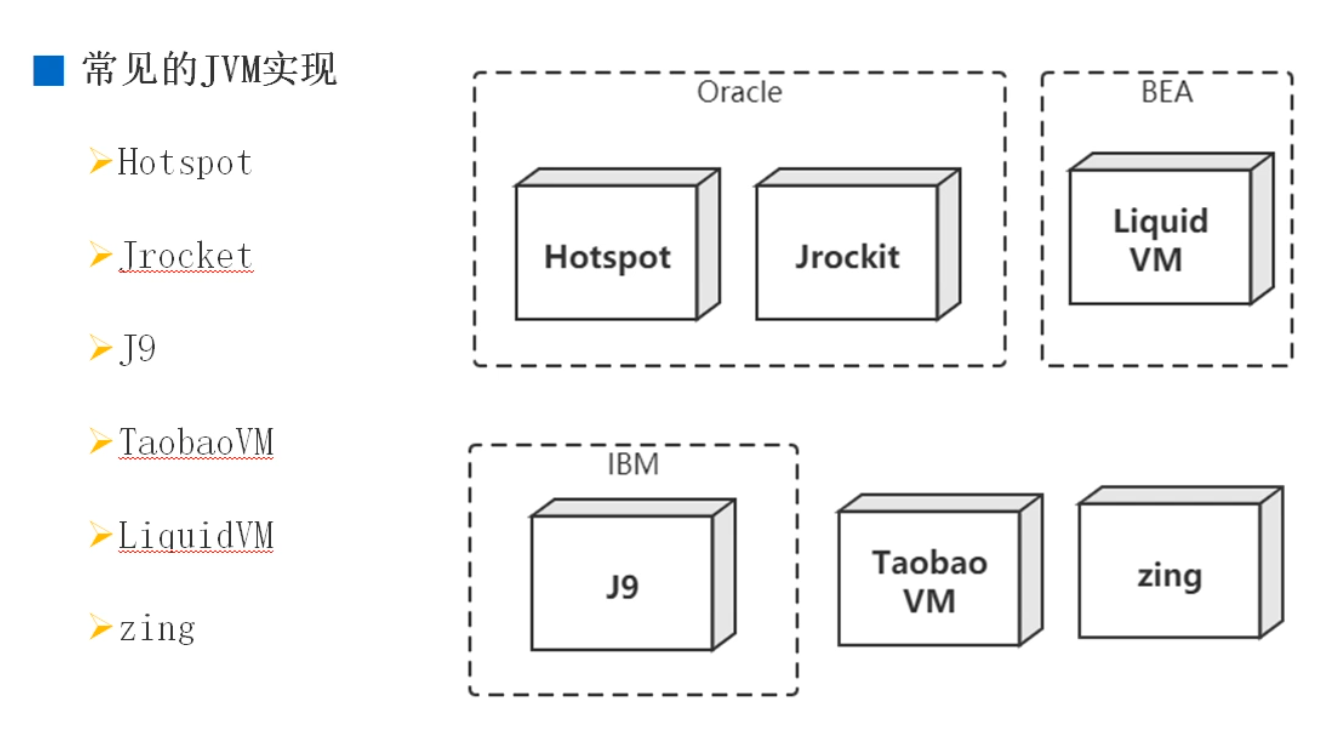
1.常见JVM实现
Hotspot:目前使用的最多的 Java 虚拟机。
Jrocket:原来属于BEA 公司,曾号称世界上最快的 JVM,后被 Oracle 公司收购,合并于 Hotspot
J9: IBM 有自己的 java 虚拟机实现,它的名字叫做 J9. 主要是用在 IBM 产品(IBM WebSphere 和 IBM 的 AIX 平台上)
TaobaoVM: 只有一定体量、一定规模的厂商才会开发自己的虚拟机,比如淘宝有自己的 VM,它实际上是 Hotspot 的定制版,专门为淘宝准备的,阿里、天 猫都是用的这款虚拟机。
LiquidVM: 它是一个针对硬件的虚拟机,它下面是没有操作系统的(不是 Linux 也不是 windows),下面直接就是硬件,运行效率比较高。
zing: 它属于 zual 这家公司,非常牛,是一个商业产品,很贵!它的垃圾回收速度非常快(1 毫秒之内),是业界标杆。它的一个垃圾回收的算法后来被 Hotspot 吸收才有了现在的 ZGC。

2.Class文件格式


![]()
3.类编译-加载-初始化

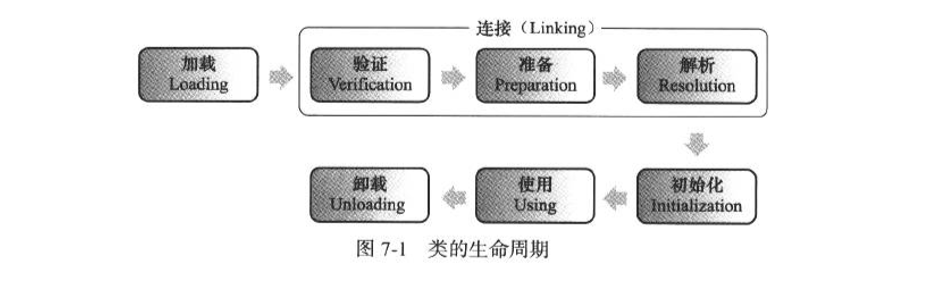
加载:在加载阶段,虚拟机只需要完成下面三件事
通过类的全限定名来获取定义此类的二进制流。
java虚拟机并没有规定从哪加载二进制流,可以是压缩包中,可从网络中,可用从数据库中,也可以是计算机运算生成(动态代理产生的代理类)等。
将这个字节流所代表的静态存储结构转化为方法区的运行时数据结构。
虚拟机外部的二进制字节流就按照虚拟机所需的格式存储在方法区中,方法区中的数据存储格式由虚拟机实现自定义。
在内存中生成一个代表这个类的java.lang.Class对象,作为方法区这个类的各种数据的访问入口。
这里并没有规定存在java堆中,在HotSpot中它是存储在方法区里面。
验证:验证是连接阶段的第一步,这一阶段的目的是为了确保Class文件的字节流中包含的信息符合当前虚拟机的要求,并且不会危害到自身的安全
验证大致会分为4个阶段的校验动作:
文件格式验证:主要验证字节流是否符合Class文件的规范,并且能够被当前版本的虚拟机处理等。该阶段的验证主要是保证输入的自己流能够正确的解析并且存储于方法区之内。只有通过了验证后,字节流才会进入内存的方法区中进行存储。
元数据验证:对字节码描述的信息进行语义分析,以保证描述的信息符合java语言规范的要求。
字节码验证:主要的目的是通过对数据流和控制流分析,确定程序语义是合法的、符合逻辑的。确保被验证的类不会危害虚拟机的安全。
符号引用验证:这个阶段发生在虚拟机将符号引用转化为直接引用的时候,这个转化动作将在连接的第三阶段-----解析中发生。符号引用验证可以看作对类自身以外的信息进行匹配校验。
准备:正式为类变量(静态变量)分配初始内存并设置初始值(并不是代码的初始赋值)的阶段,这些变量所使用的内存都将在方法区中进行分配。如果是常量则直接分配为常量值。
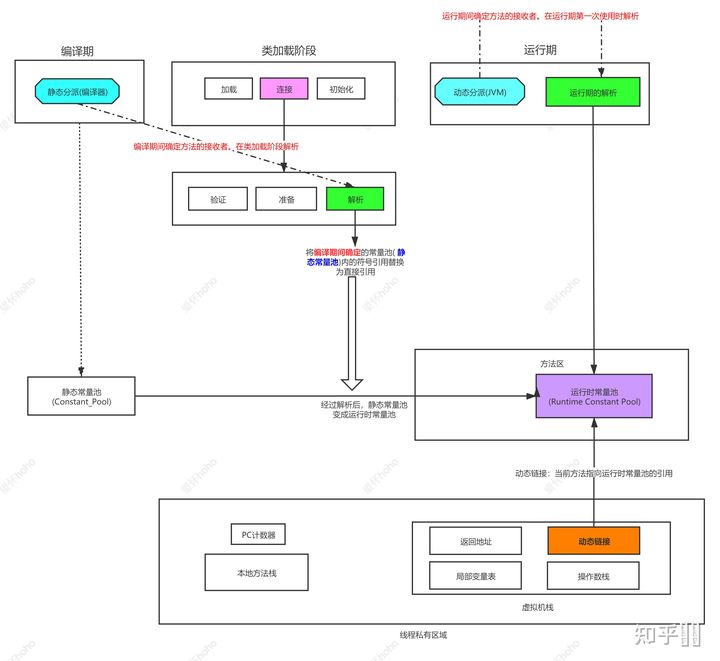
解析:将虚拟机中常量池内的符号引用替换为直接引用的过程。
符号引用:符号引用以一组符号来描述所引用的目标,符号可以是任何形式的字面量,只要使用时能够无歧义定位到目标即可。
直接引用:直接引用可以是直接指向目标的指针、相对偏移量或是一个能间接定位到目标的句柄。
初始化:初始化是类加载的最后一步,前面的类加载的过程中,除了在加载阶段用户应用程序可以通过自定义类加载器参与外,其余动作完全由虚拟机主导和控制。到了初始化阶段,才真正开始执行类中定义的java程序代码。

protected Class<?> findClass(String name) throws ClassNotFoundException {
File f = new File("c:/test/", name.replace(".", "/").concat(".class"));
try {
FileInputStream fis = new FileInputStream(f);
ByteArrayOutputStream baos = new ByteArrayOutputStream();
int b = 0;
while ((b=fis.read()) !=0) {
baos.write(b);
}
byte[] bytes = baos.toByteArray();
baos.close();
fis.close();//可以写的更加严谨
return defineClass(name, bytes, 0, bytes.length);
} catch (Exception e) {
e.printStackTrace();
}
return super.findClass(name); //throws ClassNotFoundException
}- load - 默认值 - 初始值
- new - 申请内存 - 默认值 - 初始值
4.Runtime Data Area 运行时数据区
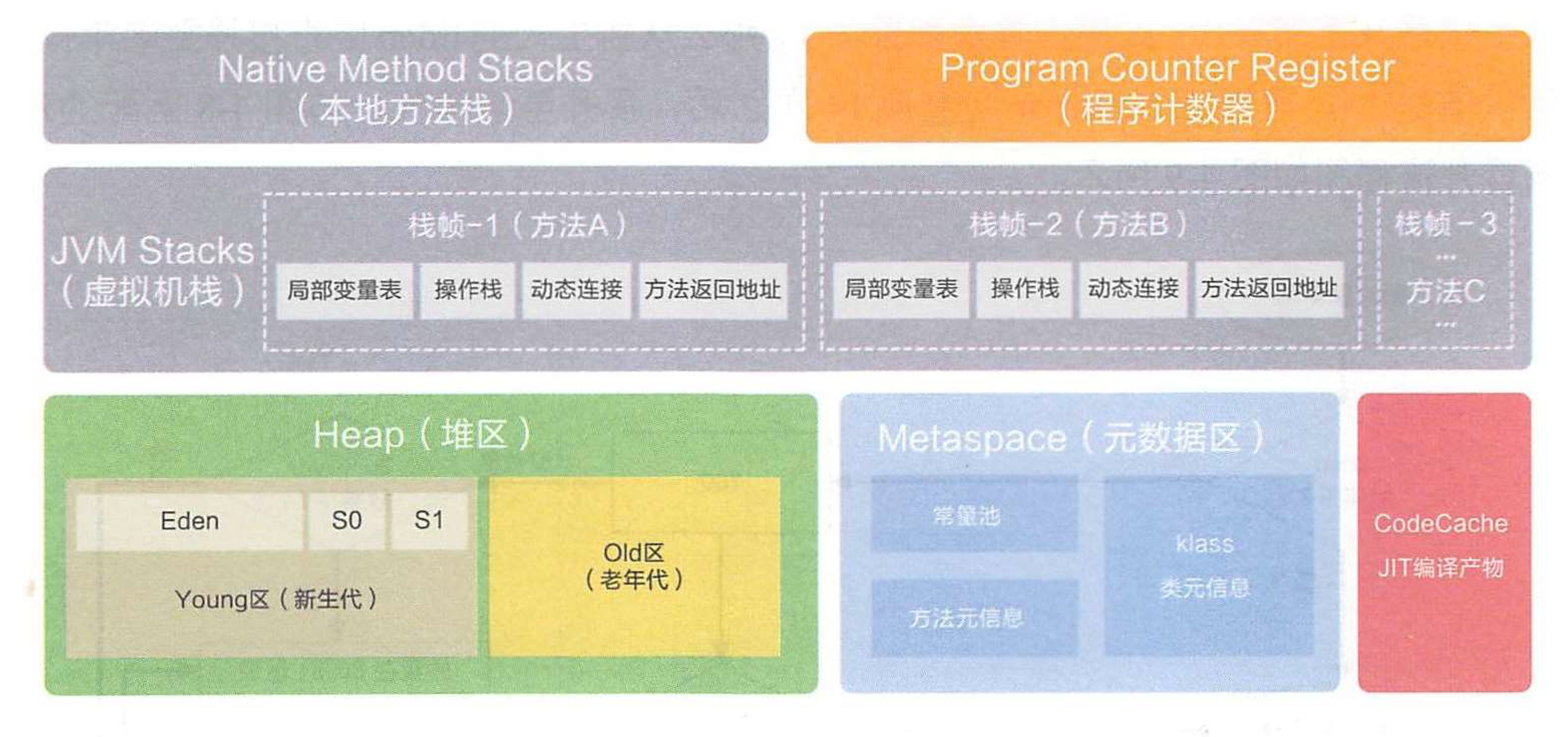
4.1.PC 程序计数器
程序计数器(Program Counter Register)是一块较小的内存空间,它可以看作是当前线程所执行的字节码的行号指示器
字节码解释器工作时就是通过改变这个计数器的值来选取下一条需要执行的字节码指令,它是程序控制流的指示器,分支、循环、跳转、异常处理线程恢复等基础功能都需要依赖此程序计数器来完成
CPU是多线程切换的执行机制,为了保证线程切换后能恢复到正确的执行位置,每个线程都需要独立拥有一个程序计数器,各个线程间的计数器互不影响,独立存储,我们称这类内存是“线程私有的内存”
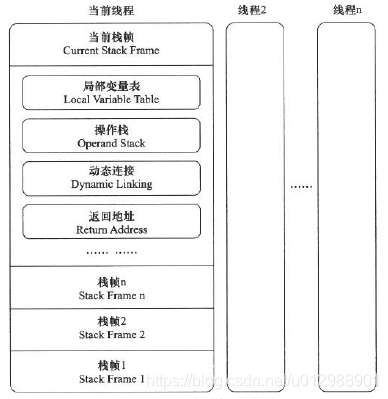
4.2.Java虚拟机栈——JVM Stack
虚拟机栈描述的是Java方法执行的线程内存模型:每个方法被执行的时候,Java虚拟机都会创建一个栈帧(Stack Frame),用于存储局部变量表、操作数栈、动态连接、方法出口等信息
每个线程对应着一个JVM Stack,线程中的每一个方法对应着一个 Stack Frame。
方法从被调用到执行完毕的过程,就对应着一个个栈帧在虚拟机栈(JVM Stack)中从入栈到出栈的过程
栈帧——Stack Frame包含如下内容:
- Local Variable Table
- Operand Stack
- Dynamic Linking
- return address
4.2.1、 Local Variable Table——局部变量表,相当于寄存器
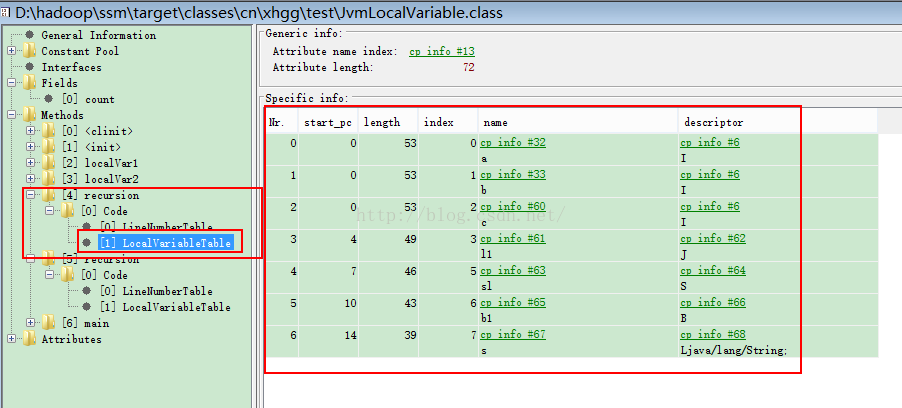
局部变量表(Local Variable Table)是一组变量值存储空间,用于存放方法参数和方法内部定义的局部变量。在Java程序编译为Class文件时就在方法的code属性的max_locals数据项中确定了该方法所需要分配的局部变量表的最大容量。
下面展示class字节码中的局部变量表的内容:
4.2.2.Operand Stack——操作数栈
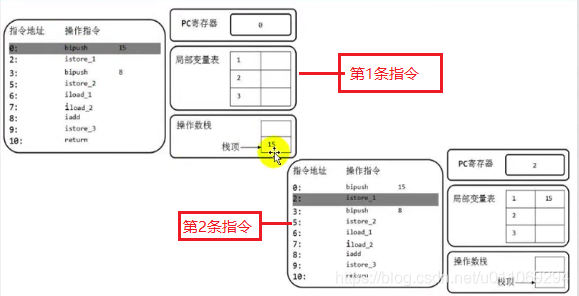
例如,在做算术运算的时候是通过操作数栈来进行的,又或者在调用其他方法的时候是通过操作数栈来进行参数传递的。举个例子,整数加法的字节码指令iadd在运行的时候操作数栈中最接近栈顶的两个元素已经存入了两个int型的数值,当执行这个指令时,会将这两个int值出栈并相加,然后将相加的结果入栈。
Java虚拟机的解释执行引擎称为“基于栈的执行引擎”,其中所指的“栈”就是操作数栈。如果当前线程请求的栈深度大于虚拟机所允许的最大深度,将抛出StackOverflowError异常。
4.2.3.Dynamic Linking——动态连接
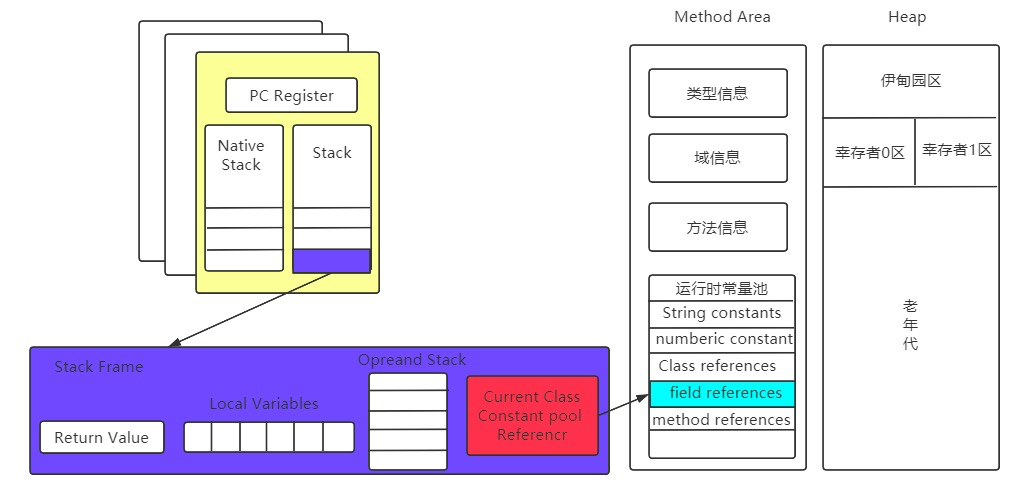
动态链接主要就是指向运行时常量池的方法引用
每一个栈帧内存都包含一个指向运行时常量池中该栈帧所属方法的引用,包含这个引用的目的就是为了支持当前方法的代码能够实现动态链接(Dynamic Linking)
4.2.4.return address——方法返回地址
在方法退出之后,都必须返回到最初方法被调用时的位置,程序才能继续运行,方法返回时可能需要在栈帧中保存一些信息,用来帮助恢复它的上层主调方法的执行状态
4.3.方法区——Method Area
1、JDK1.8之前,方法区实现为Perm Space,即永久区
- 字符串常量位于PermSpace
- FGC不会清理
- 大小启动的时候指定,运行之后不能改变,经常会产生内存溢出线程
2、JDK1.8之后,方法区实现的名称为Meta Space,即元数据区
- 字符串常量位于堆,不再放在Method Space
- 会触发FGC清理
- 如果不设定的话,最大就是物理内存,也可以指定大小,满了之后就会触发FGC
Runtime Constant Pool——运行时常量池,是方法区的一部分
我们在前面的学习中知道Class文件结构中有一项信息是常量池表(存放编译器生成的字面量和符号引用(静态概念)),在运行之后(动态概念),这部分内容在类加载完成之后存放到方法区的运行时常量池中。
4.4.Heap-堆
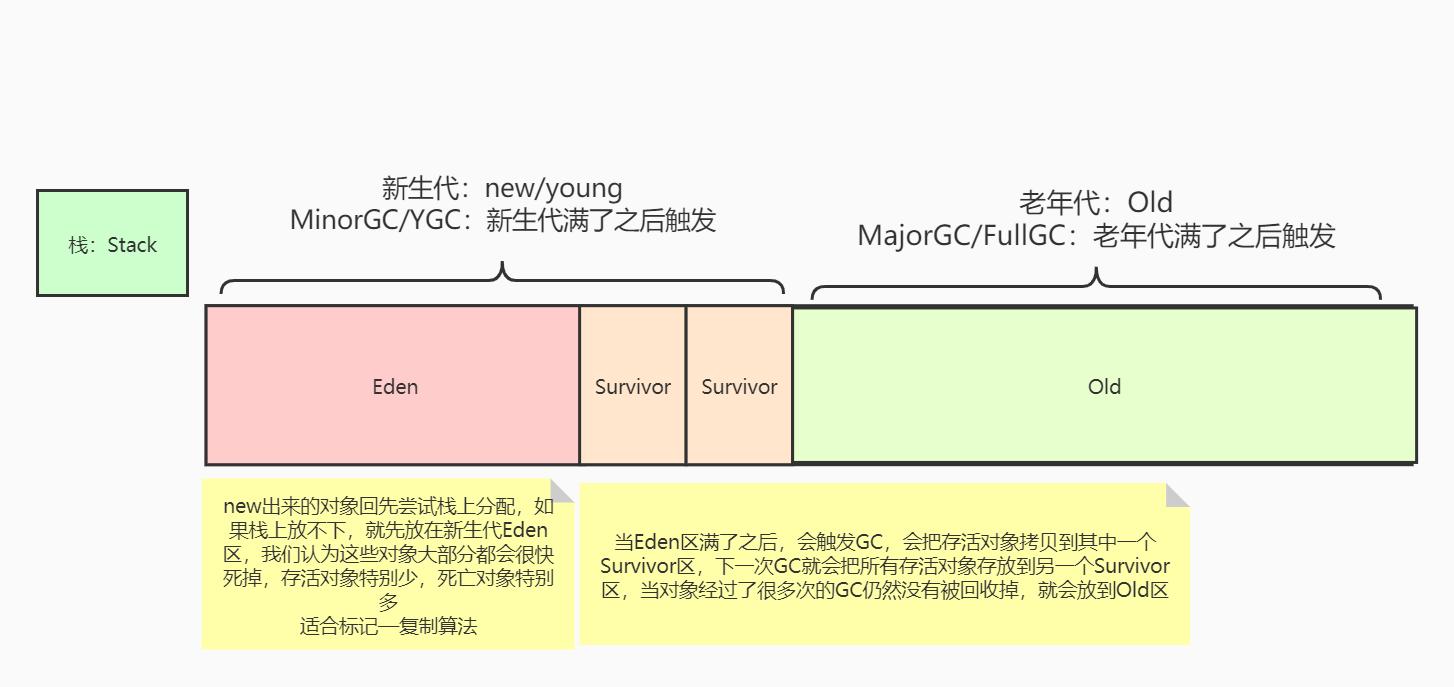
对于Java应用程序来说,Java堆(Heap)是虚拟机所管理的内存中最大的一块,被所有线程共享的一块内存区域,在虚拟机启动时创建。此内存区域的唯一目的就是为了存放对象实例,在Java中“几乎”所有的对象实例都在这里分配内存
Java堆是垃圾收集器管理(GC)的内存区域,因此也被称为“GC堆”。从回收内存的角度看,由于业界绝对主流的Hotspot虚拟机垃圾收集器全部都是基于分代收集理论,所以 ** Java堆经常被表述分为“新生代”、“老年代”、“Eden区” **等名词
由于Heap是所有线程共享的,当高并发情况下,可能有多个线程同时想要使用同一内存块,造成线程争用,效率变低。所以从分配内存的角度看,所有线程共享的Heap内存(更细节来说其实是Heap中的Eden区)中可以划分出每个线程私有的分配缓冲区(Thread Local Allocation Buffer,简称TLAB),减少线程争用,以提升对象分配时的效率
无论如何划分,都不会改变Java堆中存储内容的共性——无论哪个区域,存储的都只能是对象的实例,将Java堆细分的目的只是为了GC(垃圾收集器)更好的回收内存,以及更快的分配内存
4.5.Native Method Stack--本地方法栈
JVM自动管理,虚拟机栈为虚拟机执行Java方法(也就是字节码)服务,而本地方法栈则是为虚拟机使用到的本地(Native)方法服务。
4.6.Direct Memory--直接内存
为了增加IO效率,在JDK1.4之后增加了直接内存(Direct Memory),实现了从JVM内部能够直接访问操作系统管理的内存,即用户空间能够直接访问内核空间。NIO , 提高效率,实现zero copy
5.GC-垃圾回收
5.1 如何定位垃圾
5.1.2 引用计数(ReferenceCount)
很难解决对象之间相互循环引用的问题
5.1.3 根可达算法(RootSearching)

5.2 常见的垃圾回收算法
5.2.1 标记清除(mark sweep) - 位置不连续 产生碎片 效率偏低(两遍扫描)

算法简单,适合存活对象较多
5.2.2 拷贝算法 (copying) - 没有碎片,浪费空间

5.2.3标记压缩(mark compact) - 没有碎片,效率偏低(两遍扫描,指针需要调整)

5.3 JVM内存分代模型(用于分代垃圾回收算法)

部分垃圾回收器使用的模型
除Epsilon ZGC Shenandoah之外的GC都是使用逻辑分代模型
G1是逻辑分代,物理不分代
除此之外不仅逻辑分代,而且物理分代
5.4 常见的垃圾回收器

5.4.1 常见组合
Serial+SerialOld ; ParNew+CMS ; ParallelScavenge+ParallelOld (1.8默认)
5.4.2 垃圾收集器的分类
串行收集器(serial collector)只有一条GC线程,在运行是会暂停用户程序(stop the world)

并行收集器(parallel collector)有多条GC线程,也需要暂停用户程序
并发收集器(concurrent collector)有一条或多条GC线程,需要在部分阶段暂停用户程序
5.4.3 垃圾回收器种类
1.Serial (用于新生代,采用复制算法)(串行收集器)
2.Serial Old(用于老年代,采用标记整理算法)(串行收集器)
3.Parallel Old(用于老年代,采用标记整理算法)(并行收集器)
4.Parallel Scavenge(用新生代,采用复制算法)(并行收集器)
5.ParNew(用于新生代,采用复制算法)(并行收集器)
6.CMS(用于老年代,采用标记清除算法)(并发收集器) (问题:内存碎片化、出发SerialOld清理,串行很耗时;–XX:CMSInitiatingOccupancyFraction 92% 可以降低这个值,让CMS保持老年代足够的空间)
7.G1(10ms) (jdk1.7以后的版本推出的,维持高回收率,减少停顿,类似于concurrenthashmap的分区概念) MixedGC (java9默认gc算法是G1,且把CMS标记为废弃)三色标记 + SATB (扫描变少)
8.ZGC (1ms) PK C++ 算法:ColoredPointers + LoadBarrier
9.Shenandoah 算法:ColoredPointers + WriteBarrier
10.Eplison
5.4.4 垃圾收集器跟内存大小的关系
Serial 几十兆
PS 上百兆 - 几个G
CMS - 20G
G1 - 上百G
ZGC - 4T - 16T(JDK13)
6.JVM调优
设定日志参数
-Xloggc:/opt/xxx/logs/xxx-xxx-gc-%t.log -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=5 -XX:GCLogFileSize=20M -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintGCCause
系统CPU经常100%,如何调优?(面试高频) CPU100%那么一定有线程在占用系统资源,
找出哪个进程cpu高(top)
该进程中的哪个线程cpu高(top -Hp)
导出该线程的堆栈 (jstack)
查找哪个方法(栈帧)消耗时间 (jstack)
工作线程占比高 | 垃圾回收线程占比高
系统内存飙高,如何查找问题?
导出堆内存 (jmap)
分析 (jhat jvisualvm mat jprofiler ... )
如何监控JVM
jstat jvisualvm jprofiler arthas top...
arthas在线排查工具
- 为什么需要在线排查? 在生产上我们经常会碰到一些不好排查的问题,例如线程安全问题,用最简单的threaddump或者heapdump不好查到问题原因。为了排查这些问题,有时我们会临时加一些日志,比如在一些关键的函数里打印出入参,然后重新打包发布,如果打了日志还是没找到问题,继续加日志,重新打包发布。对于上线流程复杂而且审核比较严的公司,从改代码到上线需要层层的流转,会大大影响问题排查的进度。
- jvm观察jvm信息
- thread定位线程问题
- dashboard 观察系统情况
- heapdump + jhat分析
- jad反编译 动态代理生成类的问题定位 第三方的类(观察代码) 版本问题(确定自己最新提交的版本是不是被使用)
- redefine 热替换 目前有些限制条件:只能改方法实现(方法已经运行完成),不能改方法名, 不能改属性 m() -> mm()
- sc - search class
- watch - watch method
- 没有包含的功能:jmap















 3127
3127











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









