






基于SpringBoot+Vue2的大数据职业能力分析平台
这是我们实习期间小组完成的小项目。前端和后端分开上传在两个github中。
前端部分链接:GitHub - Seeking-L/CareerCraftHub-Vue2: CareerCraftHub,2023-2024冬季小学期,小组项目的前端页面部分(Vue2)
记得点Star!!!
我们项目大致可以分成三个部分:
- python部分
- 前端Vue2
- 后端SpringBoot + MyBatis + MySQL
项目开发时我们经验不足,平时学校比较注重理论,所以我们的项目有很多不足之处。
我们的python部分是用Java来调用的,并没有做到实时分析。
我们前端的大数据展示部分其实很多都是抄了CSDN上其他博主的代码。
表面上说是大数据其实数据大概只有几千。。
代码中有一些小bug,因为时间关系没有来得及修复。但是能跑ε=ε=ε=( ̄▽ ̄)
我在项目中负责主要的后端开发和一小部分python爬虫o( ̄▽ ̄)ブ
一、模块介绍
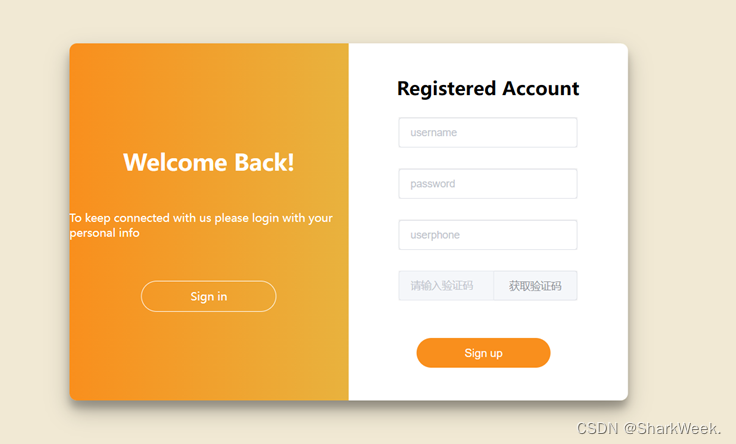
1.1 注册模块
输入用户名、密码、手机号,点击获取验证码,输入验证码完成注册。
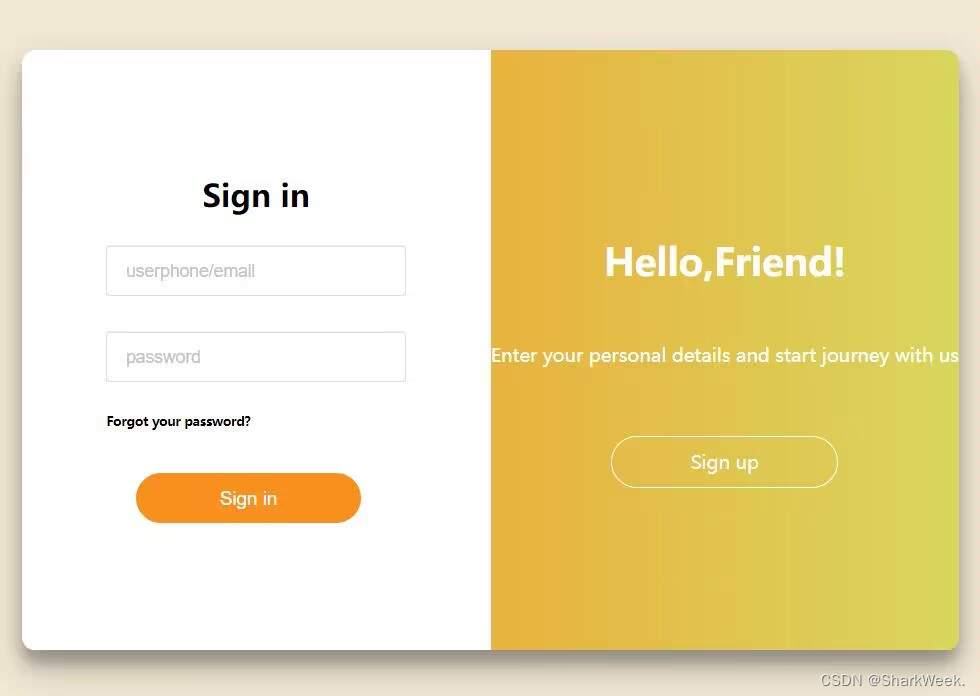
1.2 登录模块
输入已注册的手机号和密码,即可登录。
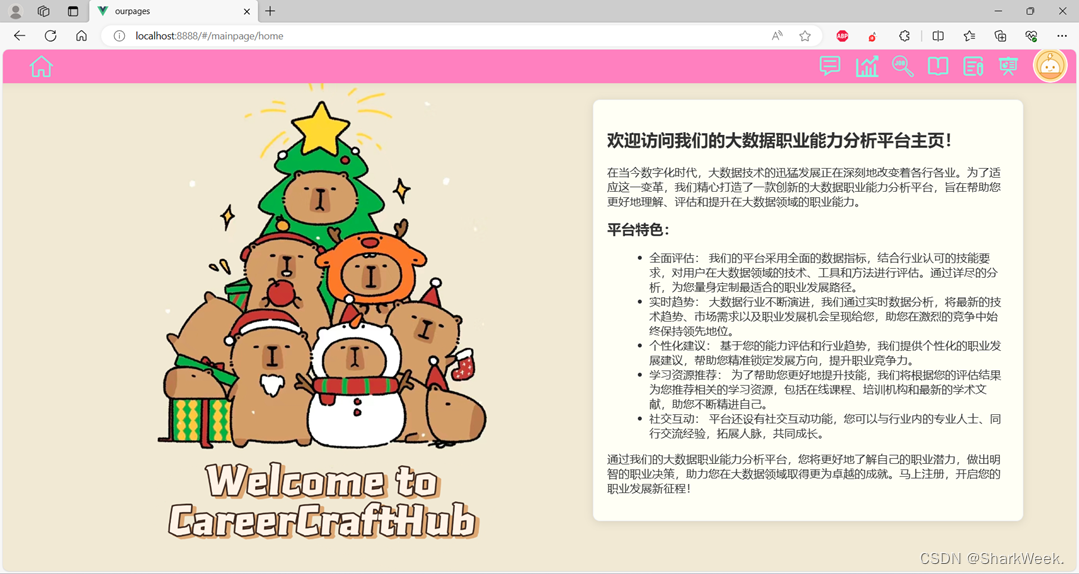
1.3 首页
欢迎语、简介。(其实是GPT生成的)
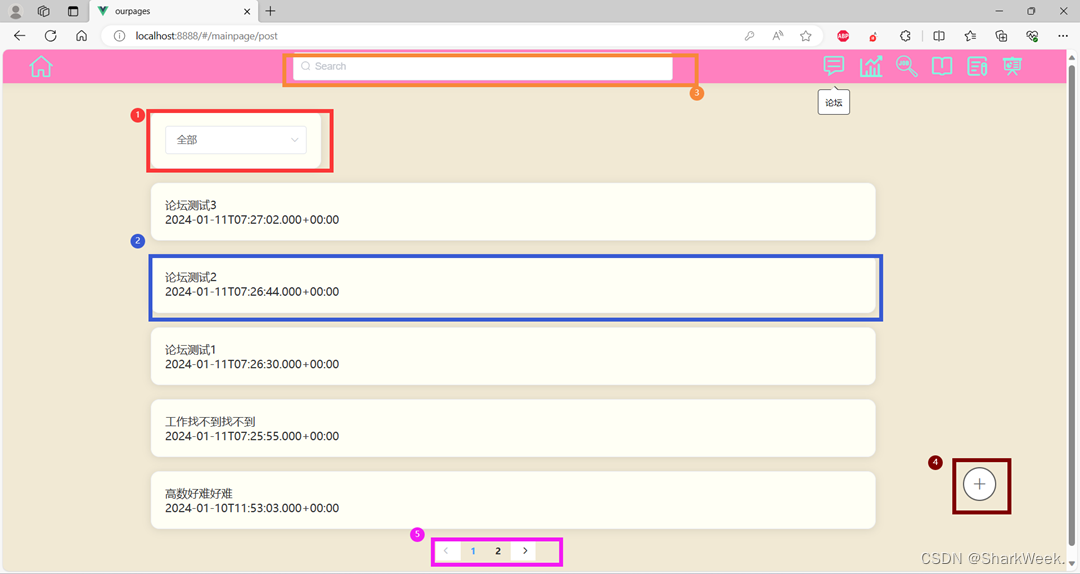
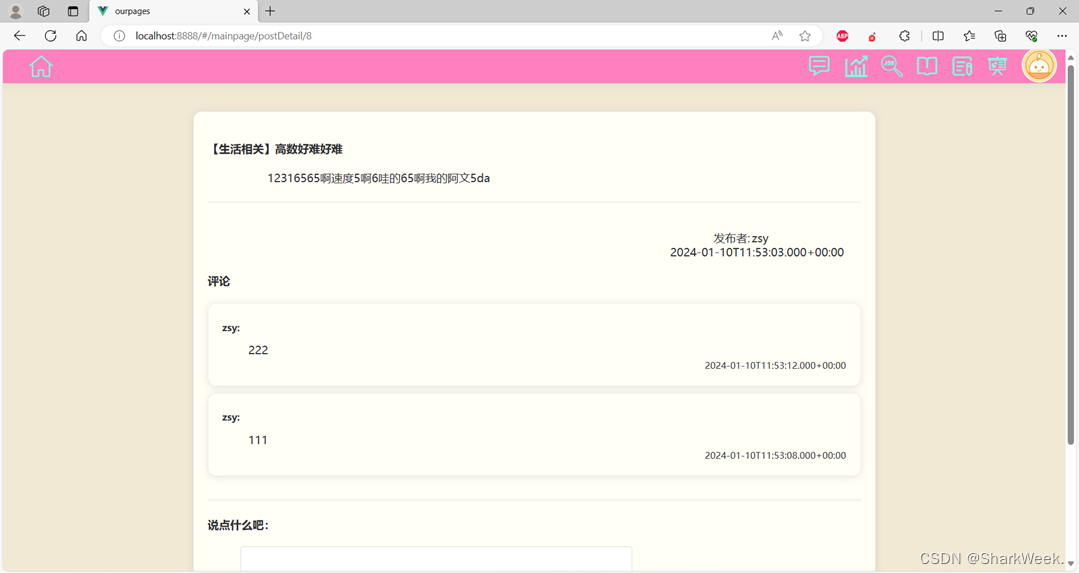
1.4 论坛模块
实现分类搜索、帖子展示、关键词检索、发布新帖子、翻页功能。
1.5 统计模块
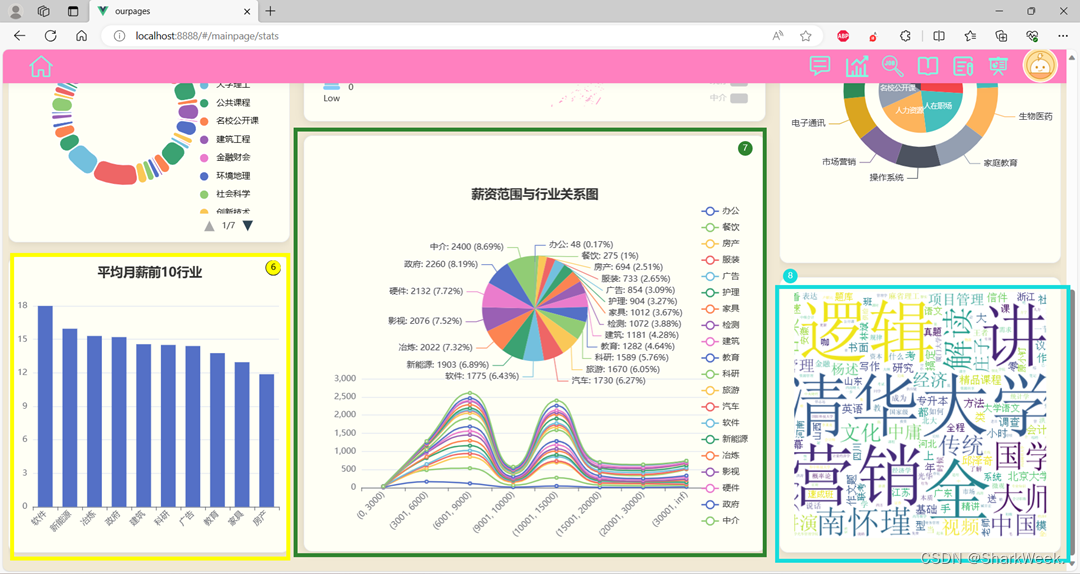
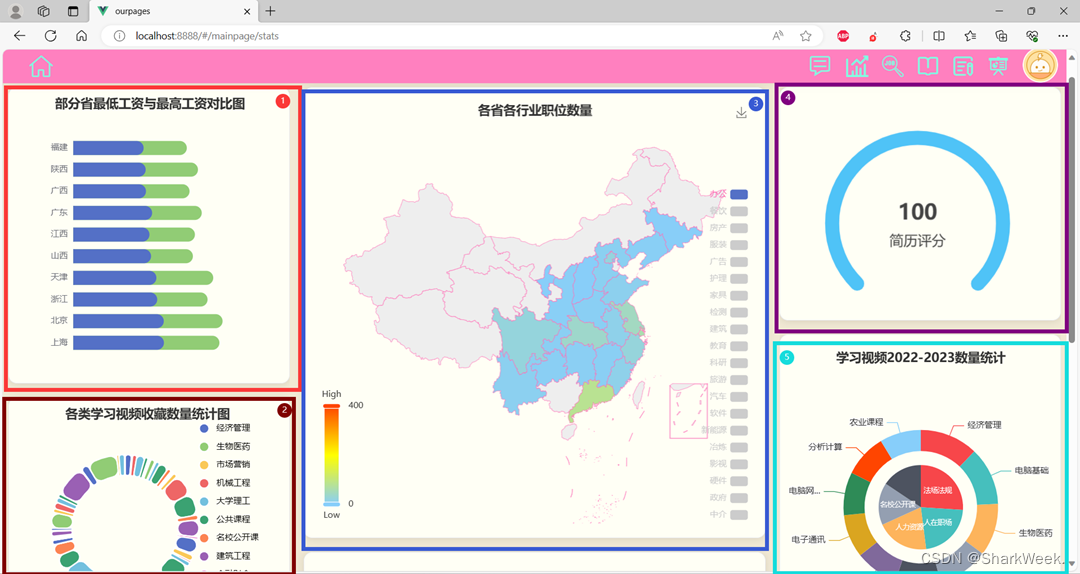
分析并展示部分省最低工资与最高工资对比图、各类学习视频收藏数量统计图、各省各行业职位数量大地图、个人简历评分、学习视频2022-2023数量统计图、平均月薪前10行业柱状图薪资范围与行业关系图、学习资料标题词云图。
1.6 工作模块
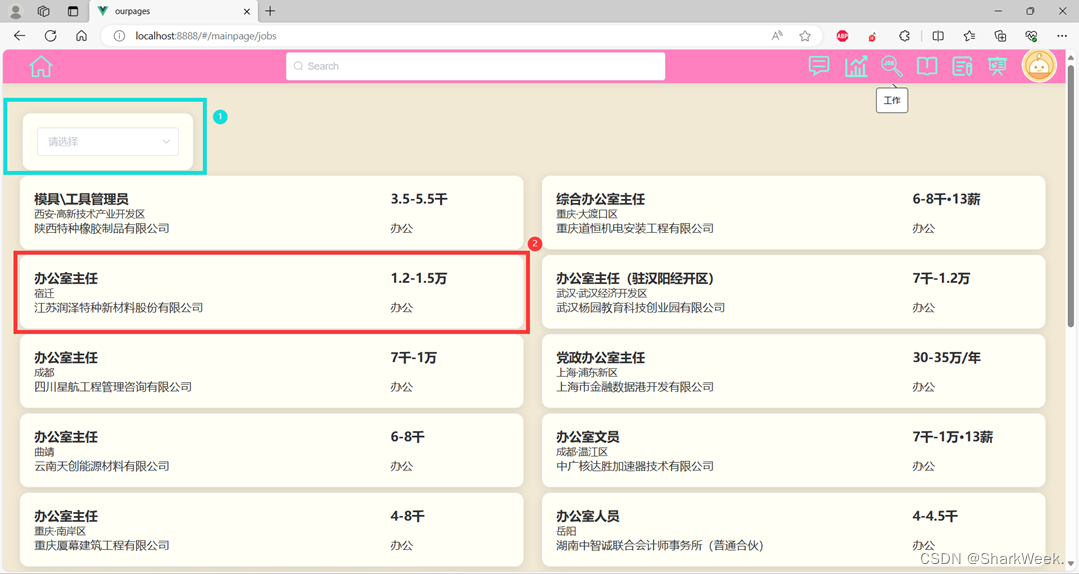
实现不同行业工作分类展示、求职页面跳转、关键词检索。
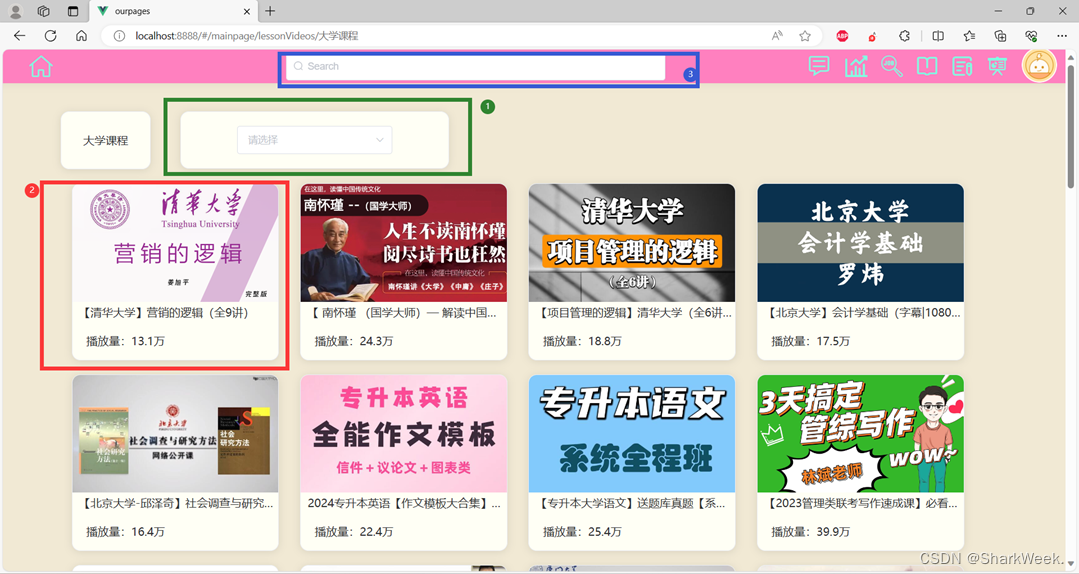
1.7 学习资料模块
记得点Star!!!
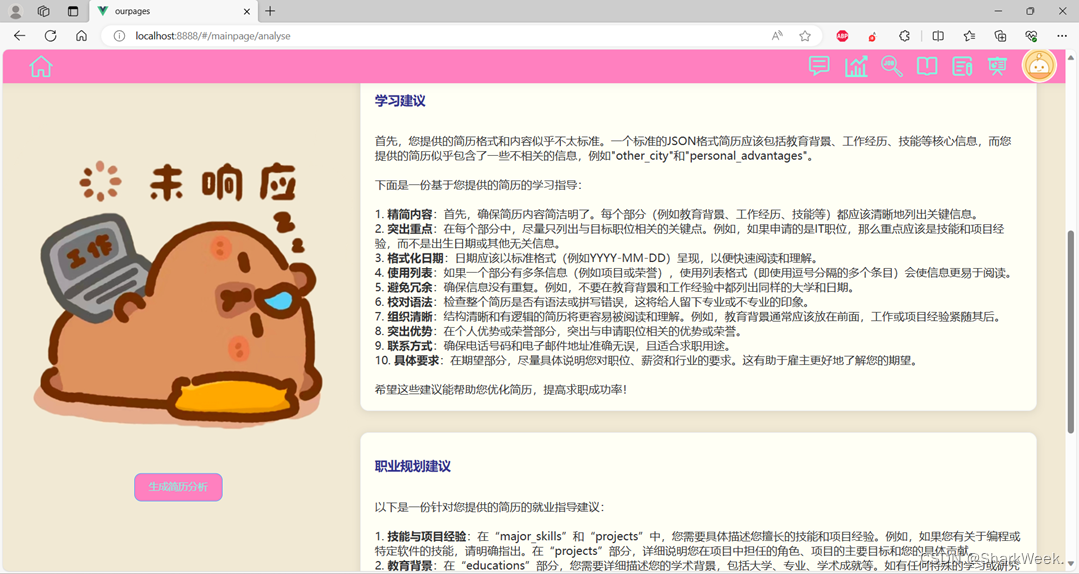
1.8 简历解析模块
利用大模型对用户简历进行分析,提供用户简历评价、学习建议、职业规划建议。
(其实是调用文心一言)
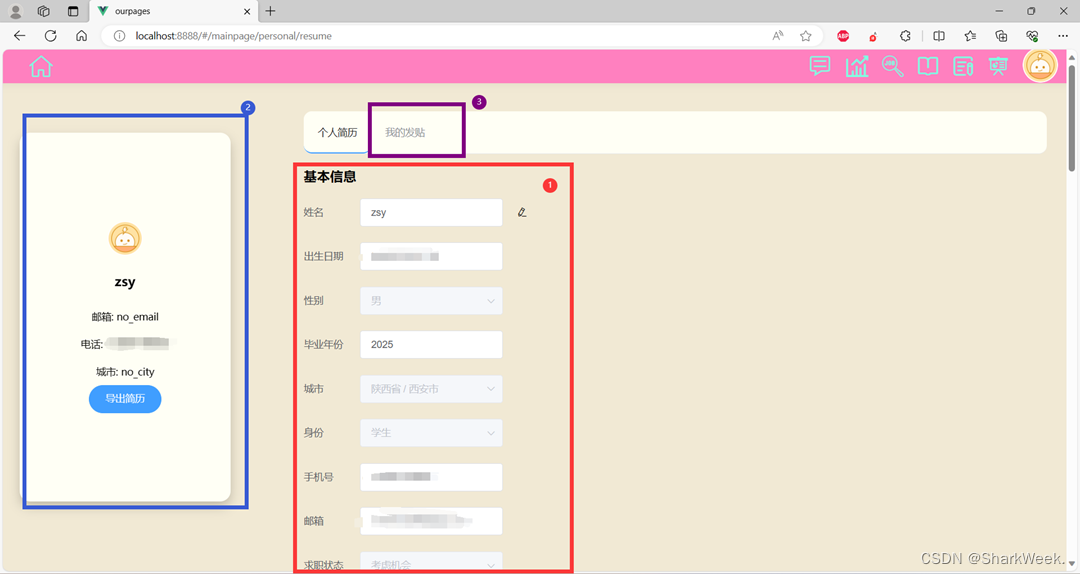
1.9 用户主页模块
提供个人简历修改、导出个人简历pdf文件、发帖记录功能。
记得点Star!!!
二、Python部分
用Python的代码有:
- 爬虫
- 调用文心一言
- 生成pdf简历
记得点Star!!!
2.1 爬虫
下面是岗位内容的爬取部分代码:
# Selenium模块是一个自动化测试工具,能够驱动浏览器模拟人的操作,如单击、键盘输入等。
from selenium import webdriver
from selenium.common import TimeoutException
from selenium.webdriver.common.by import By
import re
import pandas as pd
import time
import random
from bs4 import BeautifulSoup
# 从获取的网页源代码中提取目标数据
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
# 提取中文字符
def is_slider_container_present(driver):
try:
# 查找滑块容器
slider_container = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, 'nocaptcha')) # 这里使用 ID 选择器,你也可以根据需要修改选择器
)
return True
except TimeoutException:
# 如果滑块容器不存在,捕获 TimeoutException 异常并返回 False
return False
def handle_slider_verification(driver):
try:
# TODO: 添加处理滑块验证的代码,模拟拖动滑块的动作
# 例如,找到滑块元素,使用 ActionChains 模拟拖动,等待页面加载等操作
# 示例:等待滑块元素可见
slider = WebDriverWait(driver, 5).until(EC.visibility_of_element_located((By.XPATH, '//*[@id="nc_1_n1z"]')))
#//*[@id="nc_1__scale_text"]/span
action = ActionChains(driver)
action.click_and_hold(slider).move_by_offset(300, 0).release().perform()
driver.implicitly_wait(5)
except TimeoutException:
return
def translate(str):
line = str.strip() # 处理前进行相关的处理,包括转换成Unicode等
pattern = re.compile('[^\u4e00-\u9fa50-9\u003a\u0041-\u005a\u0061-\u007a\u002d\uff0c\u3002\uff1b\u3001]') # 中文的编码范围是:\u4e00到\u9fa5
zh = " ".join(pattern.split(line)).strip()
# zh = ",".join(zh.split())
outStr = zh # 经过相关处理后得到中文的文本
return outStr
def translate1(str):
line = str.strip() # 处理前进行相关的处理,包括转换成Unicode等
pattern = re.compile('[^\u4e00-\u9fa50-9\u002d]') # 中文的编码范围是:\u4e00到\u9fa5
zh = " ".join(pattern.split(line)).strip()
# zh = ",".join(zh.split())
outStr = zh # 经过相关处理后得到中文的文本
return outStr
def extract_data(html_code):
# 目标数据的正则表达式
p_job = 'class="jname text-cut">(.*?)</span>'
p_area = 'class="shrink-0">(.*?)</div>'
p_salary = 'class="sal shrink-0">(.*?)</span>'
p_link = 'class="cname text-cut".*?href="(.*?)"'
p_company = 'class="cname text-cut">(.*?)</a>'
# 利用findall()函数提取目标数据
job = re.findall(p_job, html_code, re.S)
salary = re.findall(p_salary, html_code, re.S)
needs_city = re.findall(p_area, html_code, re.S)
link = re.findall(p_link, html_code, re.S)
company = re.findall(p_company, html_code, re.S)
print(job)
print(salary)
print(needs_city )
print(link)
print(company)
data_dt = {'职位名称': job, '月薪': salary, '岗位城市': needs_city, '公司链接': link, '公司名称': company}
return pd.DataFrame(data_dt)
def get_pages(keyword, start, end):
# 声明要模拟的浏览器是Chrome,并启用无界面浏览模式
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument("--disable-blink-features=AutomationControlled")
#chrome_options.add_argument("--headless")
chrome_options.add_argument(
"user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.6099.130 Safari/537.36")
browser = webdriver.Chrome(options=chrome_options)
browser.maximize_window()
# 通过get()函数控制浏览器发起请求,访问网址,获取源码
url = 'https://www.51job.com/'
browser.get(url)
# 模拟人操作浏览器,输入搜索关键词,点击搜索按钮
browser.find_element(By.XPATH, '//*[@id="kwdselectid"]').clear()
browser.find_element(By.XPATH, '//*[@id="kwdselectid"]').send_keys(keyword)
browser.find_element(By.XPATH, '/html/body/div[3]/div/div[1]/div/button').click()
time.sleep(random.uniform(5, 10))
all_data = pd.DataFrame()
job0 = []
job1 = []
job2 = []
count=1
try:
for page in range(start, end + 1):
all_data = pd.concat([all_data, extract_data(browser.page_source)], ignore_index=True)
js = "window.scrollTo(0, 0)" # 将浏览器滚动到页面顶部。
browser.execute_script(js) # 执行 JavaScript 脚本,将页面滚动到顶部。
browser.find_element(By.XPATH, '//*[@id="jump_page"]').clear()
browser.find_element(By.XPATH, '//*[@id="jump_page"]').send_keys(page)
browser.find_element(By.XPATH,
'//*[@id="app"]/div/div[2]/div/div/div[2]/div/div[2]/div/div[3]/div/div/div/button[2]').click()
# 等待浏览器与服务器交互刷新数据,否则获取不到动态信息
time.sleep(random.uniform(5, 12))
if(is_slider_container_present(browser)):
handle_slider_verification(browser)
finally:
all_data.to_excel(f'{keyword}.xlsx', index=False)
browser.quit()
keywordbiao={'软件','硬件','交通','体育','保险','公关','制药','家居','工业','影视','电子','房产','会计','银行','证券','金融','信托','贸易',
'批发',
}
for keyword in keywordbiao:
# 调用get_pages函数
get_pages(keyword, 1, 50)
Bilibili爬取的代码找不到了。。
2.2 简历评分
调用文心一言评分:
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
'''
@Project :douban
@File :gptdemo.py
@IDE :PyCharm
@Author :hjh
@Date :2024/1/8 22:06
'''
import erniebot
import sys
import json
def communicate(str):
# 文心一言api的个人key
erniebot.api_type = '*****'
erniebot.access_token = '*******'
response = erniebot.ChatCompletion.create(
model='ernie-bot',
messages=[{'role': 'user', 'content': str}],
)
print(response.get_result())
sys.exit(0)
if __name__ == "__main__":
#从命令行获取两个参数 一个是文字,一个是文件路径
quesion = sys.argv[1]
path = sys.argv[2]
#读取简历
with open(path, encoding='utf-8') as file:
# 使用json.load()方法加载JSON数据
data = json.load(file)
# 将JSON数据转换为字符串
json_string = json.dumps(data)
communicate(quesion+json_string)
2.3 简历pdf生成
#!\\usr\\bin\\env python
# -*- coding: UTF-8 -*-
'''
@Project :douban
@File :getResumepdf.py
@IDE :PyCharm
@Author :hjh
@Date :2024\\1\\11 16:29
'''
from docxtpl import DocxTemplate
import aspose.words as aw
import argparse
import json
import os
import sys
# 根路径 XJTU
rootPath = os.path.abspath('.')
def fill_template(template_path, user_data, userId):
# 读取模板文档
tpl = DocxTemplate(template_path)
# 替换文档中的占位符
tpl.render(user_data)
# 另存为新的 Word 文档
output_path = rootPath + '\\src\\main\\resources\\Users\\' + userId + '\\resume.docx'
tpl.save(output_path)
return output_path
def main(userId):
json_path = rootPath+'\\src\\main\\resources\\Users\\' + userId + '\\resume' + userId + '.json'
pdf_path = rootPath+'\\src\\main\\resources\\Users\\' + userId + '\\resume.pdf'
print(json_path)
print(pdf_path)
# 从JSON文件中加载用户数据
with open(json_path, 'r', encoding='utf-8') as json_file:
user_data = json.load(json_file)
print(json_path)
print(pdf_path)
# 设置模板路径
template_path = rootPath + "\\python\\model2.docx"
# 填充模板
filled_resume = fill_template(template_path, user_data, userId)
# 使用Aspose.Words将Word文档转换为PDF
doc = aw.Document(filled_resume)
doc.save(pdf_path)
# 读取 .docx 模板
# template_path = "E:\\python\\pythonProject\\model2.docx"
#
# user_data = {
# "name": "张三",
# "gender": "男",
# "identity": "学生",
# "graduation_year": "2022",
# "tel": "123456789",
# "birthday_date": "2000-01-01",
# "city": "某地",
# "email": "zhangsan@example.com",
# "job_status": "在校-考虑机会",
# "personal_advantages": "沟通能力强,团队协作",
# "expected_industry": "IT",
# "expected_position": "软件工程师",
# "position_details": "Web开发",
# "salary_requirements": "15000元\\月",
# "work_city": "北京",
# "other_city": "上海",
# "experiences": [
# {
# "company_name": "ABC公司",
# "industry": "IT",
# "work_time": "2020 - 2022",
# "position_name": "实习生",
# "job_description": "负责前端开发",
# "isInternship": "是",
# },
# ],
# "projects": [
# {
# "project_name": "项目A",
# "role": "项目经理",
# "project_time": "2021 - 2022",
# "project_description": "开发一个Web应用",
# "project_performance": "成功上线",
# "project_link": "http:\\\\projecta.com",
# },
# {
# "project_name": "项目B",
# "role": "开发工程师",
# "project_time": "2022 - 2023",
# "project_description": "设计和实施数据库系统",
# "project_performance": "提高系统性能",
# "project_link": "http:\\\\projectb.com",
# },
# ],
# "educations":[
# {
# "university": "某大学",
# "qualification": "本科",
# "major": "计算机科学与技术",
# "study_time": "时间段:2018-2022",
# "major_courses": "数据结构,算法",
# "profession_rank": "前30%",
# "study_experience": "参与学生科研项目",
# },
# ],
# "honor_name": "优秀学生奖",
# "certificate_name": "计算机专业证书",
# "organization_name": "学生会",
# "organization_role": "主席",
# "organization_time": "时间段:2019-2021",
# "experience_description": "经历描述:组织校园活动",
# "major_skills": "Python, HTML, CSS, JavaScript",
# }
#
# # 填充模板
# filled_resume = fill_template(template_path, user_data)
#
# doc = aw.Document("word_resume.docx")
# doc.save("pdf_resume.pdf")
if __name__ == '__main__':
userId = sys.argv[1]
main(userId)
print("is in python")
# print(os.getcwd()) # F:\hjh\XJTU\python
# print(os.path.abspath('.'))
三、前端和后端部分
太多了。。。请参考:
前端部分链接:GitHub - Seeking-L/CareerCraftHub-Vue2: CareerCraftHub,2023-2024冬季小学期,小组项目的前端页面部分(Vue2)
记得点Star!!!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









