







概述
Structured Streaming是建立在SparkSQL引擎之上的可伸缩和高容错的流式处理引擎,我们可以像操作静态数据的批量计算一样来执行流式计算。当流式数据不断的到达的过程中Spark SQL的引擎会连续不断的执行计算并更新最终结果。DataSet/DataFrame的api也可以应用在Structured Streaming流式计算中,例如流式聚合,时间事件窗口,数据的join操作等。这些计算同样执行在经过最佳优化的Spark SQL引擎上。最后,系统通过check point和写前日志来保证端到端精确到一次的容错保证。简而言之,Structured Streaming提供了快速、可伸缩、可容错、端到端精确的流处理。
在内部,默认情况下,结构化流查询使用微批处理(micro-batch processing)引擎进行处理,微批处理引擎将数据流处理为一系列小批处理作业,从而实现端到端延迟低至100毫秒,并提供一次容错担保。但是,自从Spark 2.3以来,引入了一种新的低延迟处理模式,称为连续处理(Continuous Processing),它可以实现端到端延迟低至1毫秒,并且有至少一次的保证。我们在编码过程中不需要更改查询中的数据集/DataFrame操作,就可以根据需求来选择处理模式。
本指南中,会先介绍编程模型和api。主要使用默认的微批处理模型来解释这些概念,然后讨论连续处理模型。首先,让我们从一个Structured Streaming查询的简单示例开始——流字word count。
流式WordCount实例
假设我们现在现在从一个TCP协议的Socket服务中持续接收文本数据,并对这些数据进行word count的计算。首先我们仍然需要导入必要的类并且创建一个SparkSession实例,这是Spark所有功能的起点。
import org.apache.spark.sql.functions._
import org.apache.spark.sql.SparkSession
val spark = SparkSession
.builder
.appName("StructuredNetworkWordCount")
.getOrCreate()
import spark.implicits._接下来我们要从一个socket server中读取数据为一个流式的DataFrame,然后对DataFrame执行transformation来计算各单词的出现次数。
// 从socket服务器端得到一行行数据并组成dataFrame返回
val lines = spark.readStream
.format("socket")
.option("host", "localhost")
.option("port", 9999)
.load()
// 将每行数据切分为单词
val words = lines.as[String].flatMap(_.split(" "))
// 进行结果的计算
val wordCounts = words.groupBy("value").count()lines这个DataFrame可以被表示为一个包含流文本数据的无界表,这个表包含一列名为“value”的字符串,流媒体文本数据中的每一行都变成表中的一行。开始的时候她没有接收任何数据,因为我们只是设置了transformation,并没有启动它。接下来,我们使用.as[String]方将DataFrame转换为了DataSet。这样我们就可以应用flatMap操作将每一行分割成多个单词。words这个DataSet包含了所有单词。最后,我们定义了wordCounts DataFrame,对words中的单词进行分组并计数。需要注意的是,这是一个流式DataFrame,我们需要接收新数据持续运行word count。
我们现在已经设置了对流数据的接收及处理。剩下的就是实际开始接收数据并计算结果。我们设置每次更新计算时都将完整的结果打印到控制台,然后使用start()启动流计算。
// 开始运行并且打印执行结果到控制台
val query = wordCounts.writeStream
.outputMode("complete")
.format("console")
.start()
query.awaitTermination()执行完之后,程序就将在后台启动,使用awaitTermination方法让程序在收到终止指令前一直保持等待。
要想程序接收到数据我们还需要一个socket服务端,linux上可以使用命令nc -lk 9999来启动一个socket服务端,假设我们在socket服务端先输入apache spark 再出入spark hadoop,那么流式计算程序的输出将会像下面这样:
-------------------------------------------
Batch: 0
-------------------------------------------
+------+-----+
| value|count|
+------+-----+
|apache| 1|
| spark| 1|
+------+-----+
-------------------------------------------
Batch: 1
-------------------------------------------
+------+-----+
| value|count|
+------+-----+
|apache| 2|
| spark| 1|
|hadoop| 1|
+------+-----+编程模型
Structured Streaming的关键思想是将实时数据流看做一个不断增加数据的表,这种思想让流式处理模式与之前的离线批量处理模式非常相像。我们可以把流计算表示为标准的批处理式查询,就像在静态表上一样。下面让我们看一下模型中的细节:
基本概念
将输入数据流视为“输入表”。到达流上的每个数据项都像添加到输入表中的新行。
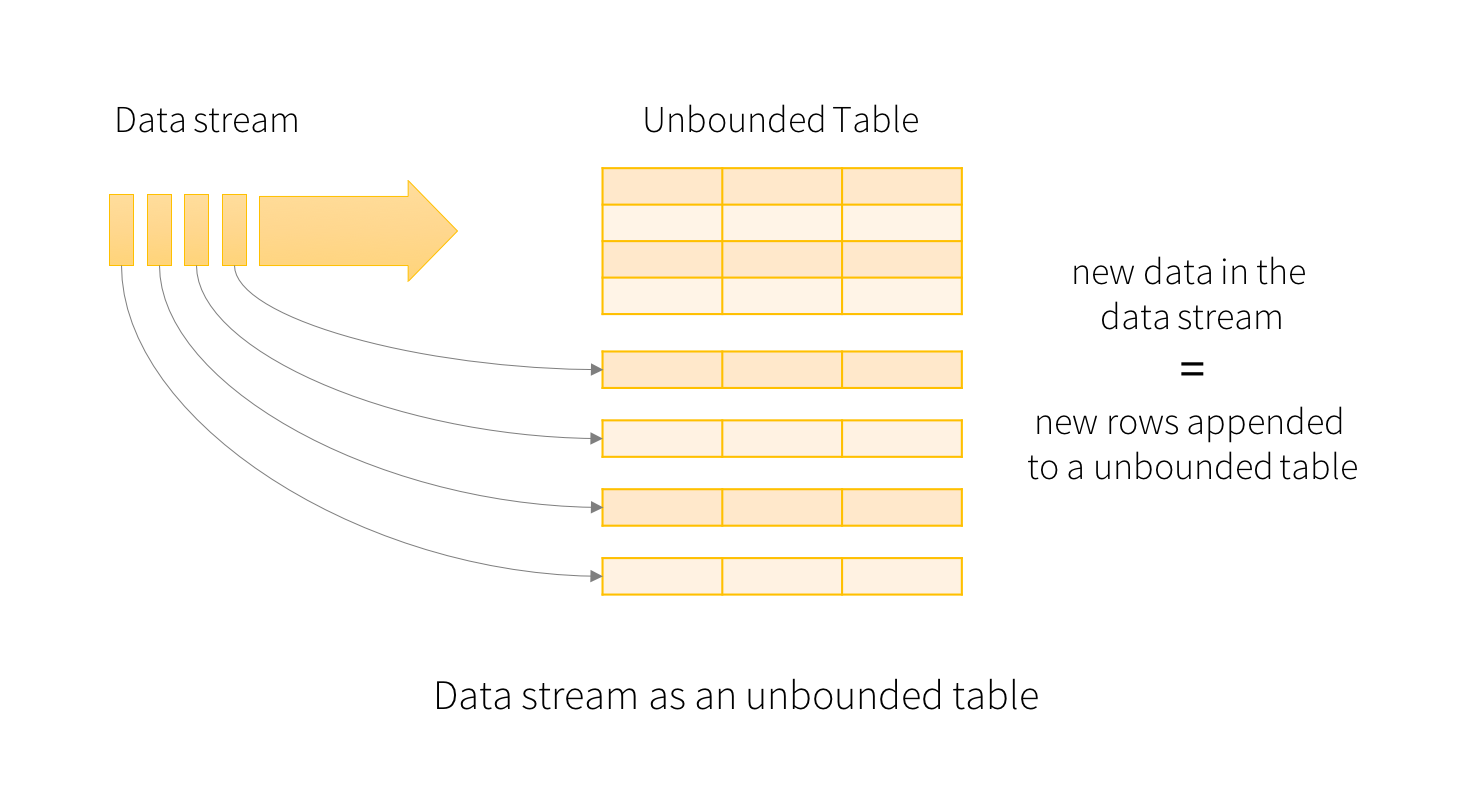
流式数据处理将生成"Result Table(结果表)",每个触发间隔(例如1s)都有新的行被添加的表中,这些数据最终会导致"Result Table"的更新,每当更新结果表时,我们都更改后的结果数据写入到外部接收器。
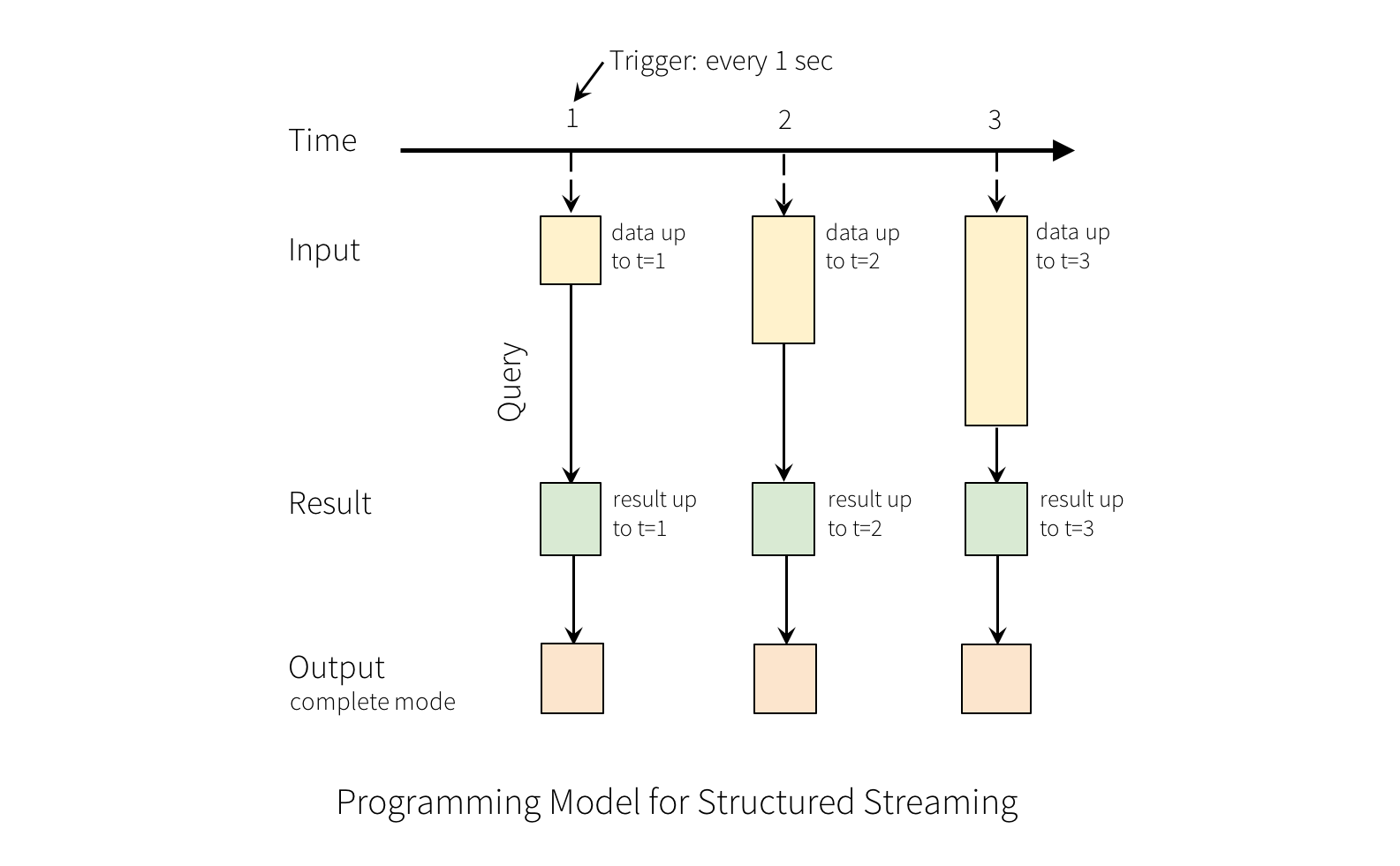
“Output”定义为输出到外部存储的内容。Output可以用不同的模式定义:
1.完整模式(complete mode)-整个更新后的结果表将写入外部存储。由存储连接器决定如何处理整个表的写入。
2.追加模式——只将最后一次追加到结果表中的新行写入外部存储。这仅适用于不期望结果表中现有行发生更改的情况。
3.更新模式——只将发生了更新的结果表中的行写入外部存储(自Spark 2.1.1以来可用)。注意,这与Complete模式不同,因为该模式只输出本次触发间隔中发生了更改的行。
需要注意的是,每种模式都适用于特定类型的查询。稍后将对此进行详细讨论。
为了演示这个模型的使用,让我们结合上面的word count实例来理解这个模型。lines指向的DataFrame是输入表,最后一行wordCounts DataFrame是结果表。请注意,用于生成word count的流式DataFrame处理与静态DataFrame完全相同。但是,在启动此处理时,Spark将持续检查socket连接中的新数据。如果有新数据,Spark将运行一个“增量”查询,该查询将之前运行的数据与新数据相结合,以计算更新的结果,如下所示
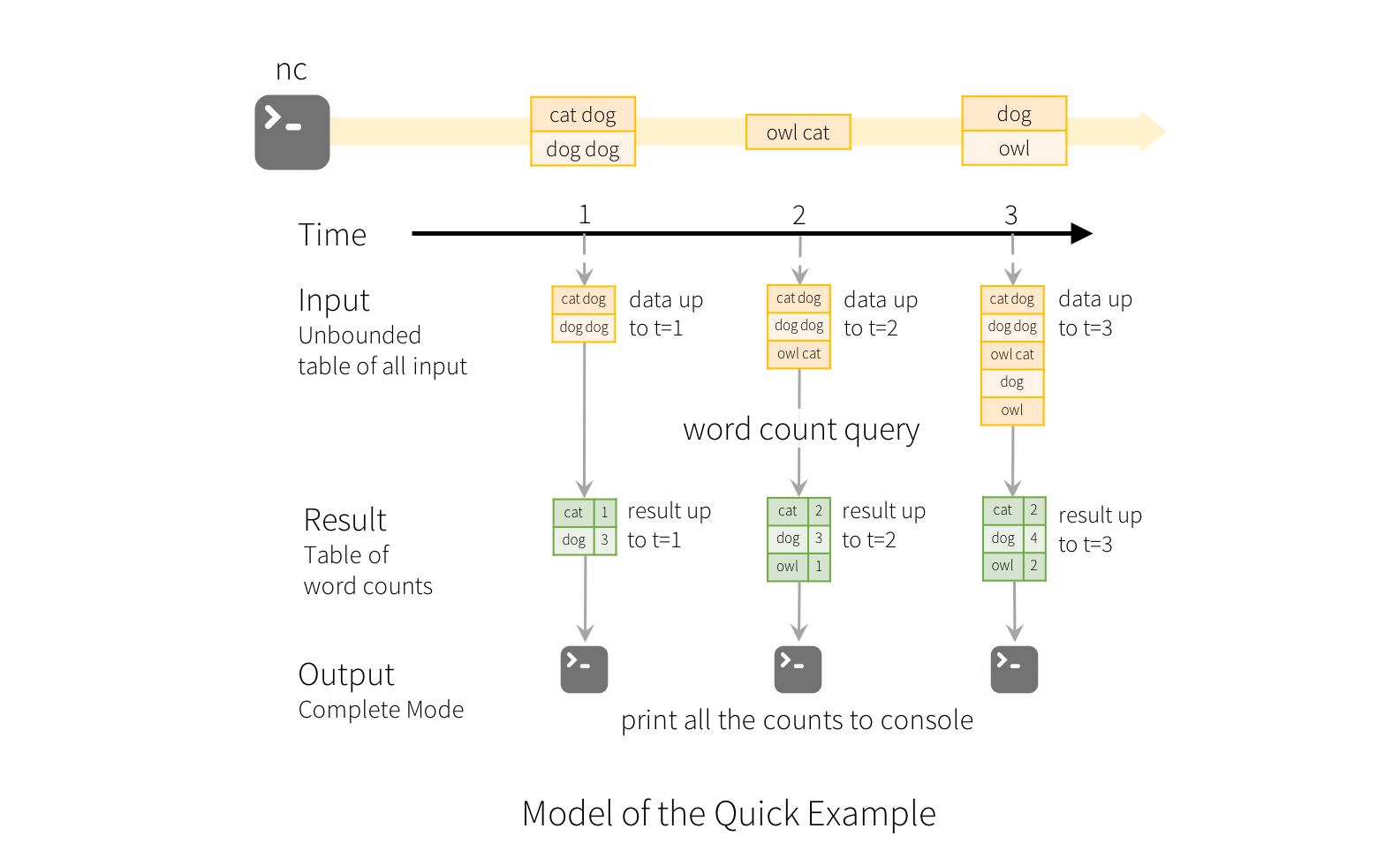
实际上结构化流不会计算整个表的数据。它从流数据源读取最新的可用数据,增量地处理数据以更新结果,然后丢弃源数据。它只保留更新结果所需的最少中间状态数据(如前面示例中的中间计数)。
这个模型与许多其他流处理引擎有很大的不同。许多流系统要求用户自己维护正在运行的聚合,因此必须考虑容错性和数据一致性(至少一次、最多一次或准确一次)。在该模型中,Spark负责在有新数据时更新结果表,从而使用户不必对结果表进行推理。例如,让我们看看这个模型如何处理基于事件时间的处理和延迟到达的数据。
处理事件时间和延迟数据
事件时间是嵌入在数据本身的时间。对于许多应用程序,我们可能希望在事件时间上进行操作。例如,如果希望获得物联网设备每分钟生成的事件数,那么我们可能希望使用数据生成时的时间(即数据中的事件时间),而不是Spark接收它们的时间。事件时间在这个模型中的表示方式是——来自设备的每个事件是表中的一行,而事件时间是行中的列值。这允许基于时间窗口的聚合(例如每分钟事件数)只是事件时间列上的一种特殊类型的分组和聚合——每个时间窗口是一个组,每一行可以属于多个窗口/组。因此,这种基于事件-时间-窗口的聚合查询既可以在静态数据集(例如,从收集的设备事件日志)上定义,也可以在数据流上定义,这可以使我们的工作更加容易。
此外,该模型可以自然地根据事件时间处理比预期晚到达的数据。由于Spark会更新结果表,因此当有延迟数据时,它可以完全控制更新旧聚合,以及清理旧聚合以限制中间状态数据的大小。从Spark 2.1开始,Spark允许用户指定延迟数据的阈值,并允许引擎相应地清理旧状态。稍后将在窗口操作部分更详细地解释这些内容。
容错语义
准确地实现端到端的一次性语义是Structured Streaming设计背后的关键目标之一,为了达成这一目标,我们设计了Structured Streaming源,接收器和执行引擎来可靠地跟踪处理的准确进度,这样就可以通过重新启动和或重新处理来处理任何类型的故障。假设每个Streaming源都有偏移量(类似kafka的偏移量)来跟踪流中的读取位置,该引擎使用检查点和写前日志来记录在每个触发器中处理的数据的偏移范围。流汇聚接收模块被设计成处理后处理的幂等函数。结合使用可重放源和幂等汇聚,结构化流可以确保在任何故障下端到端精确地执行一次语义。
使用DataSet/DataFrame的API
自Spark 2.0以来,DataFrame和DataSet可以表示静态的、有界的数据,也可以表示流式的的、无界的数据。类似于静态DataSet/DataFrame,可以使用公共入口点SparkSession从流源创建流DataSet/DataFrame,并对它们应用与静态DataSet/DataFrame相同的操作。如果不熟悉DataSet/DataFrame的话,可以查看之前的博客或别的资料来学习。
创建流式DataFrame与流式DataSet
流式DataFrame可以通过SparkSession.readStream()方法返回的DataStreamReader接口创建。 类似于用于创建静态DataFrame的read接口,可以指定源数据格式、模式、选项等的详细信息。
输入源
下面是一些内置的源:
File Source-读取以数据流形式写入目录的文件,支持的格式有text/csv/json/orc/parquet。
Kafka Source-从kafka中读取数据,与Kafka broker版本0.10.0或更高兼容。
Socket Source(主要用于测试)-从socket连接中读取utf8文本数据,Driver相当于Socket监听的客户端,因为没法提供端对端的保证,Socket Source值应该被应用于测试。
Rate Source(主要用于测试)-每秒生成指定行数的数据,每个输出行包含一个timestamp和value,其中timestamp是包含消息分发时间的时间戳类型,而value是包含消息计数的Long类型,第一行从0开始。用于测试和基准测试。
有些Source方式无法实现容错,因为没法保证在失败后使用check point偏移量重播数据。
一些示例如下:
val socketDF = spark
.readStream
.format("socket")
.option("host", "localhost")
.option("port", 9999)
.load()
socketDF.isStreaming // 返回结果是true
socketDF.printSchema
// 读取一个目录中以原子方式编写的所有csv文件
val userSchema = new StructType().add("name", "string").add("age", "integer")
val csvDF = spark
.readStream
.option("sep", ";")
.schema(userSchema) // 指定csv文件的约束
.csv("/path/to/directory") 这些示例中生成的流式DataFrame是不指定类型的,这意味着在编译时不检查DataFrame的约束,只在运行时检查。有些操作,如map、flatMap等,需要在编译时知道类型。为此,可以使用与静态Dataframe相同的方法将这些无类型的流Dataframe转换为类型化流DataSet。这一块,请参见上一篇博客。
流DataFrame/DataSet的模式推断和分区
默认情况下,基于文件源的Structured Streaming需要指定schema,而不是让Spark去自动推断数据模式,这个限制能够确保Streaming Query即使在失败的情况下也使用一致的schema。对于特殊用例,也可以通过设置spark.sql.stream.schemaInference=true重新启用模式推断。
如果要读取的文件夹下存在name=value格式的子目录,并且名称为name的列包含在schema中,name=value的数据会被填充到数据中。
流式DataFrame/DataSet可应用的操作
我们可以在流DataFrame/DataSet上应用各种操作——从无类型的、类似sql的操作(例如select、where、groupBy)到类型化的、类似于ddl的操作(例如map、filter、flatMap)。让我们看一些可以使用的示例操作。
基本操作-Selection/Projection(投影,意思就是选择部分列来显示)/Aggregation
Streaming支持DataFrame/Dataset上的大多数常见操作。后面会讨论一些不受支持的操作。
case class DeviceData(device: String, deviceType: String, signal: Double, time: DateTime)
val df: DataFrame = ... // 流式DataFrame,数据的schema是 { device: string, deviceType: string, signal: double, time: string }
val ds: Dataset[DeviceData] = df.as[DeviceData] // 流式DataSet
//选择signal大于10的数据
df.select("device").where("signal > 10") // 无类型的api
ds.filter(_.signal > 10).map(_.device) // 有类型的api
// 根据deviceType分组统计数目
df.groupBy("deviceType").count() // 使用无类型的api
// 根据deviceType分组求signal的平均数
import org.apache.spark.sql.expressions.scalalang.typed
ds.groupByKey(_.deviceType).agg(typed.avg(_.signal)) // 使用有类型的api还可以将流式DataFrame/Dataset注册为临时视图,然后使用我们非常熟悉的SQL命令。
df.createOrReplaceTempView("updates")
spark.sql("select count(*) from updates") // returns another streaming DF以上就是Structured Streaming的一些基本概念及操作,下一篇重点介绍窗口函数。
要春节了,后面更新会更快。还有好心累。















 98
98











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









