







到压缩包文件夹里解压hadoop到modules
$ cd /opt/modules/
$ tar zxvf /opt/softwares/hadoop-2.5.0.tar.gz

#设置PATH(可选)
# vi /etc/profile
export HADOOP_INSTALL=/opt/modules/hadoop-2.5.0
export PATH=$PATH:$HADOOP_INSTALL/bin:$HADOOP_INSTALL/sbin
#官方参考资料:
# http://hadoop.apache.org/ -- Documentation -- Release 2.5.2
# General -- Single Node Setup
---------------------------
配置HDFS(Hadoop分布式文件系统)
** hdfs有两个namenode(主和从),datanode(多个)
** namenode维护元数据,如:文件到块的对应关系、块到节点的对应关系,以及用户对文件的操作
** datanode用来存储和管理本节点数据
a)
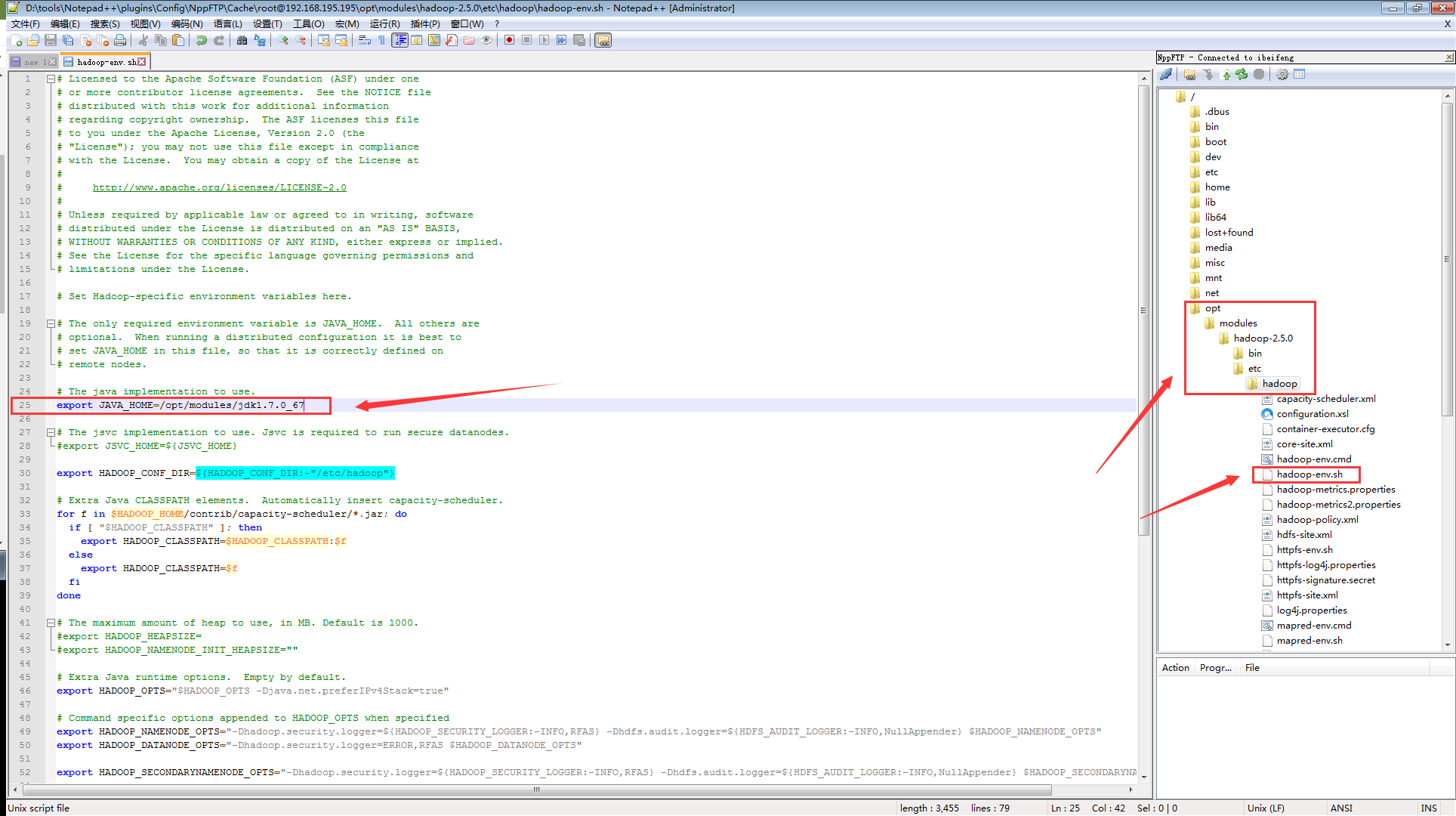
# 在Hadoop安装目录下的/etc/hadoop里,修改hadoop-env.sh文件里的JAVA_HOME
export JAVA_HOME=/opt/modules/jdk1.7.0_67
b)
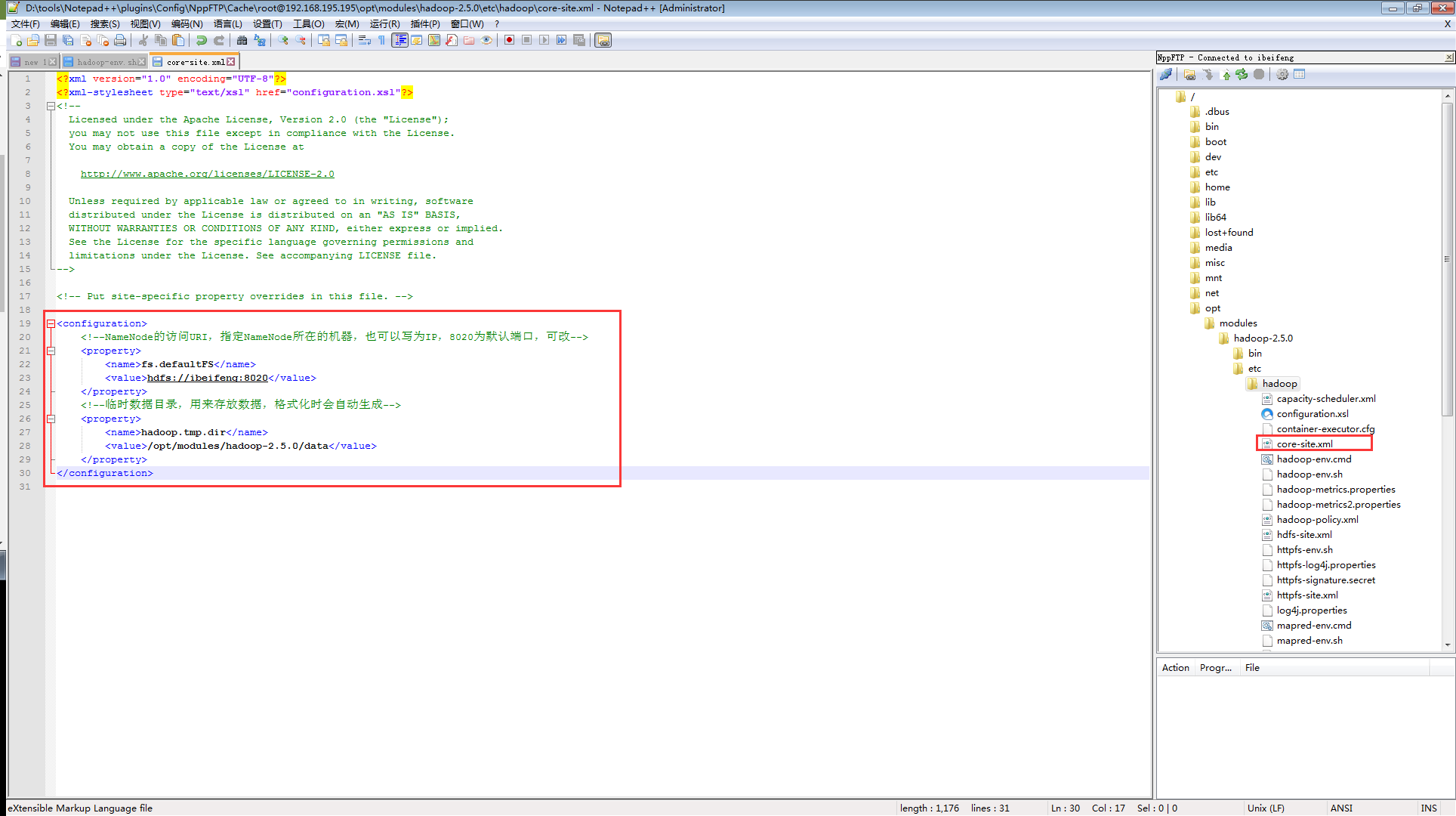
修改core-site.xml文件:注意,这里的主机名要根据自己的主机名字进行修改,不要直接拷贝。两个配置具体是干嘛的已经在内容里面写出来了,方便后面进行查看和修改,参考core-default.xml)
<configuration>
<!--NameNode的访问URI,指定NameNode所在的机器,也可以写为IP,8020为默认端口,可改-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://ibeifeng:8020</value>
</property>
<!--临时数据目录,用来存放数据,格式化时会自动生成-->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/modules/hadoop-2.5.0/data</value>
</property>
</configuration>
c)
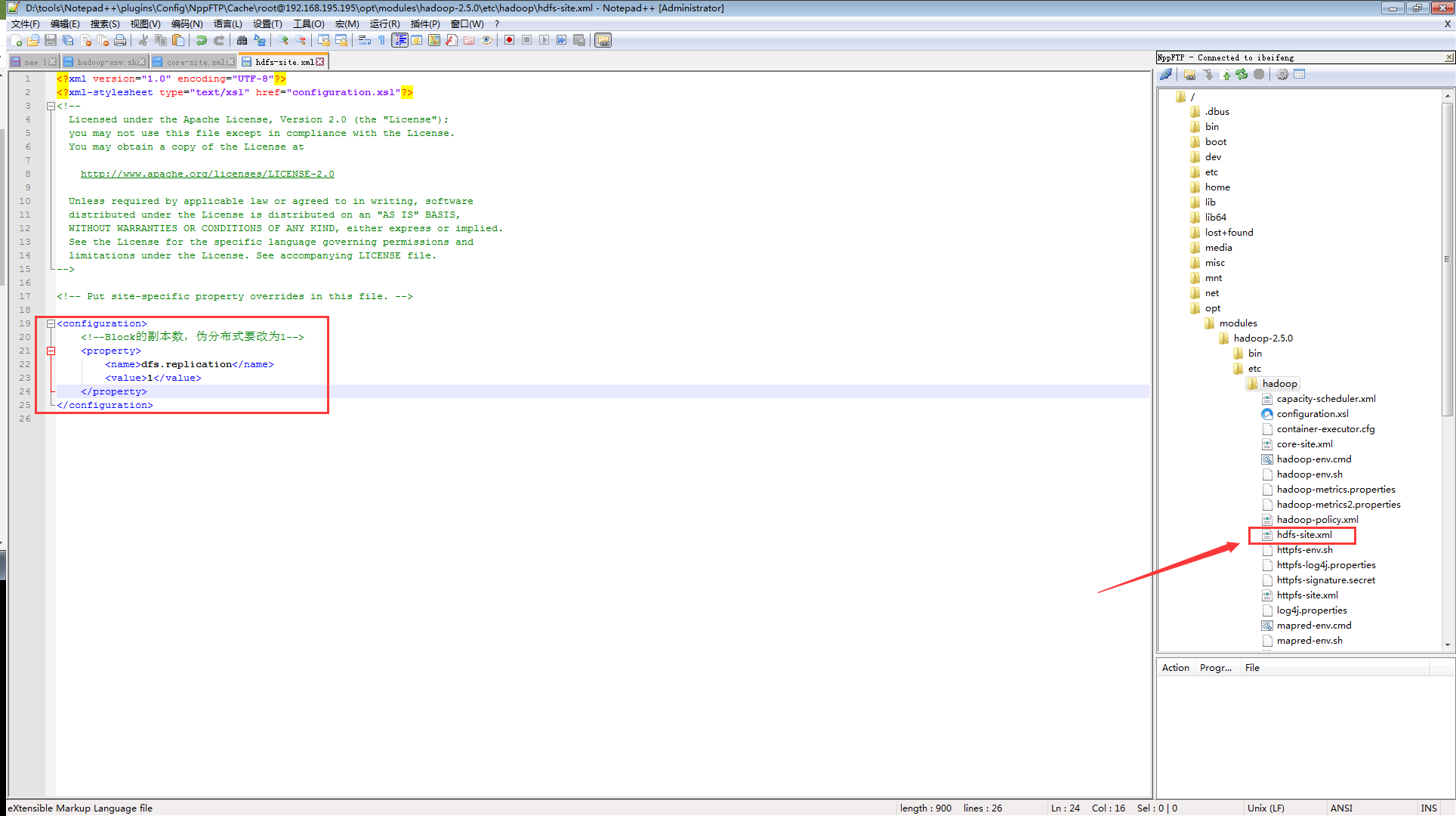
修改hdfs-site.xml文件:(这个配置是指定
Block的副本数,默认是三个,但是我们伪分布式只有一一台服务器,所以要设置为1,参考hdfs-default.xml)
<configuration>
<!--Block的副本数,伪分布式要改为1-->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
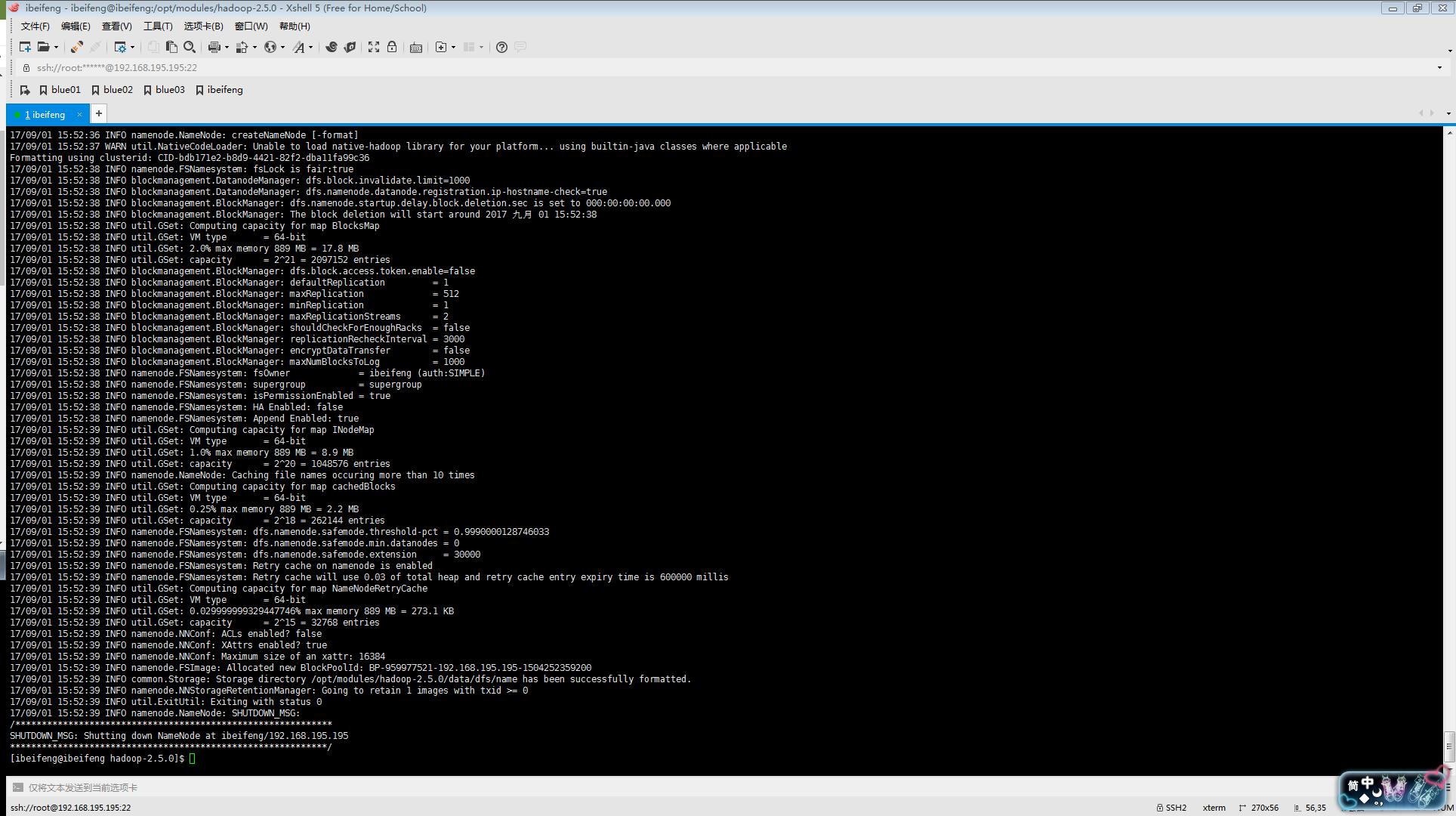
格式化namenode:(刚开始配置号Hadoop过后,HDFS里面是没有任何问价的,就像新装的一个软件里面没有任何东西一样,我们必须把它格式化,他会生成镜像文件和编辑日志文件,这样 我们才能正常的启动Hadoop集群,至于具体原因后面在讲HDFS启动过程的时候会具体讲解到的,看到下面这个界面就说明格式化成功了)
# 会自动生成data目录
$ bin/hdfs namenode -format
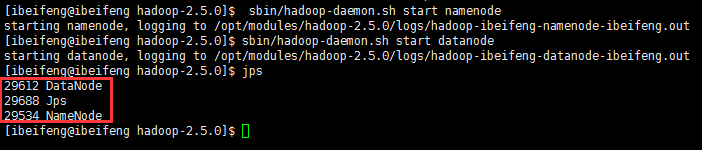
启动守护进程(服务):
# cmd文件是给Windows用的,可以删除
$
sbin/hadoop-daemon.sh start namenode # start是启动进程,stop用来停止守护进程
$
sbin/hadoop-daemon.sh start datanode
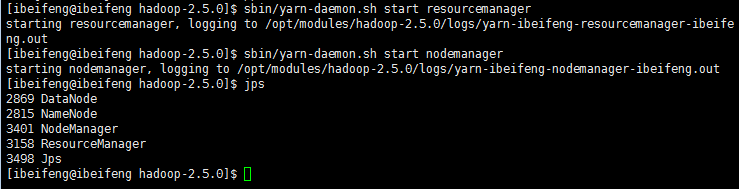
# jps --Process Status查看java进程,数字为PID(Process id),能看到NameNode和DataNode的进程就说明启动成功了
PS:
若是提示某个服务已经启动,可以去/tmp目录下删除对应的pid文件
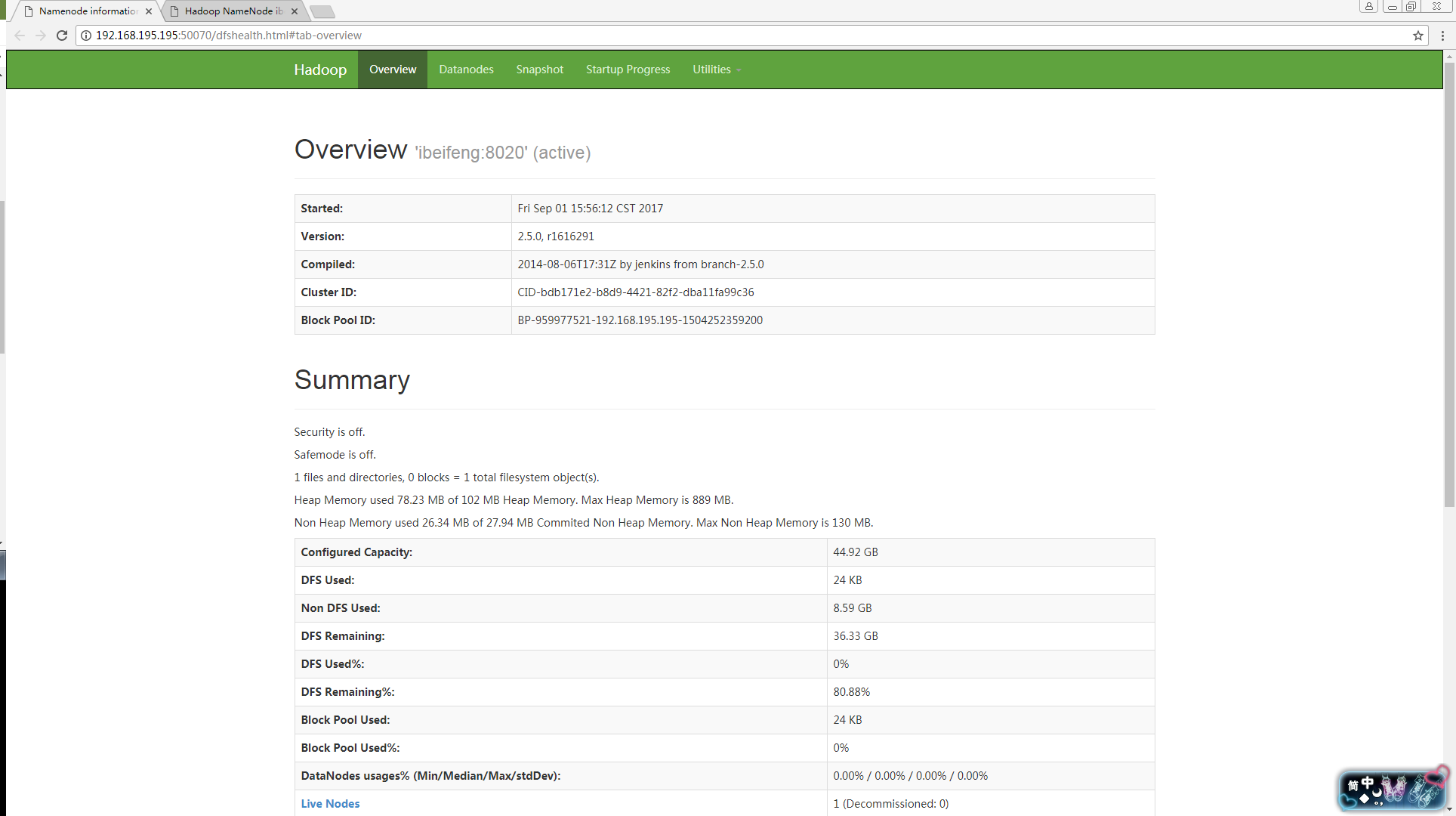
打开浏览器(开发测试当中建议使用谷歌浏览器,输入以下地址能看到以下界面说明配置成功):
http://192.168.195.
195:50070/
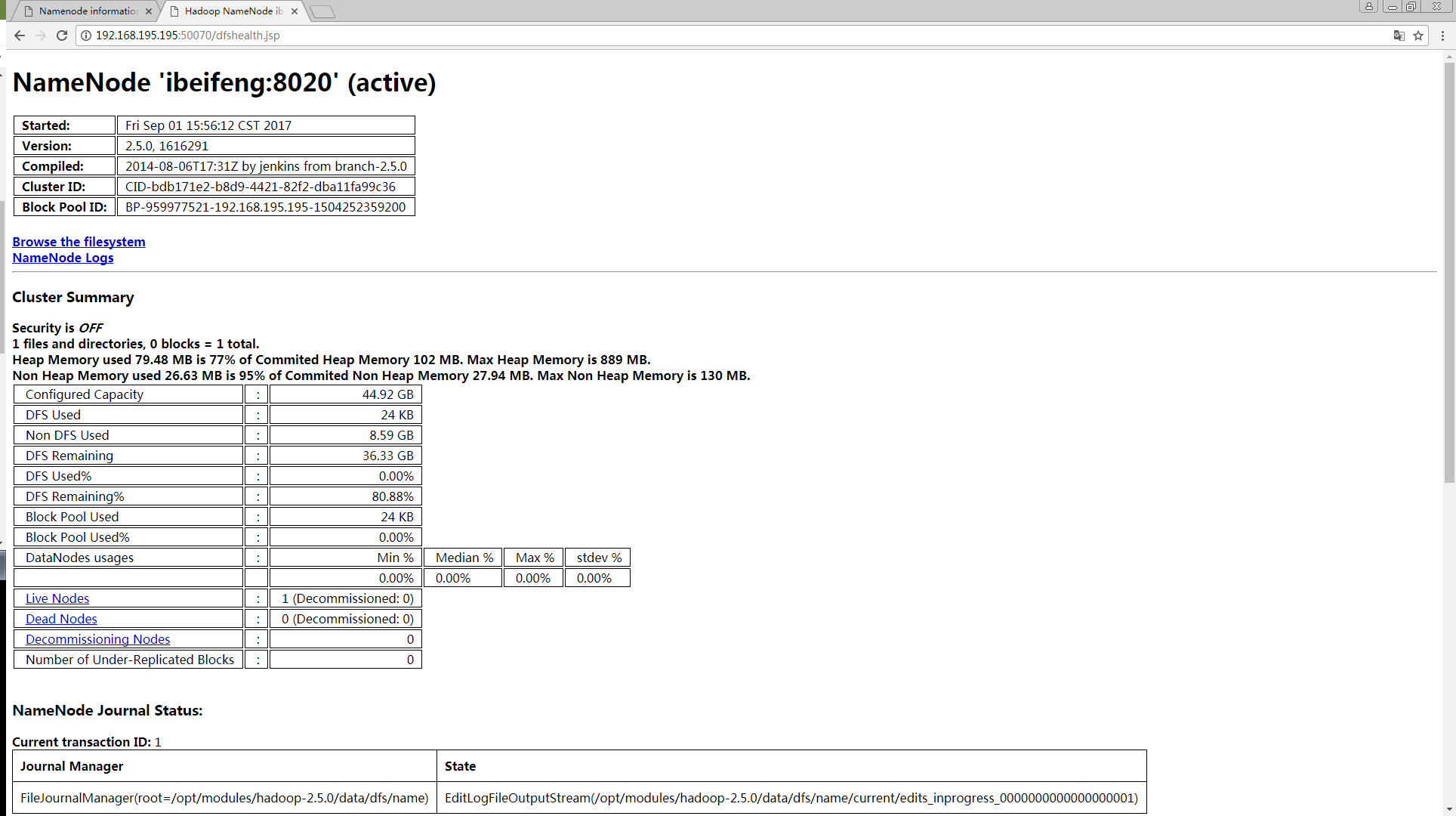
http://192.168.
195.
195:50070/dfshealth.jsp
上传文件:(测试HDFS)
# 随便创建一个文件a.txt,测试用
$ vi a.txt
# 打开网页,Utilities--Browse file system
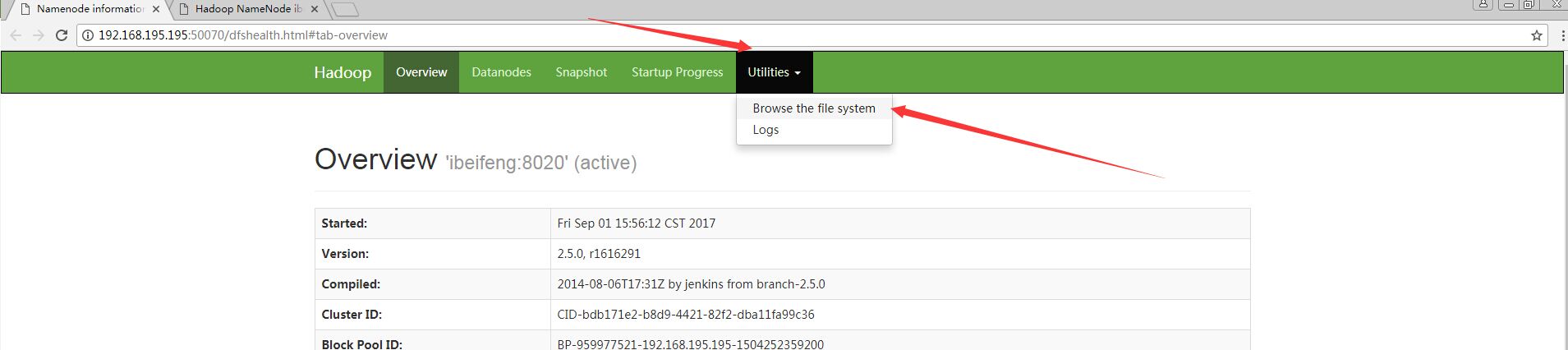
$ hdfs dfs -mkdir /input #在HDFS上创建文件夹,没有类似-cd进入目录的参数
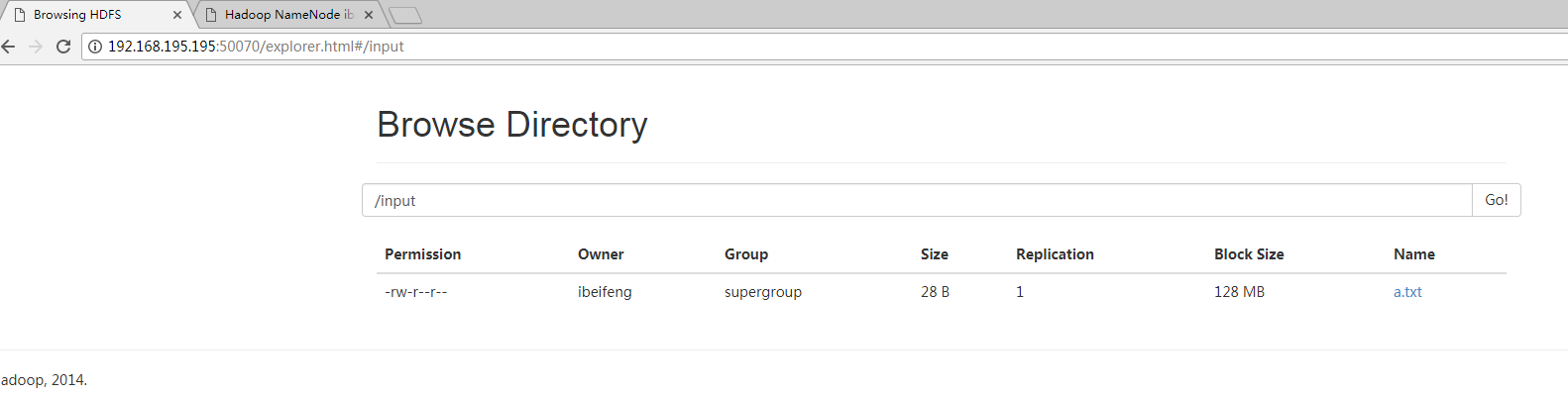
$
hdfs dfs -put a.txt /input #把本地文件拷到HDFS

----------------------------------
配置Yarn
** 两个管理器:resourcemanager、nodemanager
a)
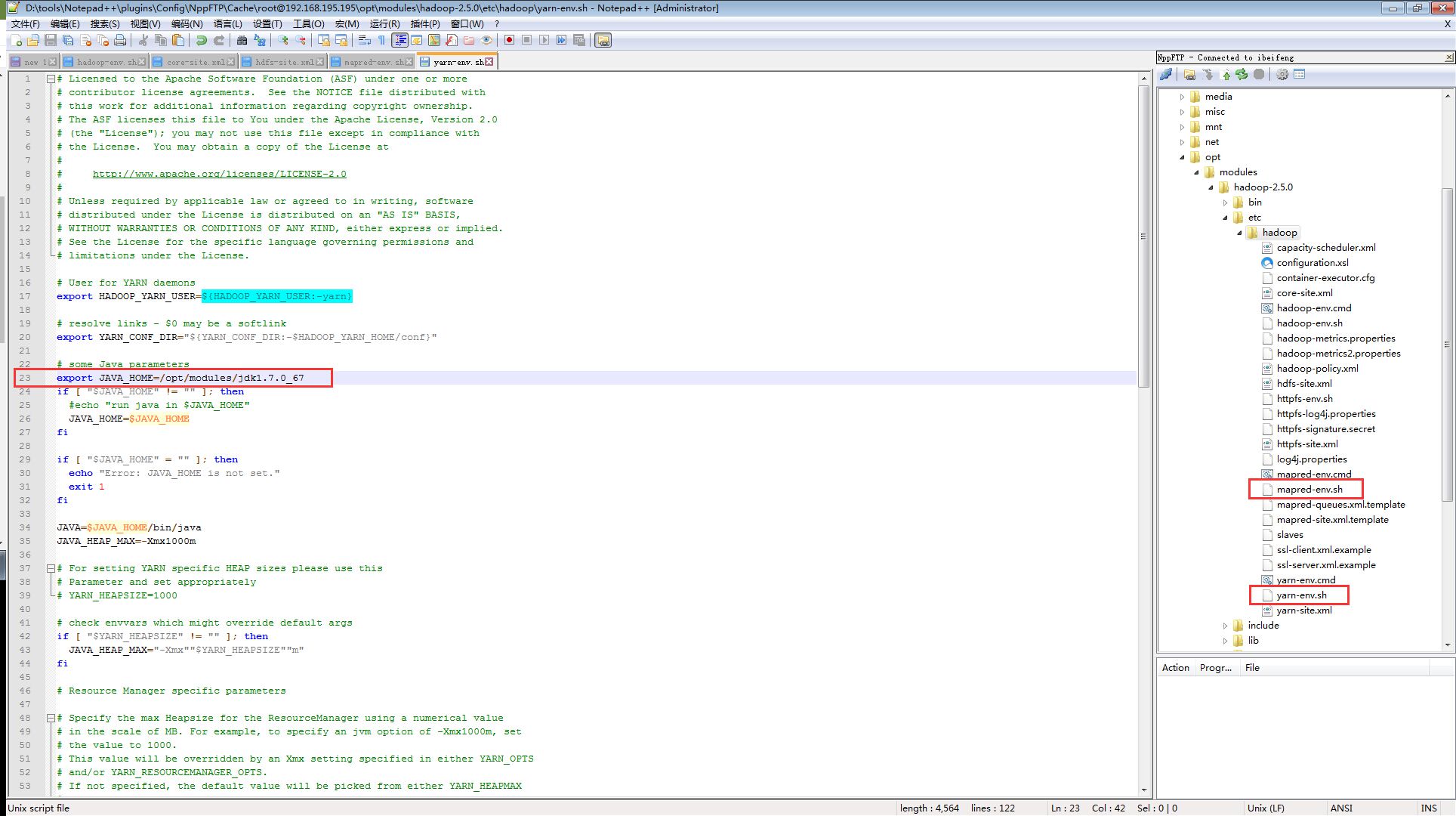
# 在/etc/hadoop里,yarn-env.sh和mapred-env.sh文件:
# 将"export JAVA_HOME"注解取消
export JAVA_HOME=/opt/modules/jdk1.7.0_67
b)
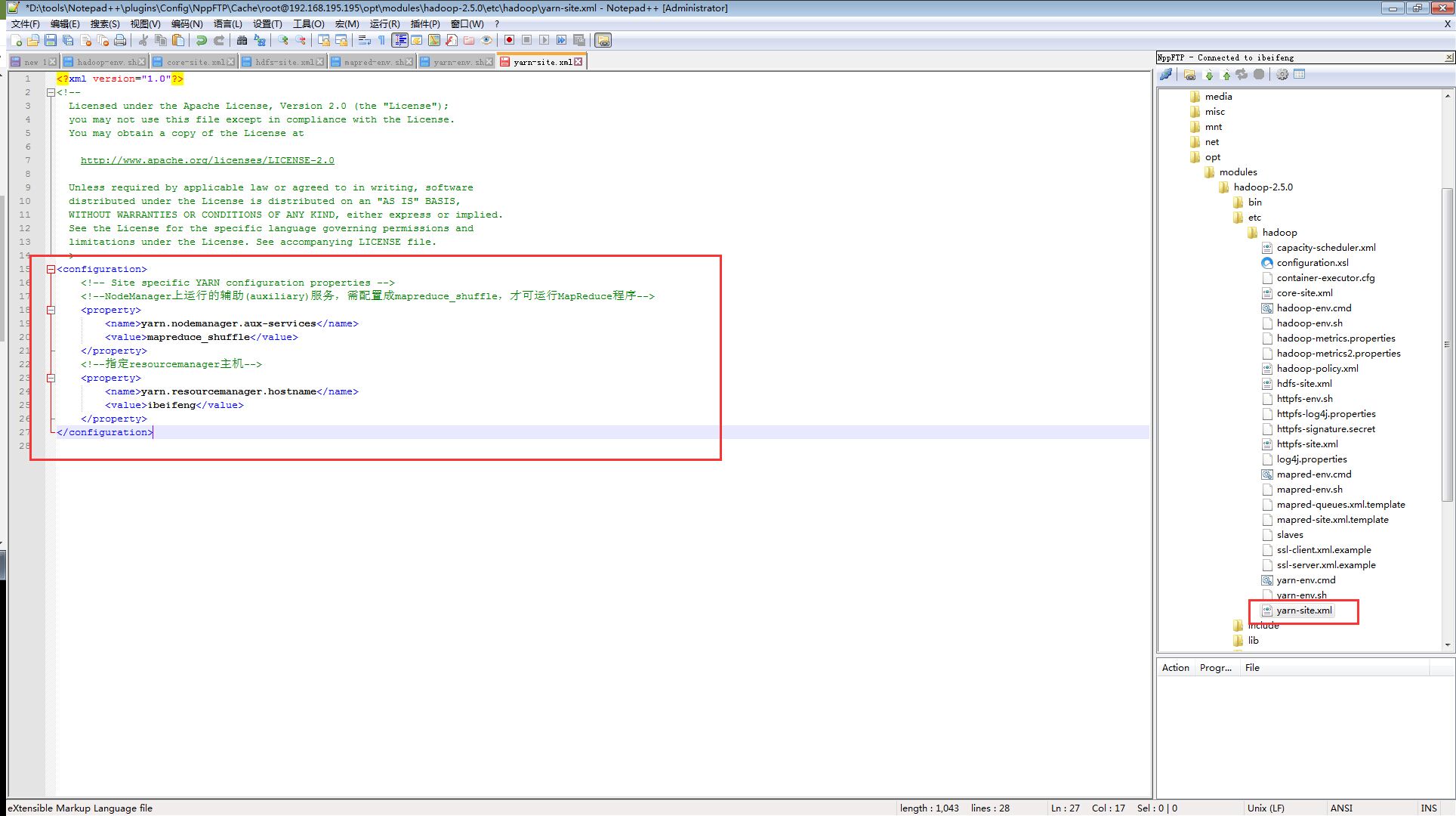
#yarn-site.xml文件
<!--NodeManager上运行的辅助(auxiliary)服务,需配置成mapreduce_shuffle,才可运行MapReduce程序-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--指定resourcemanager主机-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>ibeifeng</value>
</property>
c)
#mapred-site.xml文件(里面是没有这个文件的 ,只有一个mapred-site.xml.template,修改这个 文件,去掉.template)
<!--mapreduce是一种编程模型,运行在yarn平台上面-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
d)
hadoop-2.5.0/etc/hadoop/slaves文件:
** 记录哪些主机是datanode,目前是伪分布式,就一台机器,等以后搭集群的时候便每行一个主机名
** 替换掉原本localhost
ibeifeng
** 进入hadoop目录,启动yarn
$ sbin/yarn-daemon.sh start resourcemanager
$ sbin/yarn-daemon.sh start nodemanager
** yarn的作业监控平台,显示yarn平台上运行job的所用资源(CPU、内存)等信息
http://192.168.195.195:8088
测试:运行一个mapreduce作业
(需要启动namenode和datanode守护进程,在http://192.168.122.128:50070查看目标文件和结果文件)
# 运行官方提供的jar包,进行文件内单词统计(本例是以tab键'\t'作为单词间的分隔符)
# wordcount为程序名
# /input是输入路径,统计目录里的所有文件(可以上传多个文件试试)
# /output是输出路径,为了防止结果被意外覆盖,Hadoop规定输出文件一定不能存在
$ bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0.jar wordcount /input /output
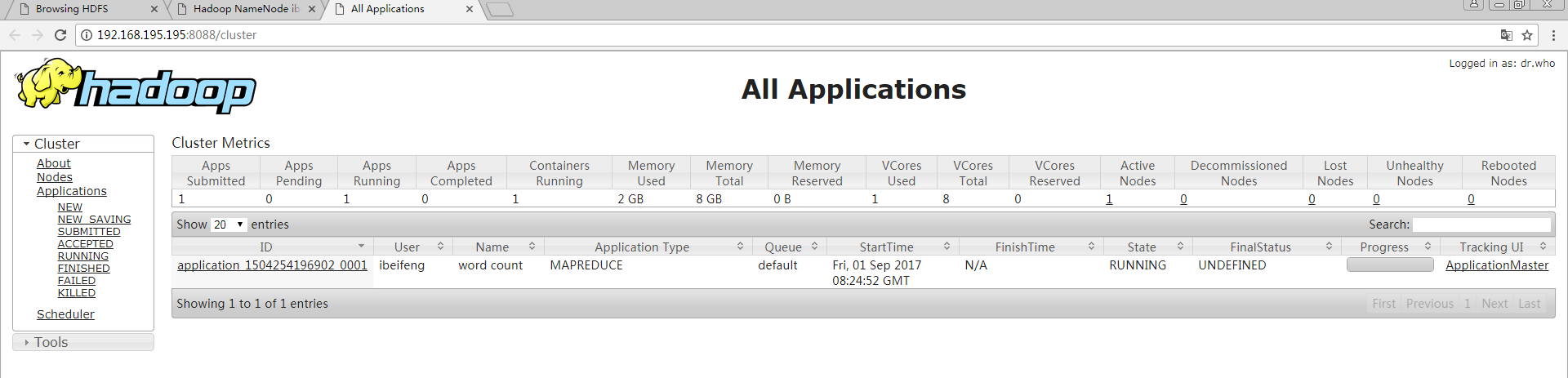
# 可以打开http://192.168.122.128:8088,查看运行信息
# 查看统计结果
$ bin/hdfs dfs -cat /output/p*
------------------------------------------
** 点击history无效,继续配置historyserver服务:
** 历史服务:查看已经运行完成的MapReduce作业记录,比如本次作业用了多少Mapper、Reducer,
** 还能看到作业提交时间、作业启动时间、作业完成时间等信息。
配置日志服务器:
yarn-site.xml文件
<!--启用日志聚合功能-->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!--日志保留时间,单位秒-->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>86400</value>
</property>
mapred-site.xml文件
<!--JobHistory服务的IPC地址(IPC:Inter-Process Communication进程间通信)-->
<property>
<name>mapreduce.jobhistory.address</name>
<value>ibeifeng:10020</value>
</property>
<!--日志的web访问地址-->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>ibeifeng:19888</value>
</property>
重启yarn服务(jps)
$ sbin/yarn-daemon.sh stop resourcemanager
$ sbin/yarn-daemon.sh stop nodemanager
$ sbin/yarn-daemon.sh start resourcemanager
$ sbin/yarn-daemon.sh start nodemanager
启动historyserver服务
$
sbin/mr-jobhistory-daemon.sh start historyserver
再次运行任务,必需改变输出目录
$ bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0.jar wordcount /input/ /output2
需要在(注意:是Windows目录,而不是Linux)C:\Windows\System32\drivers\etc里面的hosts文件里添加映射
192.168.195.195 ibeifeng
此时再点击history,就能看到结果
---------------------------------------
配置SecondaryNamenode
<property>
<name>dfs.namenode.secondary.htttp-address</name>
<value>ibeifeng:50090</value>
</property>
启动命令
$ sbin/hadoop-daemon.sh start secondarynamenode
---------------------------------------
解决警告:
$ bin/hdfs dfs -cat /output/par*
# 执行类似的命令时,会出现WARN
# Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
# 意思是当前平台(Centos6.4 64bit)不能加载(不兼容)hadoop包,hadoop包在lib目录下

解决方法:用native-2.5.0.tar.gz替换lib/native包
[ibeifeng@blue01 lib]$ rm -rf native
$ tar zxvf /opt/softwares/native-2.5.0.tar.gz
** 注意:CDH版本Hadoop不能用这个包来替换
=======================================================
PS:
编译Hadoop(选做,在Windows平台安装hadoop时,或者添加Hadoop一些额外功能时,才需要编译)
** hadoop-2.5.0.tar.gz 编译过后的包
** hadoop-2.5.0-src.tar.gz 没有经过编译的
** 系统必须联网(mvn仓库)
hadoop-2.5.0-src.tar.gz --> hadoop-2.5.0.tar.gz
** 时间比较长,而且对网络条件要求高,只要有一个包maven下载漏掉,就要重新编译,很麻烦(参考编译操作文档)
=======================================================
=============配置文件=========================================================
配置文件
* 默认配置文件:相对应的JAR中
* core-default.xml
* hdfs-default.xml
* yarn-default.xml
* mapred-default.xml
* 自定义配置文件$HADOOP_HOME/etc/hadoop/
* core-site.xml
* hdfs-site.xml
* yarn-site.xml
* mapred-site.xml
==============================启动方式===================================
启动方式
* 各个服务组件逐一启动
* hdfs
hadoop-daemon.sh start|stop namenode|datanode|secondarynamenode
* yarn
yarn-daemon.sh start|stop resourcemanager|nodemanager
* mapreduce
mr-historyserver-daemon.sh start|stop historyserver
* 各个模块分开启动
* hdfs
start-dfs.sh
stop-dfs.sh
* yarn
start-yarn.sh
stop-yarn.sh
* 全部启动
* start-all.sh
* stop-all.sh
SSH无秘钥启动
ssh-keygen -t rsa
ssh-copy-id ibeifeng
1 生成一对公私钥对
su - ibeifeng
$ ssh-keygen -t rsa #一直回车,rsa为指定的加密算法
** 执行后,在/home/tom/.ssh/下生成一对文件:id_rsa、id_rsa.pub
2 把自己的公钥发给blue01、blue02、blue03,会在.ssh/内生成authorized_keys文件
$ ssh-copy-id blue01.ibeifeng --需要输入‘yes’和目标节点的密码
***公钥发给了对方,就可以不用输入密码,直接使用私钥登录到对方主机
$ ssh ibeifeng
$ exit
PS:
1 若是不成功,则将这两个文件删除,再重新生成这两个文件即可
2 若是没有ssh-keygen命令
先用$ which ssh-keygen找到该命令对应文件:/usr/bin/ssh-keygen
然后用$ rpm -qf /usr/bin/ssh-keygen查找该文件所在的安装包:openssh-5.3p1-84.1.el6.x86_64
安装该安装包















 4336
4336

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









