 深入解析C#Dictionary的底层原理
深入解析C#Dictionary的底层原理








目录
前言:
分享一个面试的高频问题,就是C#一些集合的底层原理,今天先说一下Dictionary,这里是我在看了源码之后的一些理解和总结,欢迎大家积极讨论,和批评指正
一、Dictionary介绍:
Dictionary<TKey,TValue>的查询数据所花费的时间是所有集合类里面最快的,因为内部使用了散列函数加双数组来实现,所以其查询数据的时间复杂度为 O(1)。Dictionary<TKey,TValue>的实现是一种典型的牺牲空间换取时间的做法
二、基本构成
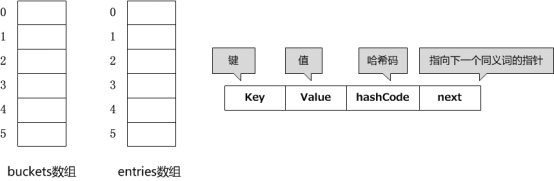
首先是最核心的部分 这个struct相当于一个链表结点,int 类型的 next指向entries数组中下一个Entry的索引
private struct Entry {
public int hashCode; // 降低31位哈希码,如果不使用则为-1
public int next; // 下一项的索引,如果是最后一项则为-1
public TKey key;
public TValue value;
}其次是我们口中常说的双数组:
Dictionary<Tkey,TValue>内部有两个数组,一个名为buckets,用于存放由多个同义词组成的静态链表的头指针(链表的第一个元素在数组中的索引,当它值为-1时表示此哈希地址不存在元素);另一个数组为entries,存放的是Entry结构体,同时这些数据通过next指针构成单链表。
private int[] buckets;
private Entry[] entries;
private int count;
private int version;
private int freeList;
private int freeCount;
private IEqualityComparer<TKey> comparer;
private KeyCollection keys;
private ValueCollection values;
private Object _syncRoot;
// constants for serialization
private const String VersionName = "Version";
private const String HashSizeName = "HashSize"; // Must save buckets.Length
private const String KeyValuePairsName = "KeyValuePairs";
private const String ComparerName = "Comparer";三、核心方法
一.Add操作
源码中Add(key,value)直接调用Insert(key,value,true),如下是Insert方法
private void Insert(TKey key, TValue value, bool add) {
if( key == null ) {
ThrowHelper.ThrowArgumentNullException(ExceptionArgument.key);
}
if (buckets == null) Initialize(0);
int hashCode = comparer.GetHashCode(key) & 0x7FFFFFFF;
int targetBucket = hashCode % buckets.Length;
#if FEATURE_RANDOMIZED_STRING_HASHING
int collisionCount = 0;
#endif
for (int i = buckets[targetBucket]; i >= 0; i = entries[i].next) {
if (entries[i].hashCode == hashCode && comparer.Equals(entries[i].key, key)) {
if (add) {
ThrowHelper.ThrowArgumentException(ExceptionResource.Argument_AddingDuplicate);
}
entries[i].value = value;
version++;
return;
}
#if FEATURE_RANDOMIZED_STRING_HASHING
collisionCount++;
#endif
}
int index;
if (freeCount > 0) {
index = freeList;
freeList = entries[index].next;
freeCount--;
}
else {
if (count == entries.Length)
{
Resize();
targetBucket = hashCode % buckets.Length;
}
index = count;
count++;
}
entries[index].hashCode = hashCode;
entries[index].next = buckets[targetBucket];
entries[index].key = key;
entries[index].value = value;
buckets[targetBucket] = index;
version++;
#if FEATURE_RANDOMIZED_STRING_HASHING
#if FEATURE_CORECLR
// In case we hit the collision threshold we'll need to switch to the comparer which is using randomized string hashing
// in this case will be EqualityComparer<string>.Default.
// Note, randomized string hashing is turned on by default on coreclr so EqualityComparer<string>.Default will
// be using randomized string hashing
if (collisionCount > HashHelpers.HashCollisionThreshold && comparer == NonRandomizedStringEqualityComparer.Default)
{
comparer = (IEqualityComparer<TKey>) EqualityComparer<string>.Default;
Resize(entries.Length, true);
}
#else
if(collisionCount > HashHelpers.HashCollisionThreshold && HashHelpers.IsWellKnownEqualityComparer(comparer))
{
comparer = (IEqualityComparer<TKey>) HashHelpers.GetRandomizedEqualityComparer(comparer);
Resize(entries.Length, true);
}
#endif // FEATURE_CORECLR
#endif
}解决冲突算法:
Dictionary<TKey,TValue>计算Key的哈希值使用的是取余法,解决冲突的方法是链接法
我们可以根据源码来推导一下这个过程:
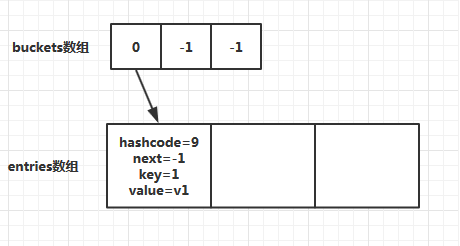
当添加第一个元素时,此时会分配buckets数组和entries数组的空间和初始大小,初始长度为3。对key=1进行哈希求值,假设第一个元素的hashcode=9然后targetBucket=9%buckets.Length(3)的值为0,此时内部结构如图所示:
然后插入第二个元素,对key=2进行哈希求值,假设hashcode=3然后targetBuckets=3%buckets.Length(3)的值为也0,此时就产生了hash冲突,Dictionary<TKey,TValue>解决冲突的方式是链接法,把发生冲突的元素链接在之前元素的后面,通过next属性来指定冲突关系,最后更新哈希表buckets数组。此时内部结构:
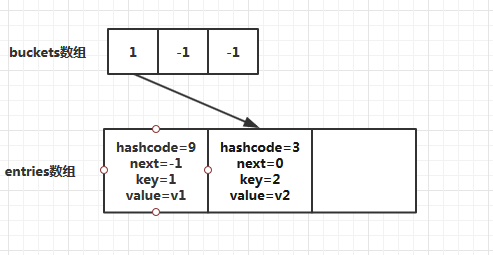
我们可以通过Dictionary<TKey,TValue>查找元素的实现来证明我们上面的分析是正确的。
二.TryGetValue等查找元素方法
从源码中可以看到所有查找元素的方法都调用了FindEntry(key)
private int FindEntry(TKey key) {
if( key == null) {
ThrowHelper.ThrowArgumentNullException(ExceptionArgument.key);
}
if (buckets != null) {
int hashCode = comparer.GetHashCode(key) & 0x7FFFFFFF;
//buckets[hashCode % buckets.Length]获得元素存储位置,然后遍历entries[i].next
for (int i = buckets[hashCode % buckets.Length]; i >= 0; i = entries[i].next)
{
//直到找到hashcode和key值都匹配的元素
if (entries[i].hashCode == hashCode && comparer.Equals(entries[i].key, key))
return i;
}
}
return -1;
}三.Resize()----扩容
有细心的小伙伴可能看过了Add操作以后就想问了,buckets、entries不就是两个数组么,那万一数组放满了怎么办?接下来就是我所要介绍的Resize(扩容)这样一种操作,对我们的buckets、entries进行扩容。
首先能够触发扩容操作的情况有两种,一种是申请的bukets数组容量排满的时候,如下所示:
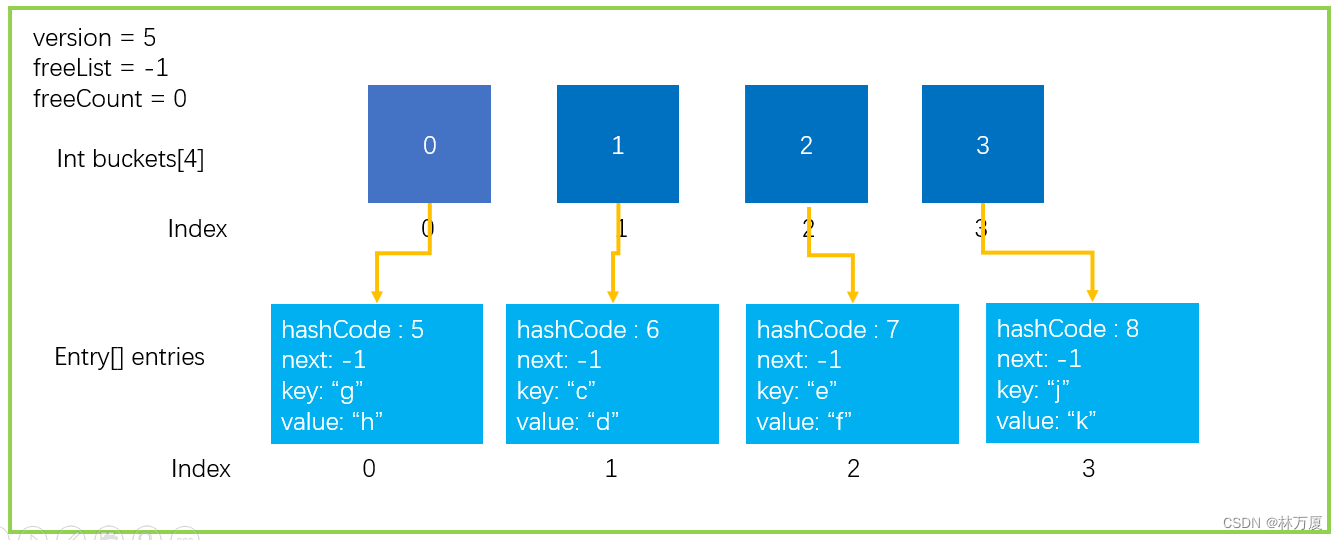
另一种情况就是当entries数组中多个元素共用一个targetbuket时:
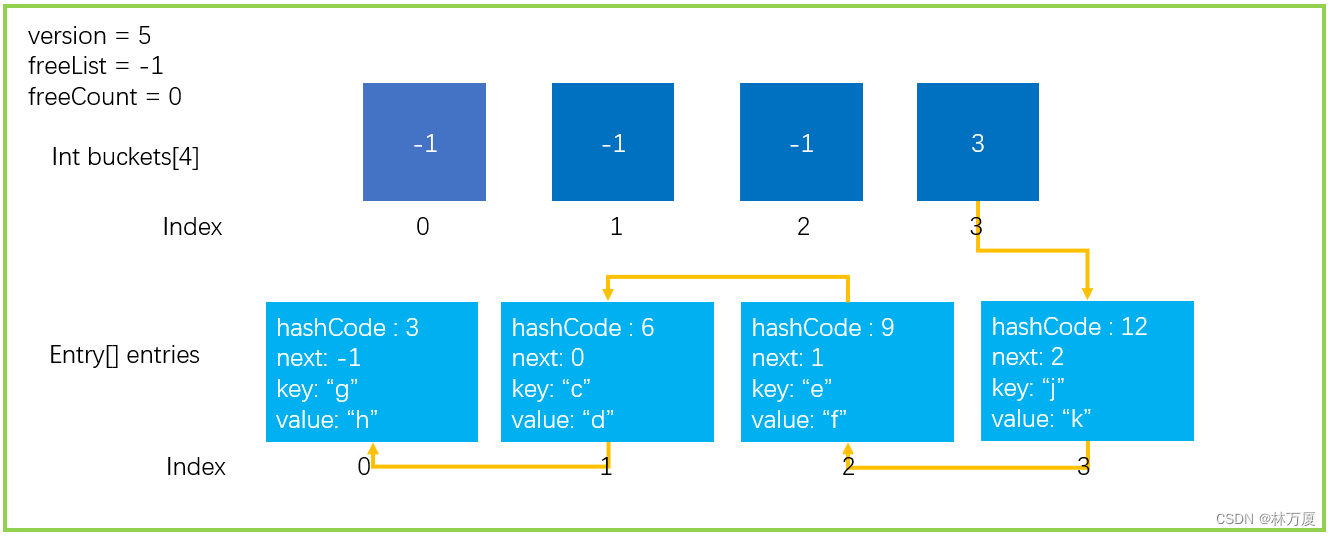
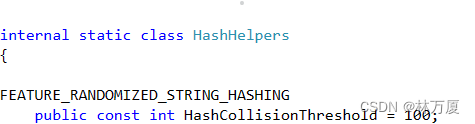
也就是说链表中某个结点后链接的元素太多,那一定会影响我们查找元素的速度,所以Dictionary底层也对这种情况做了处理,这个最大限制是100,大家可以去HashHelpers的源码中看到
Resize源码:
private void Resize(int newSize, bool forceNewHashCodes) {
Contract.Assert(newSize >= entries.Length);
// 1. 申请新的Buckets和entries
int[] newBuckets = new int[newSize];
for (int i = 0; i < newBuckets.Length; i++) newBuckets[i] = -1;
Entry[] newEntries = new Entry[newSize];
// 2. 将entries内元素拷贝到新的entries总
Array.Copy(entries, 0, newEntries, 0, count);
// 3. 如果是Hash碰撞扩容,使用新HashCode函数重新计算Hash值
if(forceNewHashCodes) {
for (int i = 0; i < count; i++) {
if(newEntries[i].hashCode != -1) {
newEntries[i].hashCode = (comparer.GetHashCode(newEntries[i].key) & 0x7FFFFFFF);
}
}
}
// 4. 确定新的bucket位置
// 5. 重建Hahs单链表
for (int i = 0; i < count; i++) {
if (newEntries[i].hashCode >= 0) {
int bucket = newEntries[i].hashCode % newSize;
newEntries[i].next = newBuckets[bucket];
newBuckets[bucket] = i;
}
}
buckets = newBuckets;
entries = newEntries;
}这样就完成了扩容的操作,
这就完成了扩容的操作,但如果是达到Hash碰撞阈值触发的扩容可能扩容后结果会更差。
在JDK中,HashMap如果碰撞的次数太多了,那么会将单链表转换为红黑树提升查找性能。目前.Net Framwork中还没有这样的优化,.Net Core中已经有了类似的优化,以后有时间在分享.Net Core的一些集合实现。
每次扩容操作都需要遍历所有元素,会影响性能。所以创建Dictionary实例时最好设置一个预估的初始大小。
四、总结
Dictionary<TKey,TValue>之所以能实现快速查找元素,其内部使用哈希表来存储元素对应的位置,我们可以通过哈希值快速地从哈希表中定位元素所在的位置索引,从而快速获取到key对应的Value值。物极必反,Dictionary<TKey,TValue>的缺点也很明显,就是里面的数据是无序排列的,所以按照一定顺序遍历查找数据效率是非常低的。

















 591
591

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









