






OpenAI的GPT-4o开口说话秒回人类,Gemini也能边听边思考——2024年全双工语音助手密集亮相,人机交互终于实现了“边说边听”的实时双向交互,使人机对话更加流畅、逼真。
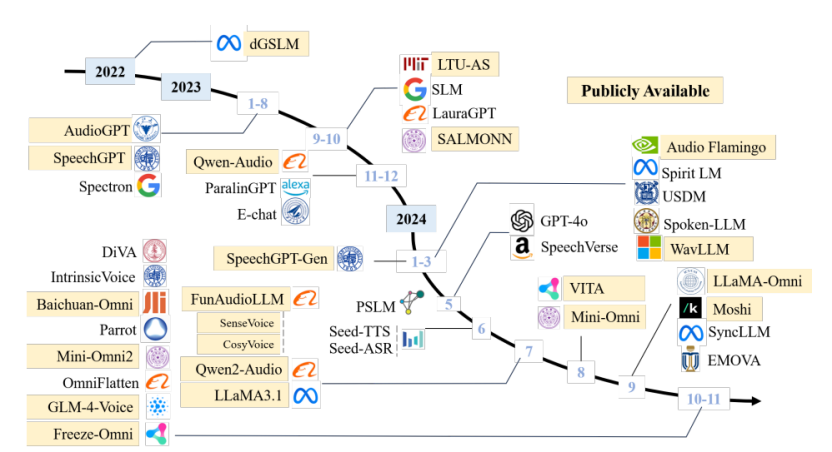
WavChat: A Survey of Spoken Dialogue Models
💡 技术揭秘:全双工语音的“灵魂三问”
① 听一半就懂,靠什么?
全双工模型的“分心阅读”能力是关键:边听用户说话,边解析语义、预测意图,还要同步生成回应。这要求模型必须学会多线程思维逻辑,而不仅仅是语音转文字。
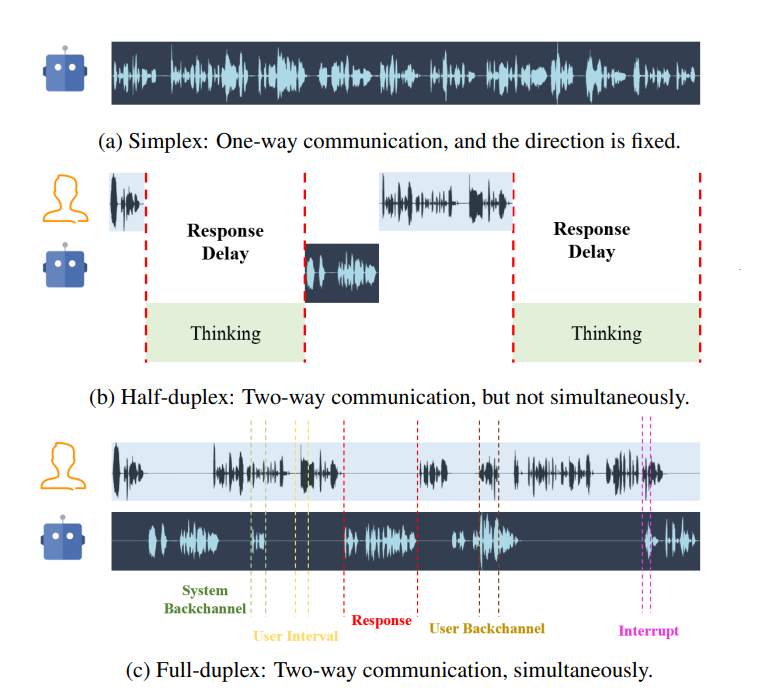
WavChat: A Survey of Spoken Dialogue Models
② 拒绝“人工智障”,怎么练?
高情商对话不光靠代码,还靠场景化数据喂养:从被打断时的自然接话,到语气停顿的智能等待,再到多轮对话的情绪连贯性——只有海量真人交互数据,才能让AI学会“人类沟通密码”。
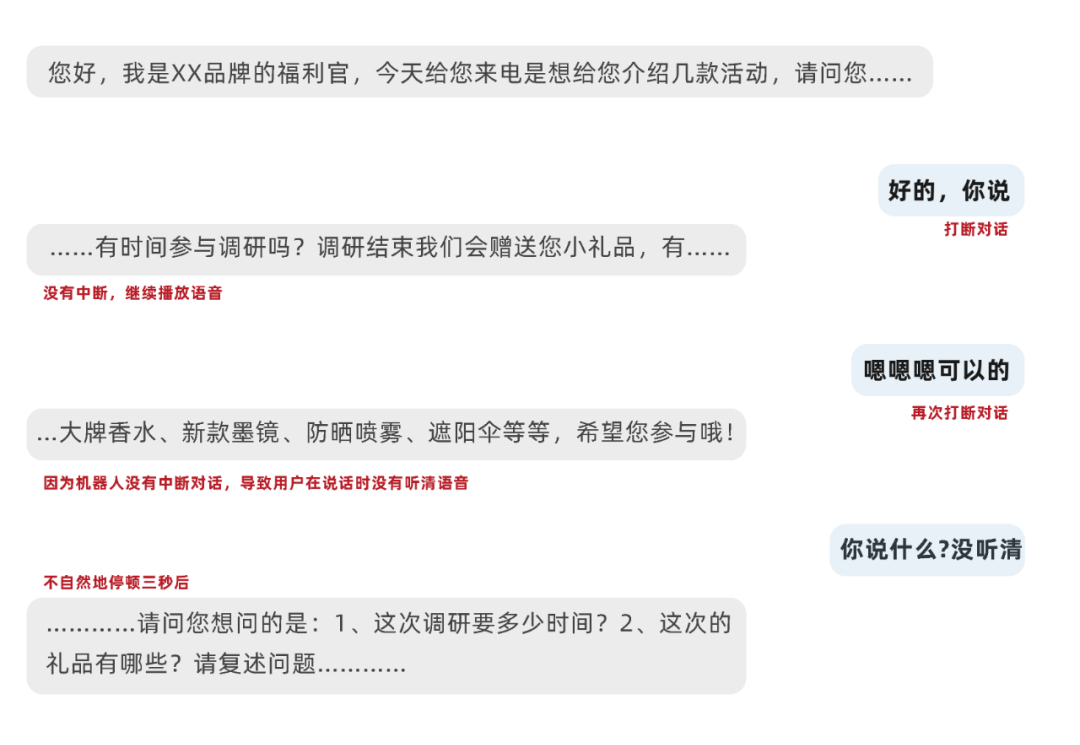
③ 怕噪音?怕口音?技术破局点在这
真正的工业级应用,必须扛住现实场景中的突发咳嗽、背景音乐、方言混杂。多模态消歧数据+噪声对抗训练,才是语音模型“抗压”的核心武器。
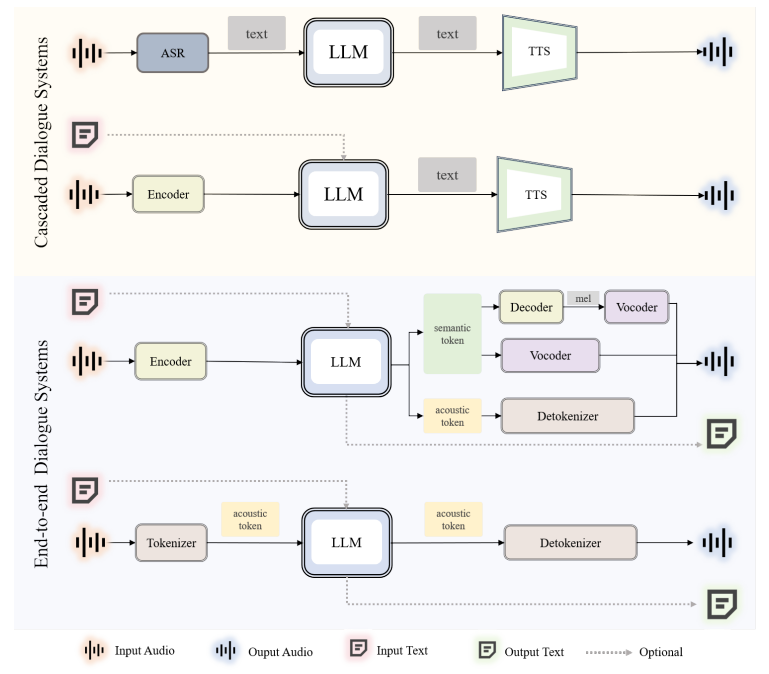
WavChat: A Survey of Spoken Dialogue Models
“数据荒”爆发:巨头都不敢说的行业痛点
全双工技术的跃进,让全球AI公司陷入新一轮焦虑:
· 高质量语音对话数据稀缺:大多数开源数据集仅支持单轮问答,缺乏真实交互的“断续性”、“即兴性”;
· 标注成本指数级攀升:需同步标注语音波形、文本语义、情绪标签、上下文逻辑,1小时录音=普通数据10倍工时;
· 隐私合规雷区:市面数据来源不明,稍有不慎可能引发法律纠纷。
🔥 破局者:海天瑞声高质量双工自然对话数据

✅ 3.2万小时真实场景录音:
每段对话10~60分钟,录音人均为专业发音人,录音人年龄、性别、音节、音素、音调平衡覆盖。
✅ 20+领域及场景:
对话围绕电商、金融、车载、医疗、家庭、娱乐、教育、运动、购物等20多个领域。
✅ 70+语种及方言:
包括中文及方言、英语、法语、德语、西班牙语、葡萄牙语、捷克语、日语、阿拉伯语、马来语、印地语、泰米尔语、泰卢固语、土耳其语、丹麦语、冰岛语等。
✅ 专业分轨采标数据处理:
专业分轨技术进行音频录制,确保每位发音人拥有独立音轨,覆盖对话打断、话轮抢接、多人交互等复杂场景。数据包含多种标注维度,包括:语音特征标注(副语言现象、发音清晰度)、逐字转写文本与时间轴对齐、说话人元数据(身份标识、性别、音色特征)、环境标注(背景噪声分类与时间定位)以及特殊场景标记(语音重叠、即兴插话等)。
人机实时双向交互时代已开启,数据质量将成为决定模型终局排位的重要因素。真实、多样、高质量的高质量双工自然对话数据,能让模型更精准地捕捉人类语言的复杂性与情感色彩,进而实现更自然、流畅的交互体验,在千行百业释放更大潜力。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









