






“Giga”一词源于“gigantic”,互联网上具有海量音频资源,但语音质量良莠不齐,高质量音频文本对数据十分稀缺且标注成本高昂,特别是在小语种领域。GigaSpeech 是一个非常成功的英文开源数据集,以 YouTube 和 Podcast 为音频来源,提供了上万小时的高质量文本标注语音数据集,获得了广泛关注和应用。针对多语言领域仍存在的语音识别性能较差、可用高质量标注数据缺乏等问题,我们提出了利用 in-the-wild 无标注音频,构建高质量大规模语音识别数据集的新范式,制作出面向真实场景的大规模、多领域、多语言的语音识别数据集 GigaSpeech 2。基于Gigaspeech 2 数据集训练的语音识别模型在三个东南亚语种(泰语、印尼语、越南语)上达到了媲美商业语音识别服务的性能。我们怀揣着技术应当普惠大众的理念,致力于开源高质量语音识别数据集和模型,促进多语言文化沟通。

1. 概述
上海交通大学跨媒体语言智能实验室(X-LANCE)、SpeechColab、香港中文大学、清华大学语音与音频技术实验室(SATLab)、鹏城实验室、海天瑞声(Dataocean AI)、思必驰(AISpeech)、Birch AI、Seasalt AI 共同合作开发了 GigaSpeech 2。GigaSpeech 2 是一个持续扩展的、多领域多语言的大规模语音识别语料库,旨在促进低资源语言语音识别领域的发展和研究。GigaSpeech 2 raw 拥有 30000 小时的自动转录音频,涵盖泰语、印尼语、越南语。经过多轮精炼和迭代,GigaSpeech 2 refined 拥有 10000 小时泰语、6000 小时印尼语、6000 小时越南语。我们也开源了基于 GigaSpeech 2 数据训练的多语种语音识别模型,模型性能达到了商业语音识别服务水平。
2. 数据集构建
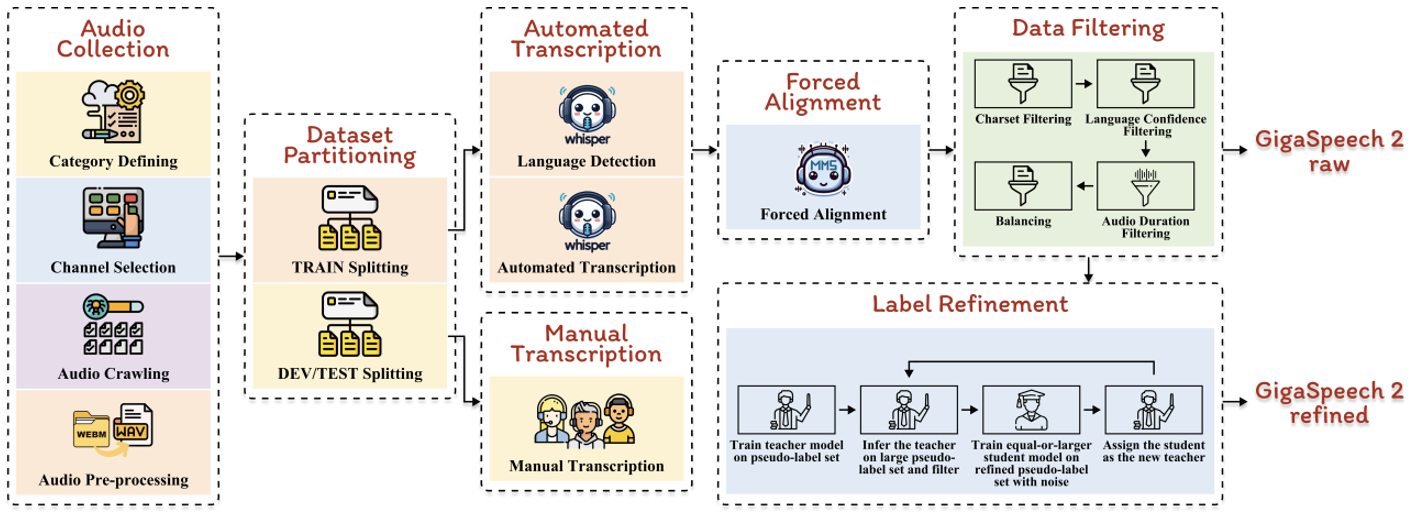
GigaSpeech 2 的制作流程也已同步开源,这是一个自动化构建大规模语音识别数据集的流程,面向互联网上的海量无标注音频,自动化地爬取数据、转录、对齐、精炼。这一流程包含利用 Whisper 进行初步转录,使用 TorchAudio 进行强制对齐,经过多维度过滤制作出 GigaSpeech 2 raw。随后,采用改进的 Noisy Student Training (NST) 方法,通过反复迭代精炼伪标签,持续提高标注质量,最终制作出 GigaSpeech 2 refined。
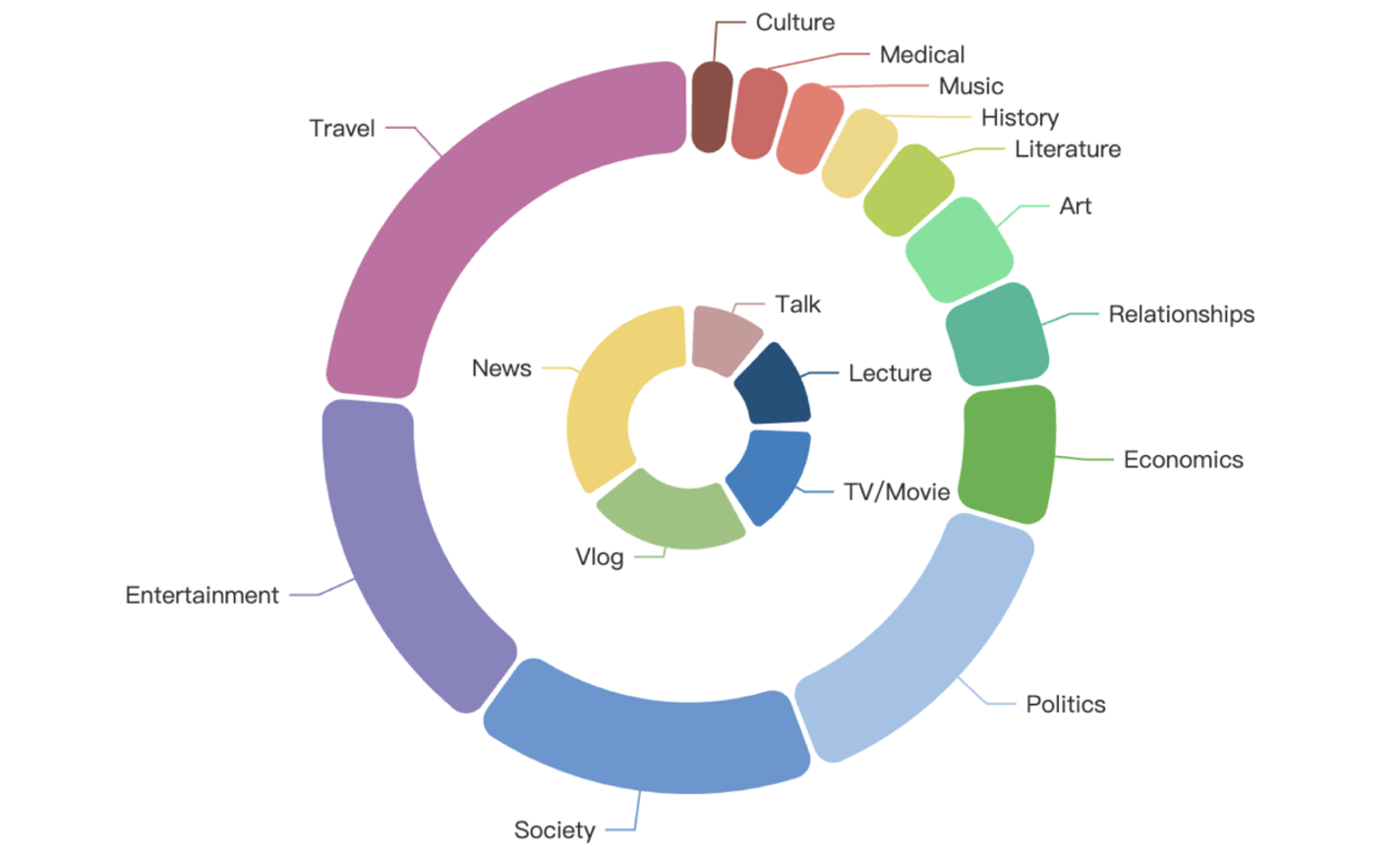
GigaSpeech 2 在主题上涵盖了多样化话题领域,包括农业、艺术、商业、气候、文化、经济、教育、娱乐、健康、历史、文学、音乐、政治、两性关系、购物、社会、体育、科技和旅行。同时,在内容形式上涵盖了多种类型,包含声书、解说、讲座、独白、电影电视剧、新闻、访谈、视频博客。
3. 训练集详情
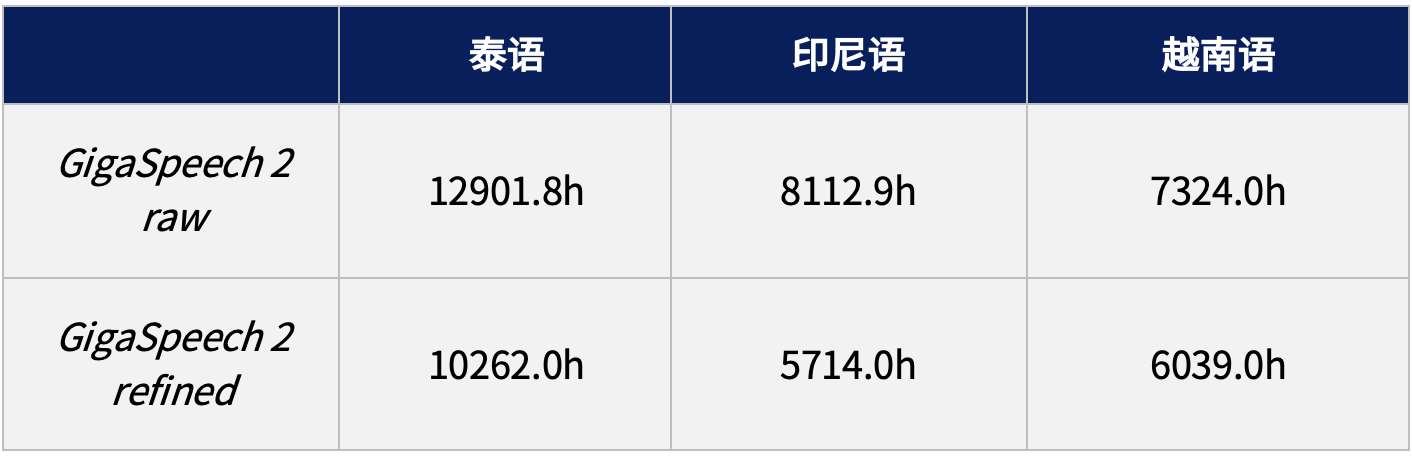
GigaSpeech 2 提供了两个版本的数据集,分别为 raw 和 refined 版本,适用于有监督训练任务。训练集时长详情如下表所示:
4. 开发集和测试集详情
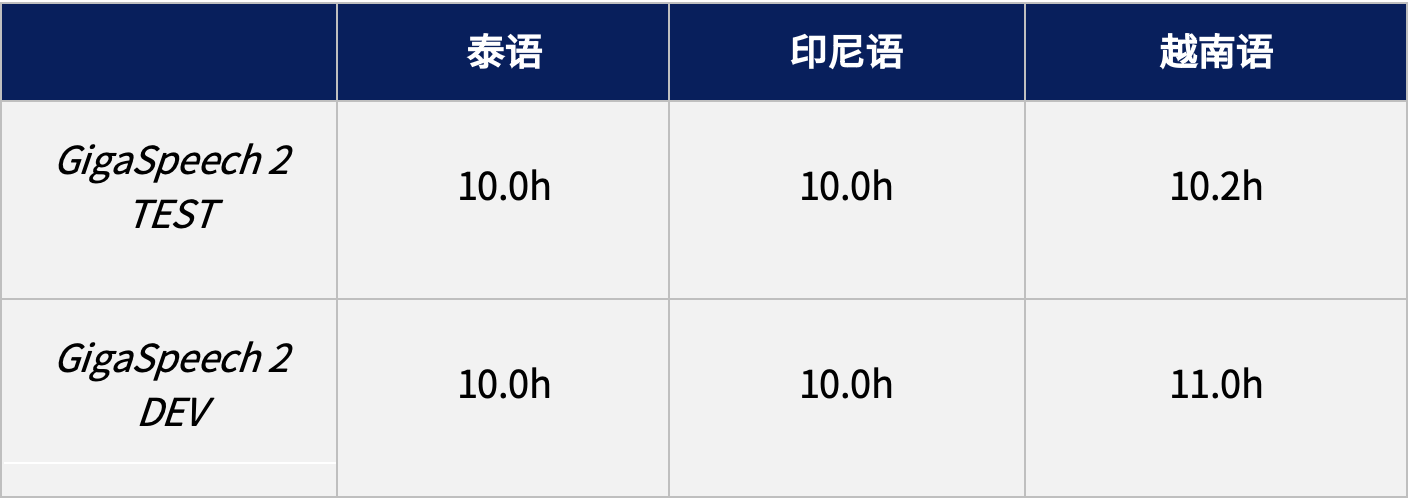
GigaSpeech 2 开发集和测试集由海天瑞声的专业人员对语音数据人工标注得到,时长详情如下表所示:
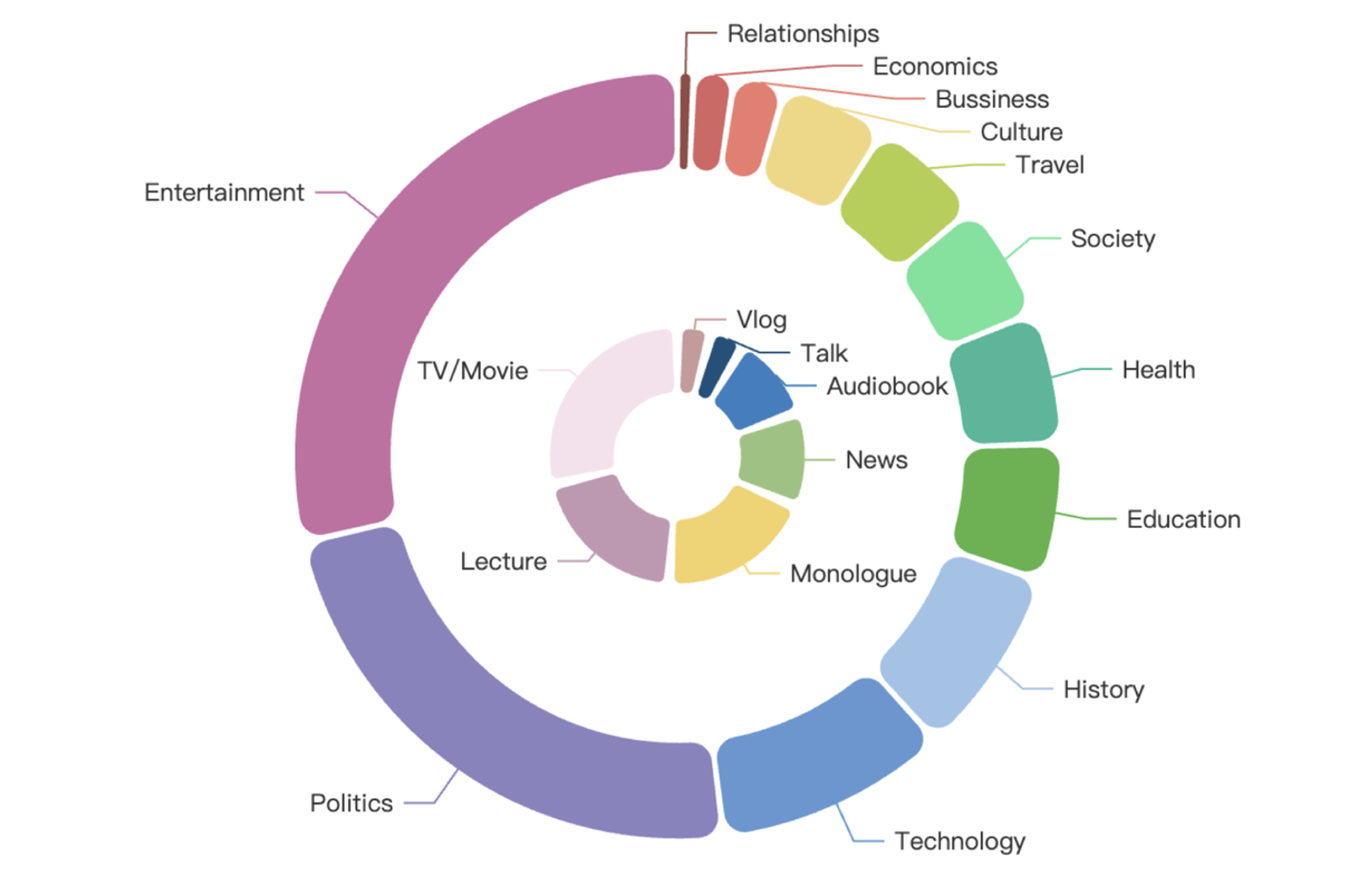
主题和内容分布详情如下图所示,外圈表示主题领域,内圈表示内容形式:
 泰语
泰语
 印尼语
印尼语
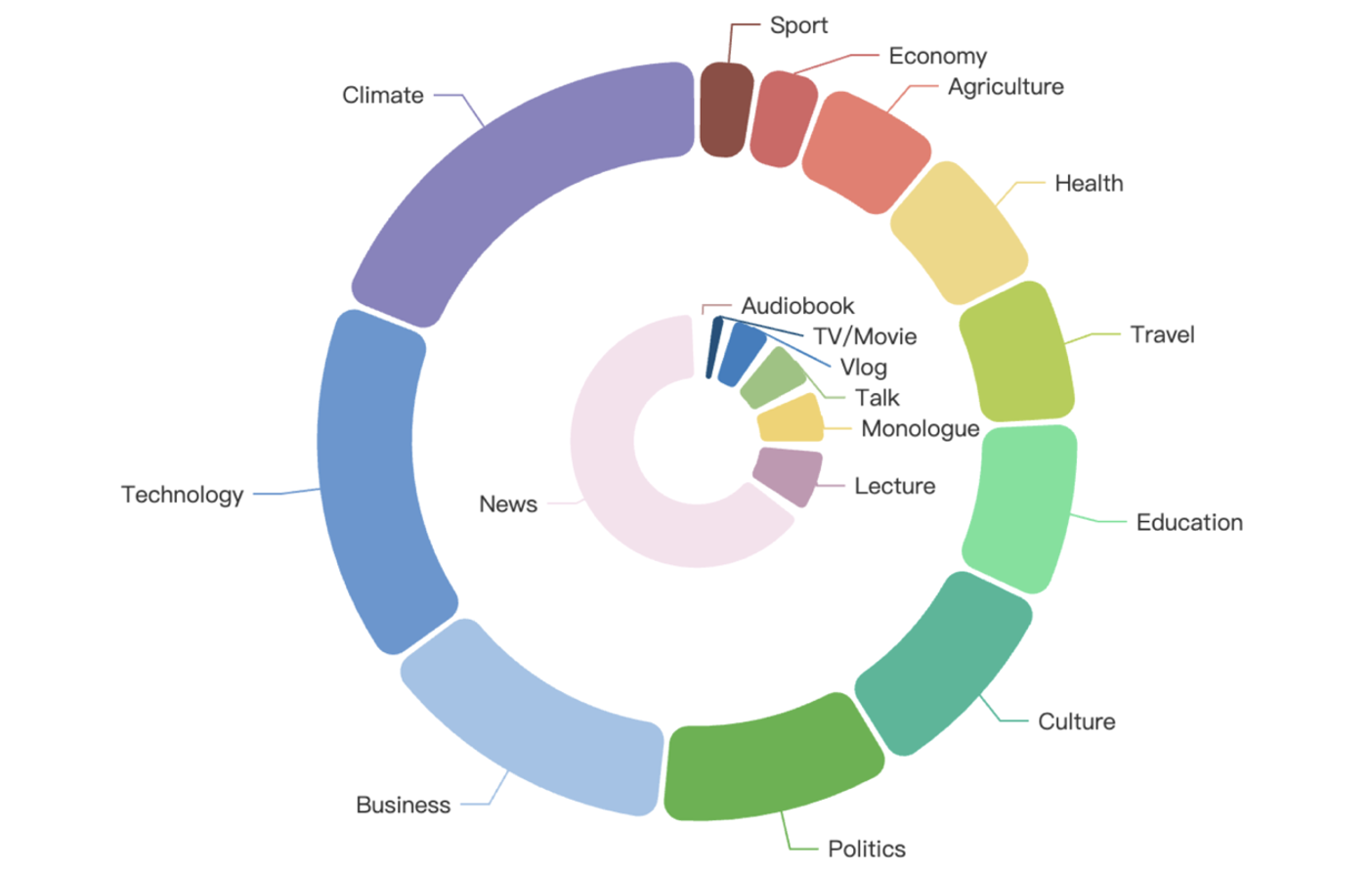 越南语
越南语
5. 实验结果
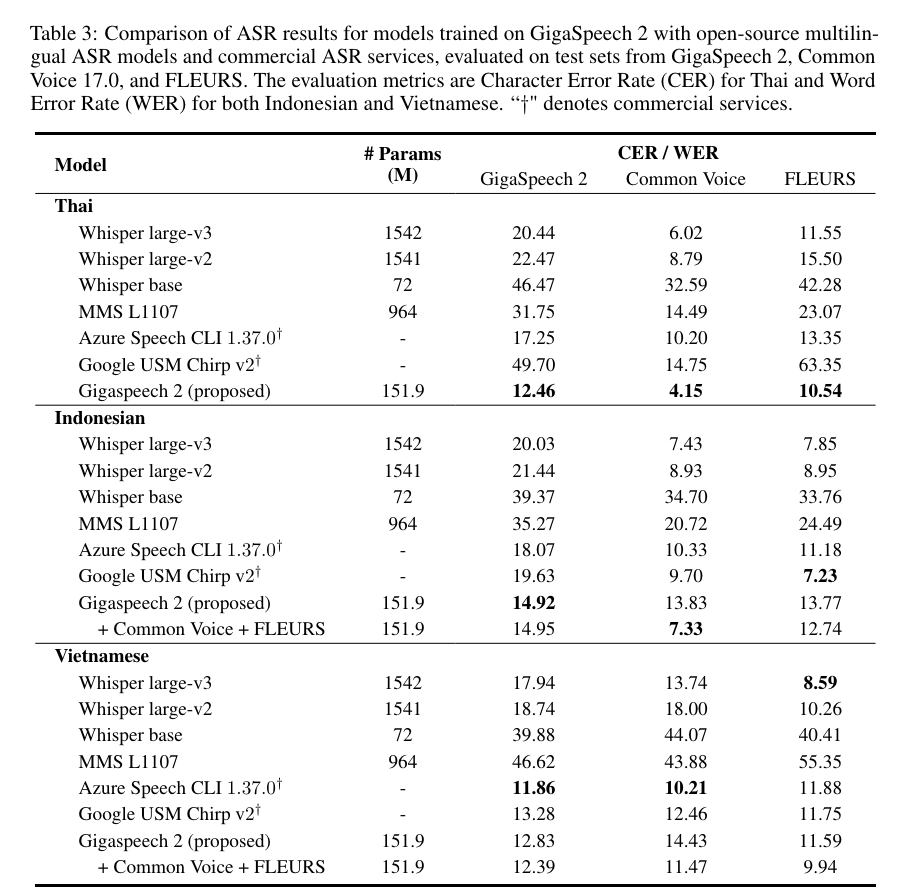
我们将使用 GigaSpeech 2 数据集训练的语音识别模型与业界领先的 OpenAI Whisper (large-v3、large-v2、base)、Meta MMS L1107、Azure Speech CLI 1.37.0 和 Google USM Chirp v2 模型在泰语、印尼语和越南语上进行比较。性能评估基于 GigaSpeech 2、Common Voice 17.0 以及 FLEURS 三个测试集,通过字符错误率(CER)或单词错误率(WER)指标进行评估。结果表明:
1)在泰语上,我们的模型展现出卓越的性能,全面超越了所有竞争对手,包括微软和谷歌商用接口。值得一提的是,我们的模型在达到这一显著成果的同时,参数量仅为 Whisper large-v3 的十分之一。
2)在印尼语和越南语上,我们的系统与现有的基线模型相比表现出具有竞争力的性能。
6. 排行榜
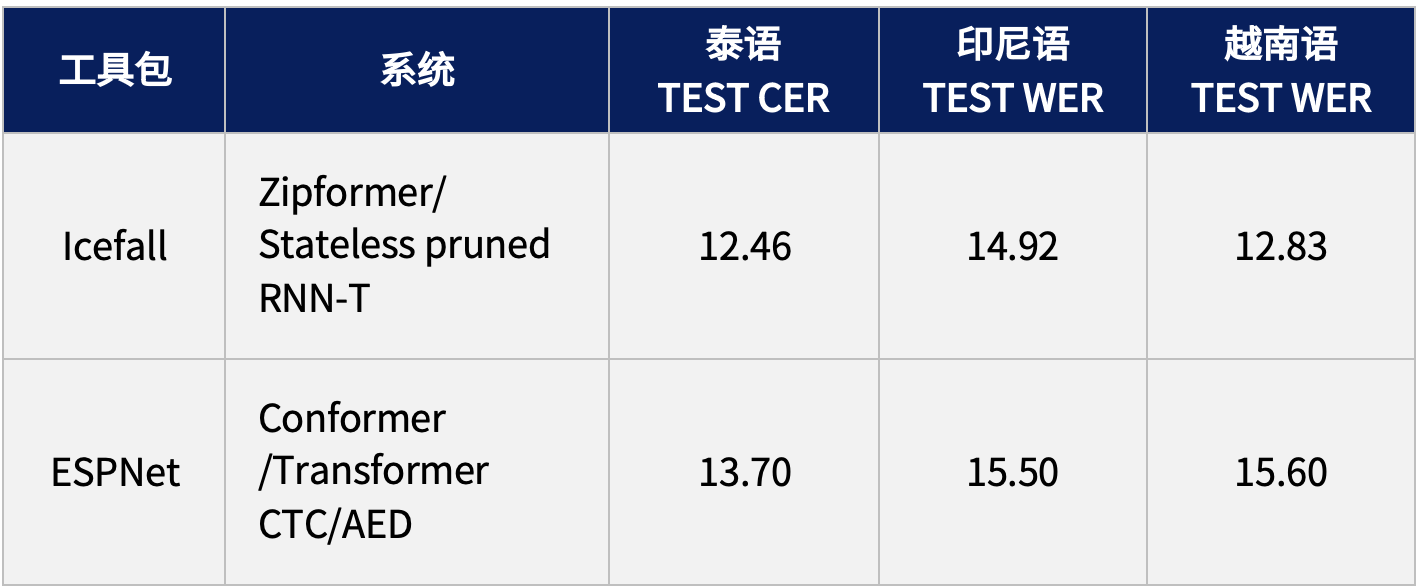
为了便于使用和跟踪最新的技术发展,GigaSpeech 2 基于主流的语音识别框架提供了基线的训练脚本,并开放了排行榜,目前提供的系统包括 Icefall 和 ESPNet,后续还将继续更新与完善。
7. 资源链接
GigaSpeech 2 数据集已开放,欢迎大家下载:
https://huggingface.co/datasets/speechcolab/gigaspeech2
大规模语音识别数据集自动化构建流程发布于:
GitHub - SpeechColab/GigaSpeech2: An evolving, large-scale and multi-domain ASR corpus for low-resource languages with automated crawling, transcription and refinement
预印版论文发布于:
https://arxiv.org/pdf/2406.11546
8. 进一步合作
我们是一群试图让语音技术更易于使用的志愿者,欢迎各种形式的合作与贡献。目前我们正在探索以下方向,如果您对某些方向感兴趣,并且认为自己能够提供帮助,请联系 gigaspeech@speechcolab.org。
-
不同预训练模型的推理架构
-
增加多样化的数据来源
-
对语音算法/服务进行基准测试
-
构建和发布预训练模型
-
支持更多语言
-
支持更多任务
-
制作新数据集

















 184
184

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









