






 本文深入探讨了LDA(隐含狄利克雷分配)模型,一种用于识别大规模文档集中潜在主题的非监督机器学习技术。文章介绍了LDA模型的基本原理,包括其三层贝叶斯概率结构和生成过程。此外,还提供了使用Python实现LDA模型的详细步骤,涵盖了数据预处理、模型训练和结果分析。
本文深入探讨了LDA(隐含狄利克雷分配)模型,一种用于识别大规模文档集中潜在主题的非监督机器学习技术。文章介绍了LDA模型的基本原理,包括其三层贝叶斯概率结构和生成过程。此外,还提供了使用Python实现LDA模型的详细步骤,涵盖了数据预处理、模型训练和结果分析。
1.LDA模型简介(节选自百度百科)
LDA(Latent Dirichlet Allocation)是一种文档主题生成模型,也称为一个三层贝叶斯概率模型,包含词、主题和文档三层结构。所谓生成模型,就是说,我们认为一篇文章的每个词都是通过“以一定概率选择了某个主题,并从这个主题中以一定概率选择某个词语”这样一个过程得到。文档到主题服从多项式分布,主题到词服从多项式分布。
LDA是一种非监督机器学习技术,可以用来识别大规模文档集(document collection)或语料库(corpus)中潜藏的主题信息。它采用了词袋(bag of words)的方法,这种方法将每一篇文档视为一个词频向量,从而将文本信息转化为了易于建模的数字信息。但是词袋方法没有考虑词与词之间的顺序,这简化了问题的复杂性,同时也为模型的改进提供了契机。每一篇文档代表了一些主题所构成的一个概率分布,而每一个主题又代表了很多单词所构成的一个概率分布。
2.LDA生成过程(节选自百度百科)
对于语料库中的每篇文档,LDA定义了如下生成过程(generativeprocess):
1.对每一篇文档,从主题分布中抽取一个主题;
2.从上述被抽到的主题所对应的单词分布中抽取一个单词;
3.重复上述过程直至遍历文档中的每一个单词。
语料库中的每一篇文档与T(通过反复试验等方法事先给定)个主题的一个多项分布 (multinomialdistribution)相对应,将该多项分布记为θ。每个主题又与词汇表(vocabulary)中的V个单词的一个多项分布相对应,将这个多项分布记为φ。
3.LDA模型实践(Python)
导入所需库
import pandas as pd
import re
import jieba
from gensim import corpora, models, similarities
from pprint import pprint
import numpy as np
import time
输入处理数据
data2 = pd.read_excel('1.xlsx')
data2_lda = data2['详情']
data2_lda.shape
data2_lda.drop_duplicates()
机械压缩
def condense_1(str):
for i in [1,2]:
j=0
while j < len(str)-2*i:
#判断至少出现了两次
if str[j:j+i] == str[j+i:j+2*i] and str[j:j+i] == str[j+2*i:j+3*i]:
k= j+2*i
while k+i<len(str) and str[j:j+i]==str[k+i:k+2*i]:
k+=i
str =str[:j+i]+str[k+i:]
j+=1
i+=1
for i in [3,4,5]:
j=0
while j < len(str)-2*i:
#判断至少出现了一次
if str[j:j+i] == str[j+i:j+2*i]:
k= j+i
while k+i<len(str) and str[j:j+i]==str[k+i:k+2*i]:
k+=i
str =str[:j+i]+str[k+i:]
j+=1
i+=1
return str
数据筛选
def chuli_lda(a):#筛选数据
a.astype('str').apply(lambda x:len(x)).sum() # 统计字符长度
data1 = a.astype('str').apply(lambda x: condense_1(x)) # 去除重复词
data1.apply(lambda x: len(x)).sum()
data2 = data1.apply(lambda x: len(x))
data3 = pd.concat((data1, data2), axis = 1) # 合并
data3.columns = ['详情','字符长度']
data4 = data3.loc[data3['字符长度'] > 4, '详情'] # 筛选长度大于4的评论
return data4
data_lda = chuli_lda(data2_lda)
data_lda
中文分词
jieba.load_userdict('热点\建设.txt')
定义停用词过滤函数
def after_stop(data):
#添加词典,去掉停用词
data_cut=data.apply(lambda x:jieba.lcut(str(x)))#lcut(x)表示给x分词,并且返回列表形式
stopWords=pd.read_csv('stopword.txt',encoding='GB18030',sep='hahaha',header=None,engine='python')
#此时注意用词里面的,不被作为分隔符
stopWords=['≮', '≯', '≠', '≮', ' ', '会', '月', '日', '–']+list(stopWords.iloc[:,0])
#将停用词添加在所有行额第0列中
data_after_stop=data_cut.apply(lambda x:[i for i in x if i not in stopWords])
return data_after_stop
data_lda_after_stop = after_stop(data_lda)
data_lda_after_stop.to_csv('data_lda_after_stop.csv',encoding='utf-8')
加载停用词表
def load_stopword():#加载停用词表
f_stop = open('stopword.txt')
sw = [line.strip() for line in f_stop]
f_stop.close()
return sw
主程序
if __name__ == '__main__':
print('1.初始化停止词列表 ------')
# 开始的时间
t_start = time.time()
# 加载停用词表
stop_words = load_stopword()
print('2.开始读入语料数据 ------ ')
# 读入语料库
f = open('data_lda_after_stop.csv','rb')
# 语料库分词并去停用词
texts = [[word for word in line.strip().lower().split() if word not in stop_words] for line in f]
print('读入语料数据完成,用时%.3f秒' % (time.time() - t_start))
f.close()
M = len(texts)
print('文本数目:%d个' % M)
print('3.正在建立词典 ------')
print ('4.正在计算文本向量 ------')
# 转换文本数据为索引,并计数
corpus = [dictionary.doc2bow(text) for text in texts]
print ('5.正在计算文档TF-IDF ------')
t_start = time.time()
# 计算tf-idf值
corpus_tfidf = models.TfidfModel(corpus)
print ('建立文档TF-IDF完成,用时%.3f秒' % (time.time() - t_start))
print ('6.LDA模型拟合推断 ------')
# 训练模型
num_topics = 30
t_start = time.time()
lda = models.LdaModel(corpus_tfidf, num_topics=num_topics, id2word=dictionary,
alpha=0.01, eta=0.01, minimum_probability=0.001,
chunksize = 100, passes = 1)
print('LDA模型完成,训练时间为\t%.3f秒' % (time.time() - t_start))
# 随机打印某10个文档的主题
num_show_topic = 10 # 每个文档显示前几个主题
print('7.结果:10个文档的主题分布:--')
doc_topics = lda.get_document_topics(corpus_tfidf) # 所有文档的主题分布
idx = np.arange(M)
np.random.shuffle(idx)
idx = idx[:10]
for i in idx:
topic = np.array(doc_topics[i])
topic_distribute = np.array(topic[:, 1])
# print topic_distribute
topic_idx = topic_distribute.argsort()[:-num_show_topic-1:-1]
print ('第%d个文档的前%d个主题:' % (i, num_show_topic)), topic_idx
print(topic_distribute[topic_idx])
num_show_term = 7 # 每个主题显示几个词
print('8.结果:每个主题的词分布:--')
for topic_id in range(num_topics):
print('主题#%d:\t' % topic_id)
term_distribute_all = lda.get_topic_terms(topicid=topic_id)
term_distribute = term_distribute_all[:num_show_term]
term_distribute = np.array(term_distribute)
term_id = term_distribute[:, 0].astype(np.int)
print('词:\t',)
for t in term_id:
print(dictionary.id2token[t],)
print('\n概率:\t', term_distribute[:, 1])
运行结果展示
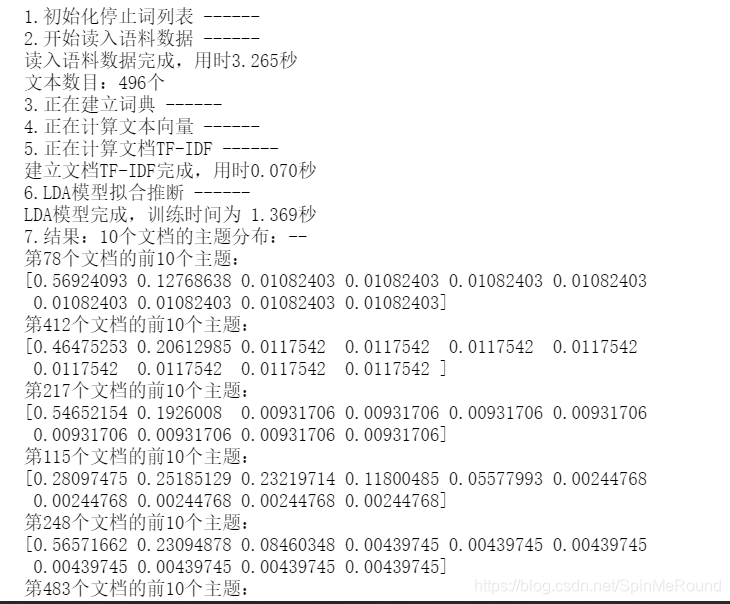


















 2241
2241

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









