







✨✨ 欢迎大家来访Srlua的博文(づ ̄3 ̄)づ╭❤~✨✨🌟🌟 欢迎各位亲爱的读者,感谢你们抽出宝贵的时间来阅读我的文章。
我是Srlua小谢,在这里我会分享我的知识和经验。🎥
希望在这里,我们能一起探索IT世界的奥妙,提升我们的技能。🔮
记得先点赞👍后阅读哦~ 👏👏
📘📚 所属专栏:传知代码论文复现
欢迎访问我的主页:Srlua小谢 获取更多信息和资源。✨✨🌙🌙



目录
本文所有资源均可在该地址处获取。
概述
视觉语言预训练(VLP)提高了许多视觉语言任务的性能。然而,大多数现有的预训练任务只擅长基于理解的任务或者基于生成的任务。此外,同时使用Web收集的有噪声的图像-文本对来扩展数据集虽然在很大程度上提高了性能,但这是一个次优的监督来源。
BLIP是一个新的VLP框架,它可以灵活的转移到视觉语言理解和生成任务。BLIP通过引导字幕有效地利用了有噪声的网络数据,其中字幕生成器生成合成字幕,滤波器去除有噪声的字幕。
模型结构
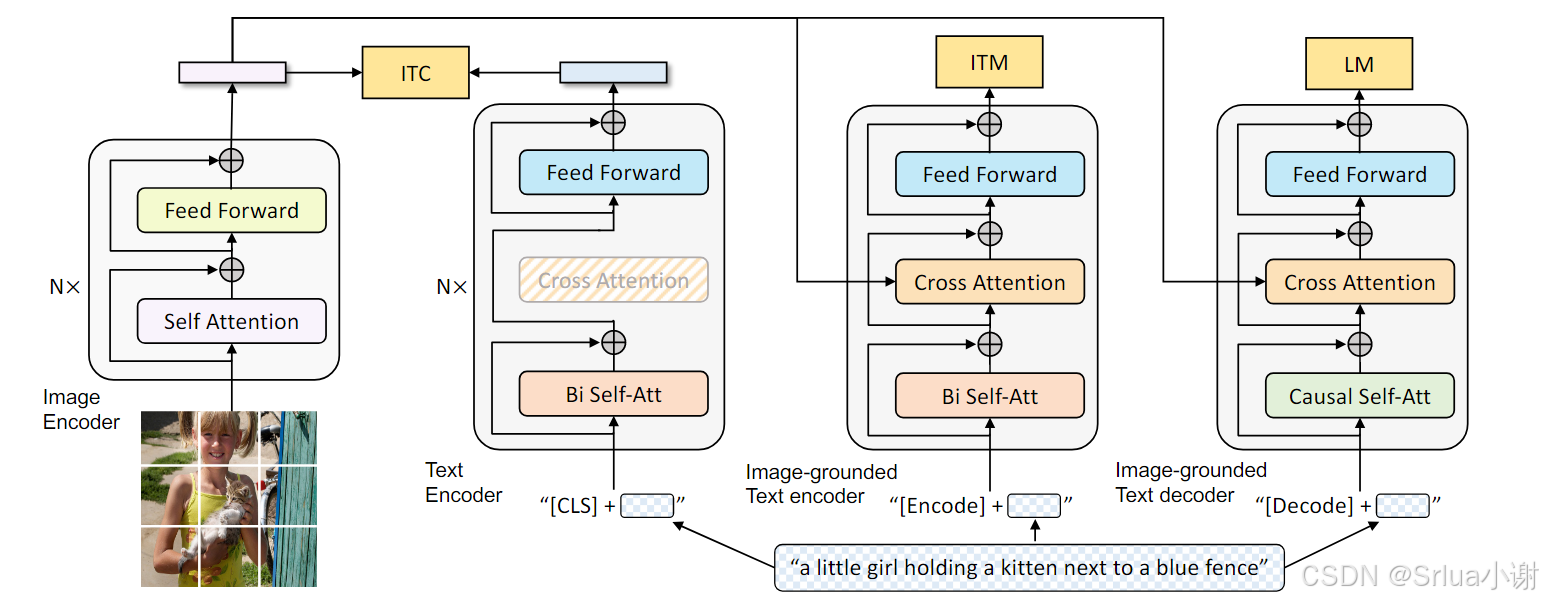
图中颜色一样的结构参数共享
BLIP使用ViT模型作为图像编码器,ViT将输入图像划分为补丁块,并将其编码为嵌入序列,使用额外的[cls]标记来表示全局图像特征。为了预训练具有理解和生成能力的统一模型,BLIP提出了编码器-解码器的多模式混合(MED),这是一种可以在一下三种功能之一运行的多任务模型:
单峰编码器
单峰式编码器分别对图像和文本进行编码,文本编码器与BERT相同,其中[CLS]标记被附加到文本输入的开头,以总结句子。BLIP使用图像-文本对比(ITC)损失的训练单峰编码器,以对齐视觉和语言表示。
基于图像的文本编码器
基于图像的文本编码器,同时在文本编码器的每个transformer块的自注意力层SA和前馈网络FFN之间插入一个额外的交叉注意力层CA来注入视觉信息。特定于任务的[Encode]标记附加到文本中,[Encode]的输出嵌入用于图像-文本对的多模态表示。基于图像的文本编码器使用图像-文本匹配(ITM)损失进行训练,以区分匹配和不匹配的图像-文本对。
基于图像的文本解码器
基于图像的文本解码器以因果自注意力层取代双向自注意力层,一个[Decode]标记用于表示序列的开始,一个序列结束标记用于表示序列的结束。基于图像的文本解码器使用语言建模(LM)损失进行训练,以生成给定图像的标题。
预训练目标函数
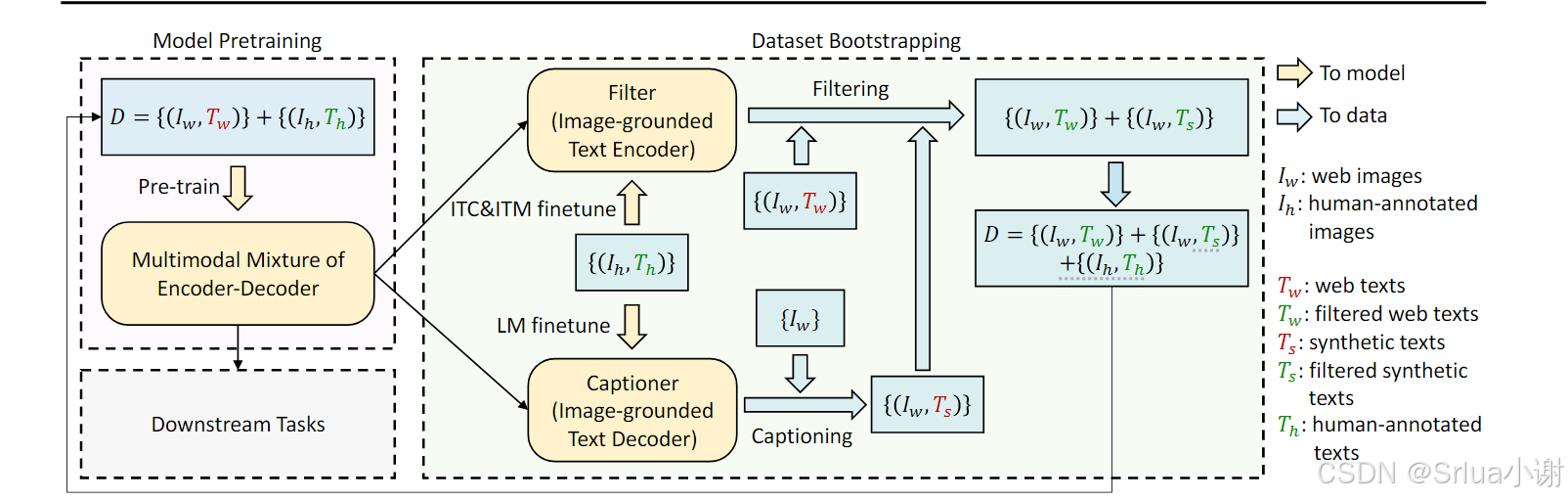
BLIP在预训练中共同优化了三个目标函数,两个基于理解的目标函数和一个基于生成的目标函数。每个图像-文本对只需要通过计算量较大的ViT进行一次前向传递,并通过文本转换器进行三次前向传递,用以激活不同的功能以计算如下所述的三种损失。
-
图像-文本对比损失(ITC)
图像-文本对比损失激活单峰编码器,它的目的是通过鼓励匹配的图像-文本对具有相似的表示,不匹配的图像-文本对具有差异较大的表示来对齐视觉转换器和文本转换器的特征空间。 -
图像-文本匹配损失(ITM)
图像-文本匹配损失激活基于图像的文本编码器,它旨在学习图像-文本多模态表示,以捕获视觉和语言之间的细粒度对齐。ITM是一个二元分类任务,模型使用ITM头部(线性层)来预测给定图像-文本对的多模态特征是匹配的,还是负的不匹配的。 -
语言建模损失(LM)
语言建模损失激活基于图像的文本解码器,其目的是生成给定图像的文本描述。该损失训练模型以自回归的方式最大化文本的可能性,优化了交叉熵损失
为了在利用多任务学习的同时执行有效的预训练,文本编码器和文本解码器共享除了自注意力层之外的所有参数,因为编码和解码任务之间的差异最好由自注意力层捕获。编码和解码任务之间的嵌入层,自注意力层和全连接前馈网络层的作用相似,因此,共享这些层可以提高训练效率,同时受益于多任务学习。
CapFilt
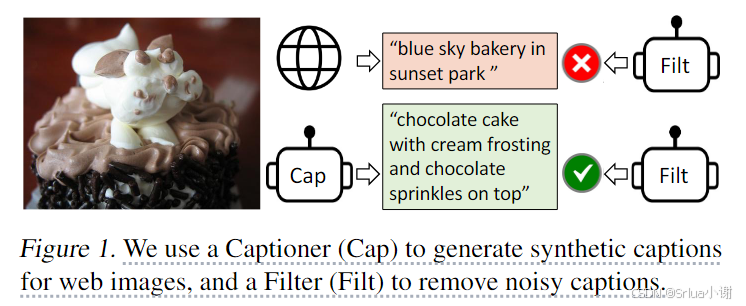
由于标注成本过高,高质量的人工标注图像-文本对的数量有限{(Ih,Th)}{(Ih,Th)},最近的工作使用了大量从网络上搜取的图像和替代文本对{(Iw,Tw)}{(Iw,Tw)}。然而,替代文本通常不能准确的描述图像的视觉内容,使他们成为一个嘈杂的信号,对于学习视觉对齐来说是次优的。
BLIP提出了Captioning 和Filtering(CapFilt),这是一种提高文本语料库质量的新方法,它引入了两个模块,一个用于生成给定web图像的标题的captioner,以及一个用于去除图像-文本对噪声的filter。captioner和filter都是从相同的预训练的MED模型初始化的,并在COCO数据集上分别进行微调,调优是一个轻量级的过程。
具体来说,captioner是一个基于图像的文本解码器,它使用LM目标函数进行微调,以解码给定图像的文本。给定web图像IwIw,captioner生成合成的标题TsTs。filter是一个基于图像的文本编码器,它使用ITC和ITM目标函数进行微调,以确定文本是否与图像匹配。如果标题预测文本与图像不匹配,则认为文本有噪声,过滤器去除原始网络文本和合成文本中的噪声文本。最后,BLIP将过滤后的图像文本对于人工注释的图像文本对结合起来形成一个新的数据集,使用它来训练一个新的模型。
演示效果
BLIP对整个图像的关注程度可视化
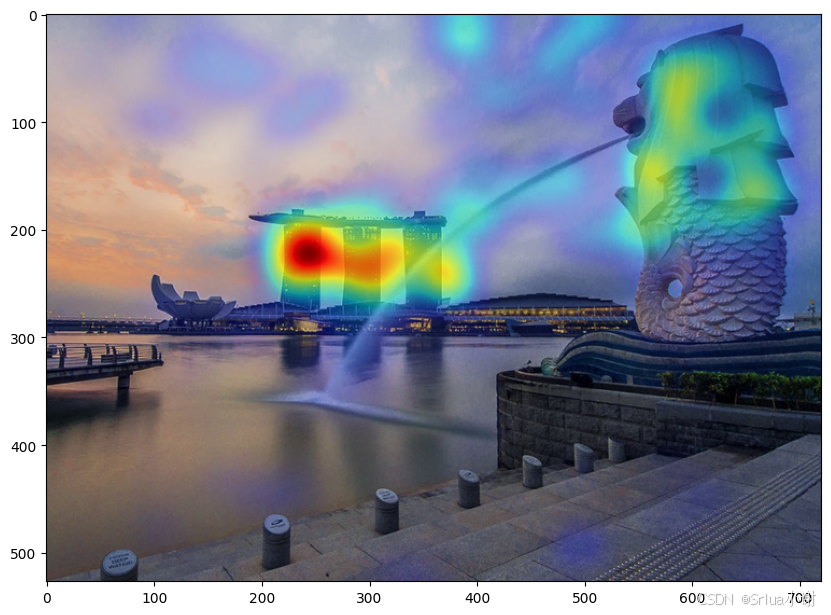
BLIP对局部分词的关注程度

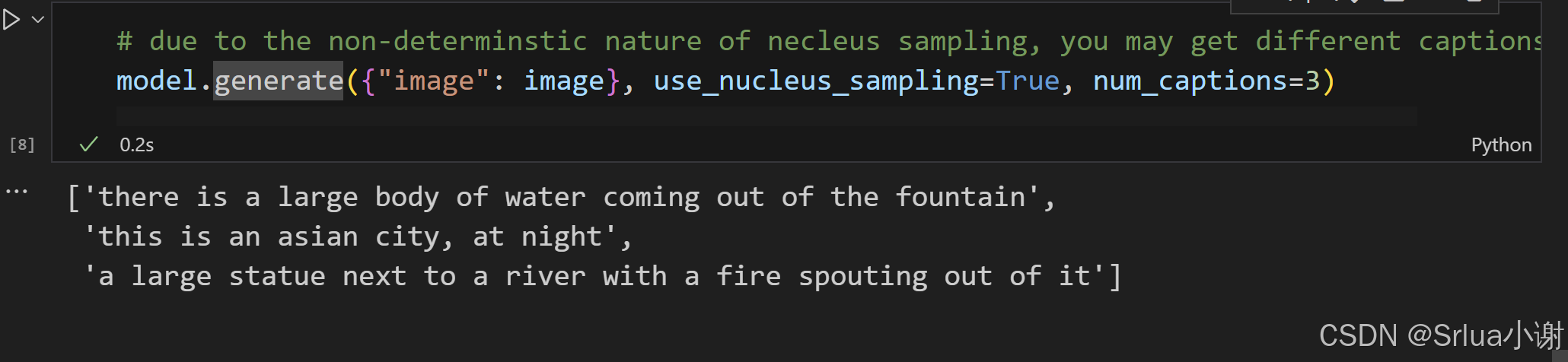
BLIP生成多个标题
核心逻辑
在这里可以粘贴您的核心代码逻辑:
BLIP生成标题
# 加载预训练好的模型
model, vis_processors, _ = load_model_and_preprocess(
name="blip_caption", model_type="large_coco", is_eval=True, device=device
)
# 以下是其他可以使用的模型
# model, vis_processors, _ = load_model_and_preprocess(
# name="blip_caption", model_type="base_coco", is_eval=True, device=device
# )
# 对图像进行预处理操作
image = vis_processors["eval"](raw_image).unsqueeze(0).to(device)
# 采用核函数采样生成多个标题
model.generate({"image": image}, use_nucleus_sampling=True, num_captions=3)
BLIP可视化
# 加载预训练模型
# model, vis_processors, text_processors = load_model_and_preprocess("blip_image_text_matching", "base", device=device, is_eval=True)
model, vis_processors, text_processors = load_model_and_preprocess("blip_image_text_matching", "large", device=device, is_eval=True)
# 准备操作
from matplotlib import pyplot as plt
from lavis.common.gradcam import getAttMap
from lavis.models.blip_models.blip_image_text_matching import compute_gradcam
import numpy as np
dst_w = 720
w, h = raw_image.size
scaling_factor = dst_w / w
resized_img = raw_image.resize((int(w * scaling_factor), int(h * scaling_factor)))
norm_img = np.float32(resized_img) / 255
# 分别处理图像和文本
img = vis_processors["eval"](raw_image).unsqueeze(0).to(device)
txt = text_processors["eval"](caption)
# 计算梯度
txt_tokens = model.tokenizer(txt, return_tensors="pt").to(device)
gradcam, _ = compute_gradcam(model, img, txt, txt_tokens, block_num=7)
# 计算整个图像的梯度并且可视化
avg_gradcam = getAttMap(norm_img, gradcam[0][1].numpy(), blur=True)
# fig, ax = plt.subplots(num_image, 1, figsize=(15,5*num_image))
fig, ax = plt.subplots(1, 1, figsize=(10, 10))
ax.imshow(avg_gradcam)
# 计算每一个token的梯度并且可视化
num_image = len(txt_tokens.input_ids[0]) - 2
fig, ax = plt.subplots(num_image, 1, figsize=(15, 5 * num_image))
gradcam_iter = iter(gradcam[0][2:-1].numpy())
token_id_iter = iter(txt_tokens.input_ids[0][1:-1])
for i, (gradcam, token_id) in enumerate(zip(gradcam_iter, token_id_iter)):
word = model.tokenizer.decode([token_id])
gradcam_image = getAttMap(norm_img, gradcam, blur=True)
ax[i].imshow(gradcam_image)
ax[i].set_yticks([])
ax[i].set_xticks([])
ax[i].set_xlabel(word)
部署方式
# 创建环境
conda create -n lavis python=3.8
conda activate lavis
pip install salesforce-lavis
# 进阶版包含源码
git clone https://github.com/salesforce/LAVIS.git
cd LAVIS
pip install -e .
参考文献



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









