






爬虫入门简记
前言:最近在工作当中接触了一部分爬虫任务,感谢工作安排,让我从一个爬虫原理都不懂的小白,进阶到爬取了拼夕夕海外站 Temu 商品信息的初级菜鸟,故在此进行知识总结,并方便其他小伙伴学习
相关总结只是个人理解,如有不对敬请指正
1. 爬虫原理及基础实战
-
基础原理解读
其实理解爬虫基础原理,需要包含一部分前端基础知识,包含html、css、js、http请求基础原理,对于这些有疑问的小伙伴请自行学习
首先我们先说下爬虫原理:我们web页面通过 dom 元素加载后,最终让用户可以通过访问 ip 或域名,在浏览器正常展示。这时候我们点击 F12 查看开发者工具,可以在后台看到全部 dom 元素,我们所需要的信息,基本可以在此处找到。一般我们要做的,就是通过各种手段获取这些 dom 元素,并解析他们的数据。
很多没有做过多反爬的网站,很多信息都可以通过直接读取 dom 元素加载出来,因为他们是静态的;而做过反爬的网站,可能通过请求才会加载元素,可能会对源码加密,可能通过部分埋点来检测用户行为(包含人机校验,在接触了爬虫后才明白这个东西真的能过滤很多爬虫啊),这时候就要我们总结其中规律,计划方案了,后续在 Temu 内容里细说。
-
那么接下来就进行一个基础示范:
- 运用技术:HTMLParser
- 爬取信息:爬取豆瓣电影 Top250 电影中文名称
- 步骤分析:
1) 进入爬取目标网站,通过请求的方式
r = requests.get( url, headers={ "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36", 'User-agent':'XXXXXXXXXXXXXXX', 'Cookie': 'XXXXXXXXXXXXXXXXXX' }, proxies={"all": proxy}, )2) 分析目标网站对应元素
查看页面如图所示
F12 查看电影名称
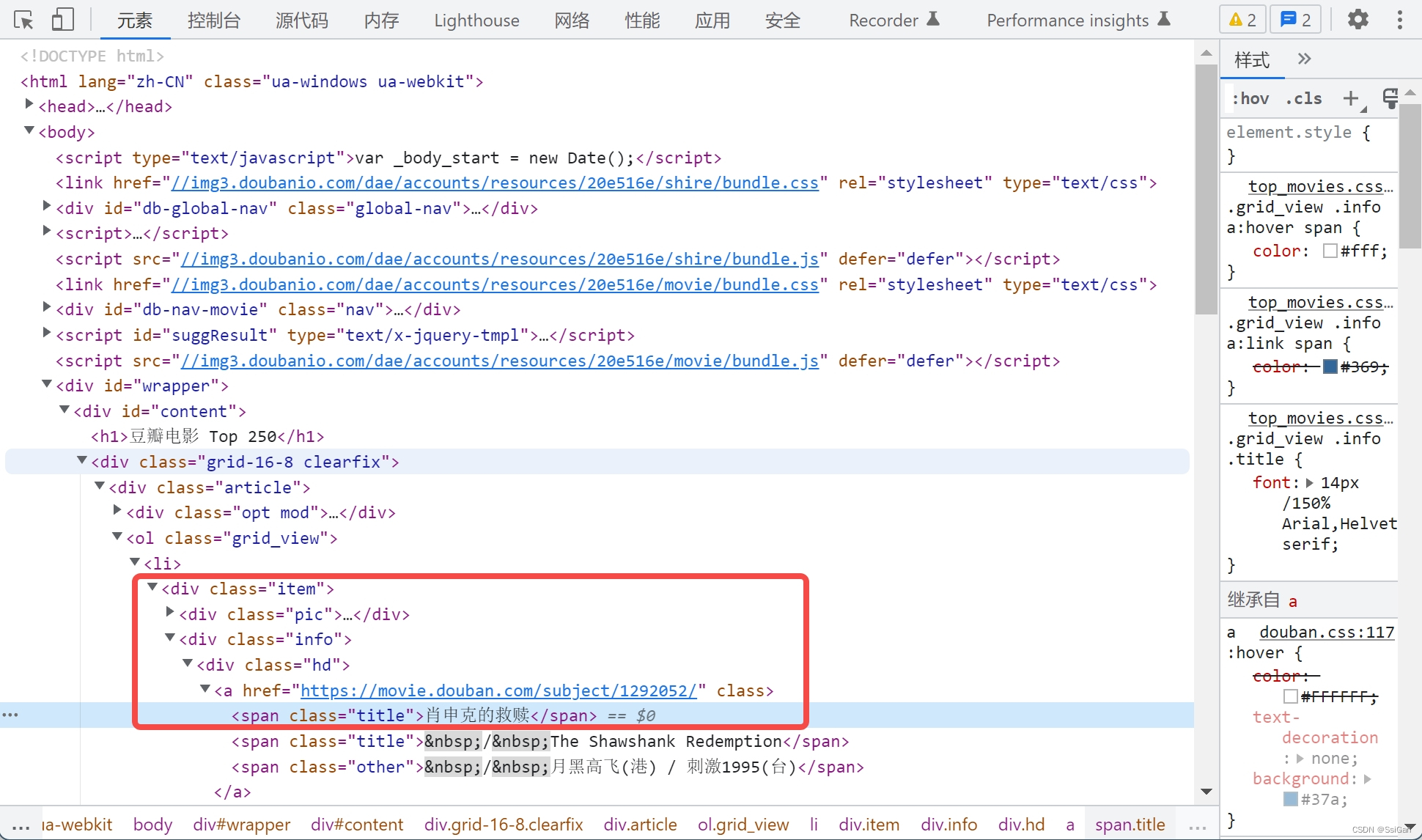
可以看到,中文电影名称,最外层依次套了几层 dom 元素,并可以看到它的 class 类名称
3) 解析 dom 元素,获取信息
抓取页面 dom 元素,解析信息root = HTMLParser(r.text) first_categorys = [] # 获取大类目及相关信息 for test in root.css(".item > .info > .hd > a"): first_categorys.append(test.css_first("span").text()) print("first_categorys:" + str(first_categorys))
- 总结下,像这样简单的网站,通过请求网页进入页面后,通过对 dom 元素分析,就可以直接解析获得需要的数据了,非常容易。关于 HTMLParser 具体语法可以自己进行查询,并且有很多可替代技术,自由选择,大同小异
完整代码如下:
import math
import requests
from selectolax.parser import HTMLParser
import re
from threading import Thread
import pandas as pd
from datetime import datetime
import time
final_list = []
proxy = "http://127.0.0.1:1006"
# 官方网址
url = "https://movie.douban.com/top250"
# 爬取大类目与小类目数据
def get_meta(url):
r = requests.get(
url,
headers={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36",
'User-agent':'XXXXXXXXXXXXXXX',
'Cookie': 'XXXXXXXXXXXXXXXXXX'
},
proxies={"all": proxy},
)
root = HTMLParser(r.text)
first_categorys = []
# 获取大类目及相关信息
for test in root.css(".item > .info > .hd > a"):
first_categorys.append(test.css_first("span").text())
print("first_categorys:" + str(first_categorys))
if __name__ == "__main__":
startTime = datetime.now()
print("开始时间:")
print(startTime)
firsts = get_meta(url)
endTime = datetime.now()
print("结束时间:")
print(endTime)
2. 爬虫基础综合实战
在上述基础上,我们可以对一些网站进行爬虫进阶了
- 运用技术:HTMLParser
- 爬取信息:爬取 samsbeauty 网站,对各类目商品进行分类,并爬取商品落地页信息,输出excel文件(网站需要翻墙,可以参考代码,爬取自己感兴趣的网站,总不会P站吧!?不会吧不会吧!)
- 步骤分析:
- 可以看到,在大类目下还有很多小类目
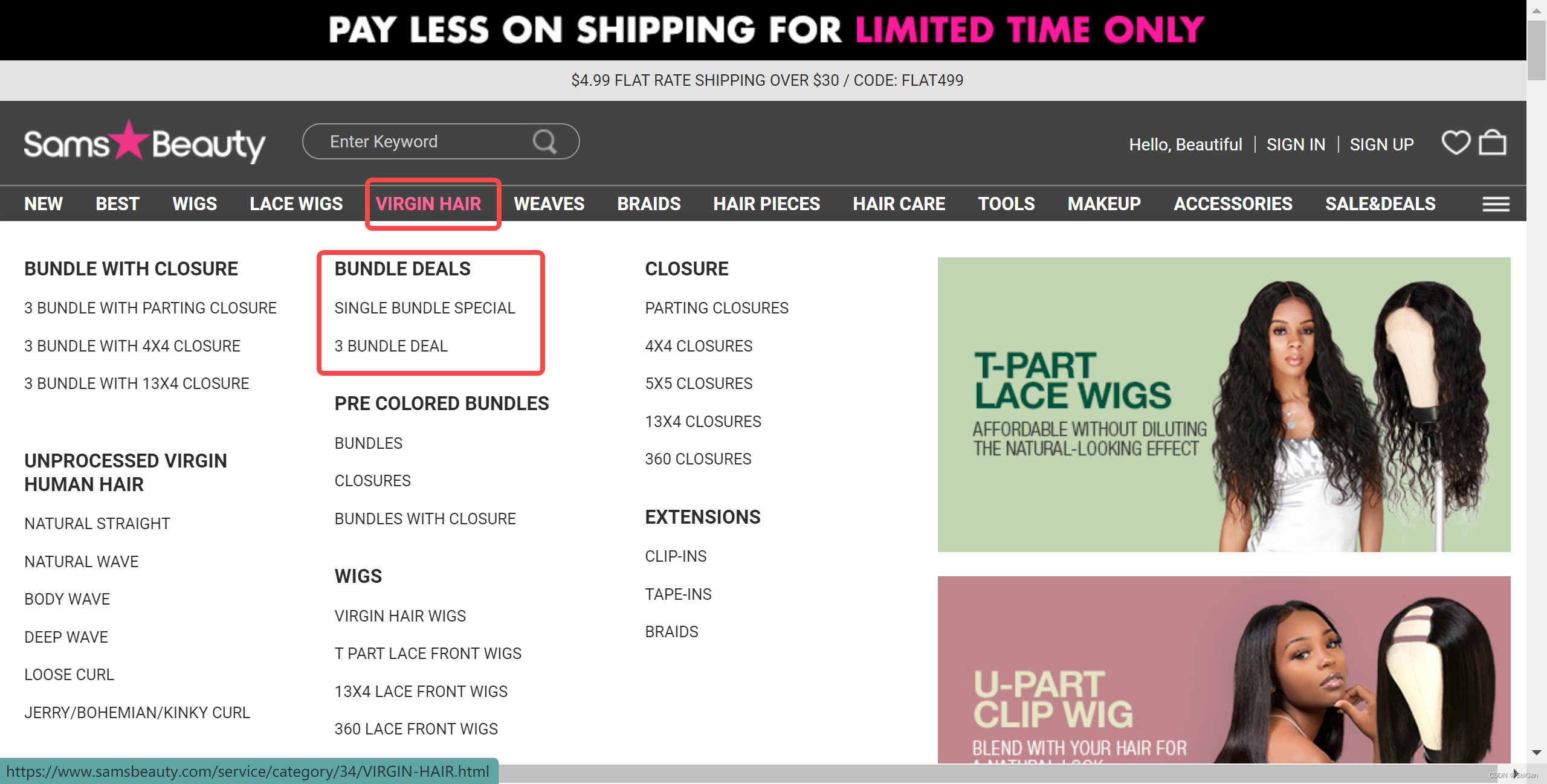
- 可以看到,访问类目页的信息,可以从上述小类目的 dom 元素上找到相关信息
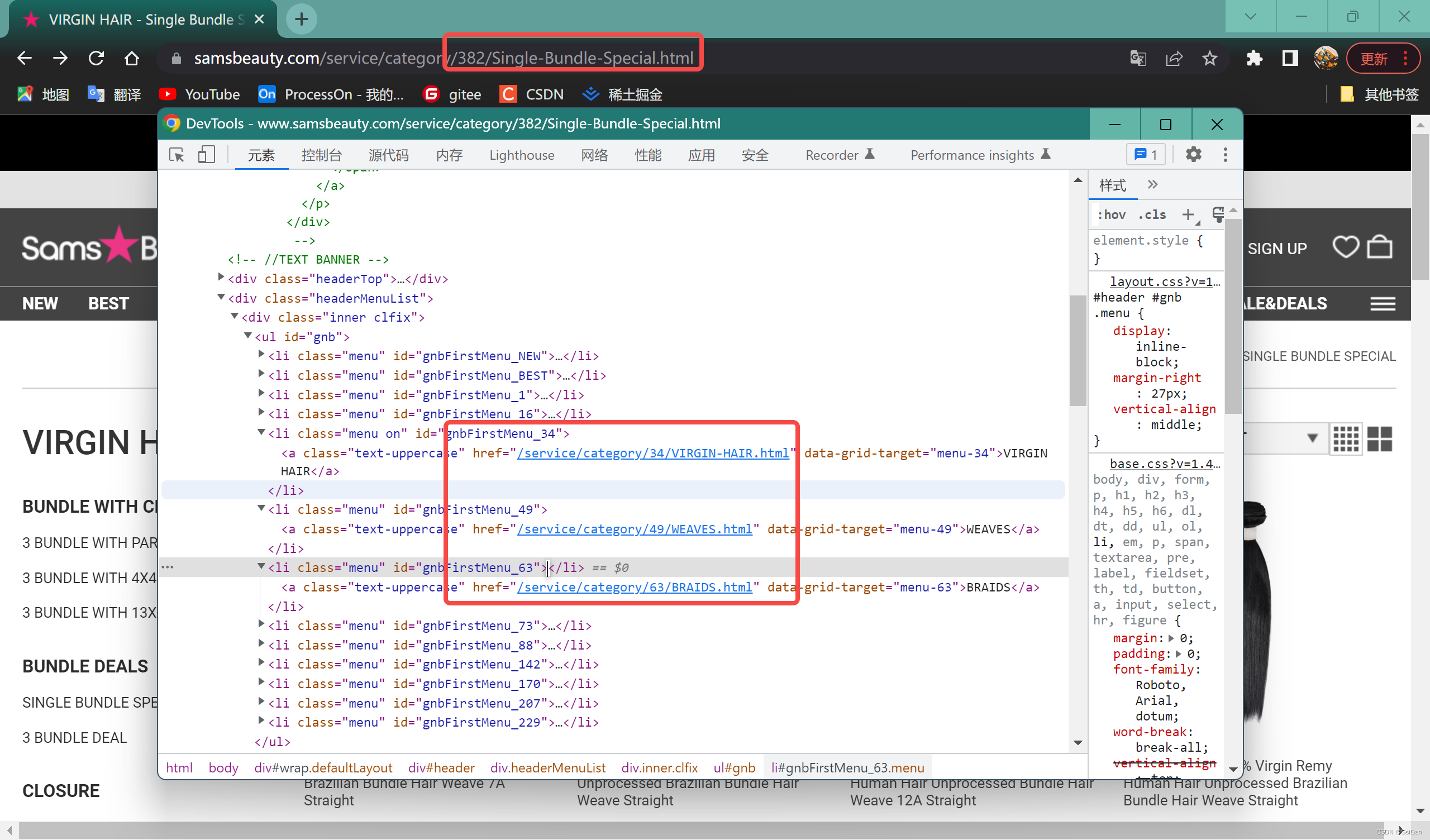
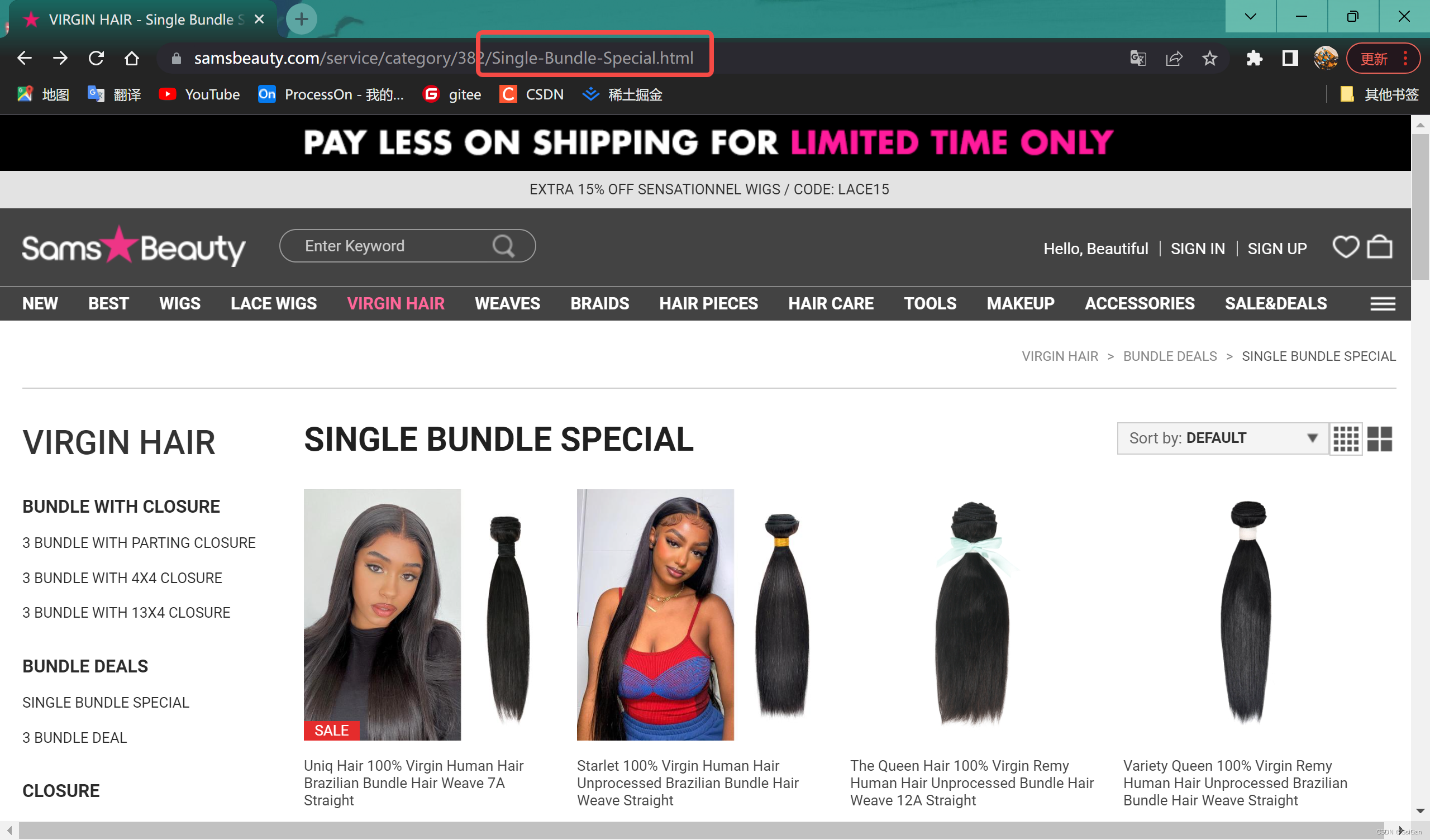
- 还可以看到,商品列表可以通过调取接口(传参类目id、分页信息等),获得相关参数(如:商品落地页访问链接等)
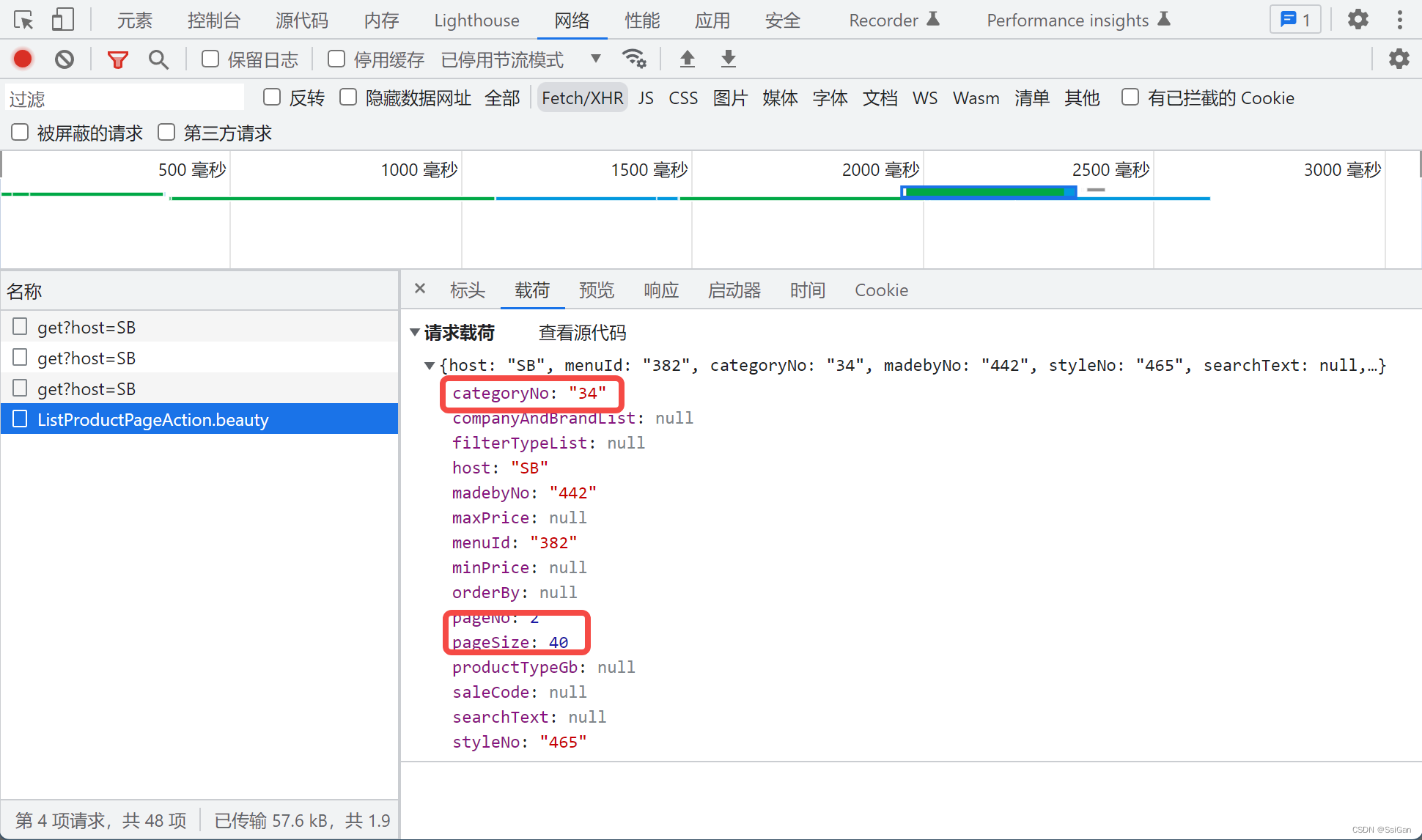
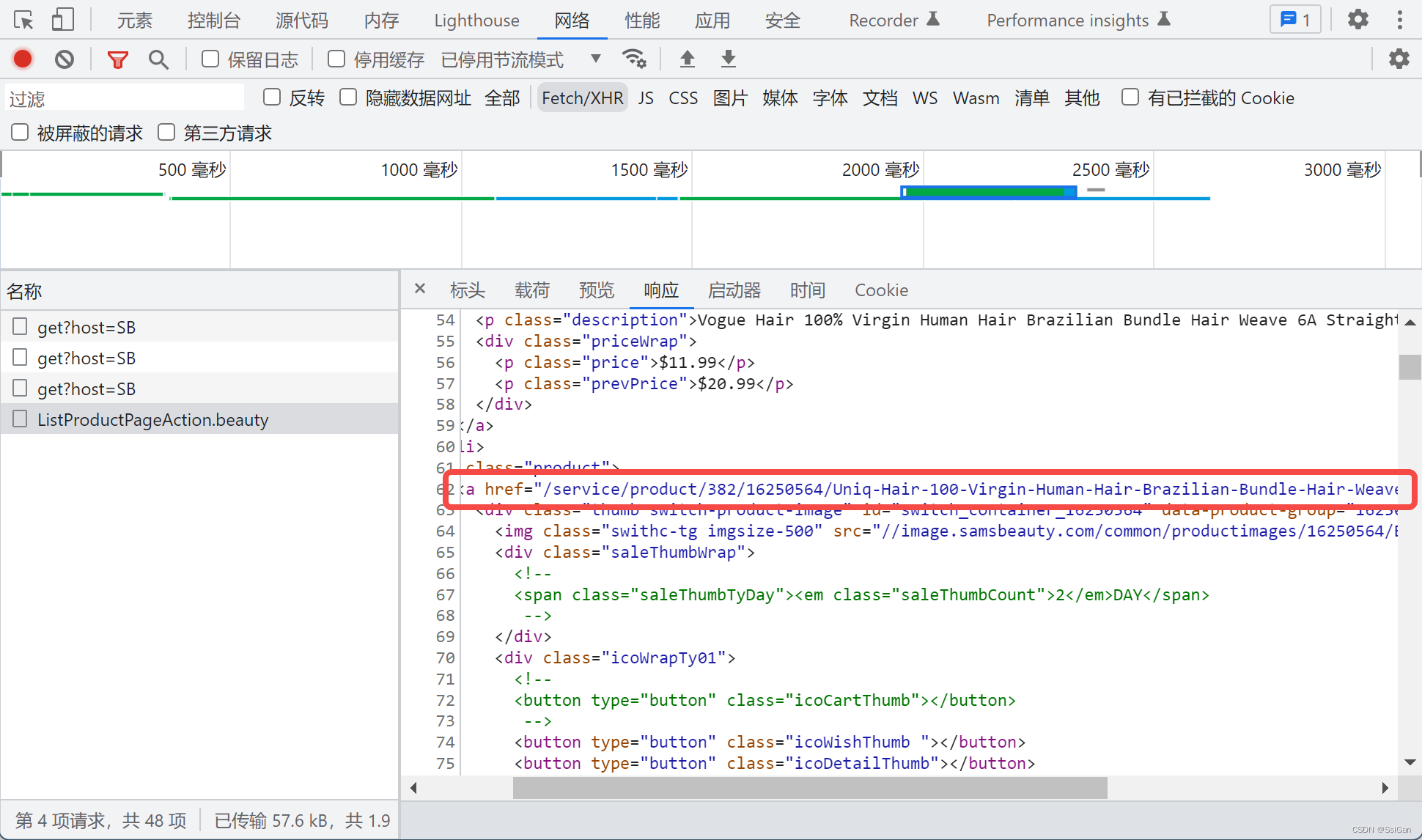
那么上述步骤总结后,代码整体如下(包含了通过多线程读取的方式):
- 可以看到,在大类目下还有很多小类目
import math
import requests
from selectolax.parser import HTMLParser
import re
from threading import Thread
import pandas as pd
from datetime import datetime
import time
import final_views
final_list = []
proxy = "http://127.0.0.1:1088"
# 官方网址
url = "https://www.samsbeauty.com"
# 产品列表请求链接
productListUrl = "https://www.samsbeauty.com/service/product/ListProductPageAction.beauty"
# 爬取大类目与小类目数据
def get_meta(url):
r = requests.get(
url,
headers={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36",
'User-agent':'XXXXXXXXXXXXXXX',
'Cookie': 'XXXXXXXXXXXXXXXXXX'
},
proxies={"all": proxy},
)
root = HTMLParser(r.text)
first_categorys = []
categorys = []
first_menus = []
# 获取大类目及相关信息
for test in root.css("#gnb > .menu > a"):
if 'data-grid-target' in test.attributes:
category_name = test.text()
target_id = test.attributes['data-grid-target']
else:
category_name = test.text()
target_id = -1
# 获取小类目及相关信息
for cat in root.css(".depth02MenuWrap > .depth02MenuList > .depth02Menu"):
if 'data-grid-id' in cat.attributes:
# 如果data-grid-id相等
if cat.attributes['data-grid-id'] == target_id and cat.attributes['data-grid-id'] not in categorys and category_name not in first_menus:
dl_list = []
categorys.append(cat.attributes['data-grid-id'])
for dl in cat.css(".inner > .categoryList > dl"):
dd_list = []
dt = dl.css_first("dt > a")
# 获取第三级信息
if dl.css("dd > a"):
for dd in dl.css("dd > a"):
views = []
# # 截取url,取第一个数字作为请求详情页列表参数
# reg_url = dd.attributes['href']
# regs = re.findall(r"\d+\d", reg_url)
# menuId = regs[0] if len(regs) else -1
# # 判断menuId是否为-1,不为-1可查询全部商品列表
# if menuId != -1:
# views = get_meta_list(menuId)
# print("view_list :")
# print(views)
dd_data = {
"third_name": dd.text(),
"third_url": dd.attributes['href'],
"views": views
}
dd_list.append(dd_data)
else:
views = []
# # 截取url,取第一个数字作为请求详情页列表参数
# reg_url = dt.attributes['href']
# regs = re.findall(r"\d+\d", reg_url)
# menuId = regs[0] if len(regs) else -1
# # 判断menuId是否为-1,不为-1可查询全部商品列表
# if menuId != -1:
# views = get_meta_list(menuId)
# print("view_list :")
# print(views)
dd_data = {
"third_name": dt.text(),
"third_url": dt.attributes['href'],
"views": views
}
dd_list.append(dd_data)
small_category = {
"small_id": cat.attributes['data-grid-id'],
"small_url": dt.attributes['href'],
"small_name": dt.text(),
"third_list": dd_list
}
dl_list.append(small_category)
big_category = {
"big_name": category_name,
"big_id": target_id,
"second_list": dl_list
}
first_categorys.append(big_category)
first_menus.append(category_name)
elif target_id == -1:
if category_name not in first_menus:
big_category = {
"big_name": category_name,
"big_id": target_id,
"second_list": []
}
first_categorys.append(big_category)
first_menus.append(category_name)
print("first_categorys:")
print(first_categorys)
return first_categorys
def get_meta_list(menuId,name):
view_list = []
i = 1
while i > 0:
time.sleep(1)
r = requests.post(
productListUrl,
json={
"host": "SB",
"menuId": menuId,
"madebyNo": menuId,
"pageNo": i,
"pageSize": 100
} if name != "SALE&DEALS" else {
"host": "SB",
"saleCode": menuId,
"pageNo": i,
"pageSize": 100
},
headers={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36",
'User-agent':'XXXXXXXXXXXXXXX',
'Cookie': 'XXXXXXXXXXXXXXXXXX'
},
proxies={"all": proxy},
)
root = HTMLParser(r.text)
if len(root.css(".product > a")) > 0:
for href in root.css(".product > a"):
view_list.append(href.attributes['href'])
return view_list
# 遍历进入对应的类目,获取该类目menuId,爬取分页信息
def work(df,_list):
for first in _list:
if len(first.get("second_list")) > 0:
for second in first.get("second_list"):
if len(second.get("third_list")) > 0:
for third in second.get("third_list"):
# 截取url,取第一个数字作为请求详情页列表参数
reg_url = third['third_url']
regs = re.findall(r"\d+\d", reg_url)
menuId = regs[0] if len(regs) else -1
# 判断menuId是否为-1,不为-1可查询全部商品列表
if menuId != -1:
# try:
views = final_views.get_meta_list(menuId, first.get("big_name"))
print("view_list :")
print(views)
for view in views:
if len(view.get("specs")) > 0:
specs = view.get("specs")
for spec in specs:
result = {
"first_name": first['big_name'],
"second_name": second['small_name'],
"third_name": third['third_name'],
"item_id": view['item_id'],
"url": view['url'],
"title": view['title'],
"spec_name": spec['name'],
"price": spec['price'],
"old_price": spec['old_price'] if spec['old_price'] > 0 and spec['old_price'] > spec['price'] else ""
}
final_list.append(result)
else:
result = {
"first_name": first['big_name'],
"second_name": second['small_name'],
"third_name": third['third_name'],
"item_id": view['item_id'],
"url": view['url'],
"title": view['title'],
"spec_name": view['title'],
"price": view['price1'],
"old_price": view['old_price1']
}
final_list.append(result)
# except Exception as err:
# print("线程大类目出错!")
# print(err)
def get_meta_view(url2):
time.sleep(1)
r = requests.get(
url2,
headers={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36",
'User-agent':'XXXXXXXXXXXXXXX',
'Cookie': 'XXXXXXXXXXXXXXXXXX'
},
proxies={"all": proxy},
)
root = HTMLParser(r.text)
price1 = 0
old_price1 = 0
if root.css_first("#totalPrice"):
price1 = float(
re.search(r"\d+(\.\d+)", root.css_first("#totalPrice").text()).group(0)
)
if root.css_first("#prevTotalPrice"):
old_price1 = float(
re.search(r"\d+(\.\d+)", root.css_first("#prevTotalPrice").text()).group(0)
)
result = {
"url": url2,
"item_id": root.css_first(".productCode > .code").text(),
"title": root.css_first(".productName").text(),
"price1": price1,
"old_price1": old_price1,
}
specs = []
result["specs"] = specs
for node in root.css(".colorList > .color,#productUnitList > [data-val]"):
add_price = float(node.attributes.get("data-val", "").split(":")[3])
name = (node.css_first(".desc") or node).text(strip=True)
add_node = node.css_first(".addPrice")
price = 0
old_price = 0
if root.css_first("#totalPrice"):
price = float(
re.search(r"\d+(\.\d+)", root.css_first("#totalPrice").text()).group(0)
)
if root.css_first("#prevTotalPrice"):
old_price = float(
re.search(r"\d+(\.\d+)", root.css_first("#prevTotalPrice").text()).group(0)
)
if add_node:
name += add_node.text(strip=True)
spec = {
"name": name,
"price": price + add_price,
"old_price": old_price + add_price,
}
specs.append(spec)
return result
def export_result(result):
# 大类目、小类目、ITEMID、URL、标题、规格名、原价、现价
result_list = []
for test in result:
if len(test.get('second_list')) > 0:
seconds = test.get("second_list")
for second in seconds:
if len(second.get('third_list')) > 0:
third_list = second.get('third_list')
for third in third_list:
if len(third.get('views')) > 0:
views = third.get('views')
for view in views:
if len(view.get("specs")) > 0:
specs = view.get("specs")
for spec in specs:
result = {
"first_name": test['big_name'],
"second_name": second['small_name'],
"third_name": third['third_name'],
"item_id": view['item_id'],
"url": view['url'],
"title": view['title'],
"spec_name": spec['name'],
"price": spec['price'],
"old_price": spec['old_price'] if spec['old_price'] > 0 and spec['old_price'] > spec['price'] else ""
}
result_list.append(result)
else:
result = {
"first_name": test['big_name'],
"second_name": second['small_name'],
"third_name": third['third_name'],
"item_id": view['item_id'],
"url": view['url'],
"title": view['title']
}
result_list.append(result)
else:
result = {
"first_name": test['big_name'],
"second_name": second['small_name'],
"third_name": third['third_name']
}
result_list.append(result)
else:
result = {
"first_name": test['big_name'],
"second_name": second['small_name']
}
result_list.append(result)
else:
result = {
"first_name": test['big_name'],
"second_name": ""
}
result_list.append(result)
print("result_list:")
print(result_list)
return result_list
# 每个大类目分一个线程
def search_views(firsts):
# 线程列表
thread_list = []
# 需要处理的数据
_l = firsts
# 每个线程处理的数据大小
split_count = 1
# 需要的线程个数
times = math.ceil(len(_l) / split_count)
count = 0
for item in range(times):
_list = _l[count: count + split_count]
# 线程相关处理
thread = Thread(target=work, args=(item, _list))
thread_list.append(thread)
# 在子线程中运行任务
thread.start()
count += split_count
# 线程同步,等待子线程结束任务,主线程再结束
for _item in thread_list:
_item.join()
if __name__ == "__main__":
startTime = datetime.now()
print("开始时间:")
print(startTime)
firsts = get_meta(url)
search_views(firsts)
# export_result(final_list)
print(final_list)
print("开始导出!")
file_name = 'final.xlsx'
sales_record = pd.DataFrame(final_list)
sales_record.to_excel(file_name)
print("完成导出!")
endTime = datetime.now()
print("结束时间:")
print(endTime)
import math
import requests
from selectolax.parser import HTMLParser
import re
from threading import Thread
import pandas as pd
from datetime import datetime
import time
view_list = []
proxy = "http://127.0.0.1:1080"
# 官方网址
url = "https://www.samsbeauty.com"
# 产品列表请求链接
productListUrl = "https://www.samsbeauty.com/service/product/ListProductPageAction.beauty"
# 获取分页数据
def get_meta_list(menuId,name):
view_list.clear()
# 循环爬取商品分页信息,该接口一次最大只能100条
i = 1
while i > 0:
time.sleep(1)
r = requests.post(
productListUrl,
json={
"host": "SB",
"menuId": menuId,
"madebyNo": menuId,
"pageNo": i,
"pageSize": 100
} if name != "SALE&DEALS" else {
"host": "SB",
"saleCode": menuId,
"pageNo": i,
"pageSize": 100
},
headers={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36"
},
proxies={"all": proxy},
)
root = HTMLParser(r.text)
# 如果存在列表信息时,开线程爬取落地页信息,20个商品一个线程
if len(root.css(".product > a")) > 0:
# 线程列表
thread_list = []
# 需要处理的数据
_l = root.css(".product > a")
# 每个线程处理的数据大小
split_count = 20
# 需要的线程个数
times = math.ceil(len(_l) / split_count)
count = 0
for item in range(times):
_list = _l[count: count + split_count]
# 线程相关处理
thread = Thread(target=work, args=(item, _list))
thread_list.append(thread)
# 在子线程中运行任务
thread.start()
count += split_count
# 线程同步,等待子线程结束任务,主线程再结束
for _item in thread_list:
_item.join()
i = i + 1
else:
i = -1
return view_list
# 多线程任务,爬取落地页信息
def work(df,_list):
for test in _list:
try:
view = get_meta_view(url + test.attributes['href'])
print(view)
view_list.append(view)
except Exception as err:
print("异常出错哟!")
print(err)
# 爬取落地页信息
def get_meta_view(url2):
time.sleep(1)
r = requests.get(
url2,
headers={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36",
'User-agent':'XXXXXXXXXXXXXXX',
'Cookie': 'XXXXXXXXXXXXXXXXXX'
},
proxies={"all": proxy},
)
root = HTMLParser(r.text)
price1 = 0
old_price1 = 0
if root.css_first("#totalPrice"):
price1 = float(
re.search(r"\d+(\.\d+)", root.css_first("#totalPrice").text()).group(0)
)
if root.css_first("#prevTotalPrice"):
old_price1 = float(
re.search(r"\d+(\.\d+)", root.css_first("#prevTotalPrice").text()).group(0)
)
result = {
"url": url2,
"item_id": root.css_first(".productCode > .code").text(),
"title": root.css_first(".productName").text(),
"price1": price1,
"old_price1": old_price1,
}
specs = []
result["specs"] = specs
for node in root.css(".colorList > .color,#productUnitList > [data-val]"):
add_price = float(node.attributes.get("data-val", "").split(":")[3])
name = (node.css_first(".desc") or node).text(strip=True)
add_node = node.css_first(".addPrice")
price = 0
old_price = 0
if root.css_first("#totalPrice"):
price = float(
re.search(r"\d+(\.\d+)", root.css_first("#totalPrice").text()).group(0)
)
if root.css_first("#prevTotalPrice"):
old_price = float(
re.search(r"\d+(\.\d+)", root.css_first("#prevTotalPrice").text()).group(0)
)
if add_node:
name += add_node.text(strip=True)
spec = {
"name": name,
"price": price + add_price,
"old_price": old_price + add_price,
}
specs.append(spec)
return result
if __name__ == "__main__":
startTime = datetime.now()
print("开始时间:")
print(startTime)
# result = get_meta(url)
# list = export_result(result)
#
# file_name = 'final2.xlsx'
# sales_record = pd.DataFrame(list)
# sales_record.to_excel(file_name)
endTime = datetime.now()
print("结束时间:")
print(endTime)
3. Temu 爬虫技术栈选择与方案确立
Temu的反爬对我这个小白确实造成了很大的困扰,爬取落地页商品信息的时候各种问题不一而足,大家用上述方法爬取的时候,就可以发现各种问题了,这时候,我们就需要其他方法了
这里我选择了 playwright 作为新的方案,简单来说就是通过程序记录用户对浏览器的操作步骤,这时候进入对应的页面,就能拿到静态信息了,就可以正常爬取信息了。具体使用不做介绍,大家可以查查 playwright 的使用。
- 技术选择:playwright、HTMLParser
- 爬取信息:
- 网站分析:
- F12 查看落地页 dom 元素信息
可以看到,所有的落地页链接,都在 class 类:autoFitList 中

这时候我们直接手动复制元素,然后将信息解析,就和之前静态信息解析一样了
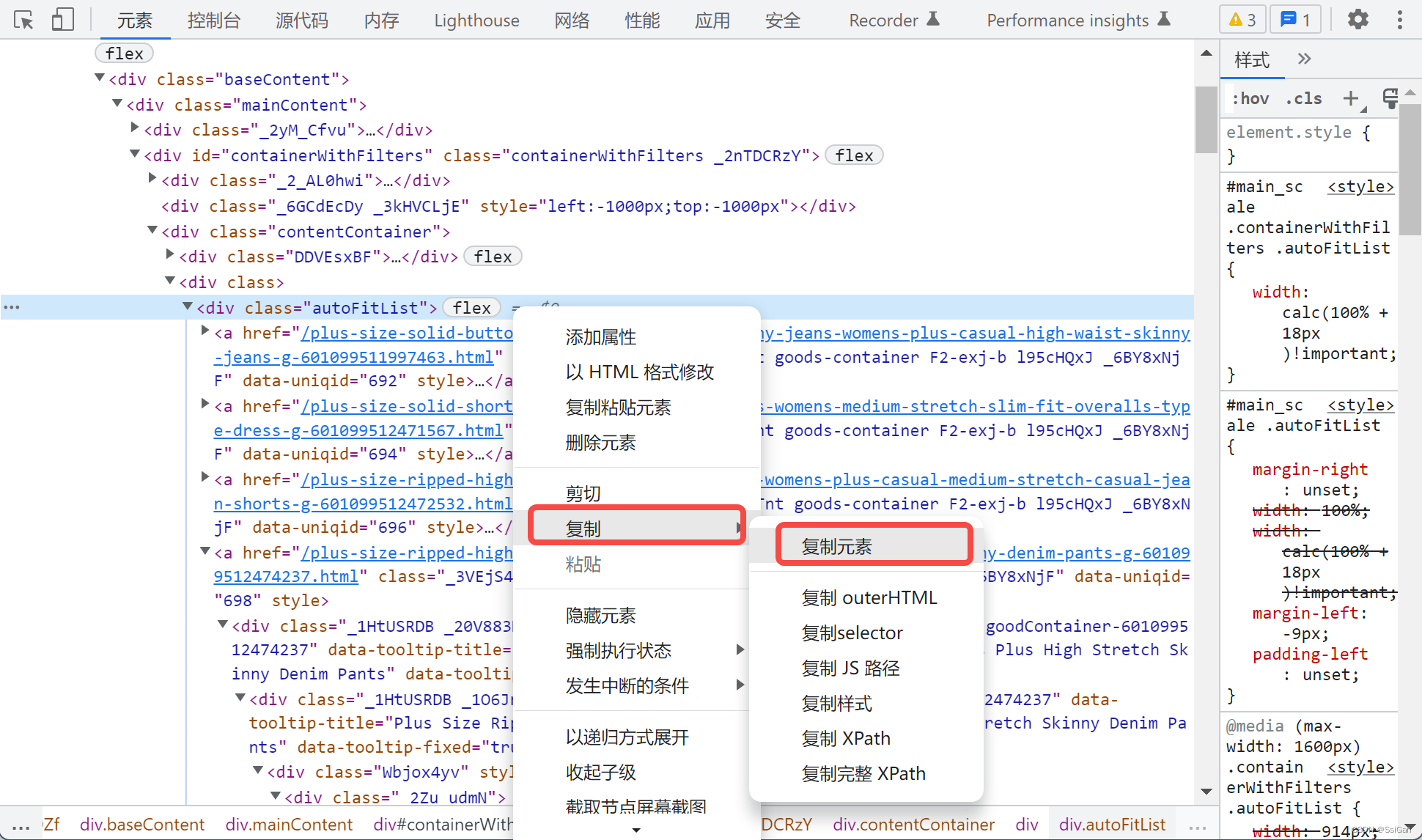
不得不说,这是一个很笨的方法,我是之前完全没接触过爬虫,在没有阅读过更多解决方案、教学后,为了赶时间想到的解决方案,只能说真的好用哈哈哈!如果有更好的解决方案,欢迎大家提出!
也侧面说明,真要想爬窃取信息,是真的挡不住的,哪怕手动一个一个页面点击访问呢是不是 - 上述问题解决后,只用 playwright 的正常调用访问落地页就好了,不做过多描述
- F12 查看落地页 dom 元素信息
具体源码如下所示:
import sys
import time
from datetime import datetime
import re
import pandas as pd
from playwright.sync_api import Playwright, sync_playwright, expect
url = "https://www.temu.com"
fileName = "category"
Description_map = {}
def run(playwright: Playwright) -> None:
browser = playwright.chromium.launch(headless=False)
context = browser.new_context(storage_state='login_data.json')
# cookies = [{'name': 'account_history_list', 'value': '%5B%7B%22uin%22%3A%22BAQNGCLZXLTQL6WX6ELLAT422KHWAWEFPU27UIML%22%2C%22email_id%22%3A%225556893914476871681160%22%2C%22email_des%22%3A%22157***218%40qq.com%22%2C%22login_type%22%3A%22MAIL%22%2C%22login_app_id%22%3A203%2C%22remember%22%3Afalse%7D%5D', 'domain': '.temu.com', 'path': '/login.html', 'expires': 1682611470.467804, 'httpOnly': False, 'secure': False, 'sameSite': 'Lax'}, {'name': 'region', 'value': '211', 'domain': 'www.temu.com', 'path': '/', 'expires': 1676115806.818664, 'httpOnly': False, 'secure': False, 'sameSite': 'Lax'}, {'name': 'language', 'value': 'en', 'domain': 'www.temu.com', 'path': '/', 'expires': 1676115806.818705, 'httpOnly': False, 'secure': False, 'sameSite': 'Lax'}, {'name': 'currency', 'value': 'USD', 'domain': 'www.temu.com', 'path': '/', 'expires': 1676115806.81872, 'httpOnly': False, 'secure': False, 'sameSite': 'Lax'}, {'name': 'api_uid', 'value': 'CmwQ0GO/8lw4CQBkDHfuAg==', 'domain': '.temu.com', 'path': '/', 'expires': 1708083806.818732, 'httpOnly': False, 'secure': False, 'sameSite': 'Lax'}, {'name': '_nano_fp', 'value': 'XpE8XqdxXqCaXqTJl9_UhvoRNxsLhHA08joHwA2u', 'domain': 'www.temu.com', 'path': '/', 'expires': 1708083813.548959, 'httpOnly': False, 'secure': False, 'sameSite': 'Lax'}, {'name': 'timezone', 'value': 'Asia%2FShanghai', 'domain': 'www.temu.com', 'path': '/', 'expires': 1676563458.898545, 'httpOnly': False, 'secure': False, 'sameSite': 'Lax'}, {'name': 'webp', 'value': '1', 'domain': 'www.temu.com', 'path': '/', 'expires': 1676563458.996468, 'httpOnly': False, 'secure': False, 'sameSite': 'Lax'}, {'name': '_gcl_au', 'value': '1.1.1019867933.1673523817', 'domain': '.temu.com', 'path': '/', 'expires': 1681299816, 'httpOnly': False, 'secure': False, 'sameSite': 'Lax'}, {'name': 'dilx', 'value': 'krTu3z4tBF6xJllyduGqv', 'domain': '.temu.com', 'path': '/', 'expires': 1705507463.705708, 'httpOnly': False, 'secure': False, 'sameSite': 'Lax'}, {'name': '_bee', 'value': 'Lymg1cHdpQesH0QhNMMWtJTfaSD4napt', 'domain': '.temu.com', 'path': '/', 'expires': 1705507463.705619, 'httpOnly': False, 'secure': False, 'sameSite': 'Lax'}, {'name': 'njrpl', 'value': 'Lymg1cHdpQesH0QhNMMWtJTfaSD4napt', 'domain': '.temu.com', 'path': '/', 'expires': 1705507463.705683, 'httpOnly': False, 'secure': False, 'sameSite': 'Lax'}, {'name': '_ga', 'value': 'GA1.1.2058068175.1673523820', 'domain': '.temu.com', 'path': '/', 'expires': 1708531459.688225, 'httpOnly': False, 'secure': False, 'sameSite': 'Lax'}, {'name': '_fbp', 'value': 'fb.1.1673523822477.33138753', 'domain': '.temu.com', 'path': '/', 'expires': 1681747470, 'httpOnly': False, 'secure': False, 'sameSite': 'Lax'}, {'name': 'IDE', 'value': 'AHWqTUnpbC-478aw9cR0XtOQgty4PI22lCBkFJ4sUegsoU8HKJ_BGNpof_jvYseu', 'domain': '.doubleclick.net', 'path': '/', 'expires': 1708083828.146372, 'httpOnly': True, 'secure': True, 'sameSite': 'None'}, {'name': 'gtm_logger_session', 'value': 'q1hn3yks04ixiq4vg5hcf', 'domain': 'www.temu.com', 'path': '/', 'expires': -1, 'httpOnly': False, 'secure': False, 'sameSite': 'Lax'}, {'name': 'shipping_city', 'value': '211%2C211000000001792', 'domain': 'www.temu.com', 'path': '/', 'expires': 1674057858.906048, 'httpOnly': False, 'secure': False, 'sameSite': 'Lax'}, {'name': '_device_tag', 'value': 'CgI2WRIIWG9MU3RkbnkaMDjqsVIQjtbM5FT9J4drX9OmXpAmJSUHu/8IMCRkrUjEk64ZYogVSw6JgFF0lRzKnjAC', 'domain': '.temu.com', 'path': '/', 'expires': 1682611470.02991, 'httpOnly': True, 'secure': True, 'sameSite': 'Lax'}, {'name': 'AccessToken', 'value': 'SDERSUBRXJRTEJXAYVJQTFYHY7C4ZFNLAXTBCHJLYXDO3LQMQQZQ0110d3b04c2a', 'domain': '.temu.com', 'path': '/', 'expires': 1682611470.029971, 'httpOnly': True, 'secure': True, 'sameSite': 'Lax'}, {'name': 'user_uin', 'value': 'BAQNGCLZXLTQL6WX6ELLAT422KHWAWEFPU27UIML', 'domain': '.temu.com', 'path': '/', 'expires': 1682611470.029992, 'httpOnly': False, 'secure': True, 'sameSite': 'Lax'}, {'name': '_ga_R8YHFZCMMX', 'value': 'GS1.1.1673971449.2.1.1673971470.39.0.0', 'domain': '.temu.com', 'path': '/', 'expires': 1708531470.057037, 'httpOnly': False, 'secure': False, 'sameSite': 'Lax'}]
# context.add_cookies(cookies)
page = context.new_page()
page.goto("https://www.temu.com/beauty-health-o3-25.html?filter_items=1%3A1")
page.wait_for_timeout(3000)
if 'Top sales' not in page.title():
page.locator("#user-account").click()
page.locator("#user-account").fill("1579759218@qq.com")
page.get_by_role("button", name="Continue").click()
page.locator("#pwdInputInPddLoginDialog").click()
page.locator("#pwdInputInPddLoginDialog").press("CapsLock")
page.locator("#pwdInputInPddLoginDialog").fill("JYyqz0407")
page.get_by_role("button", name="Sign in").click()
page.wait_for_timeout(3000)
cookies = context.cookies()
print(cookies)
for i in range(11):
if i > 4:
Description_map = {}
result_list = []
print("=========================================================")
file = fileName + str(i) + ".txt"
startTime = datetime.now()
print(file + "开始时间:" + str(startTime))
with open(file, 'r', encoding='UTF-8') as dbTest:
sys.stdin = dbTest
for line in sys.stdin:
# print(str(line))
# 获取落地页url
test_list = []
for l in line.split(","):
if l.find("html") >= 0:
test_list.append(l.replace("'", "").replace(" ", ""))
print(file + "数量:" + str(len(test_list)))
for index, land_page_url in enumerate(test_list):
try:
land_page_url = url + land_page_url
page1 = context.new_page()
page1.goto(land_page_url)
page1.wait_for_timeout(3000)
# 拼取参数
list1 = page1.query_selector_all(".wrap-2ZDZJ")
list3 = page1.query_selector_all(".spec-3QuQy")
list4 = page1.query_selector_all(".colorItem-2bzGq")
list5 = page1.query_selector_all(".spec-3cTw9")
skc_num = 1
if len(list3) > 0:
# 进入类型1,2,3,4
if len(list3) > 1:
# 进入类型2,4,表明有至少两种可选规格
if len(list4) > 0:
# 表明规格为图片 + 文字
num1 = len(list4) if len(list4) > 0 else 1
num2 = len(list1) if len(list1) > 0 else 1
skc_num = num1 * num2
else:
# 表明规格为文字 + 文字
test_list = page1.query_selector_all(".specSelector-4kzxj")
if len(test_list) > 0:
for test in test_list:
t = test.query_selector_all(".wrap-2ZDZJ")
skc_num *= len(t)
else:
skc_num = len(list4) if len(list4) > 0 else 1
else:
# 进入类型1,3,表明只有一种可选规格
if len(list4) > 0:
# 表明规格为缩略图类型
skc_num = len(list4) if len(list4) > 0 else 1
else:
# 表明规格为文字类型
skc_num = len(list1) if len(list1) > 0 else 1
else:
# 进入类型5,如果为类型5且长度大于0,则skc数量为1
if len(list5) > 0:
skc_num = 1
# print("skc数量:" + str(skc_num))
# 销量
sales = page1.query_selector(".salesTip-1FfJh").text_content()
num_sales = sales.split("(")[1].split("sold")[0]
if num_sales.find("k") >= 0 or num_sales.find("K") >= 0:
num_sales = float(re.findall(r"\d+\.?\d*", num_sales)[0])
num_sales = num_sales * 1000
else:
num_sales = float(re.findall(r"\d+\.?\d*", num_sales)[0])
# print("销量:" + str(sales.split("(")[1].split("+")[0]))
# 店铺名称
# shop_name2 = page1.query_selector(".salesTip-1FfJh").text_content()
# print("店铺名称:" + str(shop_name2.split("(")[0].split(" ")[0]))
# 实际售价
real_sale = page1.query_selector(".curPrice-846po").text_content()
# print("实际售价:" + str(real_sale.split("$")[1]))
# 原价
origin_sale = page1.query_selector(".linePrice-GOWbD").text_content()
# print("原价:" + str(origin_sale.split("$")[1] if len(origin_sale) > 1 else real_sale.split("$")[1]))
# 评分
# score = page1.query_selector(".scoreText-RCmOr").text_content()
# print("评分:" + str(score))
# 评论数
reviews = page1.query_selector(".title-3ZiVV").text_content() if page1.query_selector(
".title-3ZiVV") else "--"
# print("评论数:" + str(reviews.split(" ")[0]))
# 获取产品属性
# 向下滚动
page1.mouse.wheel(0, 10000)
page1.wait_for_timeout(1000)
descs = {}
if page1.query_selector(".more-3xcJK") is None:
# 拼取物品属性
Description = page1.query_selector_all(".item-1YBVO")
for des in Description:
before = des.text_content().split(": ")[0]
after = des.text_content().split(": ")[1]
descs[before] = after
if before in Description_map:
value_list = Description_map[before]
value_list.append(after)
Description_map[before] = value_list
else:
value_list = []
for t1 in result_list:
if before not in t1:
value_list.append("")
value_list.append(after)
Description_map[before] = value_list
for key in Description_map.keys():
if key not in descs:
value_list = Description_map[key]
value_list.append("")
Description_map[key] = value_list
else:
page1.locator(".more-3xcJK > .arrowWrap-BX8AC").click()
page1.mouse.wheel(0, 10000)
page1.wait_for_timeout(1000)
# 拼取物品属性
Description = page1.query_selector_all(".item-1YBVO")
for des in Description:
before = des.text_content().split(": ")[0]
after = des.text_content().split(": ")[1]
descs[before] = after
if before in Description_map:
value_list = Description_map[before]
value_list.append(after)
Description_map[before] = value_list
else:
value_list = []
for t1 in result_list:
if before not in t1:
value_list.append("")
value_list.append(after)
Description_map[before] = value_list
for key in Description_map.keys():
if key not in descs:
value_list = Description_map[key]
value_list.append("")
Description_map[key] = value_list
result = {
"url": land_page_url,
"商品名称": page1.query_selector(".goodsName-2rn4t").text_content(),
"SKC数量": skc_num,
"销量": int(num_sales),
"店铺名称": sales.split("(")[0],
"实际售价": real_sale.split("$")[1],
"原价": origin_sale.split("$")[1] if len(origin_sale) > 1 else
real_sale.split("$")[1],
"评分": page1.query_selector(".scoreText-RCmOr").text_content() if page1.query_selector(
".scoreText-RCmOr") else "--",
"评论数": reviews.split(" ")[0] if reviews != "--" else "--"
}
# print(index, result)
result_list.append(result)
except Exception as err:
print("异常!")
print(land_page_url)
print(err)
page1.close()
print("开始导出!")
file_name = 'final'+ str(i) +'.xlsx'
sales_record = pd.DataFrame(result_list)
# 添加属性列及数据
indexs = sales_record._stat_axis.values.tolist() # 行名称
columns = sales_record.columns.values.tolist() # 列名
print(indexs, columns)
for key, value in Description_map.items():
sales_record[key] = value
sales_record.to_excel(file_name)
print("完成导出!")
endTime = datetime.now()
print(file + "结束时间:" + str(endTime))
print("=========================================================")
context.close()
browser.close()
with sync_playwright() as playwright:
run(playwright)

















 3672
3672

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









