






上一篇文章,带大家了解了pr视频剪辑工具的基础界面和操作,相信小伙伴对于pr软件一定有了一些了解吧。接下来让我们一起更深层次的认识pr重的工具栏
这个是我们pr软件的界面,四大面板在上一篇文章中有介绍:

今天,我们再了解一些pr四大面板更多的功能:
一、源面板;
1、源面板(左上角那块):预览刚导入还未编辑的视频素材;
(1)项目面板中导入视频素材后,双击项目面板,就可以在源面板展现出来了;
(2)红圈中的1仅拖动视频:可将源面板中标记好的那段视频,拖入到时间轴编辑;
红圈中2仅拖动音频:将源面板中标记好的那段视频的音频,拖入时间轴编辑;

(3)视频时间线、蓝块停留在当前位置;如下图

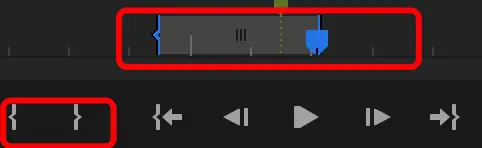
(4)添加标记、标记入点、标记出点等;如下图:

a、圈出的红色1: 添加标记(标记的是时间截点,某一瞬间),添加之后视频时间线上方出现绿色的块;

b、上图圈出的红色块2、3分别是:标记入点和标记出点;标记了一段视频,这段视频会高亮显示;
(5)插入、覆盖、导出帧;如下图:

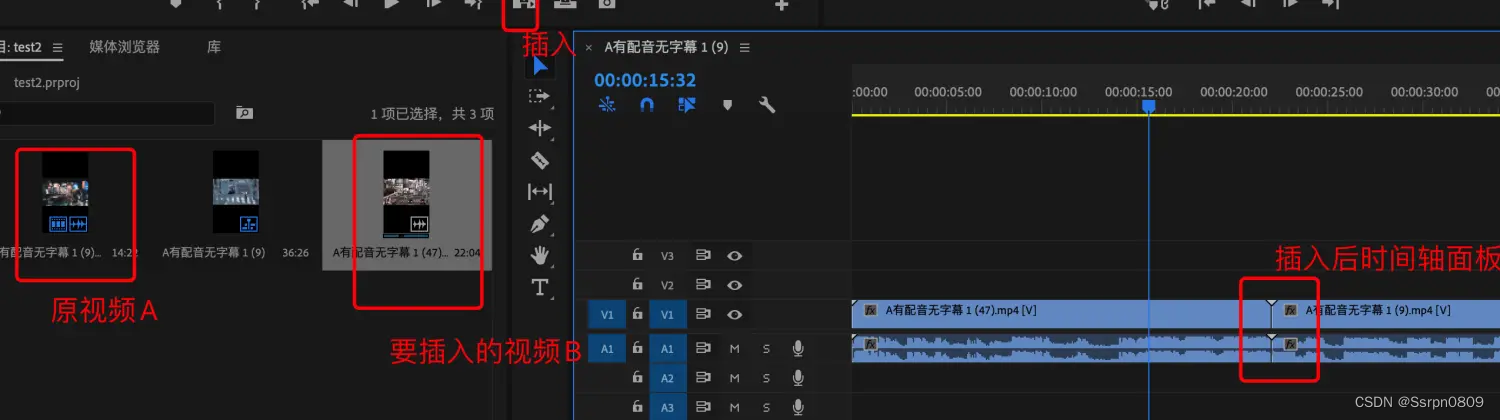
a、插入:将一个视频插入到另一个视频中间,不影响原视频;
如下图:视频A是第一次导入的,视频B后边导入,点击插入即可将视频B插入到视频A中;(可以选择在视频A任意位置插入,下图是在视频A前边插入的)
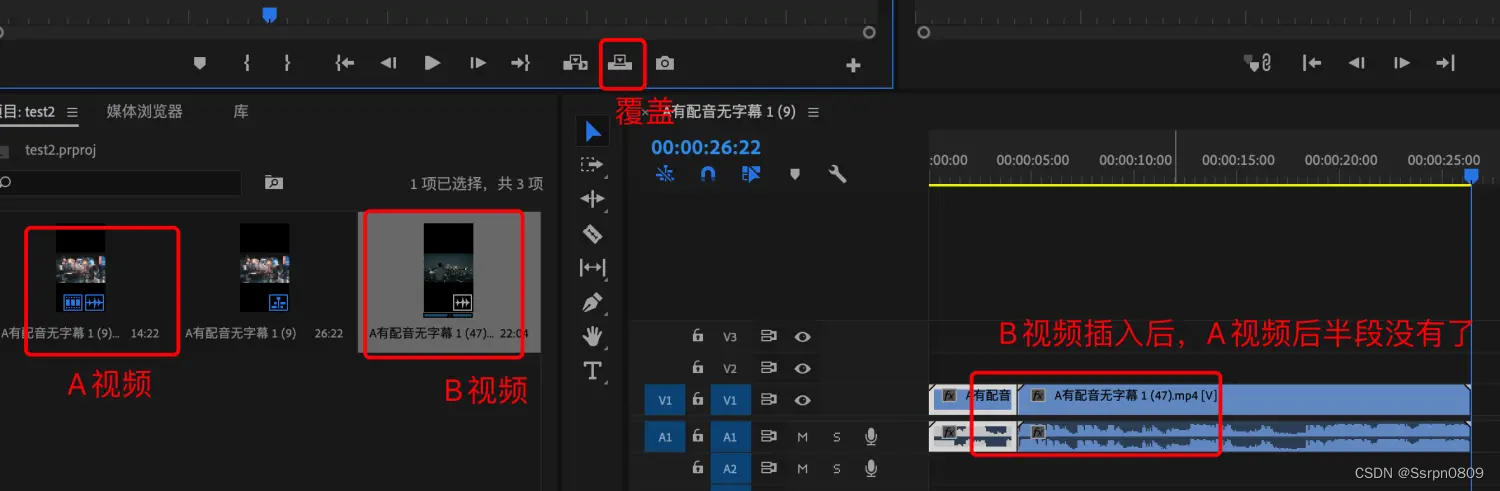
b、覆盖:时间轴上边的视频的后半段,被源面板上的视频覆盖了,没有了;
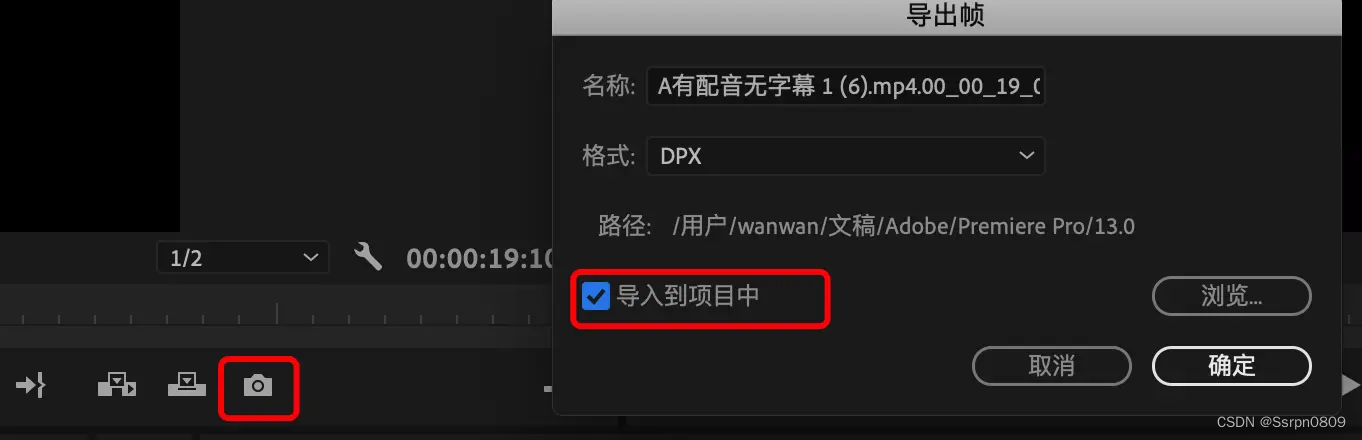
c、导出帧:将时间线停留的某一帧导出来;可以点选导入到项目中,会直接在项目面板中显示,就不需要再去保存的盘里找了。

















 791
791

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









