






第一步,确认谷歌浏览器版本,高版本才能安装插件。
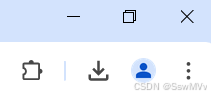
在浏览器菜单栏右上角,点击“扩展程序” ![]()
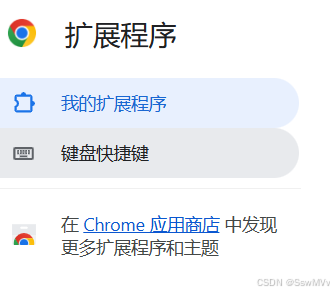
点击“管理扩展程序”,左侧列点击“Chrome应用商店”
搜索“OCR”,会出现很多文字识别工具。
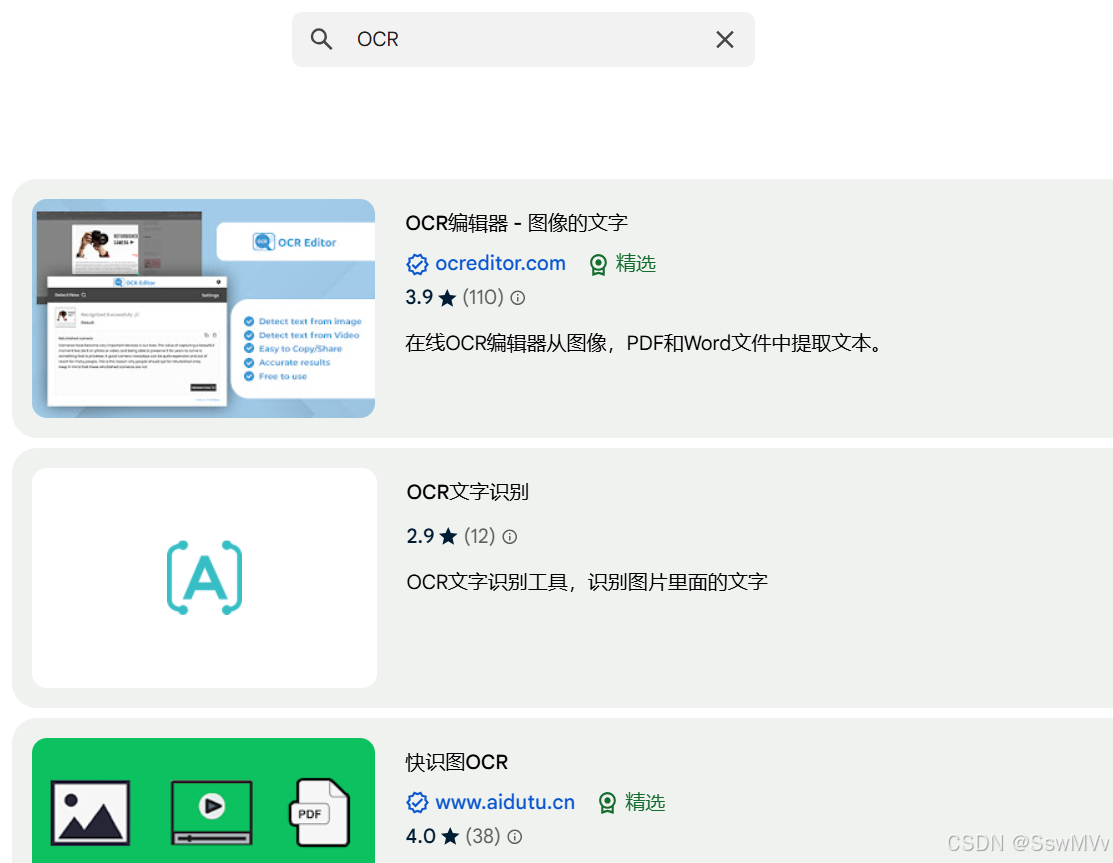
选择第二个“OCR文字识别”,这个工具方便在浏览器页面通过邮件图片或截图识别文字。但是不能用来识别PDF图片。
点击这个工具的介绍页面,右侧有推荐类似的工具。
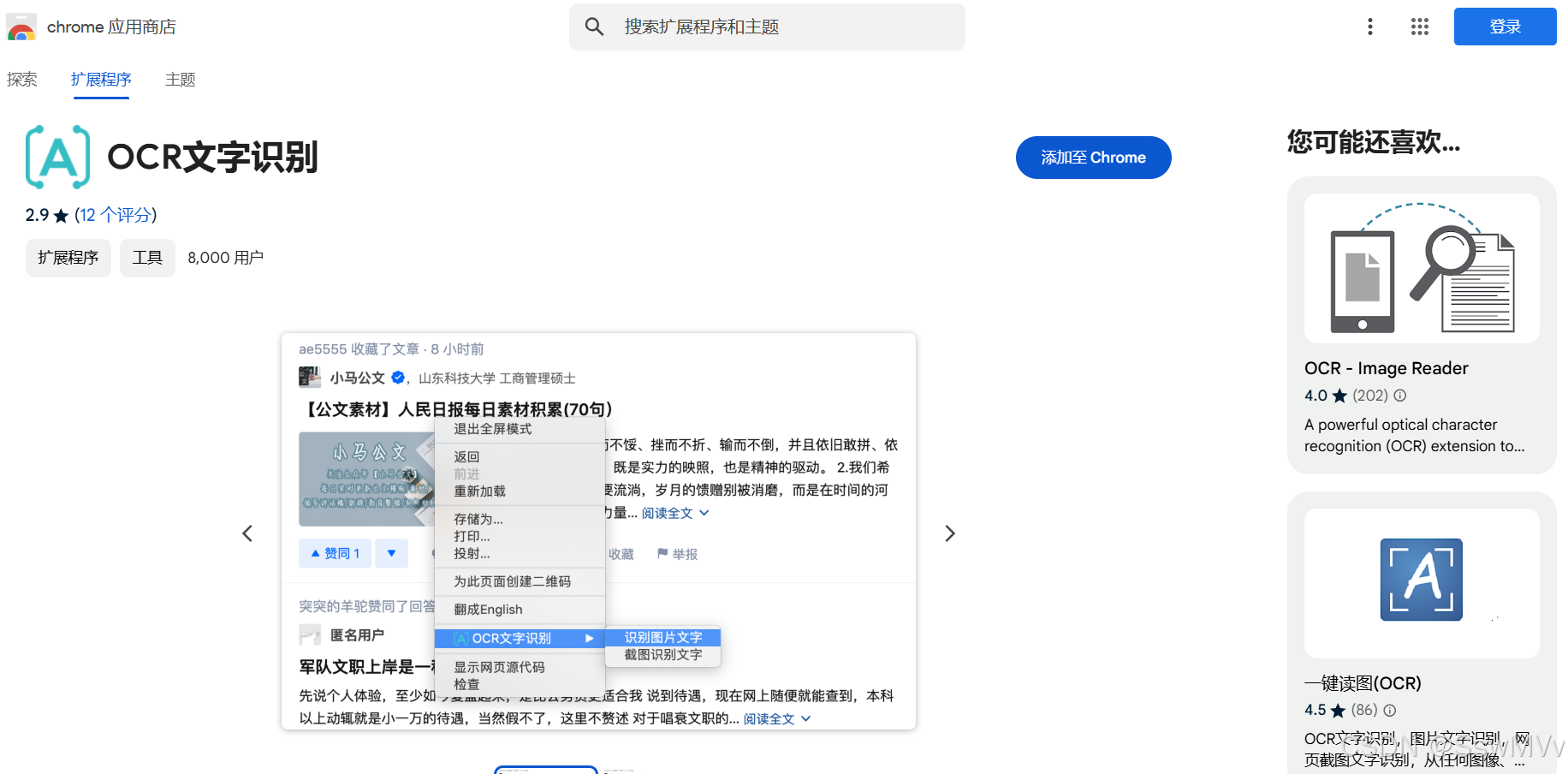
“一键读图OCR”就是本文要推荐的文字识别工具了。(现在在谷歌应用商店里搜不到了,不知道为什么。所以用了这种间接方法)

点击“添加至Chrome”。等待安装成功,就可以使用了。
下面介绍快速识别PDF文档图片文字的方法。
点击浏览器菜单栏“扩展程序”,单击刚添加的扩展程序。
会出现工具使用的选项,选择“上传图片文件”
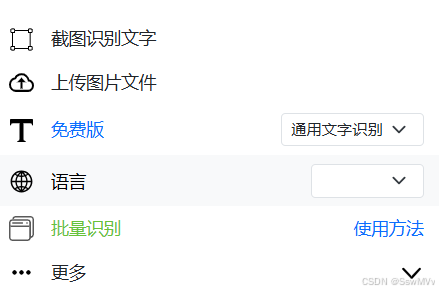
打开要识别的文档,用截图工具或者PDF阅读软件(adobe acrobat reader选中要识别的内容,然后需要按ctrl+c。windows自带的截图工具不用按ctrl+c)截图功能,截图。然后切换到OCR的上传界面,ctrl+v。就会看到图片里的文字被识别出来了。
不用保存图片再上传。
PS:一键读图每天有识别次数,如果要识别的内容多,需要登录才能继续识别。否则会识别失败(并不是因为图片不清晰)。
登录后有批量识别功能,可以识别整个PDF文档,但需要付费。劳动人民还是费费手吧。

















 1871
1871

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









