







摘要:
我们推出了 Playground v3 (PGv3),这是我们最新的文本转图像模型,它在多个测试基准中实现了最先进 (SoTA) 的性能,在图形设计能力方面表现出色,并引入了新功能。与依赖于预训练语言模型(如 T5 或 CLIP 文本编码器)的传统文本转图像生成模型不同,我们的方法将大型语言模型 (LLM) 与新颖的结构完全集成,该结构专门利用来自解码器专用 LLM 的文本条件。此外,为了提高图像字幕质量,我们开发了一个内部字幕器,能够生成具有不同细节级别的字幕,丰富文本结构的多样性。我们还引入了一个新的基准CapsBench来评估详细的图像字幕性能。实验结果表明,PGv3 在文本提示遵守、复杂推理和准确文本渲染方面表现出色。用户偏好研究表明,我们的模型对于常见设计应用(例如贴纸、海报和徽标设计)具有超越人类的图形设计能力。此外,PGv3 还引入了新功能,包括精确的 RGB 颜色控制和强大的多语言理解。
详细技术报告可见:https://arxiv.org/html/2409.10695v1#S4
模型结构
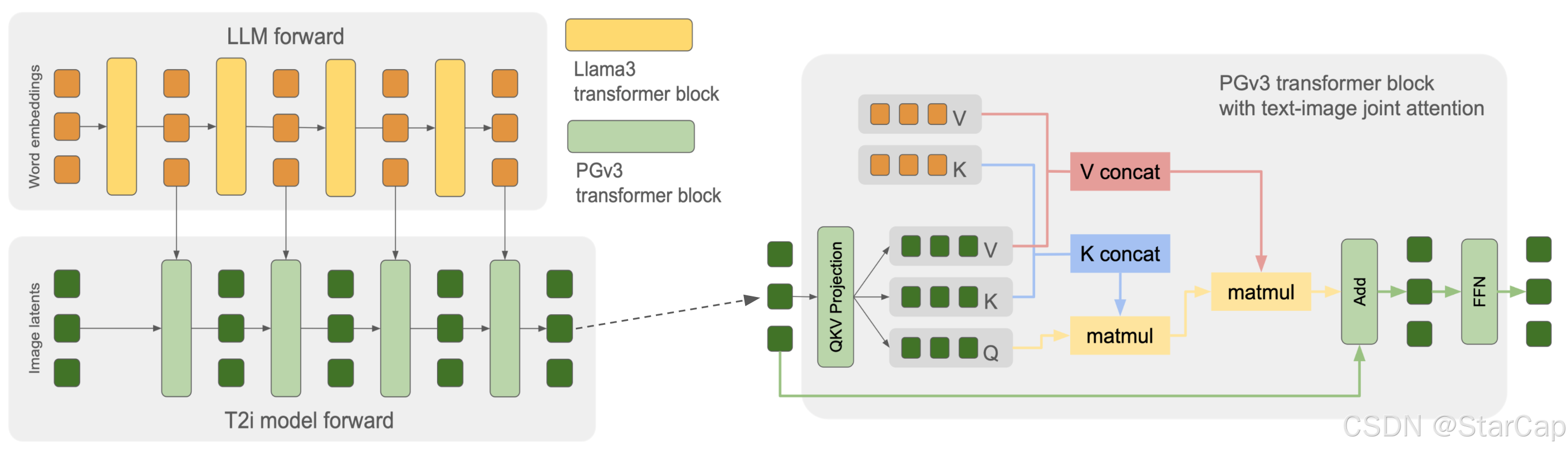
模型结构上,图像模型复刻LLM的Transformer层,包括hidden_dim、head_num和head_dim大小,将LLM每个Transformer层的特征和图像特征做single joint attention,通过将LLM每层特征都结合到图像生成模型中,让模型学会LLM模型的推理过程和逻辑,增强图像模型的文本遵从能力。类似UNet采用了跳跃连接,同时为了节省训练和推理时间将中间的Transformer block的k和v的序列长度减少4倍。
在位置编码上,比较了插值和延展ROPE,结论是:
“插值-PE”方法保持起始和结束位置ID固定,而不管序列长度如何,并在两者之间插入位置ID - 这是SD3等模型所采用的想法。另一方面,“扩展-PE”方法会随着序列长度按比例增加位置ID,而不应用任何技巧或规范化(即原始位置嵌入)。
我们发现“插值-PE”有一个明显的缺点:它导致模型在训练分辨率上严重过拟合,并且无法推广到未见过的纵横比。相比之下,“扩展-PE”方法表现良好,没有出现分辨率过拟合的迹象。因此,我们最终选择使用传统的位置嵌入。
在VAE上,为了增加图片的细节信息,将VAE的通道数从4增加到了16
提升效果的数据处理:
- 搞了个PG Captioner:一个经典的VLLM,由图像编码器、I2T Adapter和仅有decoder的LLM模型组成,来生成详细的文本描述
- 搞了个CapsBench基准,用于评估数据的caption质量
部分场景效果:
不仅可以做到文本控制生成,还可以控制图像中每个物体的颜色




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









