







Paraformer: Fast and Accurate Parallel Transformer for Non-autoregressive End-to-End Speech Recognition
1. Abstract
Transformer 最近在 ASR 领域占据了主导地位。尽管能够产生良好的性能,但它们涉及自回归 (AR) 解码器来逐个生成 token,这在计算上效率低下。为了加快推理速度,设计了非自回归 (NAR) 方法,例如单步 NAR,以实现并行生成。然而,由于输出 token 中的独立性假设,单步 NAR 的性能不如 AR 模型,尤其是在使用大规模语料库时。改进单步 NAR 面临两个挑战:首先要准确预测输出 token 的数量并提取隐藏变量;其次,要增强对输出 token 之间相互依赖性的建模。为了应对这两个挑战,我们提出了一种快速准确的并行 Transformer,称为 Paraformer。它利用基于连续积分和触发的预测器来预测 token 的数量并生成隐藏变量。然后,浏览语言模型 (GLM) 采样器生成语义嵌入,以增强 NAR 解码器对上下文相互依赖性进行建模的能力。最后,我们设计了一种策略来生成负样本,以进行最小词错误率训练,从而进一步提高性能。
使用公共 AISHELL-1、AISHELL-2 基准和工业级 20,000 小时任务进行的实验表明,提出的 Paraformer 可以达到与最先进的 AR 变换器相当的性能,速度提高 10 倍以上。
2. Introduction:
过去几年,端到端 (E2E) 模型在自动语音识别 (ASR) 任务上的性能已经超越了传统混合系统。有三种流行的 E2E 方法:联结时间分类 (CTC) [1]、循环神经网络传感器 (RNN-T) [2] 和基于注意的编码器-解码器 (AED) [3, 4]。其中,AED 模型由于其出色的识别准确率而在 ASR 的 seq2seq 建模中占据主导地位。例如 Transformer [4] 和 Conformer [5]。虽然性能良好,但此类 AED 模型中的自回归 (AR) 解码器需要逐个生成 token,因为每个 token 都以所有先前的 token 为条件。因此,解码器的计算效率低下,并且解码时间随输出序列长度线性增加。为了提高效率和加速推理,提出了非自回归 (NAR) 模型来并行生成输出序列 [6–8]。
根据迭代次数和推理持续时间,NAR 模型可分为迭代或单步。在前者中,A-FMLM 是首次尝试 [9],旨在通过恒定迭代预测以未屏蔽标记为条件的屏蔽标记。由于需要预定义目标标记长度,因此性能会受到影响。为了解决这个问题,Mask-CTC 及其变体提出使用 CTC 解码来增强解码器输入 [10–12]。即便如此,这些迭代 NAR 模型仍需要多次迭代才能获得有竞争力的结果,从而限制了实践中的推理速度。最近,提出了几种单步 NAR 模型来克服这一限制 [13–17]。它们通过消除时间依赖性同时生成输出序列。虽然单步 NAR 模型可以显著提高推理速度,但它们的识别准确率明显不如 AR 模型,尤其是在大规模语料库上进行评估时。
上述单步 NAR 工作主要关注如何准确预测 token 数量以及提取隐藏变量。与通过预测网络预测 token 数量的机器翻译相比,由于说话者的语速、沉默和噪音等各种因素,ASR 确实很困难。另一方面,根据我们的调查,与 AR 模型相比,单步 NAR 模型犯了很多替换错误(图 1 中表示为 AR 和 vanilla NAR)。我们认为缺乏上下文相互依赖性会导致替换错误增加,特别是由于单步 NAR 中需要条件独立性假设。除此之外,所有这些 NAR 模型都是在阅读场景记录的学术基准上探索的。性能尚未在大规模工业级语料库上进行评估。因此,本文旨在改进单步 NAR 模型,使其能够在大规模语料库上获得与 AR 模型相当的识别性能。(NAR因为缺少上下文关系容易出现同音字错误问题,即论文说的替换错误)
这项工作提出了一种快速准确的并行变压器模型(称为 Paraformer),可解决上述两个挑战。对于第一个挑战,与以前基于 CTC 的工作不同,我们使用基于连续积分和触发 (CIF) [18] 的预测网络来估计目标数量并生成隐藏变量。对于第二个挑战,我们设计了一个基于扫视语言模型 (GLM) 的采样器模块,以增强 NAR 解码器对标记相互依赖性进行建模的能力。这主要受到神经机器翻译 [19] 工作的启发。我们还设计了一种包含负样本的策略,通过利用最小词错误率 (MWER) [20] 训练来提高性能。
我们在公开的 178 小时 AISHELL1 和 1000 小时 AISHELL-2 基准以及工业 20,000 小时普通话语音识别任务上对 Paraformer 进行了评估。Paraformer 在 AISHELL-1 和 AISHELL-2 上分别获得了 5.2% 和 6.19% 的 CER,不仅优于其他最近发布的 NAR 模型,而且与没有外部语言模型的最先进的 AR Transformer 相当。据我们所知,Paraformer 是第一个能够实现与 AR Transformer 相当的识别准确率的 NAR 模型,并且在大型语料库上实现了 10 倍的速度提升。
3. Method
Overview:
所提出的 Paraformer 模型的总体框架如图 2 所示。该架构由五个模块组成,即编码器、预测器、采样器、解码器和损失函数。编码器与 AR 编码器相同,由多个配备内存的自注意力 (SAN-M) 和前馈网络 (FFN) [21] 或一致性 [5] 块组成。预测器用于生成声学嵌入并指导解码。然后,采样器模块根据声学嵌入和字符标记嵌入生成语义嵌入。解码器类似于 AR 解码器,只是它是双向的。它由多个 SAN-M、FFN 和交叉多头注意力 (MHA) 块组成。除了交叉熵 (CE) 损失之外,引导预测器收敛的平均绝对误差 (MAE) 和 MWER 损失也被结合起来联合训练系统。
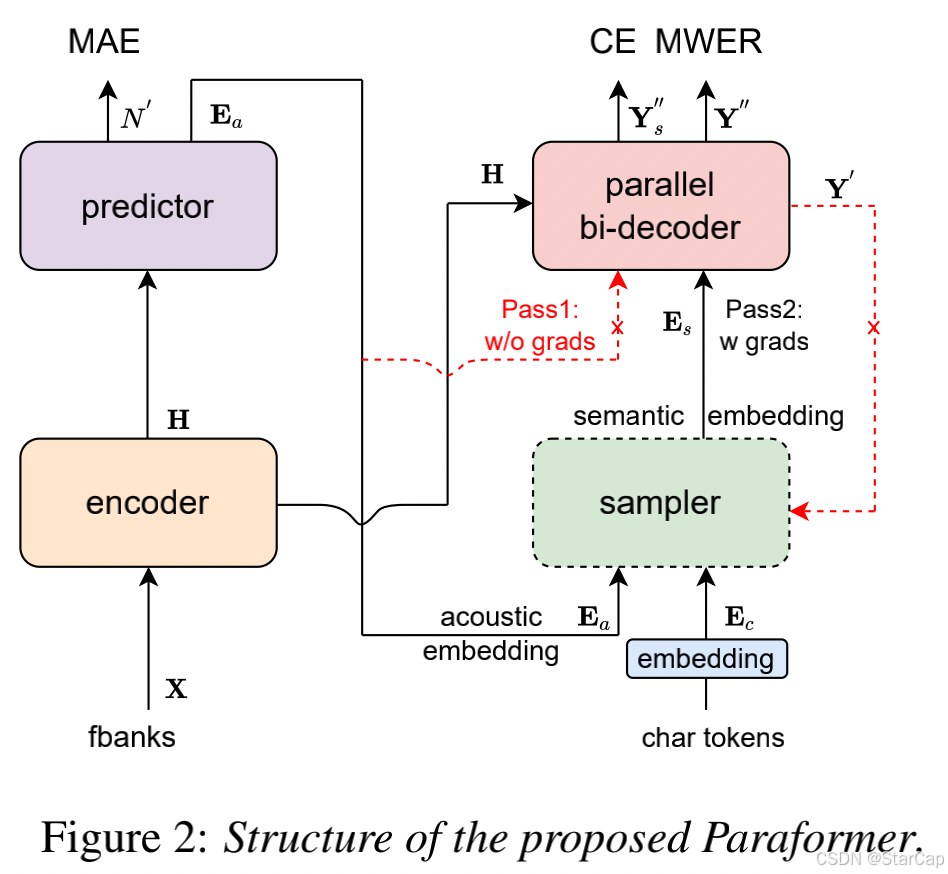
我们将输入表示为 (X, Y),其中 X 是帧号 T 的声学特征,Y 是目标标签有N个Token。编码器将输入序列 X 映射到隐藏表示序列 H。然后,这些隐藏表示 H 被输入到预测器以预测token数量 N ′ N^{'} N′和声学embedding E a E_a Ea。解码器接收声学embedding E a E_a Ea 和隐藏表示 H,以生成第一遍的目标预测 Y ′ Y^{'} Y′ ,而无需后向梯度(即这一步只是作为一个反向标签不参与梯度反传)。采样器在声学embedding E a E_a Ea和目标embedding E c E_c Ec 之间进行采样根据预测 Y ′ Y^{'} Y′和目标标签Y之间的距离生成语义embedding E s E_s Es。然后,解码器接收语义embedding E s E_s Es 以及隐藏表示 H,以生成第二遍的最终预测 Y ′ ′ Y^{''} Y′′,这次使用后向梯度。最后,对预测 Y ′ ′ Y^{''} Y
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 441
441

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









