




1. 概念
二叉搜索树又叫二叉排序树、二叉查找树。可以为空,也可以不为空,具体有以下的特性:(二叉搜索树没有重复的值)
- 若它的左子树不为空,则左子树上所有节点的值都小于根节点的值
- 若它的右子树不为空,则右子树上所有节点的值都大于根节点的值
- 它的左右子树也分别为二叉搜索树
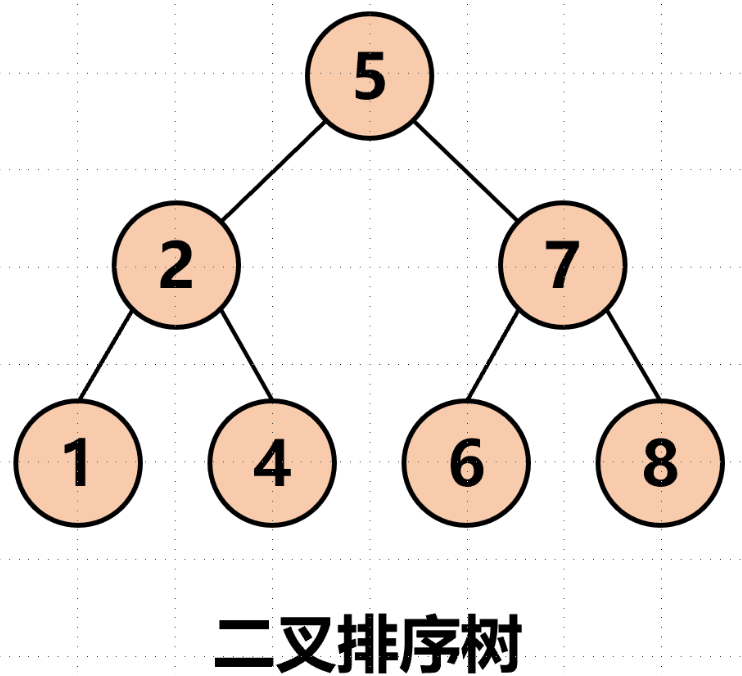
做题笔记
- 对其中序遍历时,输出结果是有序序列。
- 给定一棵二叉搜索树的前序和中序遍率历结果,无法确定这棵二叉搜索树
在二叉搜索树中进行中序遍历时,每个节点只会被访问一次,因此遍历的时间复杂度为 O ( N ) O(N) O(N)。这个复杂度表示无论树的结构如何(只要有 N 个节点),遍历树的时间是与节点数成线性关系的。
但是给定一棵二叉树并不能在线性时间复杂度内转化为平衡二叉搜索树,因为涉及旋转等操作,时间复杂度不是线性的。
2. 操作及模拟实现
2.1 二叉搜索树的查找
a. 从根开始比较,查找,比根大则往右边走查找,比根小则往左边走查找。
b. 最多查找高度次,走到到空,还没找到,这个值不存在。
非递归实现
bool Find(const K& key)
{
Node* cur = _root;
while (cur)
{
if (cur->_key < key)
//当前结点的值比要查找的值还小
//说明key可能在右子树
{
cur = cur->_right;
}
else if (cur->_key > key)
//当前结点的值比要查找的值还大
////说明key可能在左子树
{
cur = cur->_left;
}
else
{
return true;
}
}
//经过以上查找仍然找不到。
return false;
}
递归实现
bool _FindR(Node* root, const K& key)
{
if (root == nullptr)
{
return false;
}
if (root->_key < key)
{
return _FindR(root->_left, key);
}
else if (root->_key > key)
{
return _FindR(root->_right, key);
}
else
{
return true;
}
}
2.2 二叉搜索树的插入
插入的具体过程如下:
a. 树为空,则直接新增节点,赋值给root指针
b. 树不空,按二叉搜索树性质查找插入位置,插入新节点
非递归实现
bool Insert(const K& key)
{
if (_root == nullptr)
{
_root = new Node(key);//直接构造一个新结点。
return true;
}
Node* cur = _root;
Node* parent = nullptr;
while (cur)//找到结点要插入的位置
{
if (cur->_key < key)
{
parent = cur;
cur = cur->_right;
}
else if (cur->_key > key)
{
parent = cur;
cur = cur->_left;
}
else//相等的情况
{
return false;
}
}
cur = new Node(key);
if (parent->_key < key)
{
parent->_right = cur;
}
else
{
parent->_left = cur;
}
return true;
}
找到插入位置,还知道父节点才能往后插入,所以咱们需要一个 parent 结点指针。(双指针那种感觉)
递归实现
bool _InsertR(Node* root, const K& key)
{
if (root == nullptr)
{
root = new Node(key);
return true;
}
//以下是寻找过程,只达到上面if的位置。
if (root->_key < key)
{
return _InsertR(root->_right, key);
}
else if (root->_key > key)
{
return _InsertR(root->_left, key);
}
else//找到相等
{
return false;
}
}
2.3 中序遍历
void InOrder()
{
_InOrder(_root);
cout << endl;
}
//类似于封装
void _InOrder(Node* root)
{
if (root == nullptr)
return;
_InOrder(root->_left);
cout << root->_key << " ";
_InOrder(root->_right);
}
2.4 删除
情况类型分析:
- 没有孩子
- 一个孩子
- 两个孩子
前两个又可以归为一类。
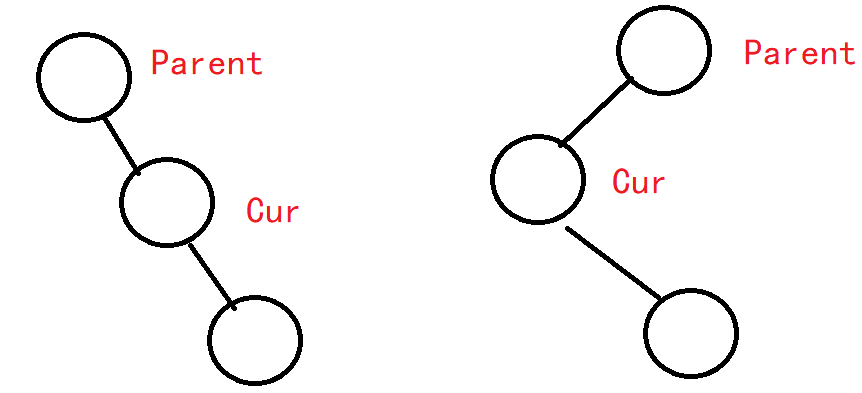
只有一个孩子且没有左子树
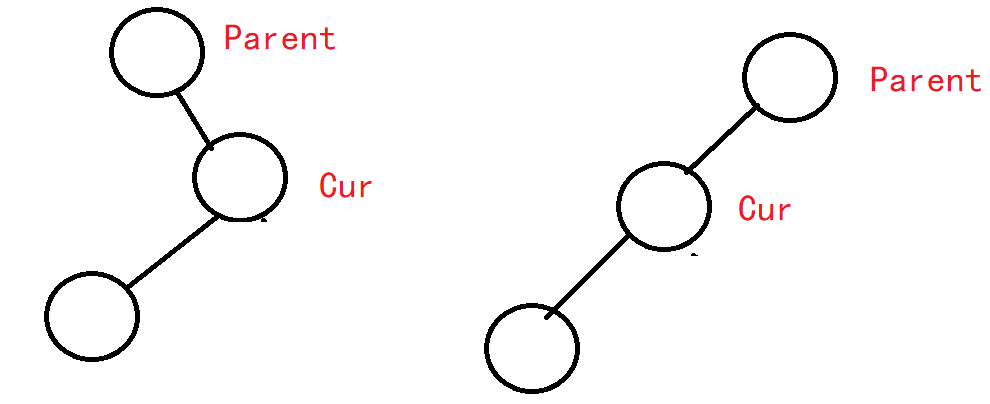
只有一个孩子且没有右子树
有两个子树——替换法删除
找一个能替换的结点,交换值,转换删除它。
这个结点可以是:
- 左子树的最大结点——左子树最右结点
- 右子树的最小结点——右子树最左结点(这段代码采取的是这个)
非递归实现
bool Erase(const K& key)
{
if (_root == nullptr)
return false;
else
{
Node* cur = _root;
Node* parent = nullptr;
while (cur)
{
if (cur->_key < key)
{
parent = cur;
cur = cur->_right;
}
else if (cur->_key > key)
{
parent = cur;
cur = cur->_left;
}
else//相等的情况,找到了!
{
//接下来的两个if-else都是讨论只有一个子树的情况
//也包括了没有左右子树的情况
if (cur->_left == nullptr)//没有左子树
{
if (cur == _root)//删除的结点为顶点
{
_root = cur->_right;
}
else
{
//在删除之前,将cur结点的上一个结点(即父节点)的指向进行更改
if (cur == parent->_right)
{
parent->_right = cur->_right;
}
else
{
parent->_left = cur->_right;
}
delete cur;
return true;
}
}
//相对上一段if只改动了parent指向——cur的左结点
else if (cur->_right == nullptr)
{
if (cur == _root)//删除的结点为顶点
{
_root = cur->_right;
}
else
{
//在删除之前,将cur结点的上一个结点(即父节点)的指向进行更改
if (cur == parent->_right)
{
parent->_right = cur->_left;
}
else
{
parent->_left = cur->_left;
}
delete cur;
return true;
}
}
else//左右都有子树,此时cur和parent都就位
{
//替换法
Node* rightMinParent = cur;
Node* rightMin = cur->_right;
//找到右子树最左结点
while (rightMin->_left)
{
rightMinParent = rightMin;
rightMin = rightMin->_left;
}
//找到了,并该值覆盖要删除的值。
cur->_key = rightMin->_key;
//判断删除的结点是上一个结点的哪一侧,
// 并将该删除结点以下最大值的结点,移到该删除结点位置。
//这也是有rightMinparent的原因,在删除rightMin之前需要重新指向。
if (rightMin == rightMinParent->_left 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1231
1231

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









