







 本文详细介绍了ELK(Elasticsearch、Logstash、Kibana)日志分析系统的部署过程,包括Elasticsearch集群的搭建,Logstash在Apache服务器上的配置,以及Kibana的安装和验证。此外,还探讨了Filebeat在ELK架构中的作用,提供了ELFK(Filebeat+ELK)的工作流程和部署步骤。
本文详细介绍了ELK(Elasticsearch、Logstash、Kibana)日志分析系统的部署过程,包括Elasticsearch集群的搭建,Logstash在Apache服务器上的配置,以及Kibana的安装和验证。此外,还探讨了Filebeat在ELK架构中的作用,提供了ELFK(Filebeat+ELK)的工作流程和部署步骤。
目录
前言
- 分析日志是运维工程师发现问题,解决系统故障的主要手段。日志主要包括系统日志、应用程序日志和安全日志。
- 一般大型系统是一个分布式部署的架构,不同的服务模块部署在不同的服务器上,问题出现时,大部分情况需要根据问题暴露的关键信息,定位到具体的服务器和服务模块,构建一套集中式日志系统,可以提高定位问题的效率。
- 经常分析日志可以了解服务器的负荷,性能安全性,从而及时采取措施纠正错误。通常,日志被分散的储存在不同的设备上。如果管理数十上百台服务器,还在使用依次登录每台机器的传统方法查阅日志,既繁琐又效率低下。为此,我们可以使用集中化的日志管理,例如:开源的 syslog,将所有服务器上的日志收集汇总。
- 集中化管理日志后,日志的统计和检查又成为一件比较麻烦的事情,一般我们使用 grep、awk 和 wc 等 Linux 命令能实现检索和统计,但是对于更高要求的查询、排序和统计等,再加上庞大的机器数量,使用这样的方法依然难免有点力不从心。
- 开源实时日志分析 ELK 平台能够完美的解决我们上述的问题,ELK 由 ElasticSearch、Logstash 和 Kibana 这三个开源工具组成。
一、ELK 日志分析系统
1. ELK 简介
ELK 平台是一套完整的日志集中处理解决方案,将 ElasticSearch、Logstash 和 Kibana 三个开源工具配合使用,完成更强大的用户对日志的查询、排序、统计需求。
2. 组件说明
2.1 ElasticSearch
- ES 是基于 Lucene(一个全文检索引擎的架构)开发的分布式存储检索引擎,用来存储各类日志。
- ES 是用 JAVA 开发的,可通过 RESTful Web 接口,让用户可以通过浏览器与 ES 通信。
- ES 是个分布式搜索和分析引擎,优点是能对大容量的数据进行接近实时的存储、搜索和分析操作。
2.2 Logstash
- Logstash 作为数据收集引擎。它支持动态的从各种数据源搜索数据,并对数据进行过滤、分析、丰富、统一格式等操作,然后存储到用户指定的位置,一般会发送给 ES。
- Logstash 由 JRuby 语言编写,运行在 JAVA 虚拟机(JVM)上,是一款强大的数据处理工具,可以实现数据传输、格式处理、格式化输出。Logstash 具有强大的插件功能,常用于日志处理。
2.3 Kibana
- Kibana 是基于 Node.js 开发的展示工具,可以为 Logstash 和 ES 提供图形化的日志分析 Web 界面展示,可以汇总、分析和搜索重要数据日志。
2.4 Filebeat
- Filebeat 是一款轻量级的开源日志文件数据搜索器。通常在需要采集数据的客户端安装 Filebeat,并指定目录与日志格式,Filebeat 就能快速收集数据,并发送给 Logstash 进行解析,或是直接发给 ES 存储,性能上相比运行于 JVM 上的 Logstash 优势明显,是对它的替代。
日志的集中化管理 beats 包括四种工具:
Packetbeat(搜索网络流量数据)
Topbeat(搜索系统、进程和文件系统级别的 CPU 和内存使用情况等数据)
Filebeat(搜集文件数据)
Winlogbeat(搜集 Windows 时间日志数据)
3. 完整日志系统的基本特征
- 收集:能够采集多种来源的日志数据
- 传输:能够稳定的把日志数据解析过滤并传输到存储系统
- 存储:存储日志数据
- 分析:支持 UI 分析
- 警告:能够提供错误报告,监控机制
4. ELK的工作原理

- AppServer 是一个类似于 Nginx、Apache 的集群,其日志信息由 Logstash 来收集
- 往往为了减少网络问题所带来的瓶颈,会把 Logstash 服务放入前者的集群内,减少网络的消耗
- Logstash 把收集到的日志数据格式化后输出转存至 ES 数据库内(这是一个将日志进行集中化管理的过程)
- 随后,Kibana 对 ES 数据库内格式化后日志数据信息进行索引和存储
- 最后,Kibana 把其展示给客户端
二、部署 ELK 日志分析系统

1. 服务器配置
| 服务器 | 配置 | 主机名 | ip地址 | 主要软件 |
|---|---|---|---|---|
| node1 节点 | 2C/4G | node1 | 192.168.10.100 | ElasticSearch、Kibana |
| node2 节点 | 2C/4G | node2 | 192.168.10.101 | ElasticSearch |
| apache 节点 | - | apache | 192.168.10.102 | Logstash、Apache |
2. 关闭防火墙
systemctl stop firewalld && systemctl disable firewalld
setenforce 0
ntpdate ntp.aliyun.com
123
3. ElasticSearch集群部署(node1、node2)
3.1 环境准备
以 node1 为例
[root@localhost ~]# hostnamectl set-hostname node1
[root@localhost ~]# su
[root@node1 ~]# echo "192.168.10.100 node1" >> /etc/hosts
[root@node1 ~]# echo "192.168.10.101 node2" >> /etc/hosts
[root@node1 ~]# java -version #不建议使用 openjdk
# rpm 安装 jdk (方法一)
cd /opt
#将软件包传至该目录下
rpm -ivh jdk-8u201-linux-x64.rpm
vim /etc/profile.d/java.sh
export JAVA_HOME=/usr/java/jdk1.8.0_201-amd64
export CLASSPATH=.:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/dt.jar
export PATH=$JAVA_HOME/bin:$PATH
#注释:
1.输出定义java的工作目录
2.输出指定java所需的类文件
3.输出重新定义环境变量,$PATH一定要放在$JAVA_HOME的后面,让系统先读取到工作目录中的版本信息
source /etc/profile.d/java.sh
java -version
# rpm 安装 jdk (方法二)
cd /opt
tar zxvf jdk-8u91-linux-x64.tar.gz -C /usr/local
mv /usr/local/jdk1.8.0_91/ /usr/local/jdk
vim /etc/profile
export JAVA_HOME=/usr/local/jdk
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
source /etc/profile
java -version
12345678910111213141516171819202122232425262728293031323334353637
3.2 部署 ElasticSearch 软件
3.2.1 安装 elasticsearch-rpm 包
以 node1 为例
[root@node1 ~]# cd /opt
[root@node1 opt]# rz -E
#上传elasticsearch-5.5.0.rpm到/opt目录下
rz waiting to receive.
[root@node1 opt]# rpm -ivh elasticsearch-5.5.0.rpm
12345
3.2.2 加载系统服务
以 node1 为例
systemctl daemon-reload && systemctl enable elasticsearch.service
1
3.2.3 修改 elasticsearch 主配置文件
以 node1 为例
[root@node1 opt]# cp /etc/elasticsearch/elasticsearch.yml /etc/elasticsearch/elasticsearch.yml.bak
#备份配置文件
[root@node1 opt]# vim /etc/elasticsearch/elasticsearch.yml
##17行,取消注释,指定群集名称
cluster.name: my-elk-cluster
##23行,取消注释,指定节点名称(node1节点为node1,node2节点为node2)
node.name: node1
##33行,取消注释,指定数据存放路径
path.data: /data/elk_data
##37行,取消注释,指定日志存放路径
path.logs: /var/log/elasticsearch/
##43行,取消注释,不在启动的时候锁定内存(前端缓存,与IOPS-性能测试方式,每秒读写次数相关)
bootstrap.memory_lock: false
##55行,取消注释,设置监听地址,0.0.0.0代表所有地址
network.host: 0.0.0.0
##59行,取消注释,ES服务的默认监听端口为9200
http.port: 9200
##68行,取消注释,集群发现通过单播实现,指定要发现的节点node1、node2
discovery.zen.ping.unicast.hosts: ["node1", "node2"]
[root@node1 opt]# grep -v "^#" /etc/elasticsearch/elasticsearch.yml
cluster.name: my-elk-cluster
node.name: node1
path.data: /data/elk_data
path.logs: /var/log/elasticsearch/
bootstrap.memory_lock: false
network.host: 0.0.0.0
http.port: 9200
discovery.zen.ping.unicast.hosts: ["node1", "node2"]
-------------------------------------------------------
scp /etc/elasticsearch/elasticsearch.yml root@192.168.10.101:/etc/elasticsearch/elasticsearch.yml
#将配置好的文件用 scp 传至 node2,后续只用去改个节点名字即可
12345678910111213141516171819202122232425262728293031323334
3.2.4 创建数据存放路径并授权
以 node1 为例
[root@node1 opt]# mkdir -p /data/elk_data
[root@node1 opt]# chown elasticsearch:elasticsearch /data/elk_data/
12
3.2.5 启动 elasticsearch
以 node1 为例
[root@node1 opt]# systemctl start elasticsearch.service
[root@node1 opt]# netstat -natp | grep 9200 #启动较慢,需等待
tcp6 0 0 :::9200 :::* LISTEN 4216/java
123
3.2.6 查看节点信息
浏览器访问 http://192.168.10.100:9200、http://192.168.10.101:9200 查看节点 node1、node2 的信息`
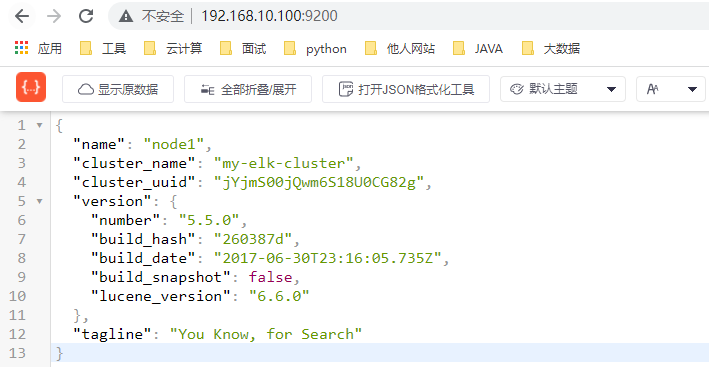
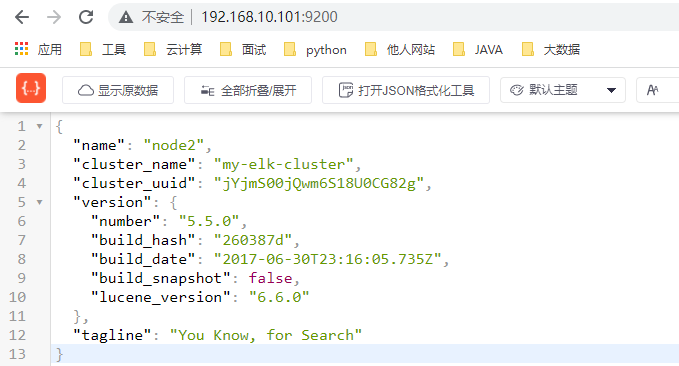
`浏览器访问 http://192.168.10.100:9200/_cluster/health?pretty、http:// 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1856
1856

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











