






本文来自于个人博客:https://docs.wziqi.vip/
安装logstash
wget https://artifacts.elastic.co/downloads/logstash/logstash-7.14.0-x86_64.rpm
yum -y localinstall logstash-7.14.0-x86_64.rpm
ln -sv /usr/share/logstash/bin/logstash /usr/local/bin/
下载地址:
https://www.elastic.co/downloads/past-releases#logstash
文档连接:
https://www.elastic.co/guide/en/logstash/7.14/index.html语法参数
logstash -t conf/logstash.conf # 检查文件是否有语法错误
logstash -f conf/logstash.conf # 运行logstash指定配置文件
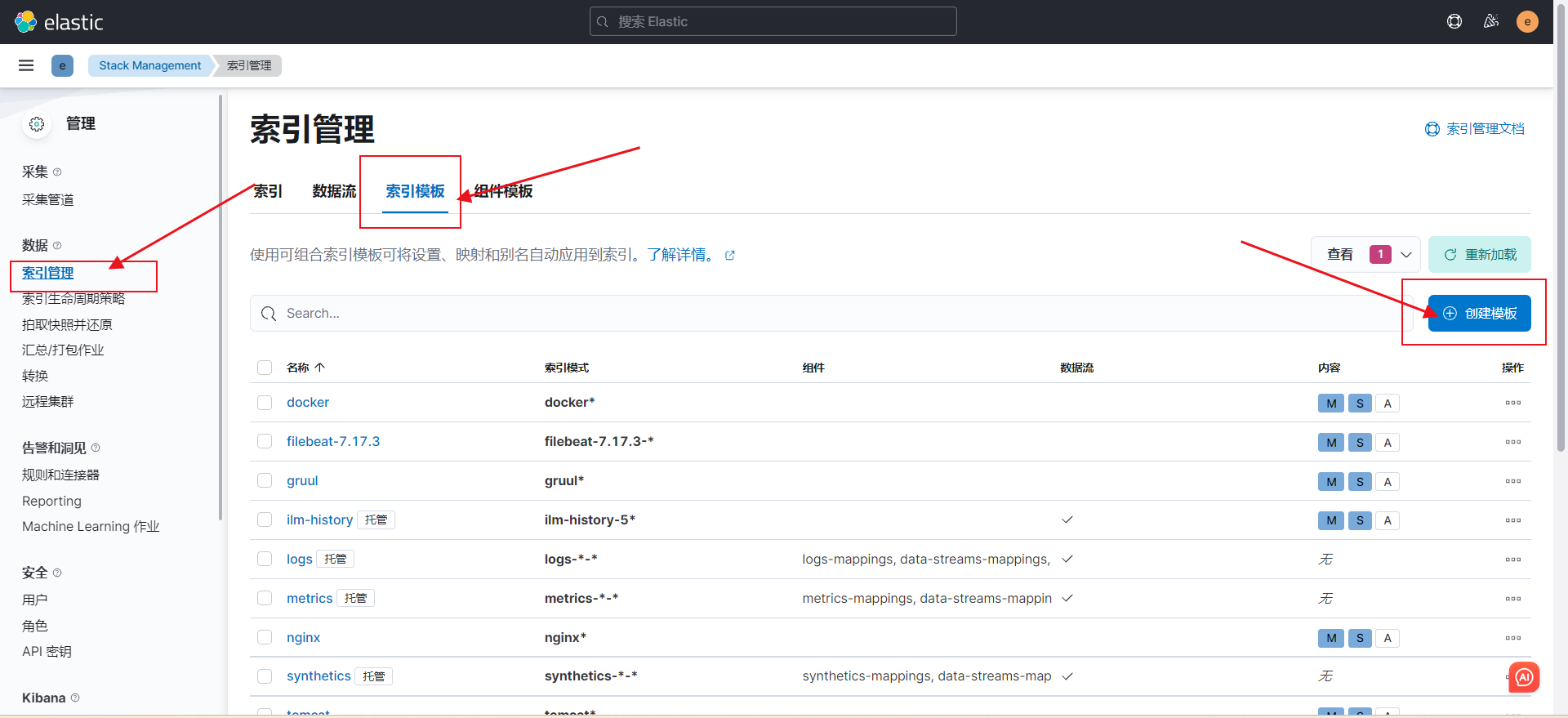
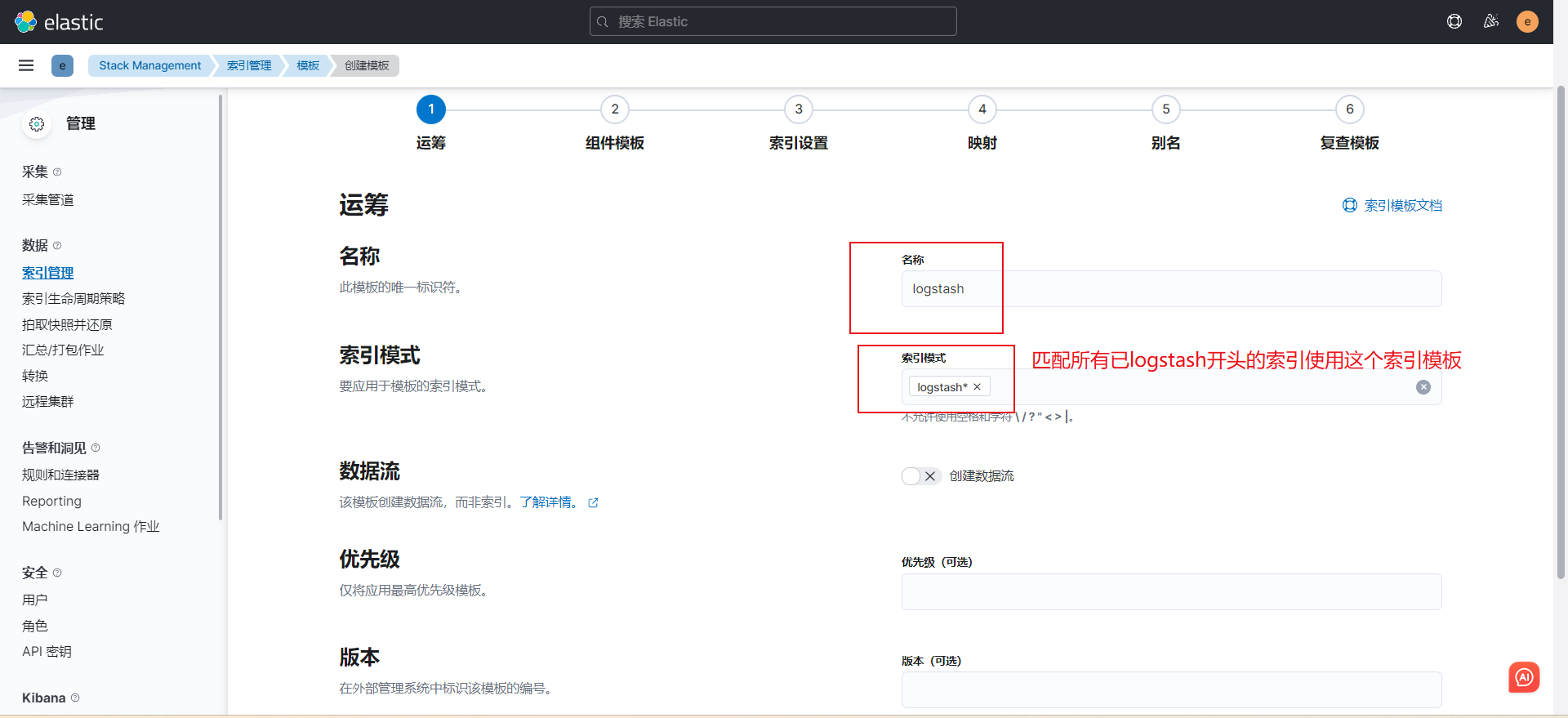
logstash -rf conf/logstash.conf # 运行logstash + 配置热加载创建索引模板
"number_of_shards": "3",
"number_of_replicas": "1"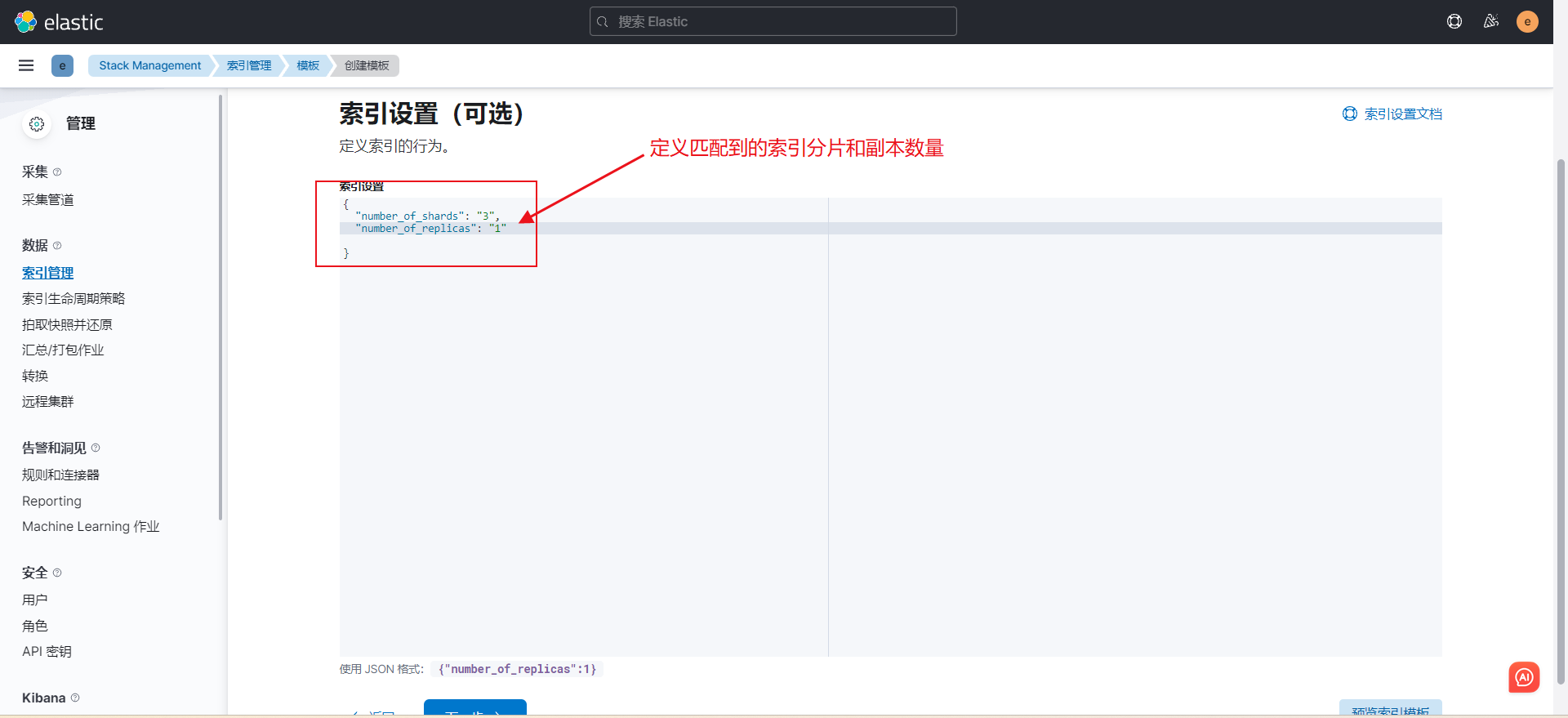
剩下的都下一步就行了
常用示例
1. input基于file案例,输出到ES
1)配置文件修改
vim 01-file-to-ES.conf
input {
file {
# 配置文件路径
path => ["/opt/logstash/logs/*.txt"]
# 指定文件的读取位置偏移量
start_position => "beginning"
#start_position => "end"
}
}
output {
elasticsearch {
hosts => ["192.168.1.12:9200","192.168.1.13:9200","192.168.1.14:9200"]
index => "logstash-file-%{+YYYY.MM.dd}"
user => "elastic"
password => "123qqq...A"
}
}
单独说一下start_position参数,logstash有一个存储偏移量的文件放在/usr/share/logstash/data/plugins/inputs/file/下边
当清空偏移量文件的时候,配置beginning,logstash会把指定的 *.txt 文件内的内容从开头输出出来
当配置为end的话,logstash则不会把当前 *.txt 里现有的数据给输出,会直接把偏移量记录,只输出启动后新加的数据2)创建测试文件
[root@node-002 logstash]# echo testfile >> logs/file.txt
[root@node-002 logstash]# echo testfile >> logs/file.txt
[root@node-002 logstash]# echo testfile >> logs/file.txt
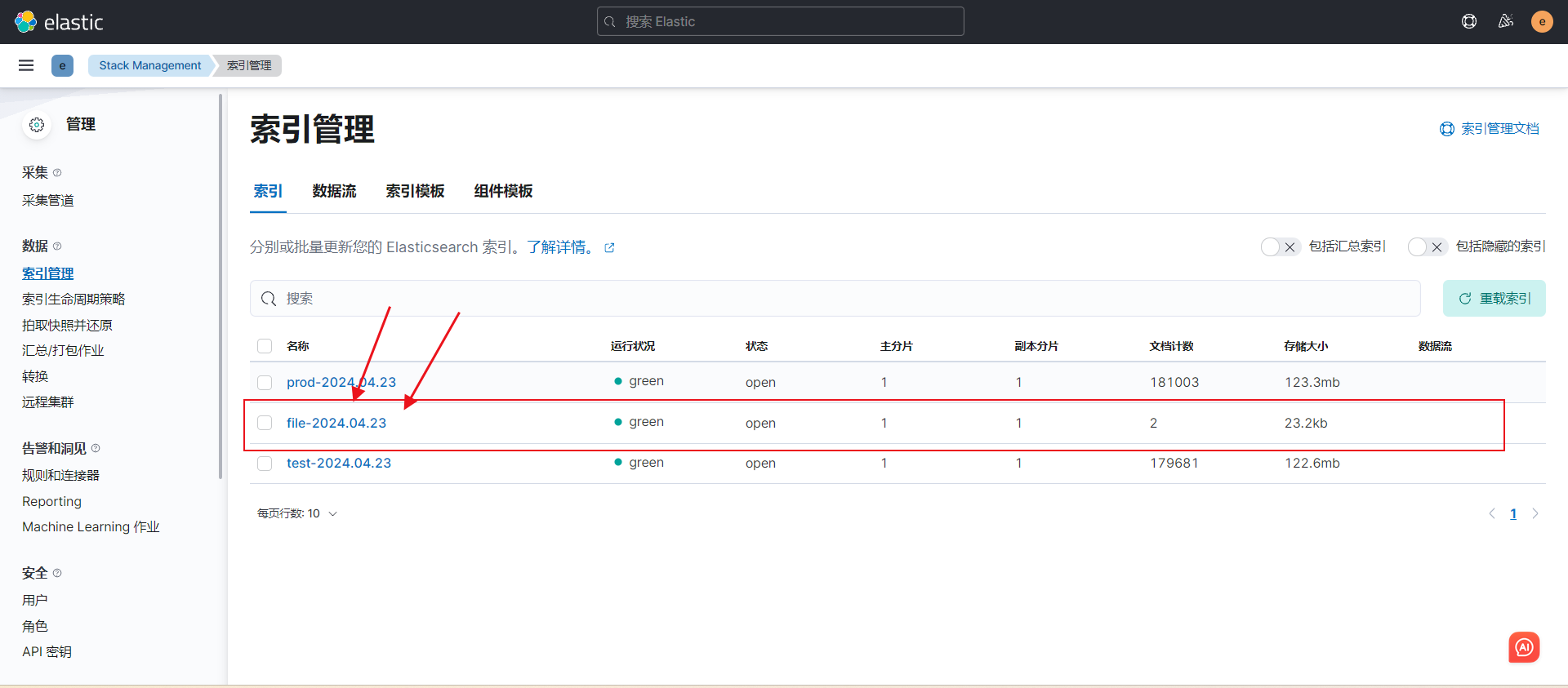
[root@node-002 logstash]# echo testfile >> logs/file.txt 3)启动服务并查看效果
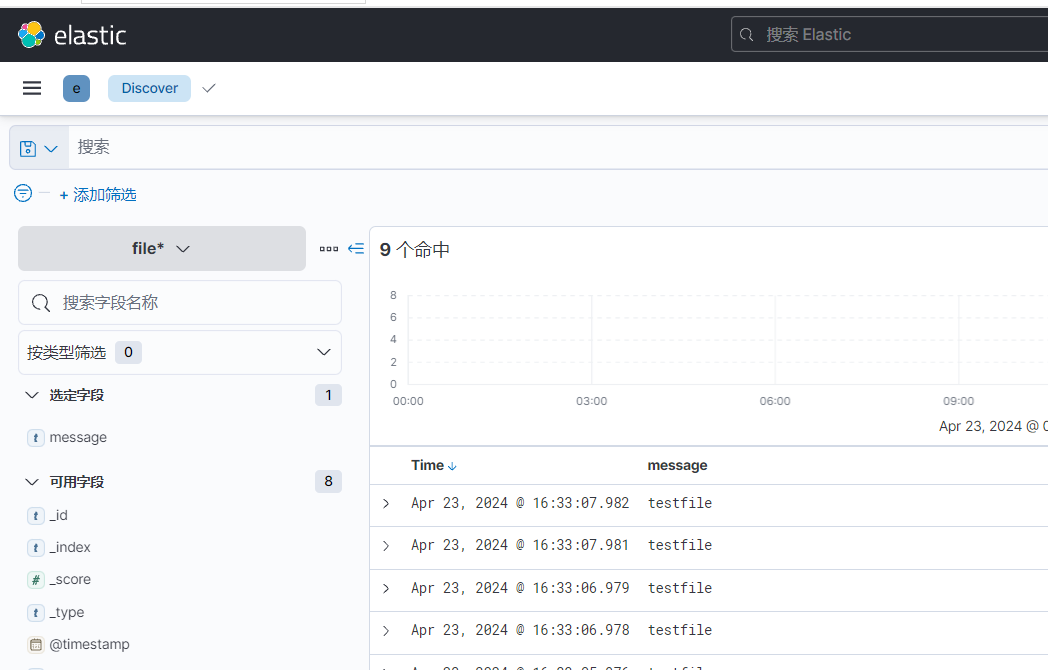
2. input基于TCP案例,输出到ES
流程图
1)配置文件修改
vim 02-tcp-to-es.conf
input {
tcp {
port => 8888
}
# 可以配置多个
#tcp {
# port => 8888
#}
}
output {
elasticsearch {
hosts => ["192.168.1.12:9200","192.168.1.13:9200","192.168.1.14:9200"]
index => "tcp-to-es-%{+YYYY.MM.dd}"
user => "elastic"
password => "123qqq...A"
}
}2)连接tcp端口测试效果
telnet 192.168.1.13 88883)查看效果
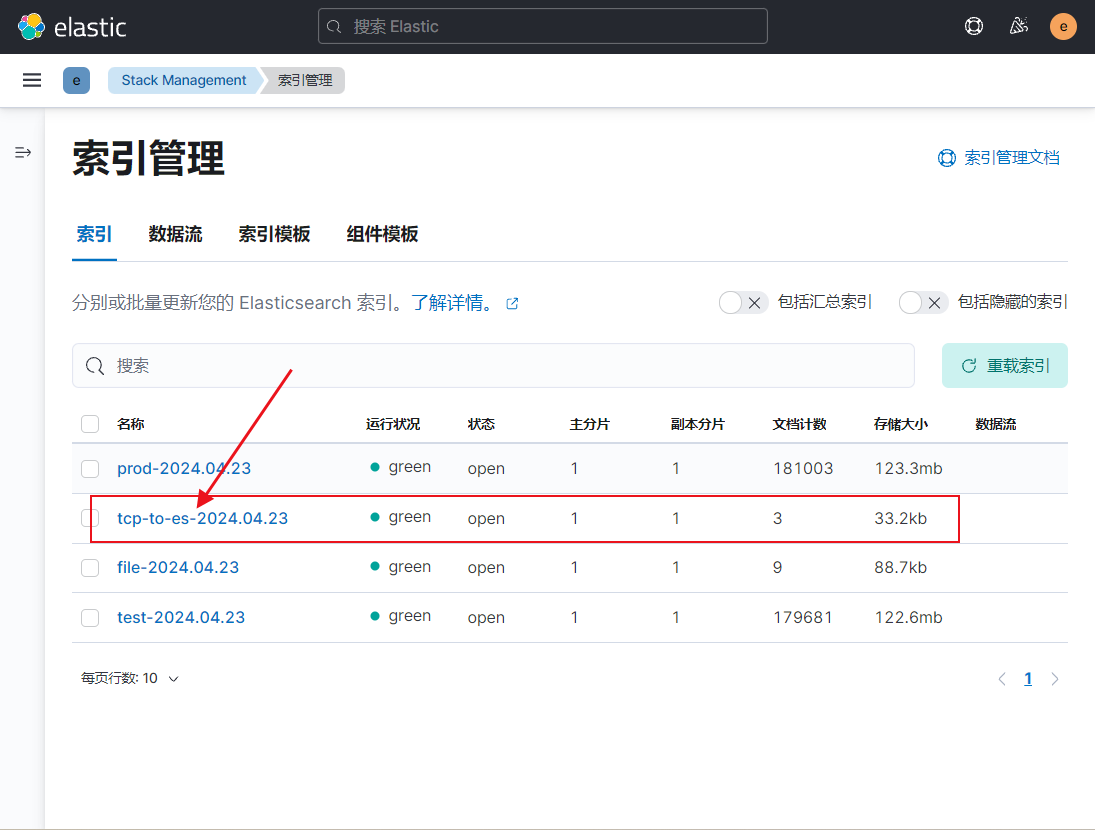
3. input基于redis案例,输出到ES
logstash获取redis的流程是拿一条删一条,所以redis中不会有日志数据
流程图
1)配置文件修改
1) vim 03-redis-to-es.conf
input {
redis {
# 指定的是REDIS的键(key)的类型
data_type => "list"
# 指定数据库的编号,默认值是0号数据库
db => 2
# 指定数据库的ip地址,默认值是localhost
host => "192.168.1.13"
# 指定数据库的端口号,默认值为6379
port => 6379
# 指定redis的认证密码
password => "testpassWord"
# 指定从redis的哪个key取数据
key => "redis-ES"
}
}
output {
elasticsearch {
hosts => ["192.168.1.12:9200","192.168.1.13:9200","192.168.1.14:9200"]
index => "redis-es-%{+YYYY.MM.dd}"
user => "elastic"
password => "123qqq...A"
}
}
2) logstash -f 03-redis-to-es.conf2)redis添加测试数据
1) 我启动了一个filebeat来测试,如果不想启动的话自己创建几条数据也行
vim filebeat.yml
filebeat.inputs:
- type: tcp # 修改为TCP类型
host: "0.0.0.0:9000" # 监听端口配置9000
output.redis: # 输出目的类型配置redis
hosts: ["192.168.1.13:6379"] # 配置redis地址
password: "testpassWord" # redis密码
db: 2 # db指定
key: "redis-ES" # key名称
timeout: 3 # 超时时间
2) 启动filebeat
filebeat -e -c filebeat.yml
3) 测试,这边连接filebeat的tcp端口,然后把数据传到redis,logstash在从redis拿数据传输到ES集群,注意logstash在redis中获取数据是拿一条删一条,所以性能快的话redis里是不会有数据保留
telnet 192.168.1.13 9000 3)查看数据
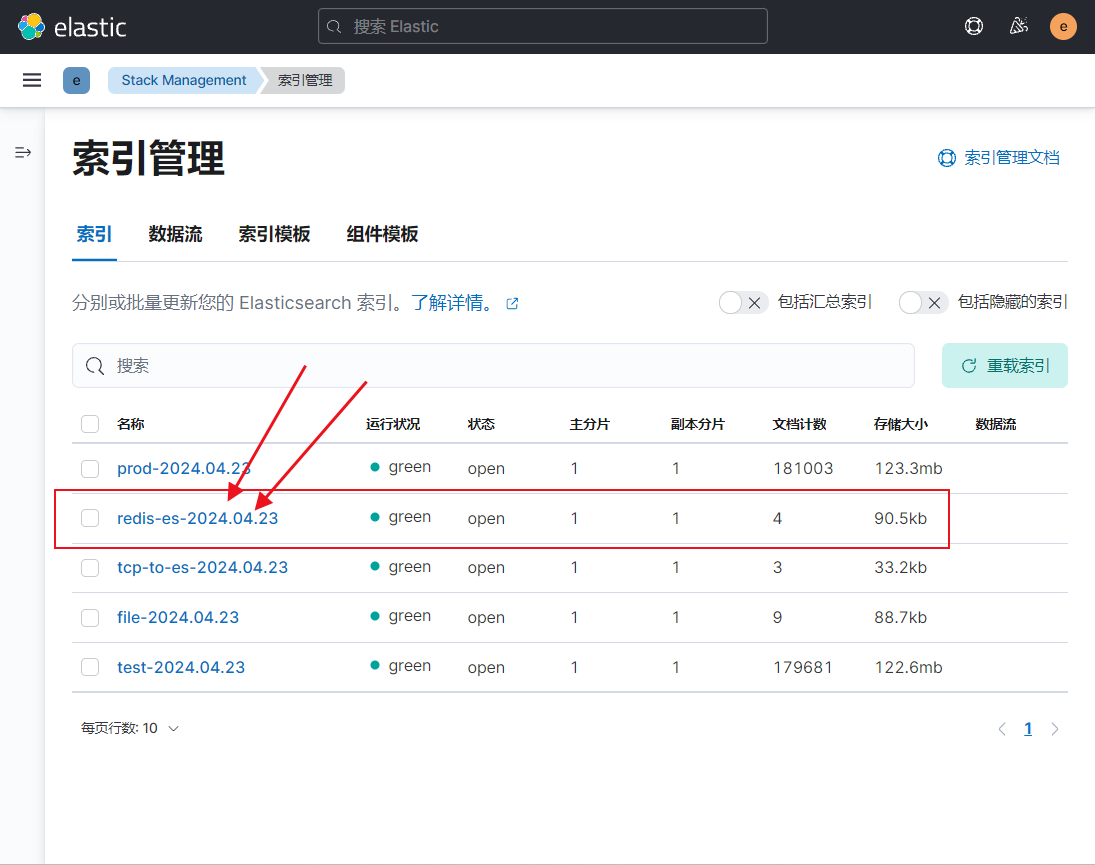
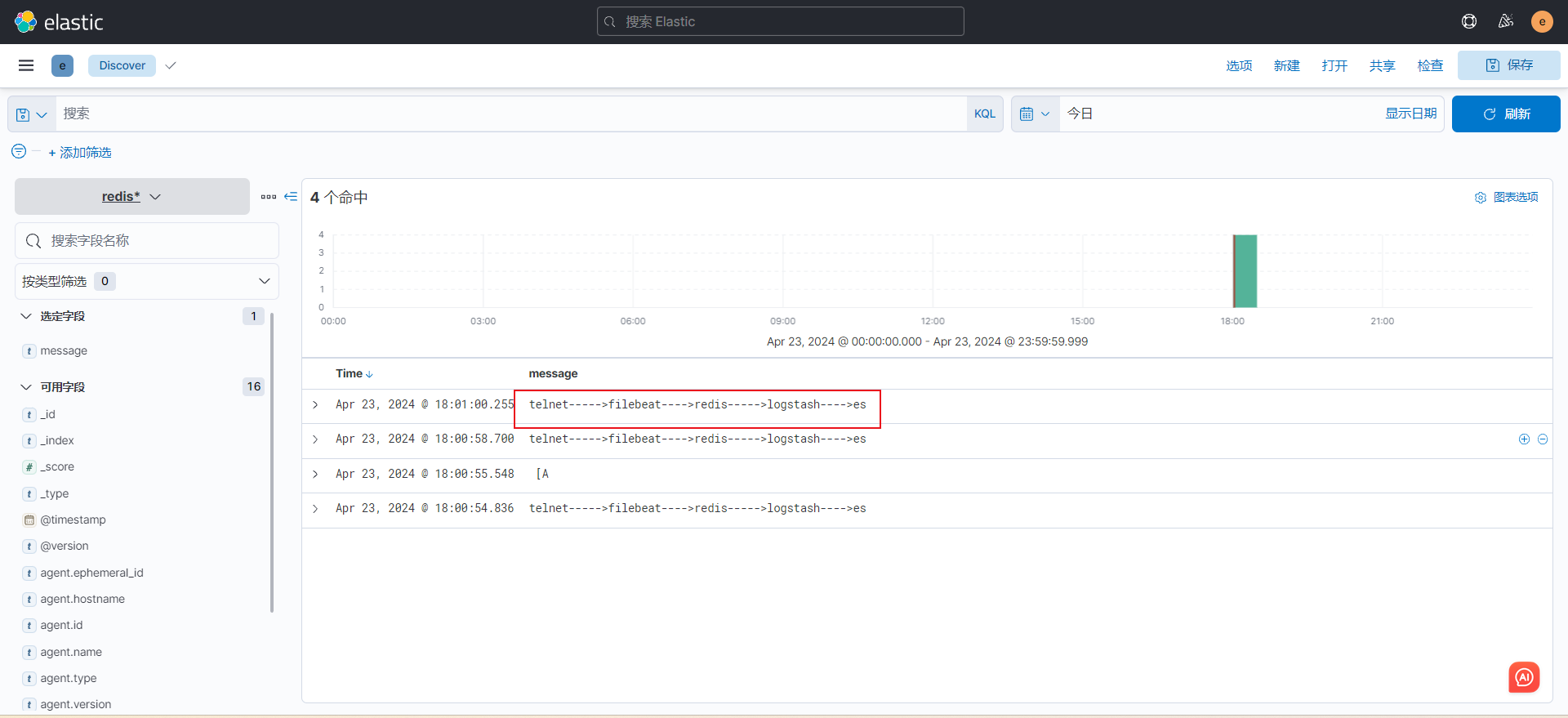
4. input插件基于beats案例,输出到ES
logstash有一个beats的input插件,可以配合filebeat来使用,实现filebeat收集日志传出到logstash在存储到es集群,这样就可以不用每台服务器上都部署一个资源占用比较大的logstash服务而可以部署一个资源占用比较小的filebeat
流程图
1)修改filebeat配置文件,并启动服务
filebeat.inputs:
- type: tcp # 修改为TCP类型
host: "0.0.0.0:9000" # 监听端口配置9000
output.logstash: # 输出目的类型配logstash
hosts: ["192.168.1.13:5044"] # 配置logstash地址2)修改logstash配置文件,并启动服务
input {
beats {
port => 5044 # 配置beats端口来监听来自filebeat的日志
}
}
output {
elasticsearch { # 传输到es集群中
hosts => ["192.168.1.12:9200","192.168.1.13:9200","192.168.1.14:9200"]
index => "filebeat-logstash-%{+YYYY.MM.dd}"
user => "elastic"
password => "123qqq...A"
}
}3)创建测试数据查看效果
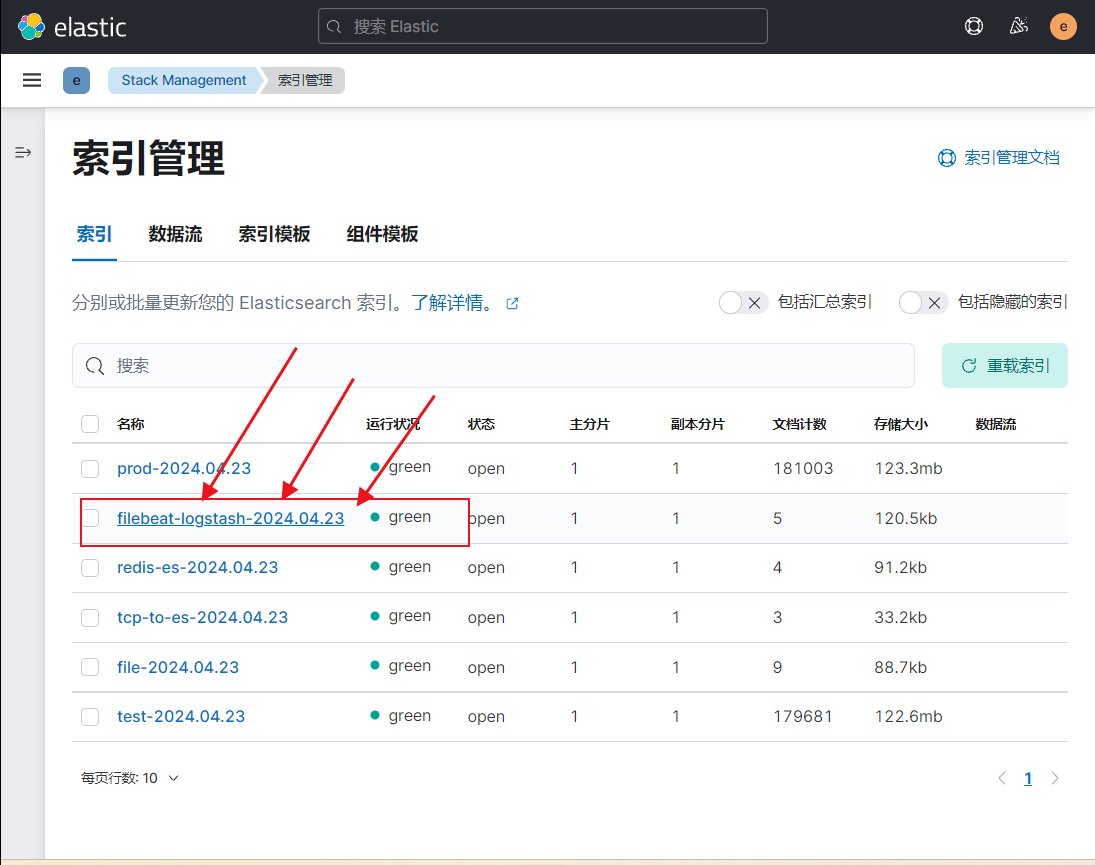
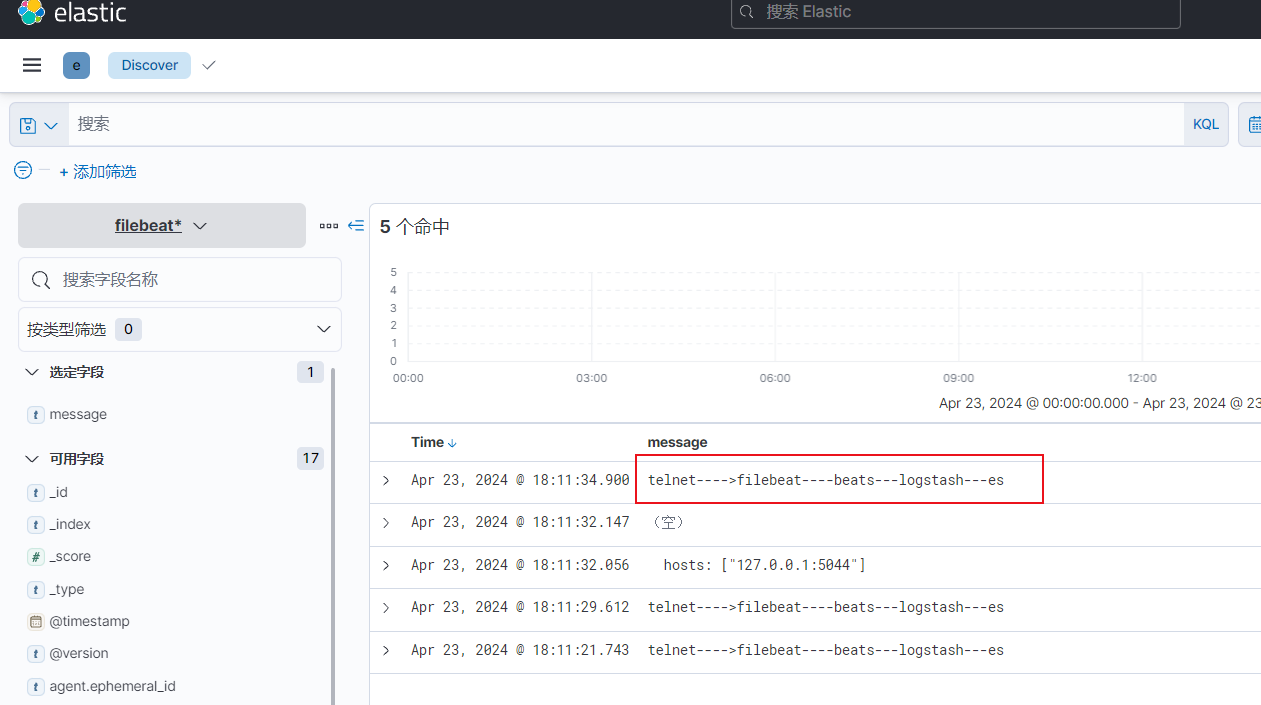
5. output插件基于redis案例
流程图
1)配置文件修改
vim output-redis.conf
input {
file {
# 定义输入的日志文件名称和路径
path => ["/tmp/file-redis.log"]
start_position => "beginning"
}
}
output {
redis {
# 定义redis地址
host => "192.168.1.13"
# 定义redis端口
port => "6379"
# 定义redis db库
db => 0
# redis 密码
password => "testpassWord"
# 写入数据的key类型
data_type => "list"
# 写入数据的key名称
key => "file-redis"
}
}2)启动服务
logstash -f output-redis.conf3)查看效果
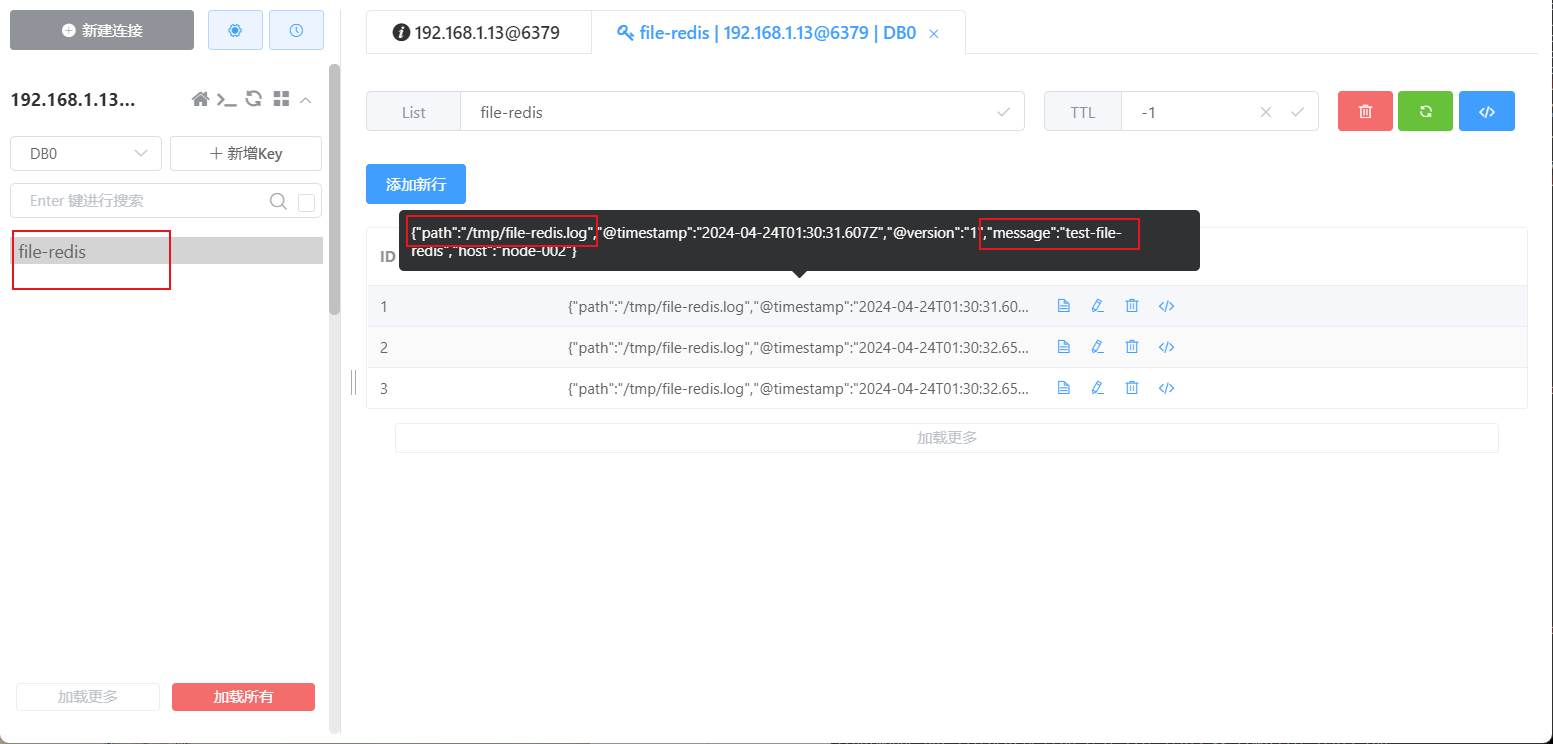
6. output插件基于file案例
流程图
1)修改配置文件
vim redis-to-file.conf
input {
redis {
# 定义redis地址
host => "192.168.1.13"
# 定义redis端口
port => "6379"
# 定义redis db库
db => 0
# redis 密码
password => "testpassWord"
# 写入数据的key类型
data_type => "list"
# 写入数据的key名称
key => "file-redis"
}
}
output {
file {
# 定义文件路径,如果没有则会自动创建
path => "/tmp/redis-file.log"
# 定义目录权限
#dir_mode => 0755
# 定义文件权限
file_mode => 0755
}
}2)启动服务
logstash -f redis-to-file.conf7. 综合案例(多输入源 输出到不同索引中)
流程图
1)修改配置文件
vim logstash.conf
input {
file {
# 配置从收集文件内容
type => "file"
path => ["/opt/logstash/logs/*.txt"]
# 指定文件的读取位置 beginning--清除完偏移量文件后会从头开始读 end--就算清楚了偏移量文件也会从文件末尾读
start_position => "beginning"
#start_position => "end"
}
redis {
type => redis
# 指定的是REDIS的键(key)的类型
data_type => "list"
# 指定数据库的编号,默认值是0号数据库
db => 2
# 指定数据库的ip地址,默认值是localhost
host => "192.168.1.13"
# 指定数据库的端口号,默认值为6379
port => 6379
# 指定redis的认证密码
password => "testpassWord"
# 指定从redis的哪个key取数据
key => "filebeat-to-redis"
}
}
output {
# 利用type定义的字段来区分不同的输入源数据输出到不同索引中
if [type] == "file" {
elasticsearch {
hosts => ["192.168.1.12:9200","192.168.1.13:9200","192.168.1.14:9200"]
index => "logstash-file-%{+YYYY.MM.dd}"
user => "elastic"
password => "123qqq...A"
}
} else if [type] == "redis" {
elasticsearch {
hosts => ["192.168.1.12:9200","192.168.1.13:9200","192.168.1.14:9200"]
index => "logstash-redis-%{+YYYY.MM.dd}"
user => "elastic"
password => "123qqq...A"
}
}
}2)启动服务
logstash -f logstash.conf8. filter 插件(日志过滤)
grok类型
gork插件:
Grok是将非结构化日志数据解析为结构化和可查询的好方法。底层原理是基于正则匹配任意文本格式。
该工具非常适合syslog日志、apache和其他网络服务器日志、mysql日志,以及通常为人类而非计算机消耗而编写的任何日志格式。
内置120种匹配模式,当然也可以自定义匹配模式:
https://github.com/logstash-plugins/logstash-patterns-
core/tree/master/patterns
# 删除几个无用字段,通用组件在那个插件内都可以使用
remove_field => [ "@version","auth","httpversion", "host", "@timestamp" ]
# 添加几个自定义字段,通用组件在那个插件内都可以使用
add_field => {
"school" => "nginx访问日志" }1)案例演示(用grok和不用的日志效果区别)
### 先不使用filter插件看下日志收集效果
vim filter-grok.conf
input {
file {
# 配置文件路径
path => ["/var/log/nginx/access.log"]
start_position => "beginning"
#start_position => "end"
}
}
output {
stdout {}
}
### 日志输出效果(这边不配置filter的话是几个默认字段)
{
"message" => "192.168.1.81 - - [01/May/2024:17:51:33 +0800] \"GET /test/index.html HTTP/1.1\" 404 153 \"-\" \"curl/7.29.0\" \"-\"",
"@timestamp" => 2024-05-01T09:51:33.396Z,
"@version" => "1",
"path" => "/var/log/nginx/access.log",
"host" => "localhost.localdomain"
}
{
"message" => "192.168.1.81 - - [01/May/2024:17:51:35 +0800] \"GET / HTTP/1.1\" 200 615 \"-\" \"curl/7.29.0\" \"-\"",
"@timestamp" => 2024-05-01T09:51:36.405Z,
"@version" => "1",
"path" => "/var/log/nginx/access.log",
"host" => "localhost.localdomain"
}
#### 配置了filter插件
input {
file {
# 配置文件路径
path => ["/var/log/nginx/access.log"]
start_position => "beginning"
#start_position => "end"
}
}
filter {
grok {
match => {
"message" => "%{HTTPD_COMMONLOG}" # 使用grok自带的模式来处理日志,
}
}
}
output {
stdout {}
}
### 日志输出效果(这边除了几个默认的字段还有grok自己提取出来的一些字段)
{
"clientip" => "192.168.1.81",
"request" => "/",
"httpversion" => "1.1",
"host" => "localhost.localdomain",
"auth" => "-",
"message" => "192.168.1.81 - - [01/May/2024:17:58:24 +0800] \"GET / HTTP/1.1\" 200 615 \"-\" \"curl/7.29.0\" \"-\"",
"@timestamp" => 2024-05-01T09:58:25.249Z,
"timestamp" => "01/May/2024:17:58:24 +0800",
"response" => "200",
"@version" => "1",
"verb" => "GET",
"ident" => "-",
"bytes" => "615",
"path" => "/var/log/nginx/access.log"
}
{
"clientip" => "192.168.1.81",
"request" => "/test/index.html",
"httpversion" => "1.1",
"host" => "localhost.localdomain",
"auth" => "-",
"message" => "192.168.1.81 - - [01/May/2024:17:58:26 +0800] \"GET /test/index.html HTTP/1.1\" 404 153 \"-\" \"curl/7.29.0\" \"-\"",
"@timestamp" => 2024-05-01T09:58:26.255Z,
"timestamp" => "01/May/2024:17:58:26 +0800",
"response" => "404",
"@version" => "1",
"verb" => "GET",
"ident" => "-",
"bytes" => "153",
"path" => "/var/log/nginx/access.log"
}2)删除/添加 输出字段
### 修改配置文件
vim filter.conf
input {
file {
# 配置文件路径
path => ["/var/log/nginx/access.log"]
start_position => "beginning"
#start_position => "end"
}
}
filter {
grok {
match => {
"message" => "%{HTTPD_COMMONLOG}" # 使用grok自带的模式来处理日志
}
# 删除几个无用字段,通用组件在那个插件内都可以使用
remove_field => [ "@version","auth","httpversion", "host", "@timestamp" ]
# 添加几个自定义字段,通用组件在那个插件内都可以使用
add_field => {
"school" => "nginx访问日志"
# 这边还可以拿字段中的数据当作自定义字段
"soucre-clientip" => "clientip ---> %{clientip}"
}
}
}
output {
stdout {}
}
### 查看日志收集效果
{
"response" => "200",
"message" => "192.168.1.81 - - [01/May/2024:18:10:57 +0800] \"GET / HTTP/1.1\" 200 615 \"-\" \"curl/7.29.0\" \"-\"",
"verb" => "GET",
"clientip" => "192.168.1.81",
"timestamp" => "01/May/2024:18:10:57 +0800",
"soucre-clientip" => "clientip ---> 192.168.1.81", # 这便是取字段数据自定义的字段
"ident" => "-",
"path" => "/var/log/nginx/access.log",
"request" => "/",
"school" => "nginx访问日志", # 可以看到自定义的字段
"bytes" => "615"
}
{
"response" => "404",
"message" => "192.168.1.81 - - [01/May/2024:18:10:58 +0800] \"GET /test/index.html HTTP/1.1\" 404 153 \"-\" \"curl/7.29.0\" \"-\"",
"verb" => "GET",
"clientip" => "192.168.1.81",
"timestamp" => "01/May/2024:18:10:58 +0800",
"soucre-clientip" => "clientip ---> 192.168.1.81",
"ident" => "-",
"path" => "/var/log/nginx/access.log",
"request" => "/test/index.html",
"school" => "nginx访问日志",
"bytes" => "153"
}
3)自定义匹配模式
# 这边是按照我的nginx访问日志随便写了几个匹配的,不适用于所有,只是了解一下知道可以这样搞,官方给了很多已经写好的可以使用
mkdir patterns && vim prok
NGINX_IP \b(?:[0-9]{1,3}\.){3}[0-9]{1,3}\b # 匹配IP地址
NGINX_TIMESTAMP \[(.*?)\] # 匹配时间戳
NGINX_REQUEST \"(.*?)\" # 匹配HTTP 请求
NGINX_RESPONSE \d+ # HTTP 响应状态码
NGINX_VERB \"(.*?)\" # 匹配 HTTP 请求的方法
NGINX_BYTES \d+ # 匹配响应的字节数
NGINX_REFERRER \"(.*?)\" # 匹配 HTTP 请求的引用页
NGINX_AGENT \"(.*?)\" # 匹配 HTTP 请求的用户代理4)logstash配置文件
input {
file {
# 配置文件路径
path => ["/var/log/nginx/access.log"]
start_position => "beginning"
#start_position => "end"
}
}
filter {
grok {
patterns_dir => ["./patterns"]
match => {
"message" => "%{NGINX_IP:ip} - - %{NGINX_TIMESTAMP:timestamp} %{NGINX_REQUEST:request} %{NGINX_RESPONSE:response} %{NGINX_BYTES:bytes} %{NGINX_REFERRER:referrer} %{NGINX_AGENT:agent}"
}
remove_field => [ "@version","auth","", "host", "@timestamp" ]
}
}
output {
stdout {}
}
5)日志内容和收集效果
echo '115.213.121.121 - - [24/Apr/2024:15:23:07 +0800] "GET /api/count HTTP/1.1" 20000 5000 "https://abc.abc.cn/h5/" "Mozilla/5.0 (iPhone; CPU iPhone OS 16_6 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/16.6 Mobile/15E148 Safari/604.1" "-"' >> /var/log/nginx/access.log
{
"ip" => "115.213.121.121",
"response" => "20000",
"message" => "115.213.62.150 - - [24/Apr/2024:15:23:07 +0800] \"GET /api/count HTTP/1.1\" 20000 5000 \"https://abc.abc.cn/h5/\" \"Mozilla/5.0 (iPhone; CPU iPhone OS 16_6 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/16.6 Mobile/15E148 Safari/604.1\" \"-\"",
"timestamp" => "[24/Apr/2024:15:23:07 +0800]",
"request" => "\"GET /api/count HTTP/1.1\"",
"bytes" => "5000",
"referrer" => "\"https://abc.abc.cn/h5/\"",
"agent" => "\"Mozilla/5.0 (iPhone; CPU iPhone OS 16_6 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/16.6 Mobile/15E148 Safari/604.1\"",
"path" => "/var/log/nginx/access.log"
}date插件修改写入es的时间
# 我没用到,只是记录一下
filter {
grok {
match => {
"message" => "%{HTTPD_COMMONLOG}"
}
# 移除指定的字段
remove_field => [ "host", "@version", "ecs", "tags","agent","input", "log" ]
}
date {
match => ["timestamp","dd/MMM/yyyy:HH:mm:ss +0800"]
# 建议大家设置为"Asia/Shanghai",写入ES的数据是准确的!
timezone => "Asia/Shanghai"
# 将匹配到到时间字段解析后存储到目标字段,若不指定,则默认字段为"@timestamp"字段
target => "nginx-timestamp"
}
}9. geoip分析源ip的地址位置
1)修改配置文件
input {
file {
# 配置文件路径
path => ["/var/log/nginx/access.log"]
start_position => "beginning"
#start_position => "end"
}
}
filter {
grok {
match => {
# 使用grok插件自带的正则匹配规则
"message" => "%{HTTPD_COMMONLOG}"
}
# 删除几个无用字段
remove_field => [ "@version","auth","", "host", "@timestamp" ]
}
geoip {
# 指定基于哪个字段分析IP地址
source => "clientip"
# 分析完IP地址后会有一些默认字段展示,这边可以配置只看那些,如果不配置则全部展示
#fields => ["city_name","country_name","ip"]
# 指定geoip的输出字段,如果不指定的话默认字段都是在geoip下
#target => "nginx-access"
}
}
output {
stdout {}
}
2)查看日志效果
{
"httpversion" => "1.1",
"response" => "404",
"message" => "124.222.25.145 - - [01/May/2024:18:21:23 +0800] \"GET /test/index.html HTTP/1.1\" 404 153 \"-\" \"curl/7.29.0\" \"-\"",
"verb" => "GET",
"geoip" => { # 这个字段下边就是IP地址信息,有经纬度和国家地区信息,也可以用上边注释的配置隐掉几个无用字段
"location" => {
"lon" => 113.7266,
"lat" => 34.7725
},
"latitude" => 34.7725,
"country_code3" => "CN",
"timezone" => "Asia/Shanghai",
"country_code2" => "CN",
"continent_code" => "AS",
"ip" => "124.222.25.145",
"longitude" => 113.7266,
"country_name" => "China"
},
"clientip" => "124.222.25.145",
"timestamp" => "01/May/2024:18:21:23 +0800",
"ident" => "-",
"path" => "/var/log/nginx/access.log",
"request" => "/test/index.html",
"bytes" => "153"
}10. useragent 插件分析客户端的设备类型
流程图
1)需要先改一下nginx的默认日志格式,把设备字段单拎出来
vim /etc/nginx/nginx.conf
...
log_format oldboyedu_nginx_json '{"@timestamp":"$time_iso8601",'
'"host":"$server_addr",'
'"clientip":"$remote_addr",'
'"SendBytes":$body_bytes_sent,'
'"responsetime":$request_time,'
'"upstreamtime":"$upstream_response_time",'
'"upstreamhost":"$upstream_addr",'
'"http_host":"$host",'
'"uri":"$uri",'
'"domain":"$host",'
'"xff":"$http_x_forwarded_for",'
'"referer":"$http_referer",'
'"tcp_xff":"$proxy_protocol_addr",'
'"http_user_agent":"$http_user_agent",'
'"status":"$status"}';
access_log /var/log/nginx/access.log oldboyedu_nginx_json;
(2)检查nginx的配置文件语法并重启nginx服务
nginx -t
systemctl restart nginx2)增加一个filebeat流程
# filebeat可以使用 json.keys_under_root: true 配置来以json的方式解析日志,但是logstash的话就需要用像mutate 这种插件来实现有点麻烦,所以我就直接用filebeat来了
vim filebeat.yml
filebeat.inputs: # Filebeat 的输入配置开始的地方
- type: log # 这是一个日志输入类型从文件中获取
enabled: true # 这个输入被启用
paths: # 这个输入会读取以下路径的日志文件
- /var/log/nginx/access.log # 这是要读取的日志文件的路径
json.keys_under_root: true # 以json方式解析日志传输
output.logstash: # 输出目的类型配logstash
hosts: ["192.168.1.13:5044"]
3)logstash配置文件
cat /opt/logstash/useragent.conf
input {
beats {
port => 5044
}
}
filter {
# 删除几个无用字段
mutate {
remove_field => ["domain","responsetime","SendBytes", "agent", "host", "@version", "ecs", "tags","input", "log" ]
}
useragent {
# 指定客户端的设备相关信息的字段
source => "http_user_agent"
}
}
output {
stdout {}
}
4)查看日志效果
# ios访问效果,http_user_agent内为设备信息
{
"os" => "iOS",
"tcp_xff" => "-",
"os_version" => "13.2.3",
"referer" => "-",
"http_host" => "192.168.1.13",
"patch" => "3",
"http_user_agent" => "Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1",
"os_name" => "iOS",
"version" => "13.0.3",
"uri" => "/index.html",
"clientip" => "192.168.1.120",
"os_major" => "13",
"name" => "Mobile Safari",
"xff" => "-",
"minor" => "0",
"major" => "13",
"os_patch" => "3",
"os_minor" => "2",
"device" => "iPhone",
"@timestamp" => 2024-04-28T06:14:30.383Z,
"upstreamhost" => "-",
"upstreamtime" => "-",
"os_full" => "iOS 13.2.3",
"status" => "304"
}
# windows浏览器访问效果,http_user_agent内为设备信息
{
"os" => "Windows",
"tcp_xff" => "-",
"os_version" => "10",
"referer" => "-",
"http_host" => "192.168.1.13",
"patch" => "5622",
"http_user_agent" => "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36 Core/1.94.238.400 QQBrowser/12.4.5622.400",
"os_name" => "Windows",
"version" => "12.4.5622.400",
"uri" => "/index.html",
"clientip" => "192.168.1.120",
"os_major" => "10",
"name" => "QQ Browser",
"xff" => "-",
"minor" => "4",
"major" => "12",
"device" => "Other",
"@timestamp" => 2024-04-28T06:13:35.373Z,
"upstreamtime" => "-",
"upstreamhost" => "-",
"os_full" => "Windows 10",
"status" => "304"
}11. mutate 组件
文档:Mutate filter plugin | Logstash Reference [7.14] | Elastic
1-1)抄了一个创建日志的python测试脚本
cat > generate_log.py <<EOF
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# @author : oldboyedu-linux80
import datetime
import random
import logging
import time
import sys
LOG_FORMAT = "%(levelname)s %(asctime)s [com.oldboyedu.%(module)s] - %(message)s "
DATE_FORMAT = "%Y-%m-%d %H:%M:%S"
# 配置root的logging.Logger实例的基本配置
logging.basicConfig(level=logging.INFO, format=LOG_FORMAT, datefmt=DATE_FORMAT, filename=sys.argv[1]
, filemode='a',)
actions = ["浏览页面", "评论商品", "加入收藏", "加入购物车", "提交订单", "使用优惠券", "领取优惠券",
"搜索", "查看订单", "付款", "清空购物车"]
while True:
time.sleep(random.randint(1, 5))
user_id = random.randint(1, 10000)
# 对生成的浮点数保留2位有效数字.
price = round(random.uniform(15000, 30000),2)
action = random.choice(actions)
svip = random.choice([0,1])
logging.info("DAU|{0}|{1}|{2}|{3}".format(user_id, action,svip,price))
EOF
# 后台执行
nohup python generate_log.py /tmp/app.log &>/dev/null &1-2)split字段数据内容分割

input {
file {
# 配置文件路径
path => ["/tmp/app.log*"]
start_position => "beginning"
#start_position => "end"
}
}
filter {
# 删除几个无用字段,remove_field是通用的,所以哪个组件内都可以使用
mutate {
remove_field => ["domain","responsetime","SendBytes", "agent", "host", "@version", "ecs", "tags","input", "log" ]
}
mutate {
# 对message字段的内容用 “|” 来分割
split => {
"message" => "|"
}
}
}
output {
stdout {}
}
1-3)查看效果
# 没有分割前的数据状态,注意message字段内容
{
"@timestamp" => 2024-05-01T11:04:08.730Z,
"message" => "INFO 2024-05-01 19:04:08 [com.oldboyedu.generate_log] - DAU|335|领取优惠券|1|26119.64 ",
"path" => "/tmp/app.log"
}
{
"@timestamp" => 2024-05-01T11:04:12.772Z,
"message" => "INFO 2024-05-01 19:04:12 [com.oldboyedu.generate_log] - DAU|5736|提交订单|0|29759.05 ",
"path" => "/tmp/app.log"
}
# 配置了split后的日志数据状态,message字段内容被按照“|”分割
{
"@timestamp" => 2024-05-01T10:57:36.749Z,
"message" => [
[0] "INFO 2024-05-01 18:57:32 [com.oldboyedu.generate_log] - DAU",
[1] "5804",
[2] "加入购物车",
[3] "0",
[4] "26439.35 "
],
"path" => "/tmp/app.log"
}
{
"@timestamp" => 2024-05-01T10:57:36.749Z,
"message" => [
[0] "INFO 2024-05-01 18:57:35 [com.oldboyedu.generate_log] - DAU",
[1] "4241",
[2] "评论商品",
[3] "0",
[4] "24780.67 "
],
"path" => "/tmp/app.log"
}2-1)分割完数据后加入顶级字段
input {
file {
# 配置文件路径
path => ["/tmp/app.log*"]
start_position => "beginning"
#start_position => "end"
}
}
filter {
# 删除几个无用字段
mutate {
remove_field => ["domain","responsetime","SendBytes", "agent", "host", "@version", "ecs", "tags","input", "log" ]
}
# 对message字段的内容用 “|” 来分割
mutate {
split => {
"message" => "|"
} }
# 把分割的数据添加到顶级字段当中
mutate {
add_field => {
# 自定义字段名称=>固定格式 [字段名名称][取那个位置的值]
"user_id" => "%{[message][1]}"
"action" => "%{[message][2]}"
"svip" => "%{[message][3]}"
"price" => "%{[message][4]}"
}
}
}
output {
stdout {}
}2-2)查看日志效果
{
"@timestamp" => 2024-05-01T11:14:59.371Z,
"message" => [
[0] "INFO 2024-05-01 19:14:58 [com.oldboyedu.generate_log] - DAU",
[1] "5696",
[2] "评论商品",
[3] "0",
[4] "18161.75 "
],
"svip" => "0",
"user_id" => "5696",
"action" => "评论商品",
"path" => "/tmp/app.log"
"price" => "18558.73 "
}
{
"@timestamp" => 2024-05-01T11:15:00.373Z,
"message" => [
[0] "INFO 2024-05-01 19:14:59 [com.oldboyedu.generate_log] - DAU",
[1] "9293",
[2] "付款",
[3] "1",
[4] "19209.9 "
],
"svip" => "1",
"user_id" => "9293",
"action" => "付款",
"path" => "/tmp/app.log"
"price" => "18558.73 "
}3-1)转换字段值类型(数字、字符串)


配置文件修改
# 需求:1. 把金额改为数字类型,方便进行排序和其他操作
2. 把svip的参数改为布尔值类型,1则为ture,非1则为false
input {
file {
# 配置文件路径
path => ["/tmp/app.log*"]
start_position => "beginning"
#start_position => "end"
}
}
filter {
# 删除几个无用字段
mutate {
remove_field => ["domain","responsetime","SendBytes", "agent", "host", "@version", "ecs", "tags","input", "log" ]
}
# 对message字段的内容用 “|” 来分割
mutate {
split => {
"message" => "|"
} }
# 把分割的数据添加到顶级字段当中
mutate {
add_field => {
# 自定义字段名称=>固定格式 [字段名名称][取那个位置的值]
"user_id" => "%{[message][1]}"
"action" => "%{[message][2]}"
"svip" => "%{[message][3]}"
"price" => "%{[message][4]}"
}
}
# 使用convert来做字段类型转换,boolean(布尔值,true/false) float(浮点数类型) integer(整数类型)
mutate {
convert => {
"svip" => "boolean"
"price" => "float"
"user_id" => "integer"
}
}
}
output {
stdout {}
}3-2)查看日志效果
{
"@timestamp" => 2024-05-01T14:44:29.258Z,
"message" => [
[0] "INFO 2024-05-01 22:44:28 [com.oldboyedu.generate_log] - DAU",
[1] "5577",
[2] "使用优惠券",
[3] "0",
[4] "28054.7 "
],
"action" => "使用优惠券",
"svip" => false, # 转换为布尔值
"path" => "/tmp/app.log",
"user_id" => 5577, # 整数类型
"price" => 28054.7 # 浮点数类型
}
{
"@timestamp" => 2024-05-01T14:44:32.263Z,
"message" => [
[0] "INFO 2024-05-01 22:44:31 [com.oldboyedu.generate_log] - DAU",
[1] "1266",
[2] "搜索",
[3] "1",
[4] "28880.61 "
],
"action" => "搜索",
"svip" => true,
"path" => "/tmp/app.log",
"user_id" => 1266,
"price" => 28880.61
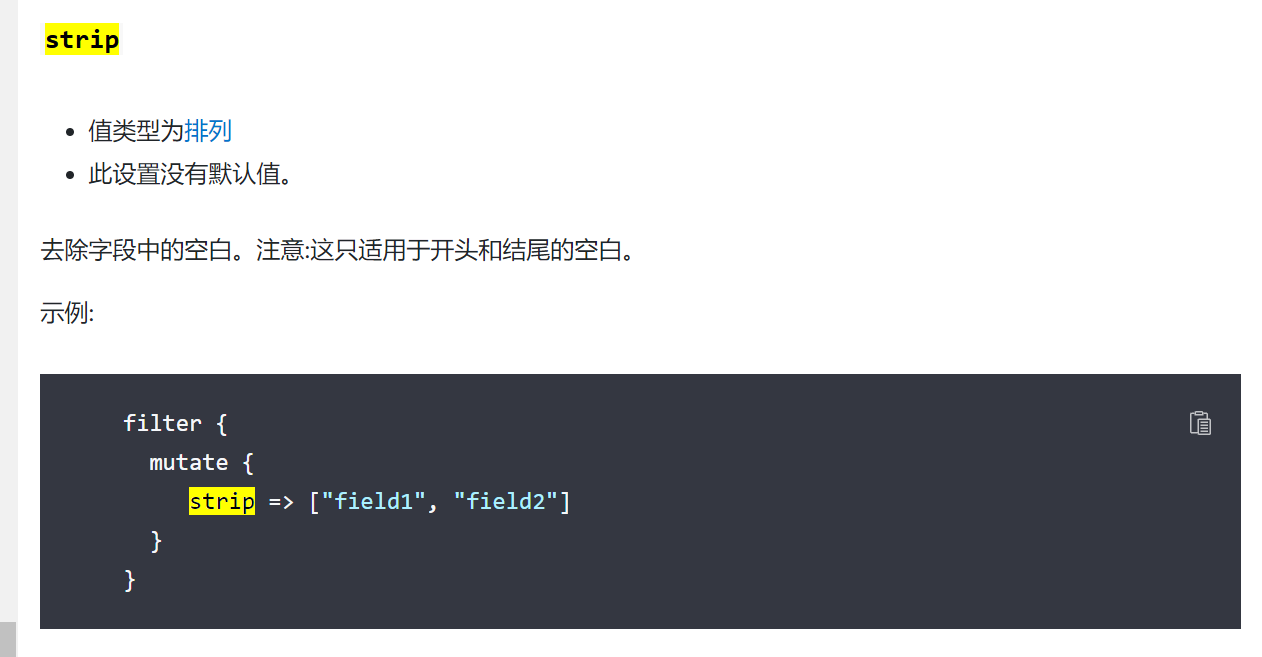
}补充:字段去空格
如果想要转换类型的字段前后有空格有可能会转换失败,所以在转换之前加一个这个参数(只可以处理开头和结尾的空格)
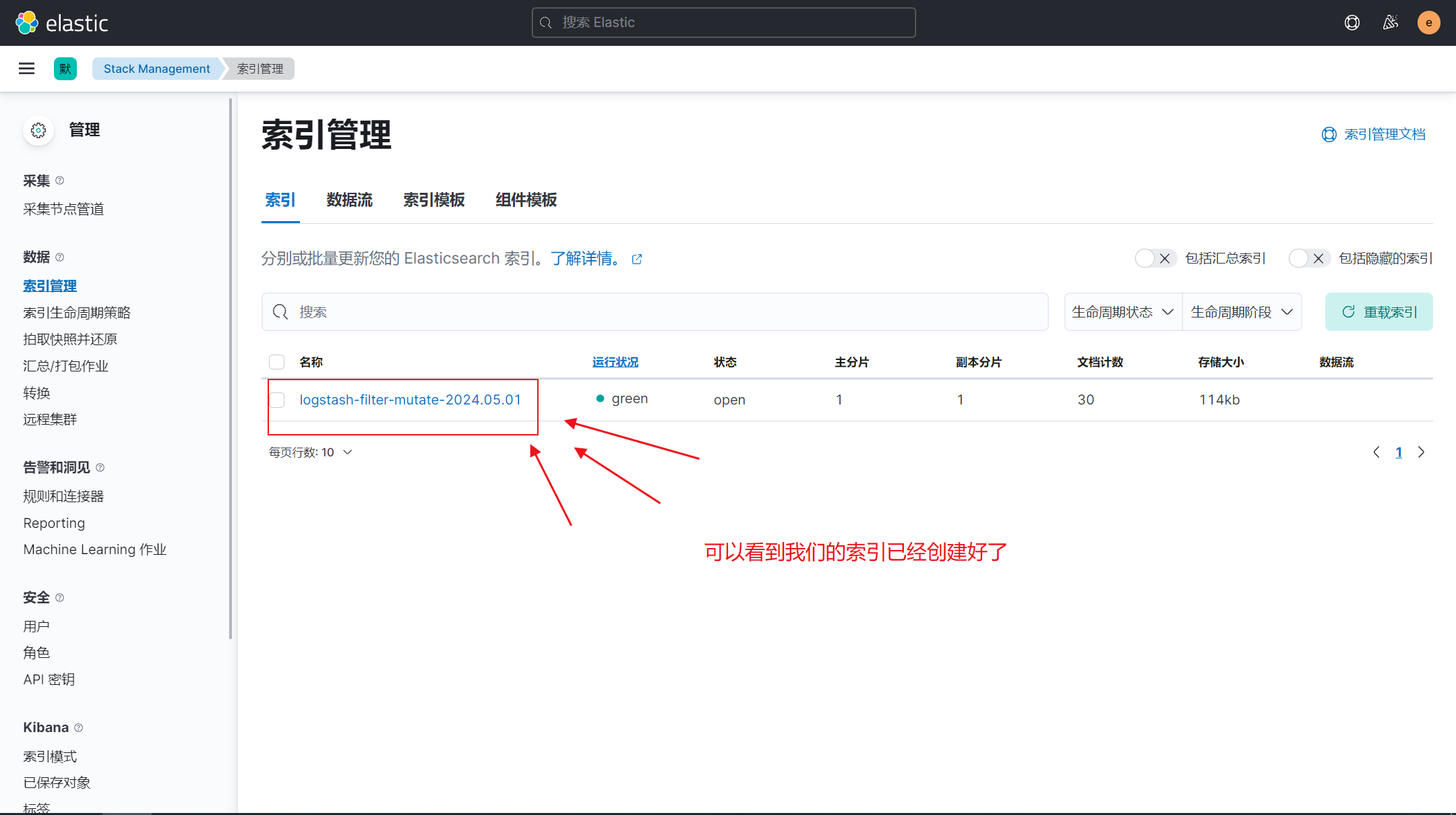
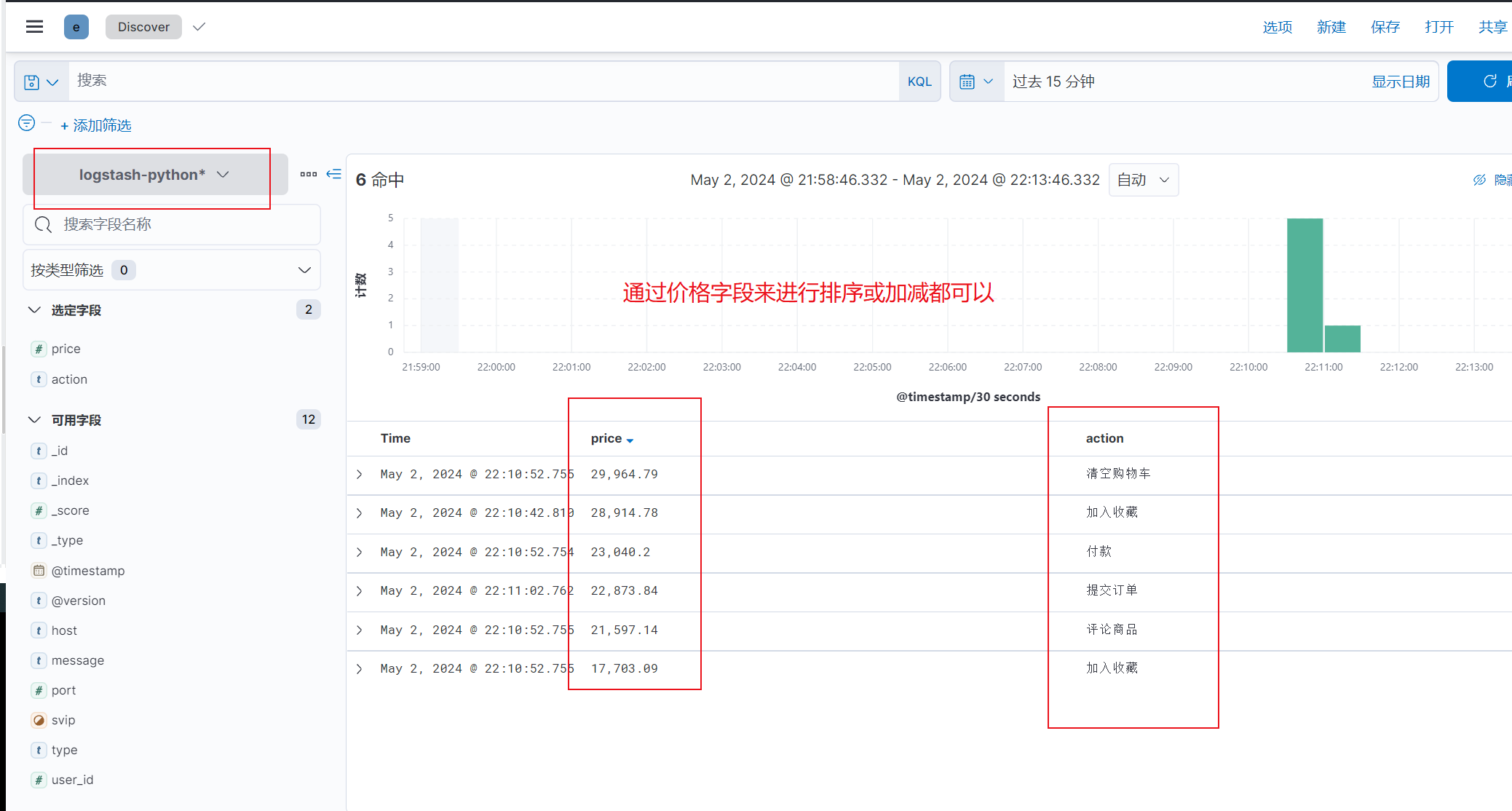
4)写入es展示排序效果
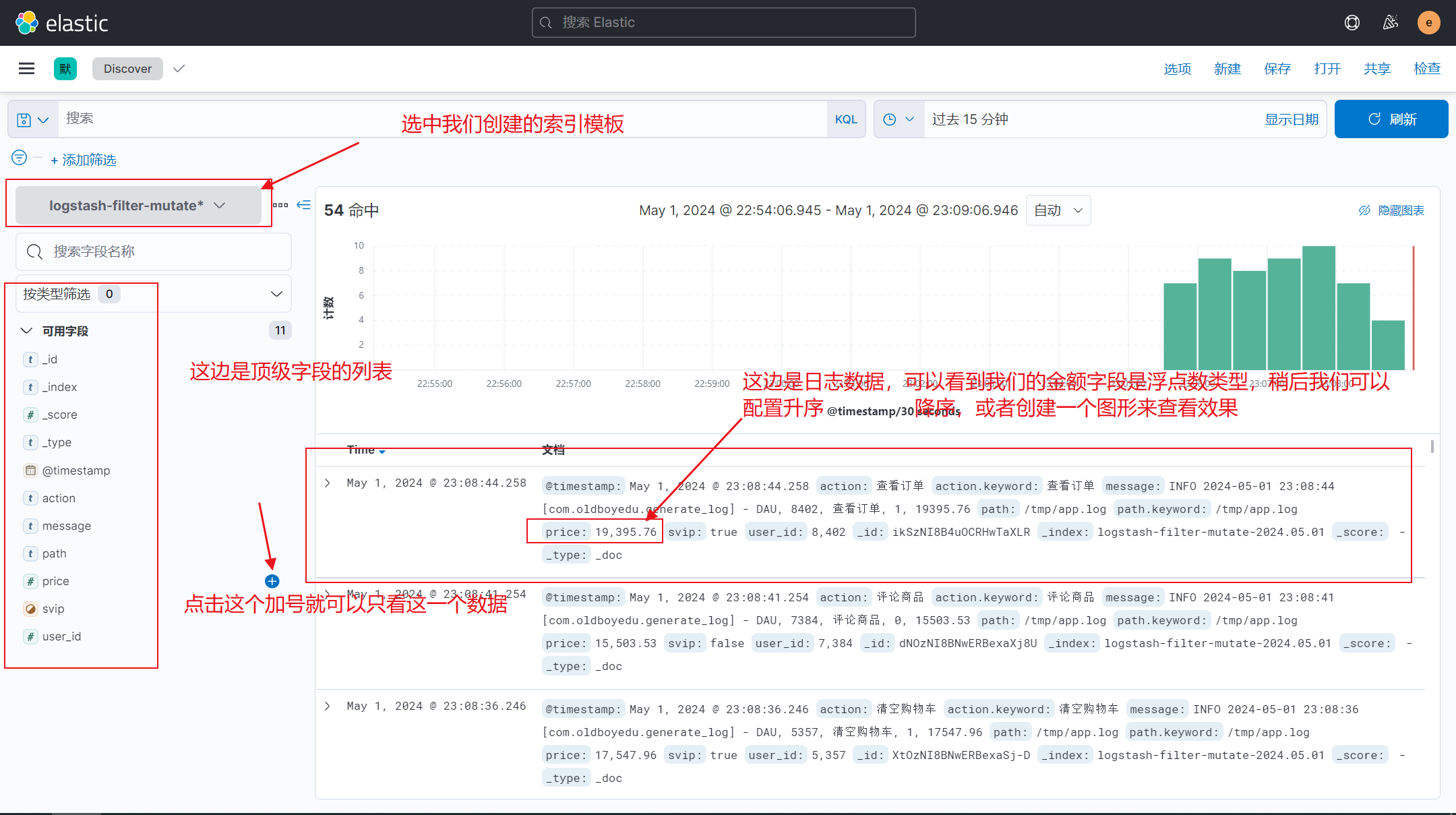
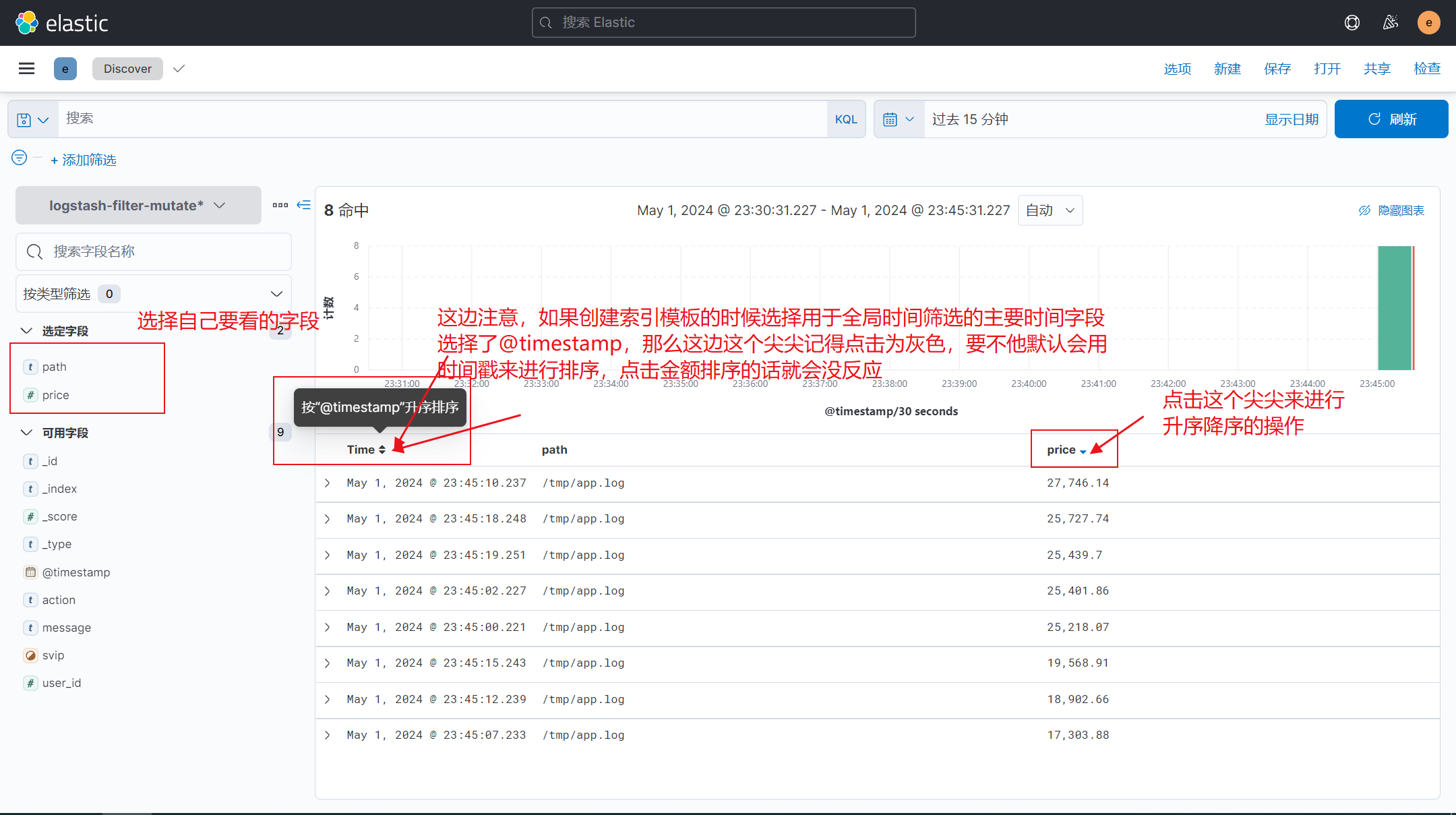
5-1)补充,copy功能

修改配置文件
input {
file {
# 配置文件路径
path => ["/tmp/app.log*"]
start_position => "beginning"
#start_position => "end"
}
}
filter {
# 删除几个无用字段
mutate {
remove_field => ["agent", "host", "@version", "ecs", "tags","input", "log" ]
}
# 对message字段的内容用 “|” 来分割
mutate {
split => {
"message" => "|"
} }
# 把分割的数据添加到顶级字段当中
mutate {
add_field => {
# 自定义字段名称=>固定格式 [字段名名称][取那个位置的值]
"user_id" => "%{[message][1]}"
"action" => "%{[message][2]}"
"svip" => "%{[message][3]}"
"price" => "%{[message][4]}"
}
}
mutate {
strip => ["svip"]
}
# 使用convert来做字段类型转换,boolean(布尔值,true/false) float(浮点数类型) integer(整数类型)
mutate {
convert => {
"svip" => "boolean"
"price" => "float"
"user_id" => "integer"
}
}
# 拷贝原字段成一个新的字段,数据一样
mutate {
copy => { "svip" => "vip" }
}
}
output {
stdout {}
elasticsearch {
hosts => ["192.168.1.81:9200","192.168.1.81:9199","192.168.1.81:9198"]
index => "logstash-filter-mutate-%{+YYYY.MM.dd}"
user => "elastic"
password => "123qqq...A"
}
}
5-2)日志效果
{
"price" => 20302.29,
"action" => "提交订单",
"user_id" => 7156,
"message" => [
[0] "INFO 2024-05-01 23:55:21 [com.oldboyedu.generate_log] - DAU",
[1] "7156",
[2] "提交订单",
[3] "1",
[4] "20302.29 "
],
"vip" => true, # copy的字段
"path" => "/tmp/app.log",
"@timestamp" => 2024-05-01T15:55:22.097Z,
"svip" => true # 源字段
}6-1)字段内容正则替换
修改配置文件
input {
file {
# 配置文件路径
path => ["/tmp/app.log*"]
start_position => "beginning"
#start_position => "end"
}
}
filter {
# 删除几个无用字段
mutate {
remove_field => ["agent", "host", "@version", "ecs", "tags","input", "log" ]
}
# 对message字段的内容用 “|” 来分割
mutate {
split => {
"message" => "|"
} }
# 把分割的数据添加到顶级字段当中
mutate {
add_field => {
# 自定义字段名称=>固定格式 [字段名名称][取那个位置的值]
"user_id" => "%{[message][1]}"
"action" => "%{[message][2]}"
"svip" => "%{[message][3]}"
"price" => "%{[message][4]}"
}
}
mutate {
strip => ["svip"]
}
# 使用convert来做字段类型转换,boolean(布尔值,true/false) float(浮点数类型) integer(整数类型)
mutate {
convert => {
"svip" => "boolean"
"price" => "float"
"user_id" => "integer"
}
}
mutate {
gsub => [
# 用“_” 来替换 path 字段内的所有 "/" 我只是随便找个数据展示下效果
"path", "/", "_"
# 批量替换修改,用"." 批量替换反斜杠问号井号减号,如果多个条件的话除了最后一个其他行都需要在结尾加 ","
#"fieldname2", "[\\?#-]", "."
]
}
}
output {
stdout {}
elasticsearch {
hosts => ["192.168.1.81:9200","192.168.1.81:9199","192.168.1.81:9198"]
index => "logstash-filter-mutate-%{+YYYY.MM.dd}"
user => "elastic"
password => "123qqq...A"
}
}
6-2)查看日志效果
### 没有替换之前的日志
{
"price" => 20302.29,
"action" => "提交订单",
"user_id" => 7156,
"message" => [
[0] "INFO 2024-05-01 23:55:21 [com.oldboyedu.generate_log] - DAU",
[1] "7156",
[2] "提交订单",
[3] "1",
[4] "20302.29 "
],
"vip" => true,
"path" => "/tmp/app.log", # 可以看到这个字段的符号还是"/"
"@timestamp" => 2024-05-01T15:55:22.097Z,
"svip" => true
}
### 进行替换之后的日志效果
{
"price" => 29924.37,
"action" => "付款",
"user_id" => 7736,
"message" => [
[0] "INFO 2024-05-02 00:08:37 [com.oldboyedu.generate_log] - DAU",
[1] "7736",
[2] "付款",
[3] "0",
[4] "29924.37 "
],
"path" => "_tmp_app.log", # 可以看到所有的 "/" 都换成了 "_"
"@timestamp" => 2024-05-01T16:08:37.719Z,
"svip" => false
}7-1)字符串转换大小写
这个就参考一下官方文档,不做展示了,用到了找一下就行
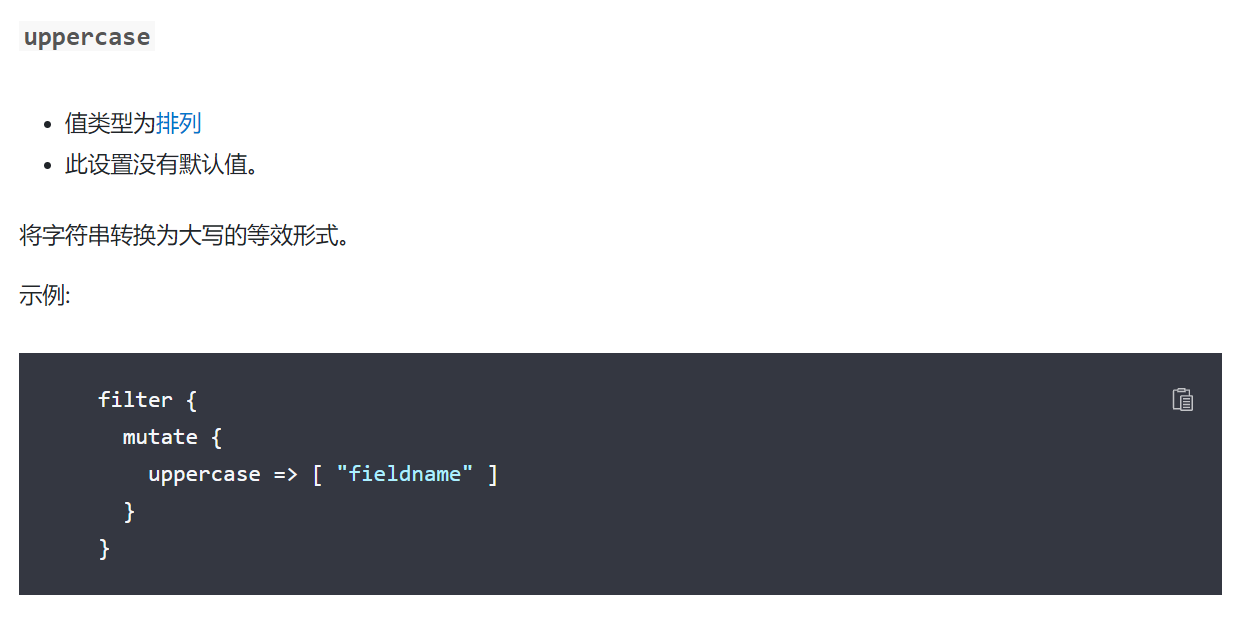
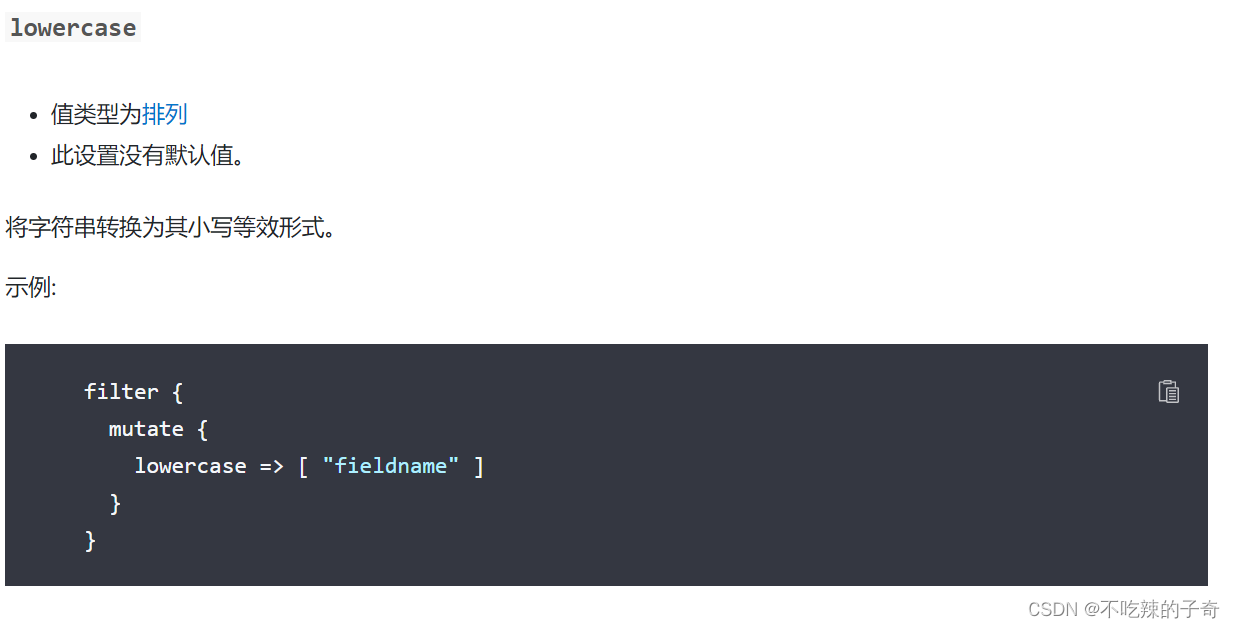
8-1)字段名称替换

配置文件示例
mutate {
# 把字段HOSTORIP 字段名称改为 client_ip
rename => { "HOSTORIP" => "client_ip" }
}9-1) 用新值替换原有字段的值

9-2)配置文件示例
mutate {
# 这边指定message字段来进行替换,先引用一下message字段在后边加个内容
replace => { "message" => "%{message}: 这是源日志消息内容" }
}9-3)查看日志效果
{
"user_id" => 7837,
"@timestamp" => 2024-05-02T02:49:53.147Z,
"path" => "_tmp_app.log",
"price" => 15199.92,
"message" => "INFO 2024-05-02 10:49:52 [com.oldboyedu.generate_log] - DAU,7837,清空购物车,0,15199.92 : 这是源日志消息内容", # 这边可以看到message字段内容进行了修改
"action" => "清空购物车",
"svip" => false
}12 综合案例
12-1 需求
通过 filebeat 来收集 nginx 服务的访问日志,并且以 json 格式发送到logsatsh,然后在 logstash 中处理数据,达到获取客户访问地址及访问设备的信息,然后上传到 ES 集群并且用 kibana 访问。
收集 python 服务运行的服务日志,不能通过 filebeat 的方式来传输给 logstash(这边只是随便想的,一般场景都可以用filebeat,我这里使用了rsyslog),收集到日志之后传输给 logstash 的 tcp 端口9999,并把他的 message 字段用 “|” 分割一下,然后把 svip 字段转换为布尔值、float 字段转换为浮点数、integer转换为整数。
12-2)流程图
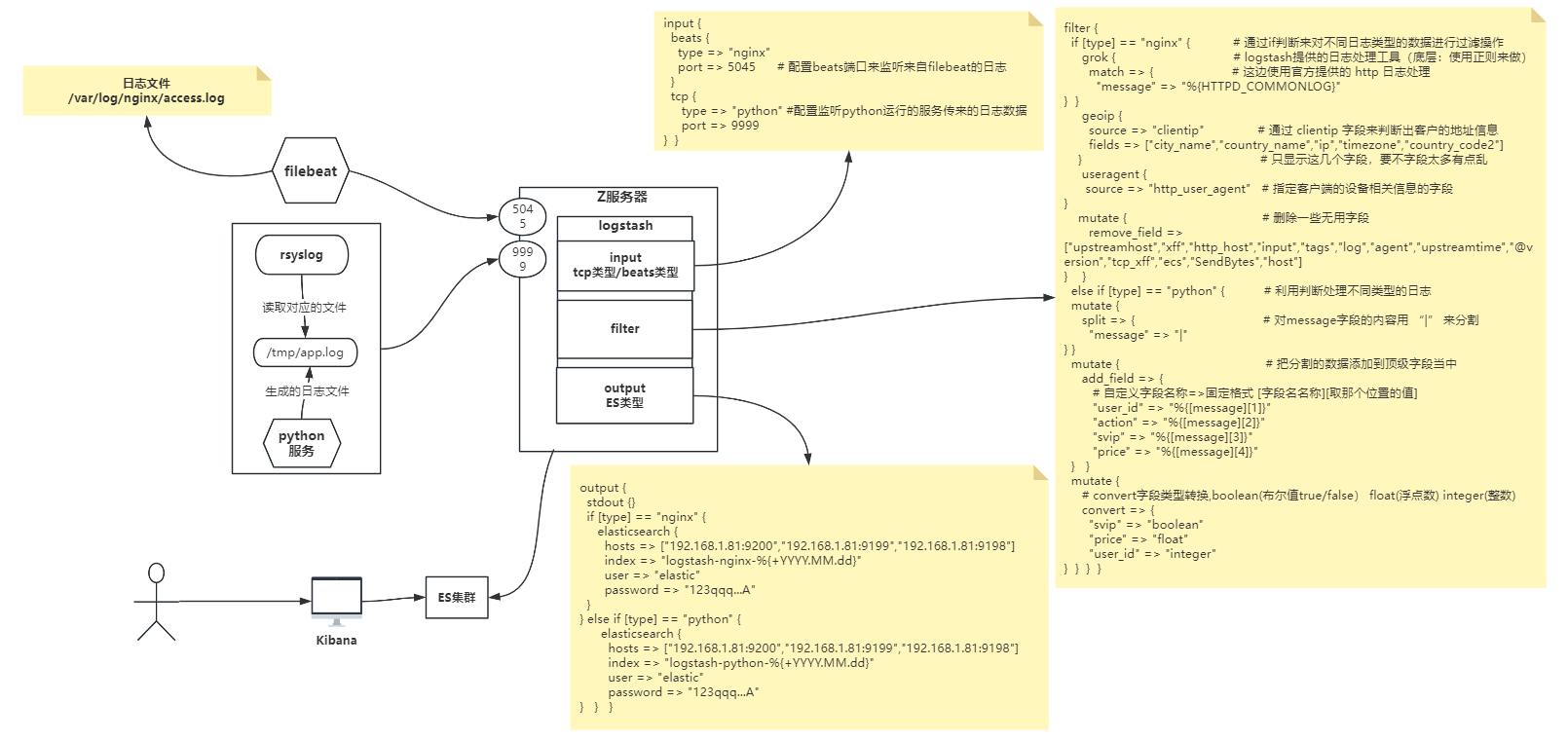
12-3) 修改nginx配置文件
vim /etc/nginx/nginx.conf
...
log_format oldboyedu_nginx_json '{"@timestamp":"$time_iso8601",'
'"host":"$server_addr",'
'"clientip":"$remote_addr",'
'"size":$body_bytes_sent,'
'"responsetime":$request_time,' '"upstreamtime":"$upstream_response_time",'
'"upstreamhost":"$upstream_addr",'
'"http_host":"$host",'
'"uri":"$uri",'
'"domain":"$host",'
'"xff":"$http_x_forwarded_for",'
'"referer":"$http_referer",'
'"tcp_xff":"$proxy_protocol_addr",'
'"http_user_agent":"$http_user_agent",'
'"status":"$status"}';
access_log /var/log/nginx/access.log oldboyedu_nginx_json;
# 重载一下配置文件
nginx -t
nginx -s reload12-4)filebeat配置文件
vim filebeat.yml
filebeat.inputs:
- type: log # 修改为log 日志类型
paths:
- /var/log/nginx/access.log # 监听日志文件路径
json.keys_under_root: true # 配置以json类型解析日志
output.logstash: # 输出目的类型配logstash
hosts: ["192.168.1.81:5044"] # 配置logstash地址
# 配置好之后运行filebeat
filebeat -e -c filebeat.yml12-5)配置rsyslog收集python服务日志
module(load="imfile" PollingInterval="10")
input(type="imfile" # 使用imfile插件
File="/tmp/app.log" # 定义日志文件路径
Tag="A-syslog") # 配置tag
if $programname == 'A-syslog' then @@192.168.1.81:9999 # 配置tcp url
python脚本的话去上边找,在 11. 1-112-6)logstash配置文件
vim logstash.conf
input {
beats {
type => "nginx" # 配置type字段,方便下边来判断日志输入源
port => 5045 # 配置beats端口来监听来自filebeat的日志
}
tcp {
type => "python"
port => 9999 # 配置TCP端口,来接受rsyslog传来的日志
}
}
filter {
if [type] == "nginx" { # 通过if判断来对不同日志类型的数据进行过滤操作
grok { # logstash提供的日志处理工具(底层:使用正则来做)
match => { # 这边使用官方提供的 http 日志处理
"message" => "%{HTTPD_COMMONLOG}"
}
}
geoip {
source => "clientip" # 通过 clientip 字段来判断出客户的地址信息
fields => ["city_name","country_name","ip","timezone","country_code2"]
# 通过 clientip 字段来判断出客户的地址信息
}
useragent {
source => "http_user_agent" # 指定客户端的设备相关信息的字段
}
mutate { # 删除一些无用字段
remove_field => ["upstreamhost","xff","http_host","input","tags","log","agent","upstreamtime","@version","tcp_xff","ecs","SendBytes","host"]
}
}
else if [type] == "python" {
mutate {
split => {
"message" => "|" # 对message字段的内容用 “|” 来分割
} }
mutate { # 把分割的数据添加到顶级字段当中
add_field => {
# 自定义字段名称=>固定格式 [字段名名称][取那个位置的值]
"user_id" => "%{[message][1]}"
"action" => "%{[message][2]}"
"svip" => "%{[message][3]}"
"price" => "%{[message][4]}"
}
}
mutate {
# convert字段类型转换,boolean(布尔值true/false) float(浮点数) integer(整数)
convert => {
"svip" => "boolean"
"price" => "float"
"user_id" => "integer"
}
}
}
}
output {
if [type] == "nginx" { # 通过判断来写入不同数据到不同索引
elasticsearch {
hosts => ["192.168.1.81:9200","192.168.1.81:9199","192.168.1.81:9198"]
index => "logstash-nginx-%{+YYYY.MM.dd}"
user => "elastic"
password => "123qqq...A"
}
} else if [type] == "python" {
elasticsearch {
hosts => ["192.168.1.81:9200","192.168.1.81:9199","192.168.1.81:9198"]
index => "logstash-python-%{+YYYY.MM.dd}"
user => "elastic"
password => "123qqq...A"
}
}
}
# 配置好之后运行logstash
logstash -rf logstash.conf12-7)查看日志效果
nginx日志
{
"type" => "nginx",
"geoip" => { # 通过clientip判断的客户端地址
"country_code2" => "CN",
"timezone" => "Asia/Shanghai",
"country_name" => "China",
"ip" => "124.222.25.145"
},
"os_full" => "iOS 13.2.3",
"name" => "Mobile Safari",
"uri" => "/index.html",
"clientip" => "124.222.25.145",
"minor" => "0",
"referer" => "-",
"major" => "13",
"status" => "304",
"os_name" => "iOS",
"domain" => "192.168.1.81",
"os_version" => "13.2.3",
"os" => "iOS",
"device" => "iPhone", # 通过http_user_agent判断的设备信息
"responsetime" => 0,
"os_major" => "13",
"@timestamp" => 2024-05-02T14:07:17.967Z,
"version" => "13.0.4",
"os_patch" => "3",
"os_minor" => "2",
"http_user_agent" => "Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.4 Mobile/15E148 Safari/604.1",
"patch" => "4"
}
python服务日志
{
"type" => "python",
"svip" => false, # 布尔值
"user_id" => 8017, # 整数
"price" => 22873.84, # 浮点数
"port" => 50672,
"@timestamp" => 2024-05-02T14:11:02.762Z,
"action" => "提交订单",
"host" => "192.168.1.81",
"message" => [
[0] "<133>May 2 22:11:02 localhost A-syslog INFO 2024-05-02 22:10:53 [com.oldboyedu.generate_log] - DAU",
[1] "8017",
[2] "提交订单",
[3] "0",
[4] "22873.84 "
],
"@version" => "1"
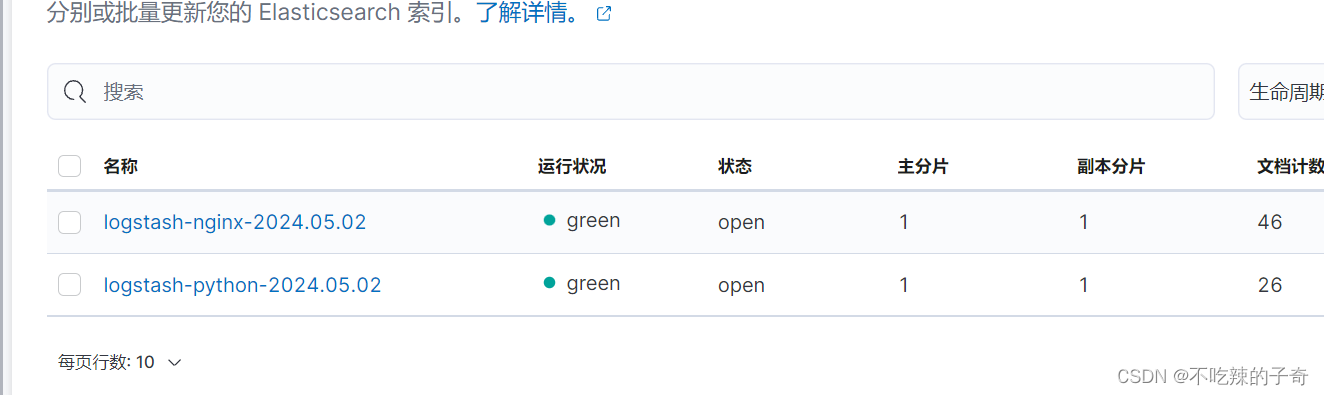
}Kibana中看下索引


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









