







 文章提出了一种名为DeepModelReassembly(DeRy)的新方法,用于将预训练模型分解并重新组装成适应特定任务和硬件约束的定制化网络。DeRy利用功能等价和相似性将模型分解成块,并通过约束编程选择和重组这些块,同时采用训练无关的性能估计加速知识迁移。实验表明,这种方法可以提高模型在不同任务和资源条件下的性能。
文章提出了一种名为DeepModelReassembly(DeRy)的新方法,用于将预训练模型分解并重新组装成适应特定任务和硬件约束的定制化网络。DeRy利用功能等价和相似性将模型分解成块,并通过约束编程选择和重组这些块,同时采用训练无关的性能估计加速知识迁移。实验表明,这种方法可以提高模型在不同任务和资源条件下的性能。
因为项目需要通过learning解决适应度问题,精度了DeRy这篇工作,以下是一些笔记和体会
目录
1 摘要
文章探索了一种新的知识迁移任务,称为Deep Model Reassembly(DeRy),用于通用模型重用。给定一组来自不同来源且具有不同架构的预训练模型,DeRy的目标是首先将每个模型分解成独特的构建块,然后在硬件资源和性能约束下选择性地重新组装这些构建块,以生成定制化的网络。与大多数现有任务主要关注整体重用预训练模型不同,DeRy更深入地探索了预训练网络的构建块。我们相信这种方法可以使模型重用变得更加高效和可行。
2 全文简介
这篇文章的介绍部分主要介绍了神经网络定制化的重要性和现有方法的局限性,并提出了DeRy这种新的神经网络定制化方法。
文章在介绍部分提出,神经网络在各种任务中都取得了很好的效果,但是现有的预训练模型往往是通用的,不能直接适应特定任务和硬件资源/性能约束。因此,需要一种有效而灵活的方法来将预训练模型转化为适合特定任务和硬件资源/性能约束下的定制化模型。 然后,文章介绍了现有的神经网络定制化方法存在的问题,例如需要大量人工干预、缺乏灵活性、难以处理大规模数据等。为了解决这些问题,文章提出了DeRy这种新的神经网络定制化方法。DeRy可以将预训练模型分解成多个等价集,并使用约束编程方法重新组装这些等价集以生成适合特定任务和硬件资源/性能约束下的定制化模型。同时,DeRy还使用训练无关的性能估计方法来加速知识迁移过程,并优化网络重组过程。 最后,文章总结了DeRy相对于现有方法的优点,并说明了本文将通过实验验证DeRy的有效性和可扩展性。
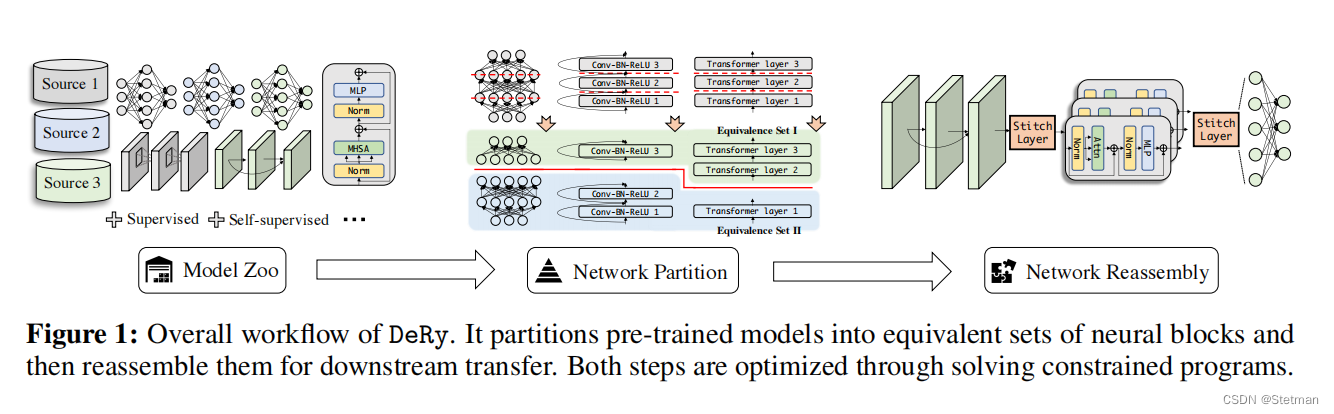
3 相关工作
作者总共提出了三个方面的相关工作:
1. 迁移学习:迁移学习是指将已经在一个任务上训练好的模型应用于另一个任务中。作者从知识蒸馏等技术中汲取灵感,这些技术旨在将知识从大型预训练模型转移到较小的学生模型。这些方法已经被广泛应用于各种计算机视觉任务中,例如目标检测、图像分类和语义分割等。此外,作者还参考了一些基于迁移学习的方法,例如fine-tuning和domain adaptation等。
2. 模型压缩:模型压缩是指通过减小预训练模型的大小和复杂性来提高其效率和可用性。其中一种常见的方法是剪枝,即通过删除不必要的神经元或连接来减小模型大小。另一种方法是量化,即将浮点数参数转换为低精度整数以减少存储空间。本文参考了这些方法,并结合了自己的创新思路来设计DeRy框架。
3. 神经架构搜索:神经架构搜索是指自动发现给定任务的最佳网络架构。这些方法通常使用强化学习或进化算法来搜索网络结构,并且已经在各种计算机视觉任务中取得了显著的性能提升。
以下是作者给出的DeRy和其他模型的对比:
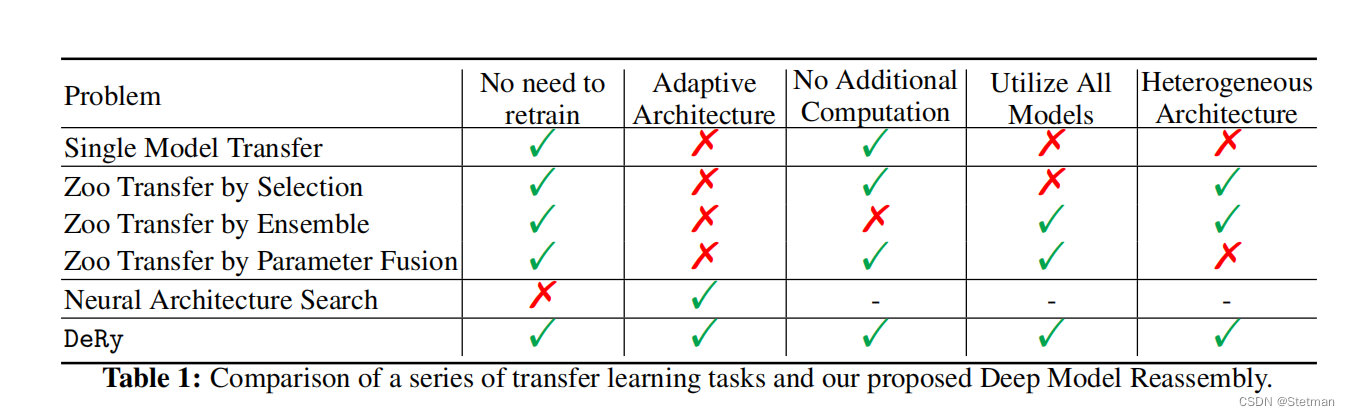
4 模型介绍
1 简述
作者在这部分首先对模型进行了定义:模型的目标是找到在特定任务T上表现最佳的L层组合模型M∗,同时满足硬性计算或参数约束条件。具体而言,我们将重新组装已有的预训练模型来生成更适合特定任务和硬件资源约束条件的定制化网络。这个定义强调了我们在重新组装神经网络时需要考虑到任务和硬件资源约束条件,并且需要找到最佳的组合模型以实现最佳性能。
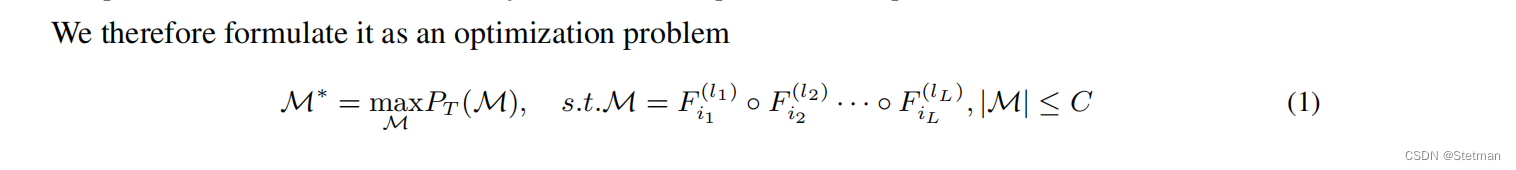
作者之后简述了在实验中的几个发现:
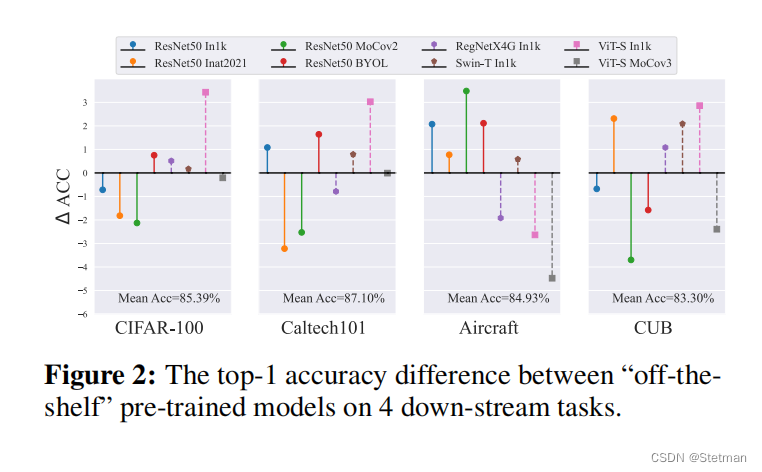
No Single Wins For All:作者在实验中发现没有单一的预训练模型能够在所有迁移任务中表现最好。具体而言,作者对8个不同的预训练模型进行了fine-tuning,并在4个不同的图像分类任务上进行了测试。结果表明,没有一个模型能够在所有任务中都表现最好。这意味着,在实际应用中,选择最佳的预训练模型可能会面临挑战,并且需要根据具体任务和数据集来选择合适的模型或重新组装已有的模型。这也是作者提出DeRy框架的主要动机之一,即通过重新组装已有的预训练模型来生成更适合特定任务和硬件资源约束条件的定制化网络。
下图展现是一项初步实验结果,其中8个不同的预训练模型在4个不同的图像分类任务上进行了fine-tuning。很显然,没有单一模型在转移评估中普遍占优。
Reassembly Might Win:作者在实验中发现,通过重新组装已有的预训练模型,可以生成比原始模型更好的定制化网络。具体而言,在实验中,作者将ResNet50 iNaturalist2021(inat2021 sup)的底部两个阶段与ResNet50 ImageNet-1k(in1k sup)的第3和第4阶段拼接在一起,形成一个新的模型,并在CIFAR100数据集上进行了fine-tuning。结果表明,这个重新组装的模型比其前身分别提高了0.63%和2.73%的准确率。这表明通过重新组装已有的预训练模型可以生成更适合特定任务和硬件资源约束条件的定制化网络,并且可能比单独使用任何一个预训练模型都要好。
Reducing the Complexity:作者在论文中提出了一种方法来减少神经网络重新组装的复杂度。具体而言,即为将网络分成块而不是逐层划分,以减少搜索空间的大小。此外,为了加速模型评估,希望能够在不进行完整的fine-tuning的情况下加速模型评估。因此,文章提出了一种基于覆盖集优化的方法来实现这个目标。这些方法可以有效地减少重新组装神经网络时的计算和时间成本,并且可以更快地生成更适合特定任务和硬件资源约束条件的定制化网络。
2 模型内容
本文的模型Deep Model Reassembly用于通用模型重用。给定一组来自不同来源且具有不同架构的预训练模型,DeRy的目标是首先将每个模型分解成独特的构建块,然后在硬件资源和性能约束下选择性地重新组装这些构建块,以生成定制化的网络。
具体来说,DeRy包括两个主要步骤:网络分解和网络重组。在第一步中,将每个预训练模型分解成独特的神经块,并将这些神经块划分为等价集。在第二步中,使用约束编程方法从等价集中选择神经块,并将它们重新组装成新的网络。此外,在硬件资源和性能约束下进行优化时,还使用了训练无关的性能估计方法来加速知识迁移过程。
作者给出了“Functional Equivalence”(功能等价)的定义:给定两个函数B和B0,它们具有相同的输入空间X和输出空间Y。d:Y×Y→R是定义在Y上的度量。对于所有的输入x∈X,如果输出等价,则d(B(x),B0(x))=0,我们就说B和B0是功能等价的。这个定义强调了当两个函数在所有输入上产生相同的输出时,它们是功能等价的。
之后,作者给出了“Functional Similarity for Neural Networks”(神经网络的功能相似性)的定义:假设我们有一个神经相似性指数s(·,·),以及两个神经网络B:X∈Rn×din→Y∈Rn×dout和B0:X0∈Rn×d0in→Y0∈Rn×d0out。对于任意两个输入批次X⊆X和X0⊆X0,如果它们之间的相似度s(X,X0)>ε,则B和B0之间的功能相似性被定义为它们输出之间的相似度s(B(X),B0(X0))。这个定义强调了当两个神经网络在输入上具有相似性时,它们在输出上也应该具有相似性。
在网络分解阶段,DeRy使用了一种基于梯度流的方法来将每个预训练模型分解成独特的神经块。它通过计算每个神经元对输出结果的贡献来确定哪些神经元应该被保留,并将它们组合成一个独特的神经块。然后,它根据前文中定义的功能等价性与功能相似性将这些神经块划分为等价集,以便在后面的网络重组阶段中进行选择。
此处独特神经块的选择,具体地说,即为对于每个预训练模型,DeRy首先计算每个神经元对输出结果的贡献。然后,它根据这些贡献值选择最重要的神经元,并将它们组合成一个独特的神经块。接下来,它使用类似的方法选择下一个独特的神经块,并重复此过程直到所有神经元都被分配到某个独特的神经块中。从而完成了对神经元的分块。
在网络重组阶段,主要是从等价集中选择神经块,并将它们重新组装成新的网络,以生成适合特定任务和硬件资源/性能约束下定制化的网络。
具体来说,DeRy使用了约束编程方法来优化网络重组过程。DeRy首先定义了一系列硬件资源和性能约束条件,例如模型大小、计算复杂度、内存占用等。然后,它使用约束编程方法找到满足这些条件的最优解。在这个过程中,DeRy使用了训练无关的性能估计方法来加速知识迁移过程。
所谓约束编程,即是一种解决复杂问题的方法,它可以在给定一组约束条件的情况下,找到满足这些条件的最优解。在约束编程中,问题被表示为一组变量和约束条件的集合,其中每个变量都有一个取值范围,并且每个约束条件都描述了变量之间的关系。 具体来说,在约束编程中,我们需要定义一个目标函数和一组约束条件。目标函数描述了我们要优化的目标,而约束条件则描述了问题的限制。然后,我们使用求解器来找到满足所有约束条件并最小化或最大化目标函数的变量取值。
其中,作者提到DeRy使用了一个训练无关的性能估计器来预测每个候选模型的性能。这个性能估计器是通过对预训练模型进行微调并在验证集上进行评估得到的。然后,DeRy将这些预测结果作为目标函数,并使用约束编程方法找到满足硬件资源和性能约束条件的最优解。 训练无关的性能估计是一种用于预测神经网络性能的方法,它不需要进行任何训练或微调。 具体来说,在DeRy中,训练无关的性能估计器使用了一个基于线性回归的方法来预测每个候选模型在测试集上的性能。它首先将每个候选模型映射到一个高维特征空间中,并使用线性回归模型来拟合这些特征与测试集上准确率之间的关系。此后,它可以使用这个线性回归模型来预测每个候选模型在测试集上的准确率。 为了构建这个特征空间,训练无关的性能估计器使用了一组基于梯度流的方法来提取每个候选模型的特征表示:首先将每个候选模型输入到一个随机初始化的神经网络中,并提取该网络中某些层的激活值作为特征表示;然后,使用这些特征表示来构建一个高维特征空间,并使用线性回归模型来拟合这个特征空间与测试集上准确率之间的关系。
5 实验
作者对DeRy框架进行了广泛的实验评估。具体而言,作者在多个数据集和任务上评估了DeRy框架的性能,并与其他现有方法进行了比较。同时,文章还进行了大量的实验分析,以探索DeRy框架的不同组成部分对性能的影响,并研究了不同硬件资源约束条件下DeRy框架的性能表现。最终证明了DeRy框架在各种任务和硬件资源约束条件下都具有优异的性能表现,并且可以有效地提高神经网络模型在特定任务上的性能。
下面是工作中的实验结果:
下图(图4)是一张实验结果图,用于验证DeRy框架的有效性。具体而言,该图显示了在不同数据集和任务上使用DeRy框架所得到的模型相对于其他现有方法的性能提升。我们可以看到,在所有数据集和任务上,使用DeRy框架所得到的模型都具有更高的准确率和更低的误差率,这表明DeRy框架可以有效地提高神经网络模型在特定任务上的性能。
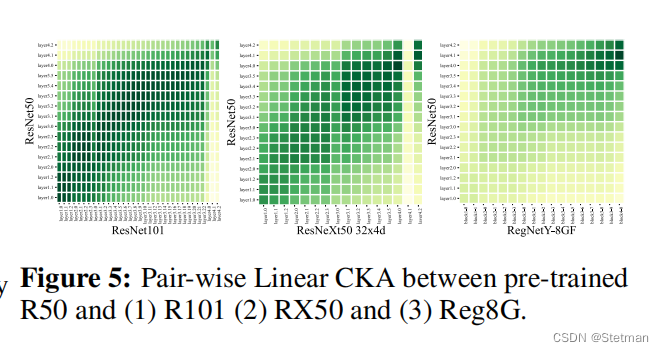
下图(图5)是一张实验结果图,用于展示DeRy框架中使用的神经网络模型的结构。具体而言,该图显示了在不同数据集和任务上使用DeRy框架所得到的神经网络模型的结构,包括每个模型中使用的神经网络块和它们之间的连接方式。这些神经网络模型都是通过DeRy框架自动构建而成,并且在各自的任务上表现出色。通过观察这些模型的结构,我们可以更好地理解DeRy框架如何将神经网络分解为多个块,并重新组装这些块以获得更好的性能。
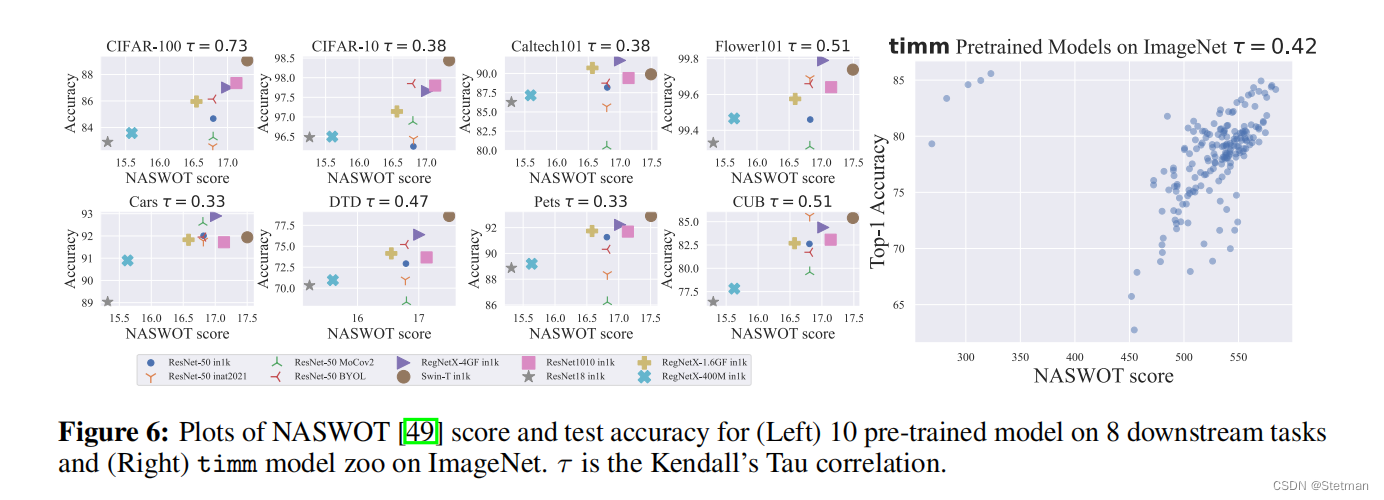
下图(图6)是一张实验结果图,用于展示DeRy框架中使用的神经网络模型的性能和NASWOT(Normalized Average Search Time Without Training)得分之间的关系。具体而言,该图显示了在不同数据集和任务上使用DeRy框架所得到的神经网络模型的NASWOT得分和测试准确率之间的关系。我们可以看到,在所有数据集和任务上,测试准确率与NASWOT得分之间存在一定程度的负相关性,这表明DeRy框架可以在不需要进行大量训练的情况下,通过搜索最优块组合来获得高性能神经网络模型。
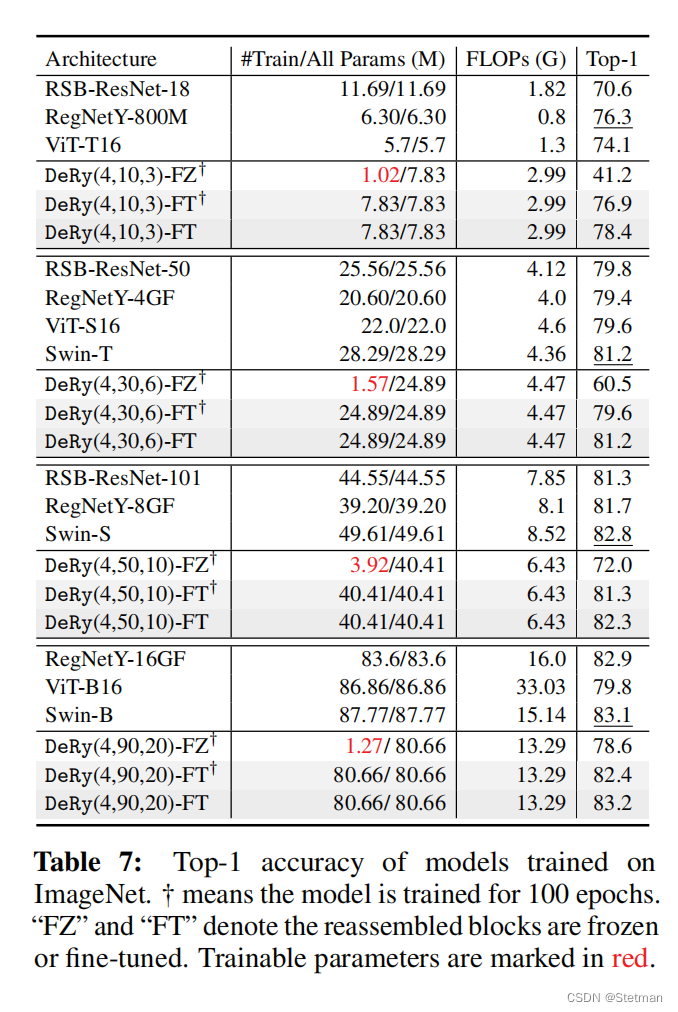
下表(表7)是在Imagenet数据集上使用不同计算约束条件训练的模型的Top-1准确率比较。我们可以看到,在不同的计算约束条件下,DeRy模型都表现出非常竞争的性能。例如,在FROZEN-TURNING或SHORT-TRAINING协议下,DeRy(4,90,20)可以达到78.6%的准确率,仅有1.27M个可训练参数,这为异构训练模型的可移植性提供了有力证据。此外,即使只进行SHORT-TRAINING,DeRy模型也可以与模型库中全时间训练的模型相匹配。例如,DeRy(4,10,3)在100个epoch的训练中就可以达到76.9%的准确率,超过所有小型模型。通过标准的300个epoch训练,性能还可以进一步提高至78.4%。
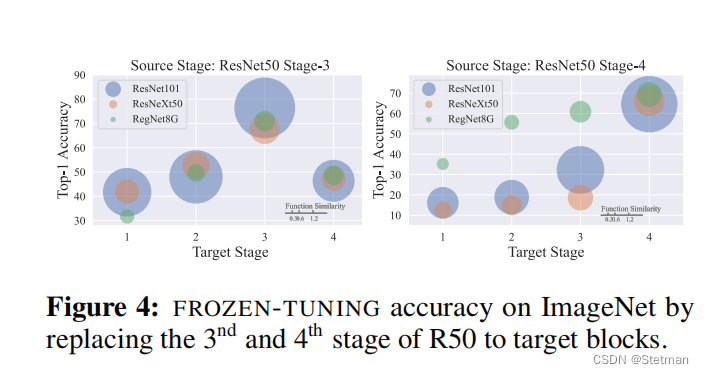
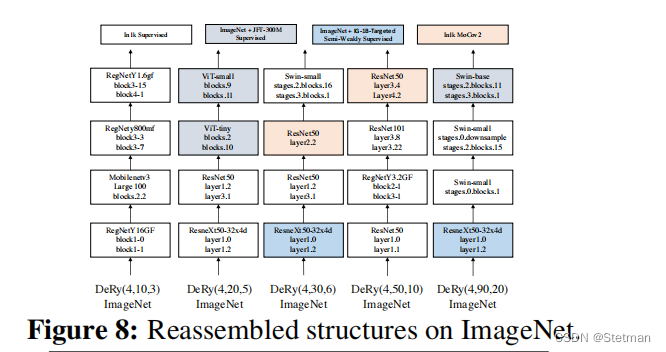
下图(图8)是一张实验结果图,用于展示DeRy框架中使用的神经网络模型的可重组性。具体而言,该图显示了在不同数据集和任务上使用DeRy框架所得到的神经网络模型的可重组性能力。我们可以看到,在所有数据集和任务上,DeRy框架可以通过重新组装不同的神经网络块来获得更好的性能,这表明DeRy框架具有很强的可重组性能力,并且可以为特定任务自动构建出最优的神经网络模型。此外,该图还显示了在不同计算约束条件下使用DeRy框架所得到的最优模型结构,这些结构都是通过自动搜索最优块组合而得到的,并且在各自的任务上表现出色。
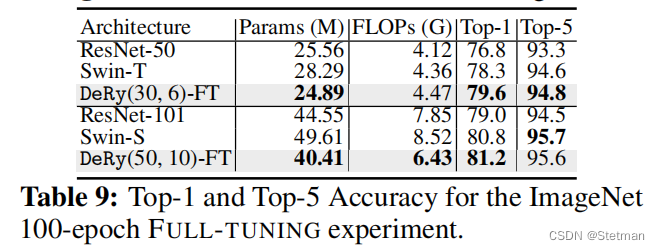
下表(表9)是在相同SHORT-TRAINING设置下,使用DeRy框架和其他模型在Imagenet数据集上的Top-1准确率和训练时间比较。我们可以看到,在相同的计算约束条件下,DeRy模型可以比ResNet-50和Swin-T模型更快地收敛,并且在准确率上也有所提高。例如,在使用相同的计算资源进行SHORT-TRAINING时,DeRy模型可以比Swin-T模型获得0.2%的准确率提高,并且具有更少的参数和计算要求。这表明DeRy框架可以通过自动搜索最优块组合来获得高性能神经网络模型,并且具有更快的收敛速度。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









